基于全局注意力的室内人数统计模型*
2022-12-22张长伦王恒友
李 静,何 强,张长伦,3,王恒友
(1.北京建筑大学理学院,北京 100044;2.北京建筑大学大数据建模理论与技术研究所,北京 100044;3.北京建筑大学北京未来城市设计高精尖创新中心,北京 100044)
1 引言
随着深度学习的不断发展和进步,目标检测也取得了令人瞩目的进展,广泛应用于机器人导航、智能视频监控、工业检测和航空航天等诸多领域,在人脸识别、行人检测和人群计数等任务中起着至关重要的作用。与传统的室内人数统计方法相比,利用目标检测进行人数统计越来越多地被用在人工智能监控中,比如考场人数统计和会议人数统计。但是,由于室内的监控一般都是俯拍机位,在一些大型室内场景中,俯拍下的人头都很小,五官较模糊,影响了检测效果,因此如何提高室内人数统计的准确率是近年来的一个研究热点。
目前,基于深度学习[1-4]且应用前景[5,6]比较广阔的目标检测算法[7-9]有了很大的进步,常见的一阶段目标检测算法有YOLO(You Only Look Once)系列[10-12]和SSD(Single Shot multibox Detector)[13]等。这类算法效率较高,但精度略低。常见的两阶段目标检测算法有Fast R-CNN[14]、SPP-Net(Spatial Pyramid Pooling Net)[15]、Corner-Net[16]、Faster R-CNN[17]和Mask R-CNN[18]等。虽然两阶段算法的精度更高一些,但算法效率较低。人数统计需要满足一定的实时性,所以一阶段目标检测算法更适合进行人数统计。
近些年来,用目标检测进行人数统计的研究取得了一定的突破,由于人数统计最大的困难在于目标过小或者特征不明显,所以如何更好地提取特征信息是人数统计研究的重点。2012年钱鹤庆等[19]提出一种基于人脸检测的人数统计方法,利用AdaBoost算法和跳帧检测方法进行实验,最终检测效果和统计速度都有提升;2019年陈久红等[20]通过改进R-FCN(Region-based Fully Convolutional Network)网络大大提高了目标检测算法对小目标的识别能力,准确率有较大的提升;鞠默然等[21]针对小目标检测率低、虚警率高等问题,提出了改进YOLOv3的模型结构,结果显示改进后的模型结构对小目标的召回率和准确率都有明显提升。结合以上文献,本文提出了一种基于全局注意力的室内人数统计模型。
本文的主要贡献如下:
(1)自建室内人群检测数据集,并利用聚类算法对锚框进行优化。
(2)引入注意力机制CA(Coordinate Attention)[22]模块对YOLOv3的特征提取网络进行改进,将CA模块与ResNet[23]模块相结合,根据不同的结合方式,组成2种不同的CA-ResNet模块,依次替换传统YOLOv3的残差模块,检测不同结合方式对算法性能带来的影响,以此提取更多的特征信息,提高模糊或者较小目标的检测精度。
(3)对CA模块进行改进,使其能够更好地从网络中提取全局的特征信息。
在自建室内人群检测数据集上训练新模型,结果表明改进后的YOLOv3算法能够提取更多重要特征,测试的召回率和平均精度有明显提升。
2 背景知识
2.1 YOLOv3算法简介
YOLOv3算法以YOLOv1和YOLOv2为基础,在YOLOv2提出的骨干网络Darknet-19的基础上引入了残差模块,并进一步加深了Darknet-19网络,改进后的骨干网络有53个卷积层,命名为Darknet-53。另外,YOLOv3借鉴了特征金字塔网络的思想,从不同尺度提取特征进行目标检测,在保持速度优势的前提下提升了预测精度,尤其是加强了对小目标的识别能力。YOLOv3算法以Darknet-53网络作为主干网络,同时与多尺度预测进行结合,网络结构如图1所示。
Darknet-53借用了ResNet的思想,在YOLOv2提出的骨干网络Darknet-19中加入了残差模块。每个残差模块由2个CBL单元和1个快捷链路层构成,其中,CBL(Convolutional_Batch Normalization_Leaky ReLU)单元包含卷积层、批正则化BN(Batch Normalization)层和Leaky ReLU[24]激活函数,这样有利于解决一些深层次网络的梯度问题。Darknet-53的网络结构一共包含53层卷积层,1,2,8,8和4代表有几个重复的残差模块,YOLOv3中没有池化层和全连接层,网络的下采样是通过设置卷积的步长为2来实现的,图像经过该卷积层之后尺寸就会减小一半。

