基于弹幕文本挖掘的社交媒体KOL研究*
2022-12-22周忠宝朱文静郭修远王立峰
周忠宝,朱文静,王 皓,郭修远,王立峰
(1.湖南大学工商管理学院,湖南 长沙 410082;2.湖南大学新闻与传播学院,湖南 长沙 410082)
1 引言
随着我国文化事业的飞速发展,社交媒体关键意见领袖KOL(Key Opinion Leader)作为互联网时代文化产业的新生力量得到广泛关注。社交媒体KOL拥有大量忠实粉丝,能凭借着自身强大的号召力和影响力使内容在粉丝人群中拥有深入的渗透力。作为广告主和消费者的媒介者,KOL帮助品牌与消费者建立联系,为品牌推广带来可信度,因此备受广告主青睐[1]。但是,KOL行业的低门槛进入,使KOL人数日益增加。据卡思数据收录,我国各平台粉丝量在10万以上的KOL已经超过20万个,而且超半数的KOL营销数据都存在刷量造假行为,这些都会导致广告主无法仅从粉丝量级来分析KOL的商业价值。如何对KOL进行更全面的分析,成为了KOL营销亟需解决的问题。
社交媒体KOL营销的传播媒介多元化,其中视频因为具有更高的传播示能和内容密度,使用更为广泛。随着视频网站的发展,弹幕技术被广泛运用。与传统评论不同,弹幕是一种直接显示在视频上的滚动评论,有“视频时间”和“自然时间”2个维度。作为一种新型的即时互动的视频评论方式,弹幕的即时性使得观众可以超越时空限制,使人们独自观看视频时有一种很多人共同观看该视频并产生共同情绪与吐槽点的奇妙心理,这种心理促使观众更愿意参与到讨论中。人们观看弹幕视频获取信息、娱乐和社交联系[2],并且弹幕会影响观众感知[3,4],这为分析KOL提供了新的研究视角。通过对弹幕内容进行文本分析,不仅可以对弹幕的主题进行检测[5],还能分析观众的情感[6,7]。
本文通过对社交媒体KOL视频弹幕进行文本挖掘,使用动态主题模型和卷积神经网络CNN(Convolutional Neural Network)模型对弹幕丰富的语义信息进行主题和情感分析,构建一种新的KOL分析体系,从而帮助广告主找到粉丝群体符合品牌调性且具有正面影响力的KOL,更精准地进行KOL营销。本文围绕视频弹幕主要从以下3个方面进行研究:(1)针对弹幕的时间属性,对视频弹幕的时间属性进行描述性统计,从弹幕时间分布对观众的行为偏好进行刻画。(2)对弹幕文本进行动态主题分析,对弹幕内容进行主题识别以及随时间变化的细粒度主题词演化分析。(3)对含有推广的视频进行情感分析,分析观众对于视频中含有推广的情感倾向。
2 相关研究
2.1 主题模型
主题模型通过分析文本中的词来研究文档中的语义主题结构,从而实现对文本的组织和归纳[8]。在主题模型中,主题是一个语义层面的假设,一个主题是一系列词汇的概率分布,文档可以由一系列主题表示。隐含狄利克雷分配LDA(Latent Dirichlet Allocation)作为最经典的主题模型[9],目前已经被广泛应用于学术界和工业界。
但是,LDA忽视了语料库中文本的时间顺序,于是Blei等[10]提出动态主题模型DTM(Dynamic Topic Model)。DTM考虑了文档的先后顺序,假设主题随时间发生变化,该模型被证明是一个能够准确描述潜在主题及其动态变化的强有力工具。
