基于数据挖掘地址的文本信息提取方法
2022-12-21郭利荣
郭利荣
(中数通信息有限公司 广东 广州 510630)
0 引言
随着计算机网络的发展与普及,许多传统的信息处理方式因此而改变,大量原本以书面方式存在的文本信息,被转换成数字信息进行传递[1]。从而极大地提升了信息的存储及传输效率,信息的总量爆炸式增加,然而具有价值的信息量并未随信息总量同比增长,具有价值的信息在信息规模爆炸的情况下反而更加难以获取。传统的信息检索方法无法有效地帮助使用者分析和理解规模巨大的文本数据,因此产生了许多试图从文本中获取知识的研究[2-3]。
文本挖掘与数据挖掘对比,其最大区别便是数据挖掘面向的数据集通常是结构化的,而文本挖掘所面对的文本信息往往是非结构化的[4-5]。文本挖掘最常见的对象就是网页文本。文本挖掘常常使用的技术有自然语言处理、统计分析、概率模式、机器学习等,运用及探究的方向主要有信息提取、文本摘要、信息过滤、对实体的标注、意见分析、关系探索、情感分析、文本分类、文本聚类等。文本挖掘的目的就是从非结构化的文字发掘出有用或是有趣的片段、模型、趋势和规律[6-7]。
目前,想要获取地址文本信息,主要来源是通过高德地图、百度地图等地理信息服务供应商[8]。这些供应商拥有开放的平台,可以获取大量的地址文本信息及其对应的地理信息。通过该平台开放的逆地理编码接口,使用随机生成的地理位置坐标信息,就能够获得大量的地址文本信息,这些地址文本信息是详细且结构化的。同时通过爬虫从公开的媒体网站上获取文本,用于构建测试集。
1 分析准备工作
1.1 马尔可夫链
马尔可夫链(Markov chain,MC)来源于俄国数学家安德雷·安德耶维齐·马尔可夫[9],其定义为以概率空间内的一维可数集为指数集的随机变量集合X ={Xn}(n>0),若随机变量的取值均在可数集内,且随机条件概率满足式(1),可表示为:

式中:Xt+1。即第t+1个随机变量的取值只与第t个变量有关,对于一个MC,在给定过去的状态为X0,X1,…,Xn-1和当前的状态为Xn时,将来状态Xn+1的条件分布独立于过去的状态,只于当前状态Xn有关。
由于马尔科夫限定的随机变量取值在可数集内,就意味着MC的状态是有限的,由此可以定义Pij作为从i状态转移到j状态的概率,其公式可表示为:

由于概率非负,且过程必须转移到某个状态(也可能转移到自身),可表示为:

如果将每种状态之间的转移概率以矩阵的形式记录,就可以得到一个转移概率矩阵,这个矩阵就表明了各个状态间的转移概率。MC经常会被用于天气预测、股市分析等领域[10]。
对于研究而言,MC还可以推广到更高阶,其公式可表示为:
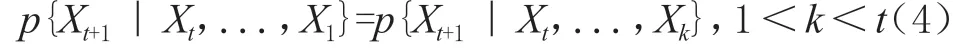
也就是对于将来的状态Xn+1而言,其状态条件分布只与过去的t-k个和现在的状态有关。因此,对于MC而言,可以称之为无记忆性的,其表现只与之前限定期限内状态有关。在文本标注中,由于其无记忆性,就可以专注于需要标注的指定文本,而不需要对全文进行分析。
1.2 地图服务接口
由于文本中的地址信息是分散或是省略的,需要使用地图服务接口对其进行补全。目前中文互联网上主要的2家地图服务供应商均对外提供了地图服务接口,其中包括了地理/逆地理编码,可以通过随机生成经纬度信息获取大量的地点名词典。同样也包含了地名查询的接口,可以将只包含部分地址信息的内容通过该接口进行补全。由于高德地图提供的接口能够有限度地免费供开发者使用,因此在研究过程中使用的均为高德地图的接口,在实际项目实施的过程中需要依据实际情况决定。
对于地图服务接口的调用主要依靠python requests实现,这种方法相对简洁,只需要提供查询词、接口key和URL便可以获得JSON格式的查询结果。对于部分可能出现重复的地名,该接口同样可以使用多个关键词来提升查询的准确性。
2 对案例文本的地点信息提取
为了提升识别的准确性,可以借助运算能力更强的机器或者花费相对多一点的时间,从而对文本做出更加精确的标注。在基于模型的方法中,会更多地考虑到目标词在整段文本中的位置,通过其上下文,以及语意分析进行考虑。
2.1 文本收集和清洗
用于训练的文本选择人民日报2014语料库,这是一个已经事先标注好词性的语料库,如图1所示。