Figure 1 YOLOv3 network structure
2.2 注意力机制CA模块
CA模块是一种灵活且轻量的注意力机制,普通的通道注意力机制,如SE-Net(Squeeze and Excitation-Network)[25]中的SE模块,是通过学习的方式来自动获取每个特征通道的重要程度,然后依照重要程度增强有用的特征并抑制对当前任务用处不大的特征,从而实现特征通道的自适应校准,但是此方法并没有充分利用全局上下文信息,通常会忽略位置信息,且增加了整个网络的计算量,SE模块结构如图2a所示。而CA将位置信息嵌入到通道注意力中,如图2b所示,分别对水平方向和垂直方向进行平均池化得到2个一维向量,在空间维度上拼接和1×1卷积来压缩通道,再通过BN层和非线性激活函数来编码垂直方向和水平方向的空间信息,接下来分割,再各自通过1×1卷积得到输入特征图一样的通道数,最后把空间信息通过在通道上加权的方式融合。这样既可捕获跨通道的信息,也可保留精确的位置信息。将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,可以互补地应用于输入特征图中增强感兴趣的目标的表示,CA模块结构如图2b所示。

Figure 2 Attention mechanism module
3 基于全局注意力的人员检测模型
3.1 自建室内人群检测数据集
在传统YOLOv3使用的常规数据集,如Pascal VOC(Visual Object Classes)数据集和Microsoft COCO(Common Objects in COntext)数据集,可检测的目标种类过多,包含人头的图像过少,甚至有些过于模糊或太小的人头并没有标注出来,因此在常规目标检测数据集上的检测效果并不理想,需要有针对性地制作数据集完成训练和检测任务。本文制作室内人群检测数据集的方法如下:
(1)利用Python网络爬虫技术从必应和百度网站爬取包含室内场景人群的图像,部分示例如图3所示。

Figure 3 Several images in the static dataset
(2)搜集北京建筑大学不同教室不同时间的监控视频,视频大小共20 GB,格式为MKV,本文将视频以1/8 fps的标准转换成相应的图像序列,部分示例如图4所示。

Figure 4 Several images in the dynamic dataset
(3)为了丰富数据集,对获得的所有图像进行数据增强,将经过人工筛选得到符合要求的图像组成数据集,共1 000幅图像,然后将1 000幅图像中的所有人头均采用LabelImg进行手工标注,标注效果如图5所示。
Figure 5 Annotation effect
3.2 聚类候选锚框
对于选择锚框的形状,YOLOv2已经开始采用K-means聚类得到先验框的尺寸。传统YOLOv3延续了这种方法,使用K-means算法对训练集中所有样本的真实框聚类,得到具有代表性形状的宽和高(维度聚类)。
利用K-means算法对自建数据集所有样本真实框(Ground Truth)的宽和高进行聚类,得到先验框大小。关于锚框数量,原YOLOv3的网络结构最终输出3个尺寸的特征图,所以取了9个锚框。在自建数据集上这9个先验框的大小是:(12×21),(20×37),(33×56),(44×93),(72×117),(74×211),(115×164),(124×277),(207×313)。
3.3 CA-ResNet模块设计
为了使YOLOv3能够获取更多特征信息,增强对模糊或者较小目标的检测能力,本文改进了YOLOv3算法的特征提取网络,将CA模块与ResNet模块相结合,根据不同的结合方式组成2种不同的CA-ResNet模块,分别记为CA-ResNet A和CA-ResNet B,来替换传统YOLOv3的残差模块。CA-ResNet模块改进的基本思想是捕获跨通道的信息,并不是每个通道都对信息传递非常有用,因此可通过对这些通道进行过滤来得到优化后的特征,帮助YOLOv3更加精准地定位和识别感兴趣的目标,提升检测精度。
CA-ResNet系列模块均由ResNet模块和CA模块构成。传统的ResNet模块结构如图6所示,改进后的2种CA-ResNet模块如图7所示,用CA-ResNet模块替换传统YOLOv3的残差模块,由于改进后的Darknet-53网络结构增加了卷积层,特征细节会有所丢失,因此为了更好地进行高层信息与低层信息的特征融合,本文对YOLOv3进行了改进,改进后的CA-ResNet-YOLOv3的网络结构如图8所示。