传统的语言建模方法使用Dirichlet分布来处理词语分布的不确定性,但是Dirichlet分布对序列建模并不适用。为解决这一问题,DTM模型引入了高斯噪声,通过状态空间模型链接了每个主题的自然参数βt,k,其中βt,k表示时间切片t中主题k的自然参数。也就是说,在动态模型中通过连接高斯分布对组件随机变量序列进行建模,并将值映射为单纯形,将逻辑正态分布延伸至时间序列上的单纯形数据。
对于文档-主题概率分布θ,DTM模型使用平均值α的逻辑正态分布来表示概率分布的不确定性,其中各参数的含义如表1所示;同时通过式(1)所示的简单的动态模型捕获模型之间的顺序结构:
αt|αt-1~N(αt-1,δ2I)
(1)
将主题和主题概率分布连接在一起,即可有序地得到一组主题模型。一组有序语料在时间切片t上的生成过程可以表述为:
(1)生成主题分布:
βt|βt-1~N(βt-1,σ2I)
(2)构建动态模型描述主题随时间的变化:
αt|αt-1~N(αt-1,δ2I)
(3)对每篇文档:
①生成文档-主题分布参数:
η~N(αt,α2I)
②对文档中的每个词语:
a 生成文档-主题分布:
Z~Mult(π(η))

Table 1 DTM paramaeter information
b 生成词语-主题分布:
Wt,d,n~Mult(π(βt,z))
其中π(·)将多项自然参数映射为平均参数。如果去掉图1中的方向箭头,不考虑时间上的动态变化,整个流程可以看做一系列独立主题模型的集合。考虑时间上的变化后,时间切片t上的第k个主题是在时间切片t-1的第k个主题的基础上经过平滑的演变得到的。
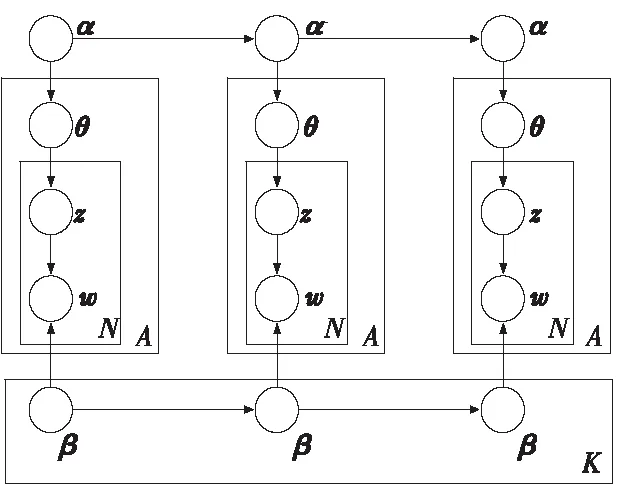
Figure 1 DTM model illustration
2.2 卷积神经网络
情感分析(Sentiment Analysis)是对文本中某个实体的观点的情感及态度的计算[11]。它利用自然语言处理、文本分析、机器学习和计算语言学等方法对带有情感色彩的文本进行分析、推理和归纳。情感分类作为情感分析技术的核心问题,其目标是判断评论中的情感取向。随着互联网评论数据的日益增多,传统基于词典的情感分析方法[12 - 14]和基于机器学习情感方法[15 - 18]已经不能高效处理海量评论的情感分类问题。近年来随着深度学习技术的快速发展,其在大规模文本数据的智能理解上表现出了独特优势,越来越多的研究人员青睐于使用深度学习技术来解决文本分类问题[19 - 24]。Socher等[21 - 23]在2011~2013年间提出了一系列基于递归神经网络的分类模型来解决情感分类问题,Kim[24]则将卷积神经网络运用于情感分类问题。实验结果表明,卷积神经网络的分类效果明显优于递归神经网络,卷积神经网络在语句级别的情感分类问题上表现优秀。
卷积神经网络是多层网络结构,主要结构按层次分卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully-Connected Layer)。模型的输入为按照文本中词语的顺序排列的词向量,卷积层通过多个卷积过滤器来发现输入文本中相邻多个词之间的局部特征,这些局部特征经过池化层得到卷积层中最重要的特征,并且保证对于不同长度的输入文本能够输出相同长度的特征。最后全连接层将所有局部特征结合变成全局特征,用来计算最后每一类的得分,得到最终的分类结果。
3 基于弹幕文本的KOL分析模型构建
3.1 弹幕数据爬取及预处理