图1 语料库
其中标注为ns的即为地点信息,只需要一个简单的程序就可以对其拆分。首先,将地址词前一个词标注为A,后一个词标注为B。之后,将ns对比已有的地点词典,词典中主要包含县级及以上的行政区划名,如果属于这一类地点,则标注为G,表明为现有地点,并拆分末尾的“省”“市”等行政区划限定词标注为H。将不包含在现有地名的词按字拆分,末尾字标为H,首字标为C,之后依次标注中部为D、末部为E给各个字。最后,将剩余部分均标注为Z。
而对于收集到用于测试集得到文本数据,首先要清除其中包含的非常用字符,仅保留中文字符和标点符号,可以考虑半角标点转换为圆角标点。进行清理的目的是保证分词程序的顺畅运行,提升分词程序的运行效率。
2.2 序列标注
序列标注所针对的是训练集,虽然用于训练的语料库已经进行了分词和标注,但该语料库所标注的类型并不符合模型的需求。应将语料库进一步划分,具体的角色分配的意义及示例见表1。
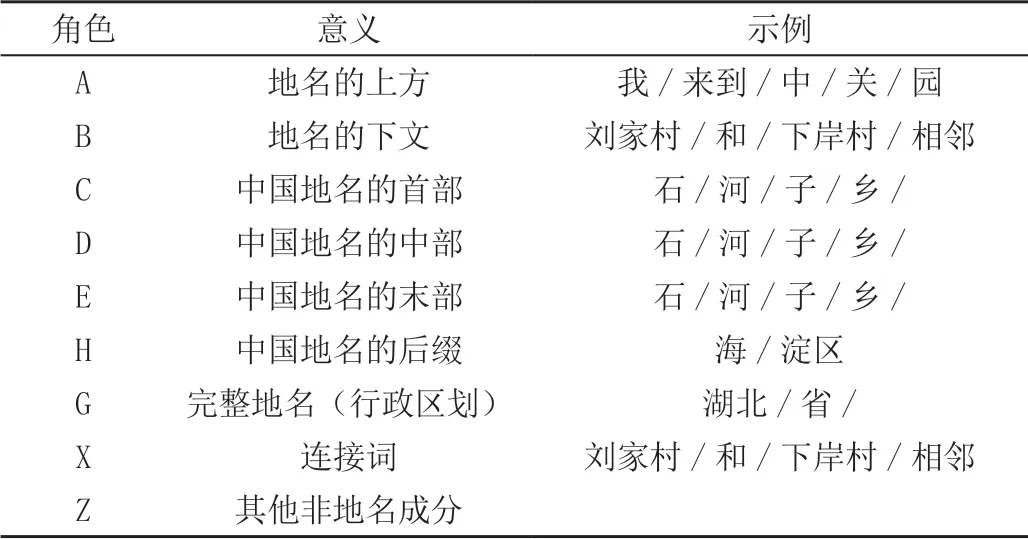
表1 角色分配的意义及示例
此部分的处理可以通过自行编写一个简单的脚本进行实现。具体实现过程如下:
1)将被标注为nr也就是人名部分的词替换为“未##人/nr”;
2)在首部和尾部分别添加“始##始/S”和“末##末/Z”,方便程序运行;
3)将标注为ns的前一词标注为A后一词标注为B,若前(或后)一词也为ns则不变;
4)当发现ns的前一词已经被标注为A时,将其标为X;
5)将ns对比现有地名,若已存在则部分标为G,如不存在则将地名拆分成单个字,依次以C、D、E标注,并将最后一个字标为H;
6)将剩余标注修改为Z,表示无意义。
2.3 最终实现
自动识别的最大困难已经在标注过程中解决,因而识别过程相对简单,只需要查找满足CH/CDH/CDFH/GH的子串即可。自动识别效果如图2所示。