Figure 6 ResNet module

Figure 7 CA-ResNet module

Figure 8 Network structure of CA-ResNet-YOLOv3
3.4 CA模块改进
CA模块中使用了平均池化来对数据进行下采样,这样既可以保留更多的图像背景信息,强调对整体特征信息进行下采样,也可以更大程度上减少参数,并且加强信息的完整传递。由于池化丢失的信息太多,虽然最大池化和平均池化都对数据进行下采样,但是最大池化更像是进行特征选择,选出分类辨识度更好的特征,保留更多细节特征。因此,本文采用平均池化与最大池化并行的连接方式,这样设计比使用单一的池化丢失的信息更少,改进的模块称为CA1(Coordinate Attention 1),其结构如图9所示。

Figure 9 CA1 module
4 实验设计
本文将进行4组对比实验来验证改进的效果:(1)将CA-ResNet A模块和CA-ResNet B模块嵌入传统YOLOv3算法的网络结构中,得到CA-ResNet A-YOLOv3算法和CA-ResNet B-YOLOv3算法,将这2个算法在自建室内人群检测数据集上进行实验,对比传统YOLOv3模型的检测性能,以检验CA模块嵌入残差模块中不同位置所带来的性能变化;(2)用GC(Global Context)[26]模块和CA1模块替换图7b中的CA模块,组成GC-ResNet B模块和CA1-ResNet B模块,嵌入YOLOv3的残差模块中,得到GC-ResNet B-YOLOv3和CA1-ResNet B-YOLOv3,对比不同注意力模块对YOLOv3算法性能的影响;(3)在自建室内人群数据集上用传统YOLOv3算法和CA1-ResNet B-YOLOv3算法进行对比实验,从评价指标的结果和检测图像的效果2方面来检验改进后的YOLOv3算法的性能;(4)将所提的CA1-ResNet B-YOLOv3算法与传统YOLOv3算法、SSD算法以及鞠默然等[21]改进的YOLOv3算法在自建人群检测数据集上进行对比实验。
4.1 评价指标
本文采用目前主流的目标检测算法的评价指标:准确率Precision、目标召回率Recall和均值平均精度mAP。
准确率Precision指算法预测为正的样本中,真实正样本的比例,一般用来评估算法的全局准确程度,其定义如式(1)所示:
(1)
召回率Recall指在原始样本的正样本中,最后被正确预测为正样本的概率,其定义如式(2)所示:
(2)
本文以室内人群检测为例,TP为正确检测出的人数,FP为误检人数,FN为漏检人数。
mAP是每个类别AP(Average Precision)的平均值,AP是P-R曲线下的面积。以召回率为横坐标,准确率为纵坐标,绘制P-R曲线,利用积分可求出mAP的值,其定义如式(3)所示:
(3)
其中,c表示类别数,p表示Precision,r表示Recall,p(r)是一个以r为参数的函数。
虚警率=1-Precision
(4)
漏警率=1-Recall
(5)
因此,准确率Precision值越大则虚警率越小,召回率Recall值越大则漏警率越小,mAP用于衡量算法好坏,值越大说明其识别效果越好。
4.2 数据集
本文的自建数据集通过视频提取和网络爬虫2种方法得到,经过筛选对其中一部分图像进行了数据增强,最终数据集包含有1 000幅图像,只有1个类别person,然后采用开源的LabelImg软件对采集到的1 000幅图像进行标注,得到了对应的1 000个xml文件,以9∶1的比例将图像分为训练样本和测试样本。
4.3 实验环境和训练参数
实验条件:本文提出的模型是使用PyTorch和Python实现的,操作系统为Ubuntu 16.04,深度学习框架为Darknet,GPU为NVIDIA GeForce RTX 2080Ti。
训练参数设置为:(1)训练迭代次数epoch设置为100;(2)每次迭代训练的图像数目batch_size设置为4;(3)subdivision设置为1;(4)输入尺寸为640×640;(5)学习率为0.001。
5 实验结果与分析
(1)CA模块嵌入残差模块中不同位置所带来的性能变化,实验结果如表1所示。