相较于其他平台,哔哩哔哩弹幕视频网站(B站)视频因无广告、弹幕有趣、社群属性强等特点吸引了大量优质用户。此外B站内容更加垂直、粉丝质量高、KOL数据造假的现象少。综合以上优点,本文以B站为研究平台,实验使用Python语言爬取视频弹幕,具体思路如下所示:
首先将爬虫伪装成浏览器:为了防止爬虫被禁,需要设置头文件和Cookie文件。头文件信息比较容易找到,在Chrome的开发者工具中选择Network,刷新页面后选择Headers就可以查看到本次访问的头文件信息,头文件信息的旁边还有一个Cookies标签,其内容就是本次访问的Cookies信息。之后爬取网页的URL:根据视频av号获取弹幕cid,再按照固定格式拼接字符串得到数据请求URL。使用GET方式请求URL,然后与前面设置的头文件信息和Cookie信息一起发送请求,从而获取页面信息。为了避免频繁的请求导致返回空值,所以2次请求间隔设置为5 s。最后进行数据的存储与清洗:解析返回的xml弹幕数据,对原始数据进行去重清洗,以CSV的格式存储在本地。对不同视频循环执行以上操作,直到所有视频弹幕数据采集完成。
本文选择B站时尚区具有代表性的up主“机智的党妹”为研究对象,“机智的党妹”账号信息如表2所示,实验共爬取了“机智的党妹”143个视频的约50万条弹幕,数据更新时间截止到2019年11月2日。
爬取完弹幕数据后,需要对弹幕数据进行去停用词和切词处理。由于弹幕语言存在网络词汇较多、口语化及书写不规范等问题,而现有的分词词库不能满足本文的切词需求,因此本文人工建立领域词典来对弹幕文本进行分词处理。
本文在Jieba分词库的基础上,对弹幕和美妆领域相关词语进行收集后,通过人工筛选和整理获得3 611个该领域的常用词,并加入到基础分词库中,汇总成实验所需要的词典。部分分词词语如表3所示。
分词处理后对实验数据进行去停用词处理,本文整理了“中文停用词库”“哈工大停用词表”“四川大学机器智能实验室停用词库”和“百度停用词表”,形成本文的停用词表。
3.2 动态主题建模
实验以对数似然度作为评估依据确定主题模型主题数,通过对不同主题数的实验结果进行比较,图2是实验选择不同主题数对应的对数似然数值。由图2可以看出,主题数为3时出现了一个局部峰值,之后随着主题数的增加,对数似然数呈递增趋势,主题数为10时对应的对数似然数最大,之后随着主题数的增加,对数似然数呈递减趋势。综合考虑,主题数为3时实验概况性好、冗余度低。

Figure 2 Log likehood
确定好主题数后,进一步对弹幕数据进行时间片划分。本文将弹幕按照自然时间排序,将弹幕数据划分为10个时间片段,具体如表4所示。

Table 4 Time slice partition
3.3 主题识别与细粒度主题词演化
DTM模型中每个词w在时间切片t中对于主题k的贡献记作βt,k,w,该值随时间、主题和词的变化而变化。通过DTM建模,全部时间切片内的词语分布概率之和表示词语对主题的贡献度,主题k中词w的贡献度为P(w|k)。=∑βt,k,w。将P(w|k)值进行排序,即根据词w对文献研究内容的贡献度进行排序,人工判定最能体现文献研究内容的主题。
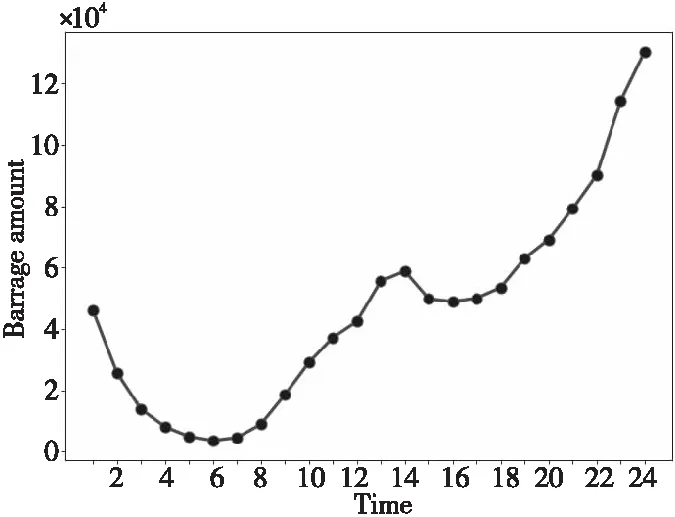
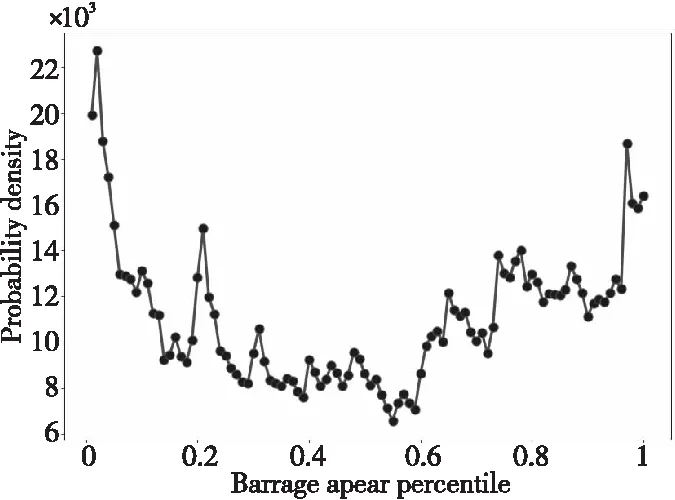
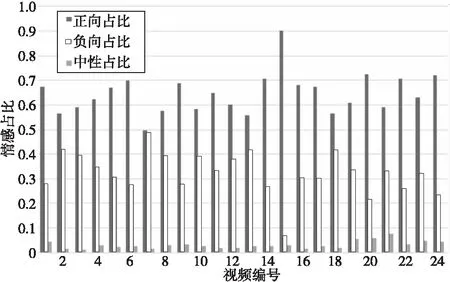
