双重编—解码架构的肠胃镜图像息肉分割
2022-12-21魏天琦肖志勇
魏天琦,肖志勇
江南大学人工智能与计算机学院,无锡 214122
0 引 言
作为全球发病率第3位(10.2%)、病死率第2位(9.2%)的疾病,自2018年以来,结直肠癌(colorectalcancer,CRC)的发病数量在中国快速上升,严重威胁了我国人民群众的生命健康(田传鑫和赵磊,2021)。然而大多数的CRC肿瘤在早期是以腺瘤性息肉的形式生长于肠道内壁,随着病情的进展逐渐发展成恶性肿瘤并扩散到其他组织,因此早期肠道息肉检查至关重要,可以大大提高成活率(90%) (Siegel等,2019)。通过结肠镜的胃肠道检查以发现早期肠道息肉并进行切除仍然是CRC防治的金标准,目前大多数指南推荐从50岁时开始筛查(Finlay等,2021)。然而传统的结肠镜检查需要至少一位有资质的内镜医生将长约1.5 m的肠镜经肛门顺着肠腔插入到结肠及回盲部,从黏膜表面观察结肠是否发生病变。这一方法不仅对内镜医生的专业水平有较高要求,同时由于肠镜的快速进出、不同息肉的发展状态(如图1所示)、内镜医生的工作状态以及采用设备的缺陷等因素,结肠镜检查有着高达6%-27%的漏诊率(Ahn等,2012)。因此,计算机辅助系统在提高结肠镜检查效果方面有着巨大潜力。

图1 结肠息肉大小、形状和外观示例图Fig.1 Example images showing the differences in size, shape and appearance of colonic polyps
综上所述,息肉的精确分割在临床应用中至关重要,使用先进的辅助算法对成像上的息肉进行自动分割可以显著提高腺瘤的查出率。然而随着息肉生长状态的不同,在大小、颜色和纹理等特征上往往存在差异且息肉边界模糊不清,这些因素使得息肉分割仍然是一项具有挑战性的任务。为了解决这一问题,在过去的十几年里有很多方法相继提出,早期的息肉分割是传统的基于手工特征的机器学习方法,例如Mamonov等人(2014)设计了基于帧的纹理内容,利用几何分析来标记图像中是否包含多边形的二分类器的结肠息肉分割算法,在视频序列长度为3 747帧的前提下为操作员节省了约90%的工作量。随着深度学习的快速发展,全卷积神经网络在医疗图像分割上的应用越来越广泛,Jha等人(2019)在ResUNet(Xiao等,2018)的基础上继续加入空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)和注意力模块后提出的ResUNet++在多个结肠息肉数据集上取得了优于U-Net(Ronneberger等,2015)和ResUNet的成绩。Jha等人(2020)提出的Double U-Net将两个U-Net的编码器(encoder)和解码器(decoder)进行skip connections,通过两个U-Net的堆叠捕获到更多的语义信息,并使用ASPP空间金字塔池化来捕获上下文信息,在MICCAI(Medical Image Computing and Computer Assisted Intervention Society) 2015(Bernal等,2017)挑战赛中对微小扁平息肉分割取得了更精确的结果。近年来,注意力机制越来越受到研究者们的重视,Chen等人(2021)认为,尽管U-Net系列网络已经取得了很大的进步,但仍然存在由全卷积网络本身所带来的无法进行长距离依赖建模的缺陷,因此将Transformer(Vaswani等,2017)引入到U-Net中,提出了TransUNet,为医学图像分割网络的改进提供了新的思路。何康辉和肖志勇(2021)提出了多层多视角的卷积方法,增强了对特征的冗余学习。Oktay等人(2018)提出了一种应用于医学图像的门控注意力模块(attention gate,AGs),可在训练时自动学习抑制不相关区域,注重有用的显著特征。
