融合双层注意力机制的属性网络节点嵌入*
2022-12-22杨凡亿马慧芳闫彩瑞
杨凡亿,马慧芳,2,闫彩瑞,宿 云
(1.西北师范大学计算机科学与工程学院,甘肃 兰州 730070;2.桂林电子科技大学广西可信软件重点实验室,广西 桂林 541004)
1 引言
网络在现实世界中无处不在,其中属性网络近年来引起了学者的广泛关注。与仅提供拓扑结构的普通网络相比,属性网络除了具有复杂的结构关联,节点也拥有与结构互补的丰富属性信息,有效地利用这些属性信息可以使网络分析受益。现有的研究表明节点的属性可以反映并影响其社区结构[1,2]。因此,面向属性网络的研究方兴未艾。典型的属性网络包括学术引文网络和社交网络等。在学术引文网络中,不同文章之间引用关系形成一个网络,其中每个节点代表文章,并且每个节点附着着和文章主题相关的大量文本信息;在社交网络中,除了用户之间密切的交流外,用户的个人资料也可以作为属性信息。
网络嵌入作为网络分析的基本工具,是近年来的研究热点。该研究是在保留近似的同时学习网络中节点的低维表示,然后用于节点分类[3]、节点聚类[4]和链接预测[5]等下游任务。例如,基于随机游走的DeepWalk[6]采用截断随机游走方式,从网络中每个节点出发,游走遍历网络中的其他节点得到若干节点序列,根据窗口获取采样节点的上下文节点,然后运用skip-gram模型最大化随机游走序列的似然概率。LINE(Large-scale Information Network Embedding)算法[7]在网络上定义了一阶相似度和二阶相似度,并最小化表示相似度与实际相似度的KL散度得到节点的表示。node2vec[8]为了挖掘网络结构的特性,引入2个超参数控制随机游走的策略,将得到的特定节点序列输入到skip-gram模型中以学习节点表示。上述经典方法只考虑了网络的拓扑结构信息,没有将节点的属性信息考虑进去。研究人员面向属性网络已提出各种各样的嵌入模型。针对属性网络得到的节点低维表示,可以使具有拓扑和属性相似的节点在嵌入空间彼此接近。经典的工作包括:Yang等人[9]在矩阵分解的框架下,提出TADW(Text-Associated DeepWalk)算法,将节点的文本特征引入到网络表示学习中。Gao等人[10]提出深度属性网络嵌入DANE(Deep Attributed Network Embedding)算法,通过捕捉结构与属性的高度非线性关联,在拓扑结构和节点属性上保持近似性特征,同时该算法可以从拓扑中学习结构和节点属性的一致和互补表示形式。
作为人类不可或缺的复杂认知功能之一,注意力机制[11]是指人在关注一些信息的同时可以忽略另一些信息的选择能力,已在众多研究领域[12-14]得到了广泛应用。本质上,注意力机制通过对模型中不同部分赋予不同权重,获取模型中更加重要的和关键的信息,从而优化模型并做出更为准确的判断。为了充分利用节点属性信息以及隐含在节点-属性中的语义信息,本文结合注意力机制,提出一种融合双层注意力机制的属性网络节点嵌入算法NETA(Node Embedding combining Two-level Attention mechanism on attributed network)。该算法的主要步骤如下:首先,构造结构-属性交互二部图,捕获直接邻居和间接邻居;其次,设计节点级注意力,考虑节点邻居的相对重要性,分别聚合直接邻居表示和间接邻居表示;最后,基于语义级注意力融合2种嵌入表示得到最终嵌入。在人工数据集和真实数据集上设计了不同的实验来验证本文算法的有效性。
2 问题定义
令G=(V,E,F)表示属性网络,其中V={v1,v2,…,vn}表示节点集合,E⊆V×V表示边集,F={f1,f2,…,fm}表示属性集合,n为属性网络中节点总数,m为属性网络中属性总数。矩阵An×n为拓扑结构邻接关系矩阵,若节点vi与节点vj之间存在边,则Aij=1,否则Aij=0。矩阵Qn×m表示节点-属性关系矩阵,若节点vi具有属性fj,则Qij=1,否则Qij=0,Qi是节点vi的属性向量。
给定一个属性网络G=(V,E,F),属性网络嵌入的目标是学习一个映射函数,将图G中的每个节点映射到一个低维的向量空间中,使得具有拓扑和属性相似的节点在低维空间彼此接近。
为了描述清晰起见,将本文主要用到的符号及其含义总结如表1所示。
3 融合双层注意力机制的属性网络节点嵌入NETA
3.1 结构-属性二部图
结构-属性交互二部图通过“节点-属性-节点”的跳转方式将2个节点联系起来,能够清晰地捕获节点与属性的关系。值得注意的是,在“节点-属性-节点”的跳转方式上,起始节点可能最终会跳转到其非拓扑邻居节点上。为了和拓扑结构中的直接邻居进行区分,本文将其称为基于属性关系的间接邻居。具体定义如下所示:

Table 1 Notations and meanings
定义1(结构-属性二部图) 结构-属性二部图用SAG=(V∪F,ESAG)表示,其中ESAG⊆V×F。则节点-属性关系矩阵Qn×m即对应于该二部图的邻接矩阵Qn×m。对于∀vi∈V,∀fj∈F,若节点vi与属性fj之间存在连边(即节点vi边包含属性fj),则Qij=1,否则Qij=0。

Figure 1 Overall framework of node embedding combining two-level attention mechanism on attributed network

3.2 节点级注意力机制
属性网络中每个节点的邻居扮演着不同的角色,并且在学习节点嵌入中表现出不同的重要性。本节利用注意力机制学习网络中每个节点邻居的重要性,并整合这些有意义的邻居表示以形成节点的嵌入。本文中,节点vi的邻居包括基于拓扑结构的直接邻居和基于属性关系的间接邻居。基于属性关系的间接邻居和基于拓扑结构的直接邻居相类似,为了节约篇幅,下文中均以基于拓扑结构的直接邻居为例进行说明。
为了能够获得可靠的节点嵌入,本文首先对节点vi的初始特征进行变换,如式(1)所示:
h′i=W1hi
(1)
其中,hi和h′i分别表示节点vi的初始特征向量和变换后的向量表示,W1是所有节点共享的可学习的变换权重矩阵,是模型需要学习的一个参数。将节点的初始特征通过W1进行变换可以得到比初始特征相对好的节点表示,同时可以将节点的向量维度转换为所需要的维度。
然后,使用注意力机制来学习节点vi邻居的重要性,并通过聚合这些有着不同权重的邻居节点以得到节点vi新的特征表示。给定节点vi,通过注意力机制[11]学习节点vj对节点vi的重要性权重αij,其计算方法如式(2)所示:
αij=softmaxj(attnode(h′i,h′j))=
(2)
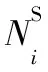

(3)
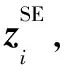
(4)

3.3 语义级注意力机制

(5)
其中,attsem是一个深度神经网络,表示语义级注意力。
(6)
其中,W2是权重矩阵,b是偏置向量,q语义级注意力向量。同样地,可以得到结构-属性二部图的重要程度wAE。进一步通过softmax函数进行归一化,可得到拓扑结构的重要性权重,如式(7)所示:
(7)
(8)
为了提高所提算法的性能,本文增加一个全连接层用于分类,并利用部分有标签的节点算法对进行优化,设计交叉熵作为损失函数,如式(9)所示:
(9)
其中,VL是拥有标签的节点集合,Yi为节点vi的标签,zi为节点vi的最终向量表示,C是分类器的参数。最后通过反向传播对模型进行优化,学习节点的向量表示。
3.4 双层注意力属性网络节点嵌入算法步骤
双层注意力属性网络节点嵌入方法步骤如算法1所示。
算法1双层注意力属性网络节点嵌入算法NETA
输入:属性网络G=(V,E,F),节点初始特征{hi,∀vi∈V},多头注意力数K。
输出:最终节点表示Z。
步骤1构造结构-属性交互二部图SAG
步骤2特征转换:∀vi∈V,h′i←W1·hi;
步骤3 fork=1..Kdo:
步骤4forvi∈Vdo:
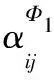
步骤8end
步骤9 end
步骤10根据式(7)计算直接邻居和间接邻居的重要性权重βSE和βAE;