本文通过抽取关注度较高的词语对主题进行描述。词w的关注程度的变化可以通过相邻时间切片内的概率正差值进行计算,即βt,k-βt-1,k(1 3.4.1 构建情感词典 通用情感词典(例如知网情感词典和大连理工情感词典)所包含的情感词大多数是普通词语,然而弹幕文本普遍精简,且包含大量网络词汇,存在口语化和不规范的问题,所以使用通用情感词典往往不能覆盖弹幕文本中的情感,无法对弹幕文本的情感极性进行判断。例如,“被圈粉”“被种草”中的“圈粉”“种草”就表达了直接的正面情感,但由于“圈粉”“种草”这类网络用语并非传统情感词,所以无法通过传统词典对弹幕情感极性进行判断。基于此,本文在通用情感词典的基础上人工添加“圈粉”“种草”“有点尬”等弹幕中常见网络用语,形成适用于弹幕情感分析的正向词典、负向词典和中性词典。部分情感词如表5所示。 Table 5 Emotional dictionary 3.4.2 情感标注 文本情感标注主要目标是把弹幕标注成正向负向或中性3种情感,常用的打标方式有逐一打标、抽样打标和词汇正负向标注。考虑到实验数据样本量大,本文选用了词汇正负向标注的方法,使用3种词典进行文档标注,通过统计情感类别符号确定每条弹幕评论文本中各类情感词的个数,再使用式(2)计算弹幕的情感极性。 (2) 其中,Sentiment表示正、负、中3种元情感分类下的情感极性;Q表示情感词个数,Q正表示正向情感词的个数,Q负表示负向情感词的个数。当Sentiment=0时,表示弹幕文本不含有情感;当Sentiment=1时,表示弹幕文本含有正向情感;当Sentiment=2时,表示弹幕文本含有负向情感;当Sentiment=3时,表示弹幕文本含有中性情感。 3.4.3 卷积神经网络建模 由于卷积神经网络模型最早是用于图像识别,其输入是二维矩阵形式,因此在使用时需要将文本数据转换为二维数据矩阵后再作为模型的输入。假定数据中长度最长的弹幕包含a个词,xi∈Rk是该条弹幕中的第i个词对应的b维词嵌入向量。卷积神经网络的输入为由a个b维向量组合而成的a×b的二维数据矩阵。对于长度小于a的样本,本文使用word2vec向量化后使用零向量进行补充,对于长度大于a的样本,(a-1)个词采用word2vec向量表示,超出部分的所有词向量的均值填充在第a位。通过这一方式,可以使不同词在向量中均匀分布。本文的弹幕数据集中数据相对较短,因此将a设定为10,词嵌入向量设为160维,即b=160。 Figure 3 Proposed convolutional neural network model 本文的CNN模型结构如图3所示。卷积层都采用相同大小的卷积核来提取出文本的局部特征,考虑到弹幕文本的情感具有显著的特征,往往只需要通过几个特征词语便能判断其情感,因此池化层采用最大池化提取出每个特征图中最具代表性的特征。重复卷积池化操作,最后通过全连接层进行特征降维,降维后的数据进入分类层完成对弹幕情感的预测。 卷积核ω∈Rh×m在长为h的窗内进行卷积操作,输出的特征如式(3)所示: si=f(ω×αi:i+h-1+b) (3) 其中,b为偏置项,f(·)为激活函数。神经网络中有多种常用的激活函数,例如sigmod函数、tanh函数和ReLU函数等。由于ReLU函数具有加快训练收敛速度、防止梯度消失、增加数据矩阵稀疏性以减少过拟合的特点,因此本文采用ReLU函数作为激活函数,如式(4)所示: f(x)=max(0,x) (4) 本文首先对“机智的党妹”视频弹幕的“自然时间”属性和“视频时间”属性进行分析:将“自然时间”属性转化为24小时制,刻画弹幕在24小时内的分布情况;将“视频时间”属性转化为所在视频时间内的百分比,刻画弹幕在视频时间内的分布情况。 