上述方法都能够有效分割息肉的主体部分,尤其是注意力机制的运用可以使模型有效地聚焦前景部分,实现像素级的全局参考,但自注意力机制会带来大量额外的计算开销,同时对大规模预训练以及数据集具有较高的要求,这都极大提高了模型训练的成本。不同于以往的利用图像本身构造注意力权重图的方法,受Jha等人(2020)使用两个U-Net级联的方式来加强上下文关系的启发,本文提出了一种由多个模型互相影响的注意力权重图构造方法,将上游网络输出的预测结果作为权重图对下游分割网络产生影响,同时在解码阶段加入轻量化模块来更好地获取全局信息,可以获得更好的分割效果。
本文的主要贡献包括5个方面:
1) 提出一种针对上述问题设计的深度神经网络结构;
2) 提出一种新的注意力矩阵获取方法,这种方法可以得到一个高精度的注意力权重图;
3) 提出一种划分子空间施加通道注意力的方法;
4) 在内镜图像CVC-ClinicDB数据集和胶囊内窥镜图像Kvasir-Capsule(Smedsrud等,2021;Jha等,2021)数据集上对模型的分割效率进行验证,并与现有的息肉分割模型进行比较;
5) 混合了上文提到的两种数据集,并对提出的方法进一步验证,以显示模型在使用不同设备捕获的图像上的分割效率。
1 相关工作
1.1 门控注意力机制
以U-Net为代表的利用卷积神经网络(convolutional neural networks,CNN)的强表征性来分割医学图像的方法通常是将分割任务分为两个步骤,即检测和分割:先确定待分割目标的感兴趣区域(region of interest,ROI),再针对ROI进行小范围的分割。但是由于医学图像本身的特点(目标组织/器官在形状、大小和颜色等特征上呈多样性等),精准地确定ROI一直是医学图像分割所要解决的难点之一。为此,Oktay等人(2018)提出了将软注意力机制应用于U-Net的门控注意力机制(attention gate,AGs),并通过对比试验证明了AGs的有效性。
AGs的具体结构如图2所示,其中,g代表解码部分的特征矩阵,xl是编码部分的矩阵,两个矩阵经过大小为1×1的卷积操作统一通道数之后进行concat拼接后进入解码层,通过Resampler重采样器将特征图重采样到原来xl的大小,最终生成一个可以通过反向传播学习的权重矩阵,获得每个元素的重要性,再将权重矩阵与原编码部分的特征矩阵相乘,得到注意力特征图。AGs的定义为
(1)
(2)

模型的泛化性是指在独立数据集上的性能;鲁棒性指在具有挑战性图像上的性能,这两者都是评价深度学习算法在临床应用价值的重要指标,因此建立一个强有力的医学分割模型必须具备足够的泛化性和鲁棒性,然而AGs对于部分医学图像并不能展现出显著的性能提升,尤其是针对像结肠息肉这一类细粒度、小目标的分割。针对这一问题,本文发现只需充分利用U-Net自身的分割性能就可以构建精确的权重图谱,因此尝试了利用网络自身产生注意力权重的方法,即双重U-Net网络结构。

图2 门控注意力机制Fig.2 Attention gate
1.2 双重U-Net架构
