基于UCI数据集的OCR光学字符识别
2022-12-22史素霞常婉秋宋志英
史素霞,常婉秋,宋志英
(1.河北政法职业学院 建设工程与法务系,石家庄 050061;2.中国农业大学 土地科学与技术学院,北京 100083;3.农业农村部农业灾害遥感重点实验室,北京 100083)
OCR字符识别是将影像数据提取出相应的字符信息,并翻译成计算机语言的过程[1]。实际上对于OCR文字识别的过程,首先是确定字符所在的矩形区域,通过记录矩阵区域的黑色像素数,对字符内容进行记录,通过记录矩形区域内黑色像素的平均和值,以及和的平均方差等统计信息,使得字符的识别具有唯一性,有利于更加准确地识别字符。计算机的发展对OCR光学字符的识别产生深远的影响。
1999—2004年,研究学者主要基于传统的统计方法对光学字符进行识别[2],隐马尔柯夫模型(Hidden Markov Model,HMM)和支持向量机(Support Vector Machine,SVM)模型出现跳跃式发展,研究学者将人脸识别技术和字符识别技术进行交叉研究[3]。2005—2012年研究学者有了新的突破,将遗传算法应用于文本检测等字符识别方向[4]。Xiao等[5]将卷积神经网络(CNN)的运行成本进行优化,基于全局监督低秩展开方法(GSLRE)和自适应下降权重(ADW)进行字符识别,将计算成本降低了10%。
1 数据来源与预处理
1.1 UCI光学字符识别数据集
本次研究选用开源的UCI光学字符数据集,从UCI Machine Learning Repository中下载获得。UCI数据集是根据机器学习相关数据标准建立的测试性数据集,由加利福尼亚大学尔湾分校(University of California,Irvine)提出,用于深度学习和机器学习算法测试的一种数据库。本次实验选用UCI数据集,原因在于其数据格式的标准性,统一规范的数据格式有利于对数据进行处理和分析,数据源质量的提高有助于识别精度的提升。
UCI光学字符数据集中包含多个字母样本,每个样本包括16个变量。其中,将字符所在矩形区域的水平位置表示为x1、字符所在矩形区域的竖直位置表示为x2、矩形区域的宽度表示为x3、矩形区域的高度表示为x4、矩形区域的黑色像素数表示为x5、矩形区域内黑色像素的平均x值表示为x6、矩形区域内黑色像素的平均y值表示为x7、x平均方差表示为x8、y平均方差表示为x9、x和y的平均相关性表示为x10、x2y均值表示为x11、xy2均值表示为x12、从左到右的边缘数目表示为x13、x边缘与y的相关性表示为x14、从下到上的边缘数目表示为x15及y边缘与x的相关性表示为x16。
1.2 数据预处理
通过对数据的筛选可以发现UCI数据集中存在许多0值点,再结合对变量含义的理解,将变量x1—x14中的0值视为残缺值,通过平均值代替。对于变量x15和x16,这2个变量中的0值表示的是一种数据统一的理想情况,即这2个变量中可以存在0值,且有意义,因此不将其视为残缺值,但这2个变量中的最大值表示这组数据不稳定,通过平均值进行替换。
2 研究方法
2.1 主成分分析模型
主成分分析方法通过降维的思想[6],将多个相关或不相关的指标化为垂直不相关的几个综合指标,即为模型的多元主成分。对于本次研究而言,此方法就是用主要的影响因素来分析图像数据集,以达到准确判断和识别每个字符的目的,具体模型建立过程如图1所示。
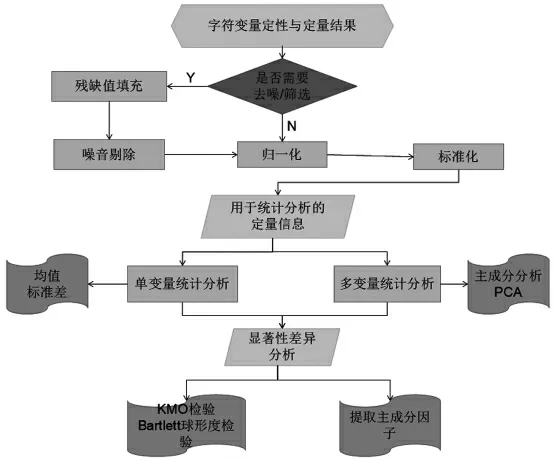
图1 主成分分析流程图
2.2 逐步回归模型
多元回归的逐步回归模型根据自变量x的显著程度,从大到小依次引入回归方程中,当之前引入的变量由于后面新引入的变量而变得不显著时,就要将之前那个剔除。基于本次的研究问题而言,这个过程要反复多次进行,直至没有显著的变量可以被引入时为止,模型因子的作用如图2所示。
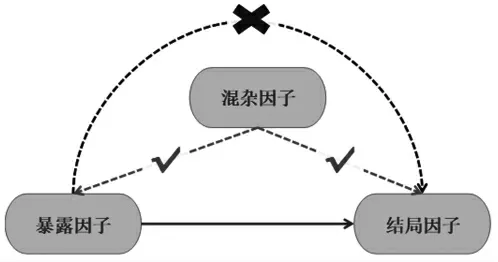
图2 逐步回归因子图
在原始下载的UCI数据集中存在很多的混杂因子,不利于进行字符识别模型的建立,以及影响字符识别的精度。混杂因子对暴露因子会产生一定的影响,并且对最后的部分结局因子会产生直接或间接的作用,而逐步回归方程可以有效地剔除部分混杂因子,因此选用逐步回归的方法,逐层剔除混杂因子。
2.3 BP神经网络模型
BP神经网络不需要提前描述输入—输出之间的映射关系,而是建立一种基于误差分析训练的多层前馈网络,通过学习计算各节点之间传递的映射关系,存储大量的非线性网络模型[7]。
基于误差反向传播规律,将BP神经网络的特征函数Sigmoid表示为{f(x)=1/(1+e-bx),b>0},多层前向反馈型神经网络的结构如图3所示。
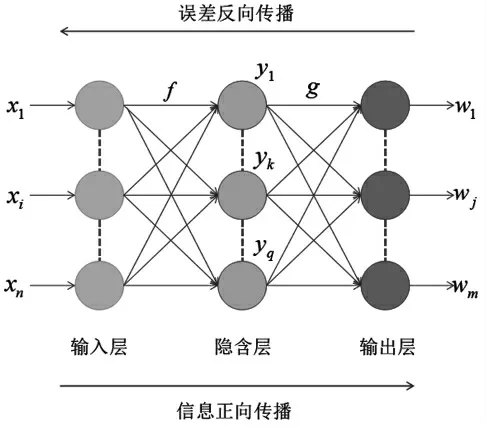
图3 BP神经网络基本结构图
本次研究将UCI数据集中70%的数据用于学习训练,训练集从输入层传入隐含层进而到达输出层,神经网络通过不断调整各层之间的函数关系,使得训练结果最接近真实的输出值,并记录这种映射关系,对剩余30%的字符数据集进行识别,从而得到识别的精度。经过一系列的处理,使得本次研究的BP神经网络具有很好的适应能力。
本次研究建立的BP神经网络的总误差E如公式(1)所示