图4是“机智的党妹”弹幕“自然时间”24小时分布统计图,横坐标是24小时制时间,纵坐标是弹幕数量。由图4可以看出,观看党妹视频的人的数量从6点到13点呈上升趋势,12点到13点达到一个局部峰值;从13点到16点有小幅度回落;16点到23点逐步增加,23点达到整体的峰值;23点到5点开始逐渐下降,5点的观看人数最少。整体来看观众更偏好于晚上观看视频。 图5是“机智的党妹”弹幕“视频时间”的分布统计图,横坐标是弹幕出现在视频中的时间占此视频的比值,纵坐标是弹幕数量。由图5可以看出,视频时间内弹幕数量波动明显,视频开头的弹幕数量最多,结尾次之,视频之间出现几次小幅度弹幕峰值。由此可以分析,观众更偏爱在视频开头和结尾发送弹幕,视频中会出现几次弹幕“小高峰”。整体看“机智的党妹”视频的观众视频观看完整度高,粉丝粘性强,互动性高。 Figure 4 Natural time distribution of barrage Figure 5 Percentage distribution of barrage 由于弹幕词语偏短,本文将实验中卷积神经网络模型中的步长设置为1,卷积核的大小设置为5*5,同时为了防止特征图变小,padding设置为2。将最大池化设置为2*2以提取特征图上的显著特征。之后再进行相同的卷积池化操作,以完成对特征的进一步提取。最后经过全连接层降维后进入分类层得到最后的情感分类。考虑到弹幕情感分布很不均匀,所以实验设置权重交叉熵为142,以此提高对负向和中性标签的损失权重,为不平衡的数据分布做了一定的补偿。 本文按8∶2的比例划分为训练集与预测集,共选择了2 000份样本数据作为训练集。实验结果显示,该模型准确率达到94%。 4.3.1 主题结果 基于DTM模型,实验数据主要被分为3个主题大类,每个主题大类下选择概率最大的20个词表示,具体如表6所示。主题1主要是关于视频风格的内容,从主题词分析结果看,视频节奏欢快,轻松搞笑,易引起观众集体大笑;主题2主要是关于形象特征的内容,从主题词分析结果看,“机智的党妹”的形象既包含女性化形象,又包含男性化形象,人物形象方面可能存在变化;主题3主要与视频内容相关,从主题词分析结果看,观众不仅对“机智的党妹”所使用的化妆品感兴趣,还热衷于讨论视频中出现的食物、衣服等物品,从这点可以看出观众对“机智的党妹”的兴趣不只局限于美妆方面。 Table 6 Topic results 4.3.2 细粒度主题词演化 在不同时间,不同弹幕主题的主题词会发生变化。通过细粒度主题关键词分析,可以得到不同时期“机智的党妹”视频弹幕的主题词变化。3个主题分类中,主题1没有发生很大变化,说明视频风格一直以轻松搞笑的风格为主。主题2和主题3的主题词存在变化。 表7是主题1随时间变化的细粒度主题词演化。由结果可以看出,各个时间切片的主题词相似,没有明显变化。每个时间段都出现了“哈哈哈”“笑”“可爱”等主题词,这表明“机智的党妹”视频风格轻松愉悦,视频中存在大量笑点。 表8是主题2随时间变化的细粒度主题词演化。由结果可以看出,不同时间切片的主题词存在差异。在前8个时间切片中,观众对“机智的党妹”的形象评价以“好看”“可爱”“妹子”“小姐姐”等女性化称呼为主;在后2个时间切片中,主题词开始出现“党哥”“好帅”“老公”等称呼,说明“机智的党妹”的个人形象特征存在变化,前期以女性化为主,后期出现男性化特征。 