传统U-Net网络包含两部分:分析路径和合成路径。分析路径负责学习图像特征;合成路径则根据学习到的特征生成分割结果。此外,U-Net还加入了跨越连接使合成路径产生更精确的结果。然而普通的U-Net网络并不能适应所有类型的医学图像应用,为了解决这一问题,Jha等人(2020)提出了一种用于语义分割的新框架Double U-Net,模型结构如图3所示。
Jha等人(2020)认为在ImageNet(Deng等,2009)上预训练过的模型可以显著提升性能,因此选择了VGG-19(Visual Geometry Group)(Simonyan和Zisserman,2015)作为上游U-Net结构的编码器,并在下游网络结构中使用了空间金字塔池化,在上下游网络之间进行跨越连接进一步提高特征利用率。该网络最终在CVC-ClinicDB(Colonoscopy Videos Challenge-ClinicDataBase)数据集(Bernal等,2015)上取得了state-of-the-art (SOTA)的结果。刘佳伟等人(2021)在此基础上加入的注意力模块在息肉分割上取得不错的成绩。

图3 双重U-NetFig.3 Double U-Net
但由于对上游网络编码器有较高的预训练要求,在实际应用中往往需要有针对性地运用其他大型数据集对某一特定的医学图像进行预训练,这大大提高了使用成本,再加上U-Net已经在多个医学图像任务中展现了极佳的性能,因此可以选择U-Net作为上游网络参与训练来生成注意力权重图。
1.3 轻量型注意力模块
Saini等人(2020)认为现有注意力计算机制产生了较高的参数开销,因此不适合以CNN为代表的紧凑型卷积神经网络,并为此提出了一种简单有效的超轻量级子空间注意力机制(ultra-lightweight subspace attention mechanism,ULSAM),如图4所示,在ULSAM中将每个特征图分解为多个子空间,并在多个子空间内学习不同的注意力特征图,从而实现多尺度、多频率的特征表示。实验结果证明,多尺度融合对精细化的目标边缘分割效果的提升是有帮助的(吉淑滢和肖志勇,2021)。

图4 子空间注意机制Fig.4 Subspace attention mechanism
结肠息肉整体较为圆滑且颜色与肠壁较为相似,因此网络会在目标边界处理上产生一定误差,影响分割性能。为了进一步提高模型在息肉边界的分割能力,可以引入轻量化注意力模块。受ULSAM的启发,在下游网络的跨越连接中加入改进的子空间通道注意力模块来提取每个特征子空间的个体注意力映射,为原始特征图提供了跨通道信息高效学习的能力,进一步提升模型针对细粒度、小目标分割上的性能。
2 方 法
2.1 方法概述
本文方法的整体结构如图5所示,因为传统卷积操作不能对小目标进行精确分割,而注意力机制可以很好地解决这一难题,因此本文设计了一个包含两种编—解码网络的模型结构,对输入图像进行两次训练,第1次训练的目标是获得注意力权重图,通过平均池化操作缩小特征图尺寸之后再将其与下游网络的解码器输出逐级相乘得到注意力权重图,利用权重图对原始图片进行拼接后进行第2轮的加强训练;通过在下游网络跨越连接中添加改进的轻量级模块ULSAM,增强通道之间的内部关系;最后通过连接操作将两部分的特征图进行融合,再进行上采样操作将融合信息汇总为增广表示,最终实现端到端的像素级预测。
2.2 注意力权重
