基于YOLOv5s的口罩佩戴实时检测系统设计
2022-12-22焦双健谢似霞
焦双健,谢似霞
(中国海洋大学 工程学院,山东 青岛 266100)
0 引 言
2019年,新型冠状病毒肺炎(以下简称新冠肺炎)疫情突然爆发,它是一种全球传播的流行病,传染性极强,自爆发以来,严重威胁着全球所有人的生命。虽然中国疫情防控的能力逐渐提高,但新型冠状病毒的突变也使这场疫情的情况不容乐观。如何应对新冠肺炎疫情,已成为全球科学界的一个焦点问题。科学界已做出许多努力,例如开发有效的疫苗、制定及时有效的治疗方案等。相关研究显示,新型冠状病毒主要通过飞沫和气溶胶传播。这种传播很有可能在与感染者的社会互动如交谈、接触中发生。因此,正确佩戴防护口罩成为一种科学有效的降低病毒传播率的方法。佩戴口罩可以有效过滤和阻断空气中的病毒,为人们的工作和出行安全提供保障。如今,在地铁、机场、火车站和工业厂房等人群众多的公共场所,都有专人来检查路过的人是否佩戴口罩。为了节省人力,避免漏检,有必要开发一种自动检测方法,检测公共场所的个人是否正确佩戴口罩,这也有利于疫情的智能防控。
随着深度学习和计算机视觉的快速发展,目标检测技术已经可以被很好地运用在口罩佩戴的自动检测中。经典的目标检测算法包括单阶段算法、两阶段算法和其他无锚算法,如Faster RCNN[1]、RetinaNet[2]、SSD[3]、YOLOv1[4]、CornerNet[5]等。现有的人脸和口罩检测算法可以分为两类。一类是追求快速推理速度的实时检测方法,另一种是高性能的检测方法,它优先考虑检测的准确性。李泽琛等[6]提出了一种多尺度注意力学习的Faster R-CNN口罩人脸检测模型,平均精度均值(mean Average Precision,mAP)达到90%以上,平均精度比较高,属于第一类,但是检测速度较慢,无法做到很好的实时性检测。曾成等[7]提出一种基于YOLOv3改进的算法M_YOLOv3来进行口罩佩戴检测,实验结果表明,YOLOv3的检测速度较快,但平均精度只有不到80%,属于第二类,但经过改进,改善了小目标的问题,mAP可以达到88%以上。