步骤12计算交叉熵损失:L=-∑vi∈VLYiln(C·zi);
步骤13反向传播和更新参数;
步骤14返回:最终嵌入Z。
4 实验及结果分析
本节通过在数据集上进行广泛实验,来回答以下研究问题,以验证本文算法的有效性。
问题1NETA在节点分类和节点聚类中性能如何?
问题2NETA对参数的敏感程度如何?
问题3NETA的两级注意力机制对算法的性能贡献如何?
本节首先介绍实验所需的数据集,其次介绍对比算法和实验设置,最后对实验结果进行分析并结合案例分析阐释本文算法的有效性。所有代码都是使用Python3.7实现。
4.1 实验数据集
实验数据集包括真实数据集和人工数据集。表2和表3分别给出了真实数据集的统计信息和人工数据集中的参数及其含义。
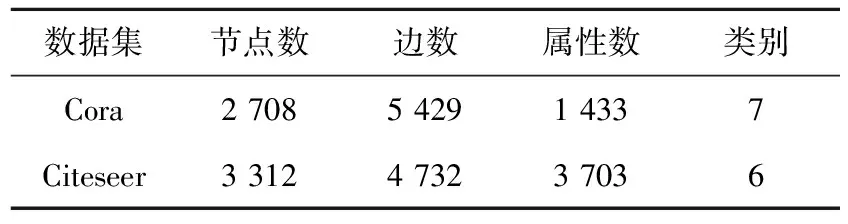
Table 2 Statistics of real-world datasets

Table 3 LFR parameters and meanings
Cora(https://linqs.soe.ucsc.edu/data)是一个科学论文的引文网络,其中共有2 708篇论文(节点),5 429对论文之间的引用关系(边),分为7个研究领域。每篇论文均用一个0/1值的词向量描述,该词向量指示论文中是否存在相应的词,共包含1 433个单词,并视为每篇论文的属性。
Citeseer(https://linqs.soe.ucsc.edu/data)是一个引文网络数据集。它包含6个研究领域的3 312篇研究论文,含有4 732条边。每篇论文均用一个0/1值的词向量描述,该词向量指示论文中是否存在相应的词,共包含3 703个单词,并视为每篇论文的属性。
人工数据集是使用LFR 基准[15]生成的LFR-1和LFR-2。在人工数据集的每个真实类别中,节点均附有随机生成的相似属性,且2个不同类别之间的属性有差异。LFR参数符号及其含义如表3所示,其具体参数的设置如下所示:
LFR-1:N=20000,k=10,max_k=50,μ=0.1,τ1=2,τ2=1,min_c=20,max_c=50,On=0,Om=0。
4.2 对比算法
为评估本文算法NETA的性能,选取以下2类算法进行对比,第1类算法只考虑网络拓扑结构而没有考虑节点的属性信息,即DeepWalk和node2vec。第2类算法融合了网络拓扑结构和节点属性信息,即TADE和DANE。具体描述如下所示:
(1)DeepWalk[6]:通过从每个图节点开始随机游走生成节点序列来模拟句子,这一系列节点序列组成了“语料库”。DeepWalk 设定了背景窗口的大小,然后将随机游走得到的“语料库”输入skip-gram模型,得到每个图节点的图嵌入表示。
(2)node2vec[8]:为了挖掘网络结构的局部特性和全局特性,引入2个超参数p和q控制随机游走的策略,得到特定的节点序列后也运用skip-gram模型学习节点表示。
(3)TADE[9]:在矩阵分解的框架下,将节点的文本特征引入到网络表示学习中。
(4)DANE[10]:该算法可以捕捉到结构与属性的高度非线性关联,并在拓扑结构和节点属性上保持近似性特征。
对于DeepWalk和node2vec,窗口大小设置为10,步长为80,步数为10。对于其余的对比算法,其参数设置遵循原始论文,最后将节点表示的维数设置为64。
4.3 实验结果与分析
4.3.1 节点分类和节点聚类(问题1)
为了验证本文算法NETA的性能,将NETA得到的节点表示分别用于节点分类和节点聚类任务。在节点分类任务中,采用K近邻KNN(K-Nearest Neighbor)(K=7)分类器进行节点分类。本文使用Macro-F1和Micro-F1作为评价指标。表4给出了算法运行10次的平均结果。在节点聚类任务中,采用K-Means聚类算法进行节点聚类,将K-Means的簇数设置为每个数据集的类别数,使用归一化互信息NMI(Normalized Mutual Information)和调整兰德系数ARI(Adjusted Rand Index)作为评价指标。由于K-Means的性能受初始簇中心的影响,因此将本文算法重复运行10次,并在表5中给出了平均结果。
从表4和表5中可以看出,在节点分类和节点聚类任务中,本文算法的效果相比其他对比算法均为最优。在分类任务中,针对2个数据集而言,TADE、DANE和本文算法NETA均优于DeepWallk和node2vec,这在一定程度上表明,网络中节点的属性可以为网络嵌入提供较好的支持,将网络拓扑结构和节点属性信息融合之后,网络嵌入的效果有了较大提升,这点在表5中也有体现。其次,本文算法NETA在2个数据集上均优于TADE和DANE,这说明捕获节点的重要性和节点-属性的重要性对网络嵌入是有益的,不同的节点在进行嵌入表示时应该有着不同的重要程度。
4.3.2 参数敏感性分析(问题2)
在数据集Cora,Citeseer和LFR-1上对参数的敏感性进行分析,研究不同参数对本文算法NETA的影响。
(1)最终节点嵌入的维度。
本文算法NETA的分类效果受最终的节点嵌入向量z维度的影响。本节在3个不同数据集上对不同维度的节点嵌入向量z进行测试,实验结果如图2所示。可以看出,在Cora和Citeseer数据集上,本文算法NETA的性能在维度为64时效果最好,后续随着维度的继续增加,NMI值开始降低,算法性能也随之下降;在LFR-1人工数据集上,当最终嵌入维度为128时,本文算法NETA性能最好,后续同样随着维度的增加,算法性能也下降。原因是NETA需要一个合适的维度来编码信息,更大或者更小的维度可能会使信息不充分或者带来冗余,导致效果不佳。
(2)语义级注意力向量维度。
语义级注意力的性能受语义级注意力向量的影响,本节在3个不同的数据集上对不同维度的语义级注意力向量进行测试,实验结果如图3所示。