注意力是一种机制或方法论,其并没有严格的数学定义,因此本文提出的通过添加额外的神经网络来给输入的部分分配不同的权重应该属于软注意力(soft attention)。软注意力包括空间注意力和通道注意力,其最终目的就是选择细粒度的重要像素点,进而让网络把注意力放到该区域上,简单来说就是要让目标区域的像素值变大。通常使用的方法是利用输入图像自身结合在编—解码过程中的上下文信息来挖掘输入和输出之间的关系。
本文方法使用掩码(mask)来形成注意力机制,是基于位置的软注意力。掩码的原理在于通过一层新的权重将图像数据中关键的特征标识出来,通过学习训练让双层网络学习到每一幅输入图像中需要关注的区域。在上游网络的backbone中利用两个大小为3×3、激活函数为ReLU的卷积块提取出特征图,为了防止在训练过程中数据分布发生改变以及梯度爆炸,在每一次卷积操作之后加入批归一化层(batch normalization,BN)进行批归一化操作。在解码器中需要将图像恢复至原来的尺寸,通过使用反卷积的上采样操作可以增大特征图的分辨率。由于网络的整个操作都可反向传播,因此上游网络可以通过反向传播不断训练以提高输出掩码图像的精确度,最后经过Sigmoid操作可以将上游网络输出图像的像素归一化到0-1的范围内,像素值越接近1就代表原图像中对应像素判断为目标的概率越大。为了更大限度地利用上游网络的输出信息,整体模型的输出还将与未进行Sigmoid操作的上游输出进行一次残差操作,模型输出具体为

图5 网络结构Fig.5 Network mechanism
y=F(σ2(f(x))×x)+f(x)
(3)
式中,y表示模型的最终输出矩阵,x表示模型的输入图像,F表示下游网络的操作函数,f表示上游网络的操作函数,σ2表示Sigmoid函数。
2.3 门控注意力
与Attention U-Net类似,经过上游网络输出的掩码图像可以在下游网络解码器中作为门控信号来调整特征图。在压缩掩码分辨率的过程中选择了2×2的平均池化层。因为相较于最大池化,平均池化可以保证在嵌套的池化操作中保留准确的掩码信息,防止将低概率像素值增大。如图6所示,在一个2×2的滑动窗口内有3种可能的情况:4个像素均为背景、4个像素均为前景以及4个像素中部分为前景。当出现第1种情况时,虽然最大池化可以保证池化后的像素值仍然可以预测为背景,但是在经过多轮最大池化后该像素值会不断升高,最终导致原本应该是背景的区域被放大;当4个像素均为前景时平均池化可以保证网络始终给予这部分特征较大的关注;对于4个像素中大部分为前景或大部分为背景的情况下平均池化可以起到细化边缘的作用。

图6 平均池化与最大池化的比较Fig.6 Compare with Avgpooling and Maxpooling
需要特别指出的是,在下游网络的第1层并没有像其他层一样将掩码图像作为门控信号来对解码路径中的特征图进行调整,因为本文认为未经池化压缩的原始图像具有最丰富的语义信息,压缩再扩张操作反而会损失这些上层语义信息,因此选择将上游网络的输出经Sigmoid激活函数之后直接与输入图像进行乘操作,这样可以确保在保留图像的高级语义信息的同时又保证模型将注意力集中在目标区域。
2.4 子空间通道注意力
为了使编码器传送给解码器的特征空间包含更多的远程依赖,同时尽可能减少计算量,本文参考了Saini等人(2020)方法将完整的特征图划分为互斥的多个子空间,以及DANet(Fu等,2019)的通道注意力的思想,在下游网络的跨越连接中加入了轻量级子空间通道注意力模块ULSCAM,对特征图分块计算注意力后进行信息汇总,这种方法可以用极少的附加参数和计算来捕捉更为复杂的跨通道信息交互。