潘卫国等[8]提出通过基于YOLO的目标检测算法实现对交通标志牌的实时检测识别,通过改进,使得算法在检测精度得到提升的同时,也充分满足了实时检测的要求,并得到了相关验证。综上,单阶段的目标检测算法经过改进,更适合应用于各种场景下的口罩佩戴实时检测,精度不低,速度也快。
本文提出一种基于YOLOv5s的口罩佩戴实时检测系统,先训练好用于口罩检测的达到预定标准精度的模型,再将该模型放入相关设备。该模型权重较小,推理速度快,可以很好地放入嵌入式设备中。该系统能够实时地判断人脸是否佩戴口罩,速度和准确性都比较高。可以通过在机场、超市和施工现场入口等人口流量高的地方部署相关设备,来实现对口罩佩戴的智能监测,从而有效提高疫情防控的效率。
1 目标检测模型的选择和改进
1.1 目标检测模型的选择
YOLO系列等单阶段的目标检测算法普遍具有检测速度快的优点,虽然比双阶段的目标检测算法精度低,但经过改进,精度也完全满足实时检测的要求。YOLO系列自身也在不断地完善和发展,在精度和检测速度上的效果越来越好。YOLOv5作为YOLO系列比较先进的算法模型,与YOLOv4相比,模型轻量,有巨大的灵活性,可以很好地满足口罩视频图像检测实时性的要求。YOLOv5的网络结构如图1所示。YOLOv5算法根据网络架构的深度和宽度分为4个大小不同的版本,具体包括YOLOv5s,YOLOv5m,YOLOv5l及YOLOv5x。YOLOv5s在COCO测试集与验证集上面的AP指标为36.8,AP50指标为55.6。YOLOv5s算法在V100 GPU上的推理只需要2.2 ms,帧率为455 f·s-1。该网络的模型大小仅为7.3 MB。相对地,YOLOv5x算法在V100 GPU上的推理速度是6.0 ms,帧率为167 f·s-1,模型的大小达到87.7 MB。可以看出,YOLOv5s网络小,推理速度也很快,因此比较适合嵌入式设备使用,适合部署在单片机上,能够在一定程度上解决目前大且复杂的模型难以被实际应用的问题。而且,其他三种模型都是在YOLOv5s基础上修改yaml文件,进行加深加宽网络操作,不需要修改大量的代码。本文使用YOLOv5s,其他三种模型可以在此基础上进行修改和精进。虽然YOLOv5s在实时性目标检测方面有诸多优点,但是在检测口罩时还存在错检漏检率高、无法很好地识别小目标等问题。因此,需要针对这些问题进行改进。