神经网络每一层权值的确定都是基于正向的信息传递和误差的反向传播,误差信号δk的计算如公式(2)所示

通过对输出值Wk的正向传播与期望值Ek的反向传播计算,得到隐含层与输出层之间的权重wkj如公式(3)所示
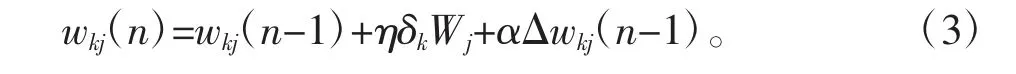
误差信号δk通过反向传播至输入层,从而得到输入层误差信号δi,计算过程如公式(4)所示
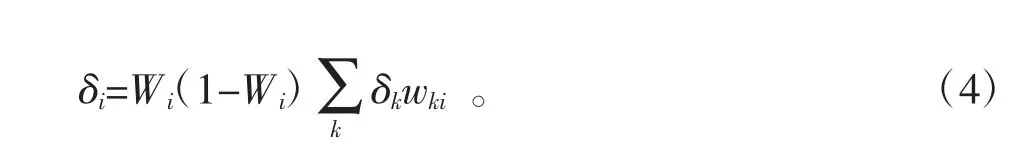
基于反向传播误差信号δi,重新设定输入层和隐含层之间的权重阈值wji,计算过程如公式(5)所示
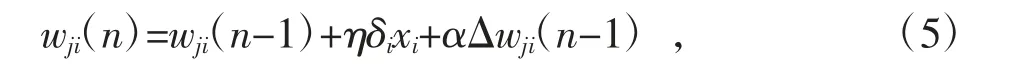
式中:η为控制迭代步长的学习率;α为控制训练速度的动量项。
通过对神经网络进行反复训练,使得各层之间的权重阈值达到最好的效果,从而使整个BP神经网络的识别精度达到最好。
3 结果与分析
3.1 基于主成分分析的特征提取
基于UCI数据集对数据的初步统计,提取每个字符对应的所有变量的平均值,并以此作为原始的指标。对原始的指标进行标准化变换,根据统计学公式得到2个原始变量xi与xj之间的相关系数rij,计算过程如公式(6)所示
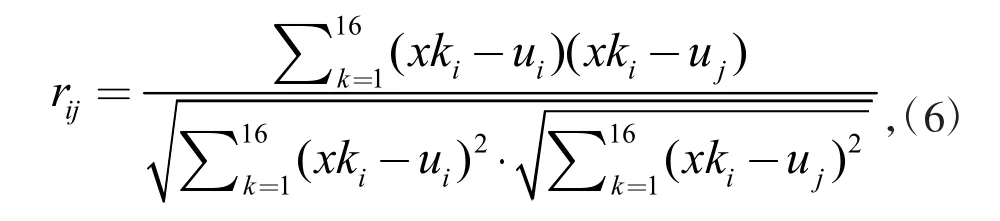
式中:因为相关系数矩阵是对称矩阵,所以rij=rji。
通过主成分分析法计算原始变量的相关系数矩阵R,使累计贡献率达85%以上,计算结果见1。