具体结构如图7所示:对于拆分后的每个子空间,让注意力机制分别学习各个子空间的注意力图,以减少整体计算上的空间和通道冗余,同时对不同层的特征图用划分子空间求注意力图的学习方式实现了多频率的特征表示,这种方法对高频率区域内细微细节的精细化分割效果更为理想,计算为
(4)
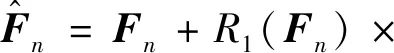
(5)


图7 轻量级子空间通道注意力模块Fig.7 Ultra-lightweight subspace channel attention module
3 实验与分析
3.1 实验数据集
如表1所示,本文使用了两种不同设备采集的带有ground truth的结肠息肉数据集。Kvasir-Capsule数据集(Oktay等,2018)是包含了13类标记异常的开放数据集,在肠胃医学专家的帮助下从胶囊内窥镜采集到的44 228个视频帧中存在55个包含息肉的帧,Jha等人(2021)对这55个视频帧进行了标注并提供了息肉的位置信息,将其整合成了KvasirCapsule-SEG数据集并开放于医学图像分割和定位任务。CVC-ClinicDB数据集(Bernal等,2015)来自西班牙巴塞罗那临床医院,由31个结肠镜检查视频中提取的612幅息肉图像和专家手工标注的ground truth组成,用于医学图像处理中的分割实验。

表1 实验中用到的医学分割数据集Table 1 The biomedical segmentation datasets used in our experiments
上述两个结肠息肉数据集是由不同设备提取得到的,在成像方面具有明显差异性,胶囊内镜采集到的图像呈现出鱼眼镜头所特有的凸面效果,而常规肠胃镜的图像则更为舒展。为了研究提出的网络在跨设备图像上的分割效果,将上述两种数据集混合,组成了一个全新数据集CVC-KC,分辨率统一到336×336像素。
3.2 评价指标
为了评估本算法的性能,选择Dice相似指数(DSC)、精确率(precision)、召回率(recall)以及均交并比(mIoU)作为评价指标,分别定义为
(6)
(7)
(8)
(9)
式中,真阳性TP(true positive)是将正样例(息肉部分)正确分类的像素点数;真阴性TN(true negative)是将负样例(背景区域)正确分类的像素点数;假阳性FP(false positive)是将负样例错误分类的像素点数;假阴性FN(false negative)是将正样例错误分类的像素点数。Dice系数是一种集合相似度量函数,其中|X∩Y|表示矩阵X和矩阵Y之间的交集元素的个数,|X|和|Y|分别表示两矩阵元素的个数,k表示分类数,在本文的实验中均为1。所有评价指标值均介于0-1,指数越接近1表示分割结果与ground truth的相似度越高。
3.3 实验环境及参数设置
模型基于Pytorch框架,在一块NVIDIA RTX 1080Ti上进行训练,为了充分利用GPU设备的显存资源,将图片的大小统一设置为224×224像素,batch-size设置为8。为了扩充训练集采取了随机旋转、翻转和移位的数据增强策略,对于每一个数据集将其顺序完全打乱并随机划分为6 ∶2 ∶2的3个互斥组分别作为训练、验证和测试集;对于混合数据集CVC-KC,使用CVC-ClinicDB数据集中全部图像进行4 ∶1的划分作为训练集和验证集,并在KvasirCapsule-SEG数据集上测试模型的分割性能,并交换二者位置进行第2次实验,标记为数据集KC-CVC。使用Adam优化器,为了得到最佳分割结果,将初始学习率设置为3E-4,学习率衰减定义为