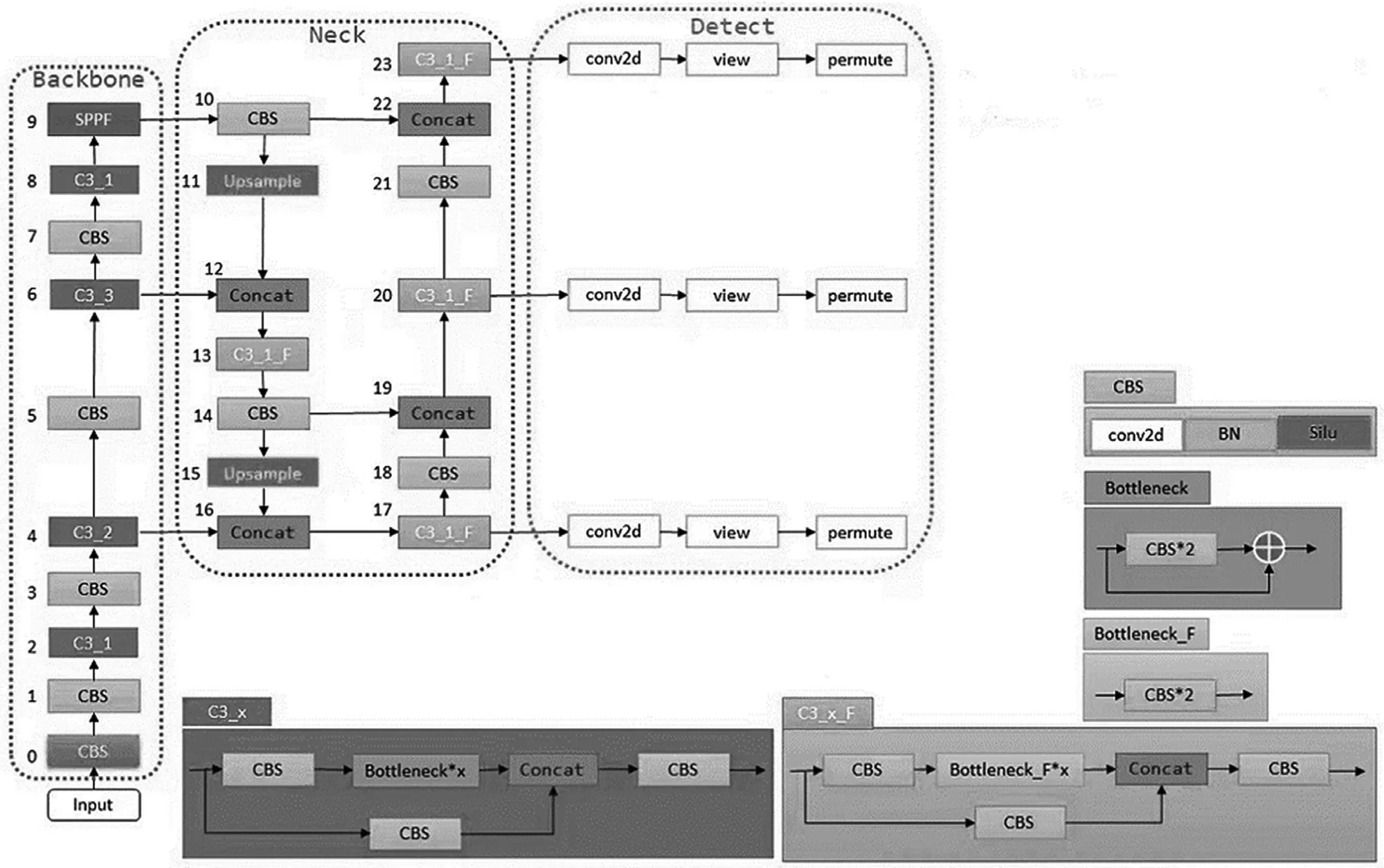
图1 YOLOv5的网络结构
1.2 针对口罩佩戴检测模型的改进
1.2.1 加入SE通道注意力机制
为了提高准确率,能识别到小目标或者较远处的目标,检测模型通常会加入注意力机制,让网络更加关注重要特征。
SENet作为较早的通道注意力机制,其目的是通过一个权重矩阵,从通道域的角度赋予图像不同位置不同的权重,得到更重要的特征信息。SE模块如图2所示。SE模块的操作主要为挤压(Squeeze)和激励(Excitation)。被加入的SE模块就通过这些操作让网络更关注待检测目标,提升网络模型的整体效果。
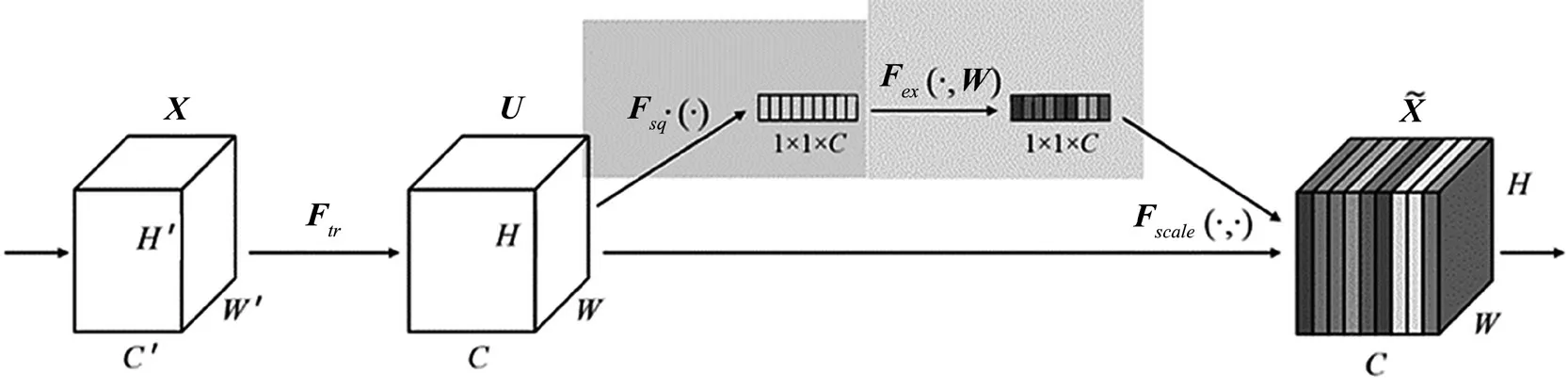
图2 SE模块的示意图
SE模块是一个即插即用的模块,它在YOLOv5s模型中的加入位置也是一个值得研究的话题。本文将SE模块添加进主干部分的C3模块之后,参数量引入较小。实验结果显示出了不错的提升效果。
1.2.2 改进损失函数
对于目标检测网络来说,目标框回归损失函数的选择非常重要。损失函数经历了一段时间的发展,也呈现出了几种不错的结果。对于YOLOv5s来说,它普遍采用的是GIOU_Loss作为Bounding box的损失函数。GIOU函数是最早出现的IOU函数改进版。GIOU损失函数的表达式为

式中:IOU为真实边界与预测框的交并比,A为预测矩形框,B为真实矩形框,C为A和B的外接矩形。GIOU损失函数能很好地反映真实框与预测框的重合程度和远近距离,一定程度上解决了IOU不能体现A和B两者之间距离的关键问题。但是,它也存在着缺点,当目标框完全包裹预测框时,如图3所示,GIOU会失去它的优势,变得和IOU一样,无法体现出A和B两者的位置关系。