Table 4 Performance comparison of node classification

Table 5 Performance comparison of node clustering
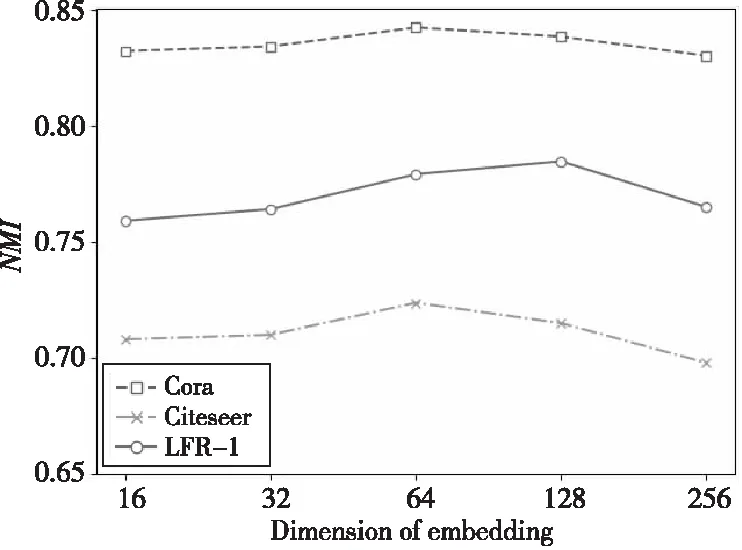
Figure 2 Effect of dimension of embedding on NMI