图2 自动识别效果图
标注结果为:
始##始/S,未##人/Z,来自/A,湖北/G,的/X,荆/C,门/H,B,在/A,佛山/G,市/H,南/C,海/D,区/H,大/C,沥/D,镇/H,某/B,物业公司/Z,做/Z,保安/Z,末##末/Z。
从中获取到的地名有“荆门”“佛山市”“南海区”“大沥镇”。同时可以借助行政区划或者地图服务供应商,将地名信息补充完整。在这个过程中,将满足GH的子串定义为固有地点,将满足CH/CDH/CDFH的子串定义为其他地点。通常固有地点为现有的行政区划名称,而其他地点通常为乡一级的行政区划或者是范围较小的地点名,其他地点由于在全国范围内的重名率较高,容易出现混淆。因此通过结合固有地点与其他地点,可以获得更准确的地点信息。
2.4 通过网络服务优化结果
在互联网的帮助下,可以通过地图服务供应商获得更加庞大的地址数据库,通过以下格式向高德地图api发送请求:
parameters = {'output':'json',
'key':'#########################',
'keywords':'#固有地址信息|其他地址信息#',
}
base = 'https://restapi.amap.com/v5/place/text?parameters'
response = requests.get(base,parameters)
通过这样一种方式,就可以对提取到的地址信息进行扩张。对于部分如“望海楼”重名的地址名词,往往无法获得指定的地址,因此考虑通过与其最近的固有地址进行组合查找。在“望海楼”前增加限定词“珠海”后,该搜索结果便是精确可用的。通过这一种固有地址组合地名信息联合查找的方式,对于一部分模糊地点也能够进行定位。这极大地提升了从文本中获取到的地址信息的准确性。
本文是从案例文本中获取地址信息的,因此希望获得的地址信息应当是精确到县级以下,因此要对模型方法所获得的结果进行后续处理。处理逻辑过程如下:
1)按序提取已经标注的地点信息,排除其他词的干扰,同时将地址类别为固有地址的词段进行标记;
2)遍历全部的非固有地名信息,将其与其前一个最近的固有地名组合;
3)该组使用request高德地图api,获取搜索结果,将结果替换原先非固有地名;
4)删除仍然存在的固有地名。
经过以上模型处理后,程序运行结果如图3所示。

图3 程序运行结果
显然,“中大五院”未被识别为地点,实际上是由于模型未能识别该地点。通过对语料库的分析判断,可能是其被标注为nt,即机构团体名所导致的结果。
3 结语
综上所述,通过数据挖掘模型方法对文本内容中的地址信息提取提供了方案。先介绍了文本数据挖掘的方法及在项目中所需要的模型算法,在对模型方法的实际运用过程中,可以看出模型方法在面对部分固有地名已经退化统计。同时,对模型方法提出了更高的要求,能够更加准确地理解语境。本文也开创性地提出了将地点信息分级方法,通过将信息分级为固有地点和其他地点,并依据其他地点会跟固有地点相近出现的文本规律。通过地图信息服务供应商,结合查询固有地点与其他地点,便能够获取准确且相对单一的地点信息。