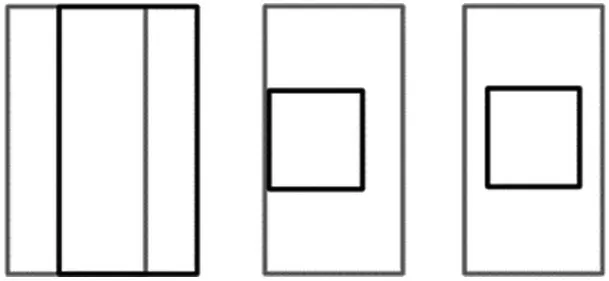
图3 GIOU公式中A和B区域的位置关系
鉴于GIOU损失函数的局限性,本文用CIOU损失函数代替GIOU损失函数。因为CIOU的计算方法充分考虑了预测框和真实框之间的重叠面积、中心点距离和长宽比。使用CIOU损失函数,可以使YOLOv5s网络在训练时保证预测框更快地收敛[9]。本文训练结果的对比,显示出CIOU损失函数的优越性。所以本文将CIOU损失函数作为口罩检测的损失函数,代替了GIOU损失函数。
2 系统总体设计
本文口罩检测系统的结构设计如图4所示。系统以口罩检测设备为核心,检测设备可以为各类单片机或者嵌入式设备,本文选用的是NVIDIA Jetson TX2嵌入式平台[10]。除此之外,系统还包含摄像头、报警器、显示屏幕、服务器以及存储数据的数据库。该系统通过摄像头采集视频流图像,通过检测设备实时识别出图像中的人脸是否佩戴口罩,并通过报警器和显示屏给出相应的结果,对未佩戴口罩的人做出警示。
图4 系统结构设计图
口罩检测的流程如图5所示。检测设备通过YOLOv5目标检测算法训练好的口罩检测模型对获取到的图像进行识别,当检测到有人未佩戴口罩,报警器就会立马发出警报,同时显示屏幕会显示出警告信息。当检测到口罩已经佩戴,系统仅会在显示屏幕上显示。这些结果都会通过服务器上传至存储数据的数据库,以方便相关人员查看。
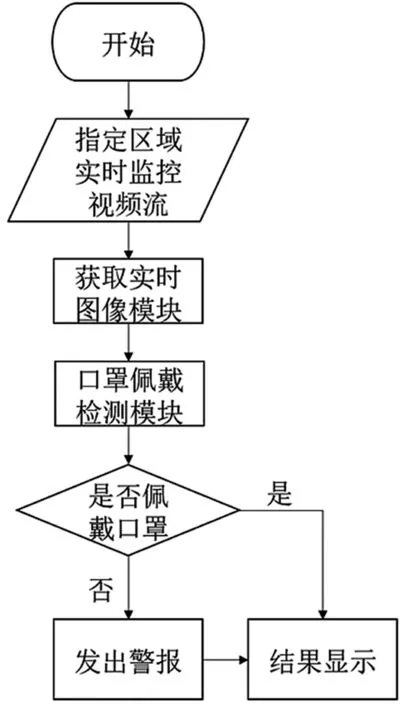
图5 检测设备系统流程图
3 口罩检测模块设计
3.1 口罩数据集
本文数据集大部分来源于互联网公开的数据集,还有少量自己拍摄和在公开视频中截取的图像。每张口罩数据集的图片都有对应的标签文件。标签分为戴口罩的人脸和不戴口罩的人脸两类,用mask和face表示。图片总计2 000张,经筛选和随意排序后,将图片按3∶1∶1的比值划分为训练集、测试集和验证集。训练集为1 200张,测试集和验证集均为400张。相关数据集图片如图6所示。

图6 数据集照片
3.2 评价指标