Figure 3 Effect of the semantic-level attention vector dimensionality on NMI
可以看出,在3个数据集上,当注意力向量的维度均在128时,本文算法NETA的性能最好。之后,算法性能开始降低,这可能是由于过拟合引起的。
(3)多头注意力机制数量。
为测试多头注意力机制的效果,本节在3个不同的数据集上设置不同K值进行测试,当K=1时多头注意力机制退化为单头注意力机制,实验结果如图4所示。从图4中可以看出,随着K值的增加,本文算法NETA在3个数据集上的性能都得到了提升,当K=8时算法性能达到最好。

Figure 4 Effect of number of multiple attention mechanism on NMI
4.3.3 注意力机制分析(问题3)
在学习节点的嵌入表示时,本文考虑了不同类型的邻居及其重要性,并为其分配了不用的权重。为了更好地理解权重的意义,本节设计案例对节点级注意力和语义级注意力进行分析。
(1)节点级注意力机制。
以Cora数据集为例,将节点P2583及其邻居表示为图5,它们的注意力权重如图6所示。P2853、P1423和P2135表示神经网络领域的论文;P378和P1173表示概率方法领域的论文;P2337表示基于案例领域的论文。从图6可以看到,表示神经网络领域论文的节点的邻居节点权重较大,其他领域论文的节点的邻居节点权重较小。其中,节点P2583在节点级上有着最大的注意力权重,这说明节点本身在嵌入中起着最重要的作用。这是合理的,因为表示一个节点,最重要的是节点自身的信息,而通常将邻居的信息视为一种补充信息。此外,节点P1423和P2135有着第2和第3的注意力权重,因为它们也表示神经网络领域的论文,可以为识别P2583的类别做出重要贡献。其余邻居的注意力权重较小,因为它们所表示的论文不属于神经网络领域并且不能很好地为识别P2583做出一定的贡献。根据上述分析,可以看到节点级的注意力权重可以区分邻居之间的重要程度,并为一些有意义的节点分配较高的权重。

Figure 5 Neighbors of P2583 in topology

Figure 6 Weight distribution of neighbors of P2583
(2)语义级注意力机制。
为了分析邻居类型对节点表示的重要性,本文对比了仅使用某一种邻居类型进行节点表示的结果及该邻居类型的注意力权重,结果如图7所示。从图7中可以看出,仅考虑单独邻居类型的节点表示结果与该邻居类型的注意力权重成正比,由此可见,本文算法能够较好地学习到不同邻居类型对节点表示的重要性。

Figure 7 Attention weight of two types of neighbors
4.3.4 注意力机制消融分析(问题3)
为了分析节点级注意力和语义级注意力对本文算法的贡献,本节设计了该算法的2种变体。首先变体1仅考虑语义级注意力(NETA-N),并为每个节点的邻居分配相同的权重;变体2仅考虑节点级注意力(NETA-S),并认为拓扑结构和结构-属性二部图的重要程度相同,最后以本文算法NETA为基准,在Cora数据集上分别进行了节点分类和节点聚类任务,表6为3种算法执行10次的平均结果。

Table 6 Performance comparison of NETA and variants
从表6中可以看出,首先,不考虑节点级注意力(NETA-N)或者不考虑语义级注意力(NETA-S)时,性能都比基准算法NETA差,这说明对节点级注意力和语义级注意力建模是很有必要的。其次,通过比较NETA-N和NETA-S可以得知,在不考虑节点级注意力时本文算法性能下降比不考虑语义级别时算法性能下降要多一些,这说明节点级注意力相比语义级注意力更加重要,因为节点级注意力对节点的邻居根据重要程度分配不同的权重,其包含的信息更加有助于节点的表示。
5 结束语
本文设计了一种融合双层注意力机制的节点嵌入算法来有效实现属性网络的嵌入。首先将节点的直接邻居和间接邻居利用注意力机制进行表示;然后聚合直接邻居的重要性和间接邻居的重要性以生成节点的最终嵌入。在真实数据集上的大量实验验证了本文算法NETA的有效性。但是,在构建结构-属性二部图时,本文仅考虑了节点间是否拥有相同属性,并未考虑节点拥有相同属性的数量。其次,在结构-属性二部图上进行的跳转仅考虑了邻居节点对嵌入的贡献,并未考虑中间节点的影响,这将是下一步需要研究的问题。