表9是主题3随时间变化的细粒度主题词演化。由结果可以看出,不同时间切片的主题词存在差异。虽然“机智的党妹”是一个美妆类up主,但是观众弹幕所讨论的话题并不局限于美妆领域。“好吃” “买”“同款”等词说明粉丝在观看党妹视频时,不仅会关注视频中的美妆类产品,对于视频中出现的食物等其他产品,粉丝也表现出强烈的兴趣和购买意愿。“bgm”“表白”“新年快乐”“生日快乐”等词说明观众不仅是把“机智的党妹”当成一个屏幕里面的人,还把她当成一个乐于分享的朋友,粉丝忠诚度高。后期出现的“沾”“喜气”“中奖率”等词,说明“机智的党妹”在视频中增加了粉丝福利,而观众对于这种福利表现积极,参与度高,这也可能是其后期弹幕内容发生变化的原因。 Table 7 Topic words evolution of Topic 1 Table 8 Topic words evolution of Topic 2 Table 9 Topic words evolution of Topic 3 本文从“机智的党妹”143个视频中筛选出了24个含有广告的视频,使用CNN模型对这24个视频的弹幕进行情感分析。表10是24个含有推广视频的整体情感占比均值,由表10可知,正向情感均值占比约为0.65,负向情感均值占比约为0.32,中性情感均值占比约为0.03。正向情感占大多数。 Table 10 Sentiment analysis results 图6是24个含有推广视频的弹幕情感极性分析的百分比堆积柱形图。由图6可以明显看出,观众对于视频中含有推广的态度,持正向情感多于持负向情感,说明观众对于视频中含有产品推广的行为,大部分是理解与支持的。中性情感占少数。 Figure 6 Emotional polarity stacked bar chart 本文以社交媒体B站为研究平台,利用弹幕这一用户生成内容,以美妆类KOL“机智的党妹”为例,对其视频弹幕进行动态主题分析和情感分析,从而帮助品牌从文本挖掘视角对KOL进行全面了解,为品牌找到合适的KOL提供数据参考。 从分析结果看,弹幕的“自然时间”和“视频时间”可以很好地刻画观众的观看行为特征,为广告主应该在何时投放广告提供参考;动态主题分析既可以从整体刻画观众的弹幕主题,也可以从细粒度刻画不同时间的主题词演化,帮助广告主具体了解不同KOL的粉丝群体特征,更加精准地进行广告投放;情感分析可以分析观众对于KOL合作推广的态度,避免因粉丝抵触推广行为而降低品牌好感度。 因为弹幕文本含有大量网络语言,传统文本挖掘方法不能完全适用对弹幕的文本分析,所以之后的工作可以从以下方面改进:首先构建更为专业的弹幕领域的分词词典,以便对弹幕文本进行更好的分词处理,为之后的分析提供更好的数据支持。其次,构建更为专业的弹幕领域的情感词典。弹幕文本的用语不规范导致同一个词在不同语境中有不同的情感极性,这就需要更为细分的情感词典为情感分析提供参考。此外,弹幕数据还可以作为舆情分析的数据源,不仅能帮助了解观众在观看视频时讨论的主题变化,还能监控观众的情感变化,对KOL和品牌双方都有借鉴意义。3.4 情感分析

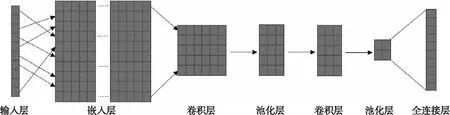
4 实验与结果分析
4.1 实验数据描述
4.2 实验设置
4.3 动态主题分析




4.4 情感分析

5 结束语