表1 主成分分析总方差解释
由此得到7个主成分。
3.2 基于逐步回归的字符识别模型
在进行逐步回归计算前,引入主成分分析法得出的具有显著作用的因子作为自变量,确定显著性下检验的水准,作为引入和剔除变量的标准。针对本次的研究,样本的观察数n=26,自变量个数m=16,则剩余自由度为9,显著性水平α=0.05,对7个自变量计算偏回归平方和Ui,计算过程如公式(7)所示
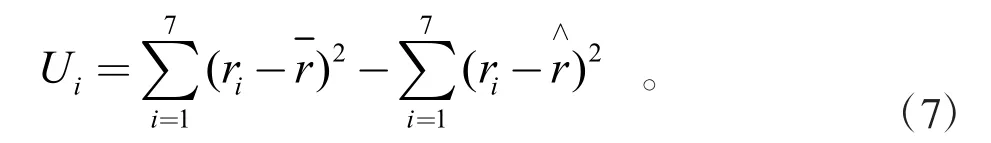
根据Ui值的大小作为自变量被引入线性回归方程后对方差的贡献。重复此步骤多次后,回归方程已无自变量可以剔除,同时也无新变量可以再被引入,此时构建出的字符识别模型为
F=-2.549×10-15+3.54x1-0.42x2+2.87x3+0.89x4+2.97x5-1.61x6+1.61x7+1.96x8-0.54x9-1.84x10+2.03x11+0.48x12+1.88x13+1.61x14+0.84x15+0.94x16。
3.3 基于神经网络的优化识别模型
根据公式(1)至公式(5)建立BP神经网络,对基于主成分分析和逐步回归算法建立的光学字符识别模型进行优化,得到的神经网络模型为
F=-2.55×10-15+3.52x1-0.41x2+2.64x3+0.89x4+2.91x5-1.63x6+1.61x7+1.96x8-0.51x9-1.87x10+2.02x11+0.41x12+1.83x13+1.62x14+0.81x15+0.91x16。
为了直观地看出通过字符识别模型预测出的数据,选取了前7个字符的预测结果显示,如图4所示。
图4 字符识别分布图
4 精度评价
将UCI数据集中70%的光学字符信息用于学习,30%的数据信息用于验证,通过离散型方程选取与每个字符均值距离最远的30%的数据,计算出每2个字符大致相交处的分界线B,计算过程如公式(8)所示

通过与字符的真实值进行比较,计算出每个字符的精度值,然后总和求均值Z,得到研究建立的字符识别模型精度Z为87.5%,各部分字符识别精度如图5所示。

图5 字符识别精度分析图
5 结束语
通过进行上述的实验研究,对识别精度的提高做出以下猜想:
本次实验是将异常数据进行替换,将其变成可用数据的预处理方法,是在尽量不更改数据集数量的情况下进行的,如果将异常数据直接删除,数据集变小,但精准度可能会提高。
在建立BP神经网络的过程中,提高学习的数据比例,变更成学习UCI数据集的80%或者更多,使得到的训练关系系数变得更加准确,进而提高识别的精度。
在今后的实验研究中将设计实验,检验以上2个猜想,提高光学字符识别的精度。