Table 1 Detection results on self-built dataset
从表1可以看出,CA-ResNet B-YOLOv3算法的mAP值最大,比传统YOLOv3的高出11.25%,比CA-ResNet A-YOLOv3算法的高出0.28%,也就是说,将CA模块嵌入在残差模块中Add之前的效果更好,可以保留更多目标在特征图中的语义信息,便于模糊目标的识别。
(2)不同注意力模块对YOLOv3算法性能的影响,实验结果如图10和表2所示。
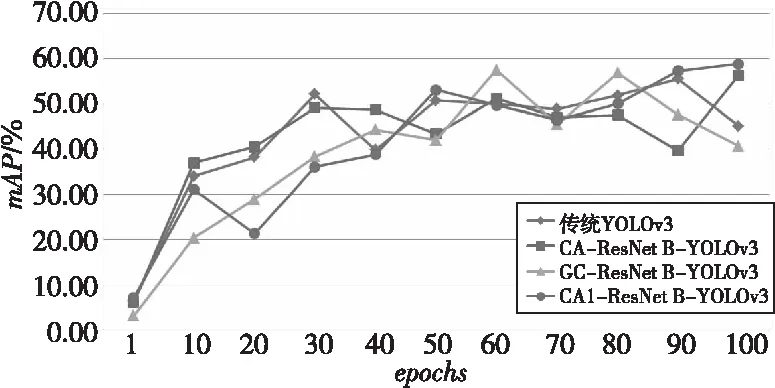
Figure 10 Changes of mAP during training of different algorithms

Table 2 Performance effects of different attention modules
从实验结果可明显看出,使用改进后CA1模块的YOLOv3算法各个指标都有明显提升,无论是Precision值还是Recall值都有明显增长,即达到了减少漏警率和误检率的目的,从最终的mAP值可以看出算法性能获得了改善。
(3)CA1-ResNet B-YOLOv3算法的效能评估和分析,只有一个目标类别person,在自建数据集上的检测性能如表3所示。

Table 3 Performance of CA1-ResNet B-YOLOv3 algorithm on self-built dataset
从表3的实验结果可以看出,与传统YOLOv3相比,CA1-ResNet B-YOLOv3算法的检测准确率提升了5.82%,召回率由92.37%提高到96.23%,上升了3.86%,CA1-ResNet B-YOLOv3算法的mAP由45.10%提高到了58.87%,检测效果如图11和图12所示。
对比图11和12可以看出,CA1-ResNet B-YOLOv3算法对于一些复杂场景,如与背景相近的阴暗处的人也可以较好地识别,定位准确度提高了很多,误检和漏检的情况也有显著改善。

Figure 11 Detection results of traditional YOLOv3 algorithm on self-built dataset

Figure 12 Detection results of CA1-ResNet B-YOLOv3 algorithm on self-built dataset
(4)在自建数据集上对比经典算法。硬件平台为NVIDIA GeForce RTX 2080Ti,检测结果如表4所示。在NVIDIA GeForce RTX 2080Ti嵌入式平台上,结合表4对比不同算法在自建人群检测数据集上的检测精度可以看出,CA1-ResNet B-YOLOv3算法相较于传统YOLOv3模型在mAP指标上提高了约13.77%,Recall值有很大的提升,漏警率降低了许多;相较于同样是一阶段目标检测算法的SSD算法,其mAP提升了9.32%,相较于复现的鞠默然等[21]提出的改进的YOLOv3算法,其mAP提高了3.13%,Recall值提高了1.93%。

Table 4 Performance comparison of different algorithms
6 结束语
本文基于全局注意力来进行人数统计。首先,利用动态数据集和静态数据集相结合自建数据集,并对部分数据集进行了数据增强;通过K-means算法重新聚类锚框;然后将CA模块与ResNet模块相结合,构成2种不同组合方式的CA-ResNet模块,替换传统YOLOv3的残差模块;并对CA模块进行了改进,使其更好地提取细节特征信息;最后根据识别出来的人进行统计,实时返回画面中的人数。实验结果表明,改进后的CA1-ResNet B-YOLOv3算法对于室内人群识别的召回率、检测的平均精度都有明显提升。
但是,改进后的算法在训练速度和人数统计的实时性方面上还有较大提升空间。下一步将在不影响检测性能的情况下降低计算量、精简网络结构进行深入研究。