由于口罩检测本质上是一项分类和定位任务,因此应使用典型指标进行评估,包括真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)。基于这些指标,精度(Precision)和召回率(Recall)的定义如下:

精度和召回率都是简单地从一个角度来评价模型的好坏。它们的值越靠近1,模型的性能越好;越靠近0,模型的性能越差。为了综合评价目标检测的性能,一般采用平均精度均值mAP来进一步评估模型的好坏。
平均识别精度(Average Precision,AP),采用精度(Precision,P)和召回率(Recall,R)两个值作为横纵坐标,其所围成的面积为平均识别精度,即为P-R曲线,如式(4)所示。mAP则为平均精度均值,一般以IOU为0.5来计算mAP,其中IOU如式(5)所示。式(5)中A代表预测的边框,B代表目标实际的边框。AP是计算某一类P-R曲线下的面积,mAP则是计算所有类别P-R曲线下面积的平均值,如式(6)所示。
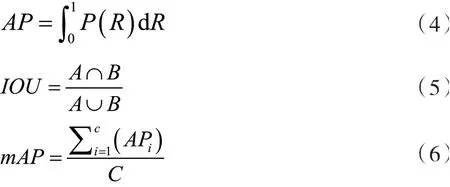
本文的平均精度均值就是对佩戴口罩的人脸的平均识别精度和不戴口罩的人脸的平均识别精度求均值,即公式(7)。
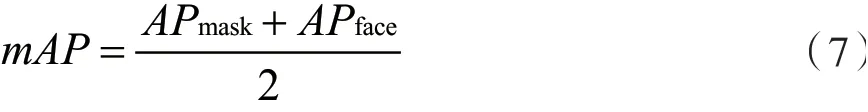
3.3 模型训练
PyTorch是目前难得的简洁、优雅、高效且快速的框架,已经在深度学习框架中达到了一定的高度。在当前开源的所有框架中,PyTorch在灵活性、易用性、速度等方面占据绝对优势[11]。因此,本文选择PyTorch作为训练框架来进行模型训练。
首先,将数据集的jpg文件放入images文件夹,将txt文件放入labels文件夹,将标记完成的数据集图片和标签文件分别放入对应的训练集、测试集、验证集文件夹中。在data文件夹下创建一个新的yaml文件来标记数据集的位置、数据集的类别和目标名称。数据集处理完成之后就可以进行模型训练。在Anaconda3搭建的名为yolo5的虚拟环境中运行train.py进行模型训练,迭代次数为100轮,batchsize设为4。
本文对YOLOv5s模型进行训练,将口罩图片数据通过输入端先进行Mosaic数据增强操作提升模型的训练速度和网络的精度,其次进行自适应锚框计算和自适应图片缩放,再次,通过主干网络和Neck网络对图片进行切片操作,进行图像特征的聚合等操作。最后在目标检测结果的输出阶段,运用替换后的CIOU作为损失函数,通过加权nms后处理,进一步提升算法的检测能力。
3.4 系统性能分析
本文采用平均精度AP、平均精度均值mAP和P-R曲线这三种评价指标来评价所训练的口罩检测模型的性能优劣。AP和mAP越接近于1,模型的训练效果越好。
本文用收集到的各种场景下的口罩数据集来进行口罩检测系统的性能分析。将IoU设为0.5,计算每一类的所有图片的AP,然后所有类别取平均,即mAP,由此得到基于YOLOv5s的口罩佩戴实时检测模型的性能评价和对比。结果如表1和图7、图8所示。加入SE通道注意力机制后,较原始YOLOv5s网络的总体mAP指标提升了3.9%,然后将CIOU损失函数替代GIOU损失函数后,又使该指标提升了1.1%,达到86.7%。改进后模型性能提升明显。该模型的精度能满足实时性口罩佩戴检测的要求。
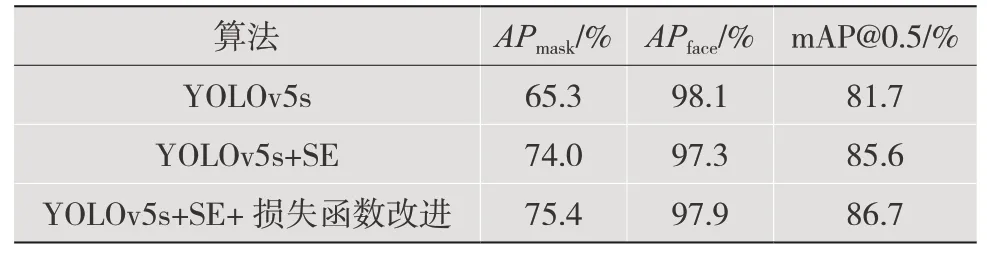
表1 口罩检测模块的改进结果对比
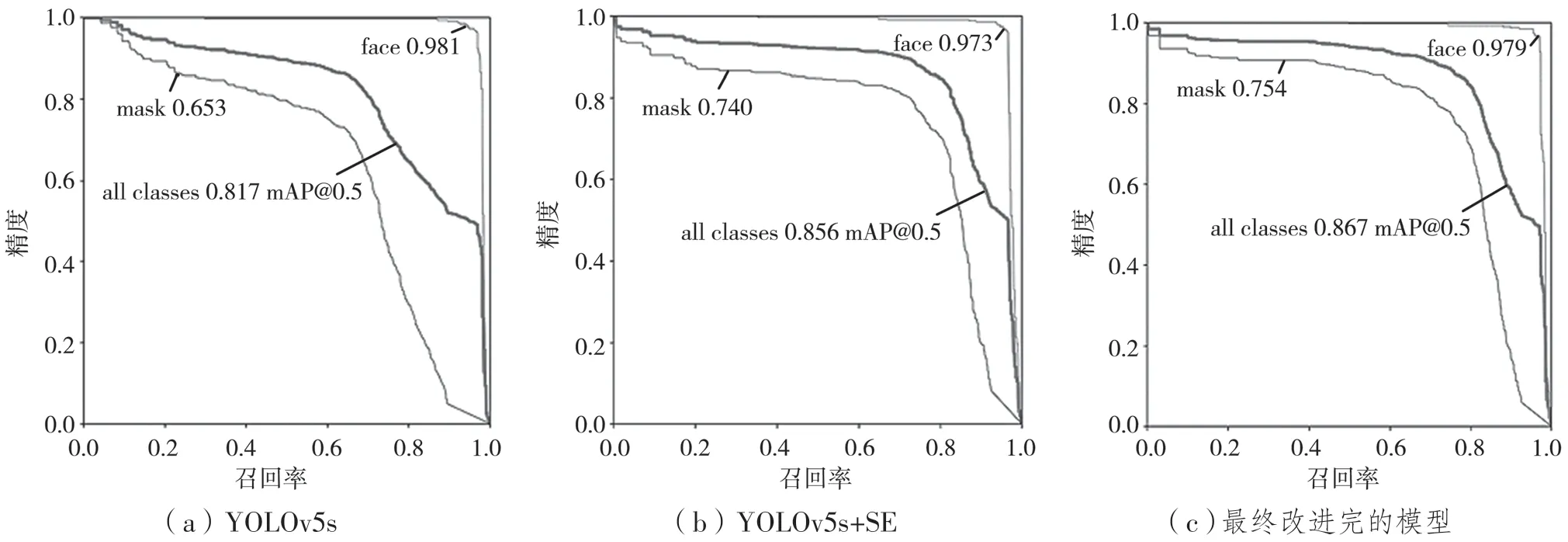
图7 不同算法的P-R曲线

图8 算法改进前后的效果对比图
4 结 语
为了提高口罩佩戴检测的效率,本文提出了一种基于YOLOv5s的口罩佩戴实时检测系统设计方案。首先,对目标检测模型进行了选择和改进,选择了适合于嵌入式设备的推理速度较快的YOLOv5s模型。对YOLOv5s网络模型进行改进,加入了SE通道注意力机制,改进了目标框回归损失函数。将改进的YOLOv5s模型进行训练,精度达到预定标准,训练完成后,得到最优模型。此系统将该模型部署到相关设备上以实现实际应用,实现了系统设计的目标。在未来的工作中,应该在保证模型轻量和检测速度的基础上,继续提升模型的精度,实现对小目标和较远处目标的精准识别。