(10)
M=E×T
(11)
式中,bl代表基础学习率,G表示当前已训练的batch总数,M是训练轮数与训练集大小的乘积,E则代表训练的epoch数,T代表训练集大小。
3.4 损失函数
Dice loss是Milletari等人(2016)在V-Net中提出的loss函数,计算为
(12)
式中,矩阵X和矩阵Y分别代表进行对比的矩阵。由于对正负样例不均衡的场景有着不错的性能且训练过程中更注重对前景区域的挖掘,因此Dice loss非常适合于小目标、样本不均衡场景下的语义分割,广泛采用于医学图像分割任务中。但它也存在着训练loss不稳定、曲线混乱等缺点,因此本文将二分类交叉熵损失函数BCE loss(BL)和Dice loss(DL)混合使用,最终loss函数定义为
Loss=BL×w+DL×(1-w)
(13)
式中,变量w代表二分类交叉熵损失函数的权重,默认大小设置为0.5。
3.5 实验结果
3.5.1 消融实验
为了度量文中提出的所有组件的有效性,进行两组对比实验来证明双重U-Net结构(U2 Net)、掩码注意力门(mask attention gate,MAG)和ULSCAM都可以在一定程度上提高息肉分割的性能。
本文提出的多种改进策略结果如表2所示,可以发现,当采用级联U-Net并将第1个网络的输出作为注意力权重对第2个网络的输入进行改进后,各项性能指标均取得了较大的提升,尤其是在CVC-ClinicDB数据集上,准确率和召回率的提升都达到了2%以上;进一步将上游网络的输出经过平均池化之后对下游网络解码器部分的特征矩阵进行权重分配后对召回率的提升最为显著,接近4.5%,同时在KvasirCapsule-SEG数据集上也取得了提升;因此本模型相较于U-Net在分割性能上具有明显优势。
3.5.2 ULSCAM中子空间数的影响
为了探究ULSCAM模块中划分子空间数对模型分割性能的影响,本文做了进一步实验:分别将特征图划分为子空间数1(不划分)、2、4、8和16且其他条件相同的情况下的各项指标。可以预测的是,虽然在划分次数小时会损失一定的精度,但当划分数逐渐增大之后,本模块可以得到更好的跨通道信息交互,结果如表3所示。
3.5.3 以权重图为基础的门控注意力机制的作用
为了探究以上游网络生成的权重图对下游网络的解码过程中添加门控注意力机制的影响,本节对消融实验中的MAG进行分析。相较于Attention U-Net,MAG机制的实现是通过附加的注意力权重图谱,上游网络的输出结果经过归一化处理后会形成预测图的注意力分布矩阵,用来表示每个像素的重要度,这个重要度是根据图像的目标学习出来的,权重矩阵也可以通过反向传播来学习。通过权重矩阵作为门控机制在下游网络的解码器部分进行乘操作可以引导模型侧重目标区域。通过消融实验表2可以看出:相较于传统分割网络U-Net,添加了MAG模块的U2 Net网络在DCS、mIoU以及Recall上均有明显提升,证明了本文提出的MAG模块的有效性。
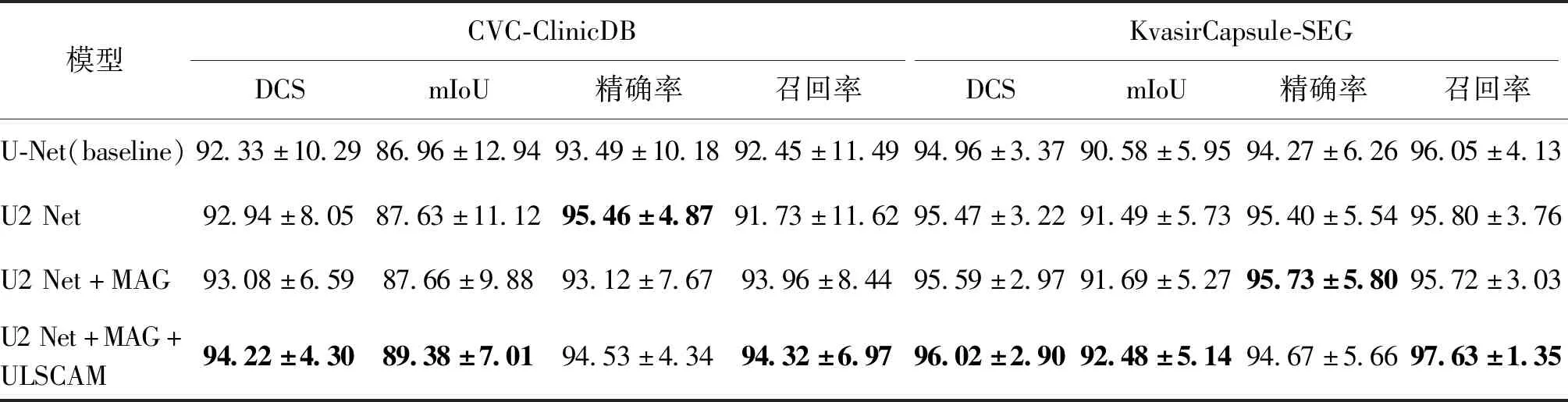
表2 本文改进方法的比较Table 2 Comparison of segmentation algorithms of proposed improved strategies /%

表3 ULSCAM中子空间数的比较Table 3 Comparison of the number of subspaces in ULSCAM /%
3.5.4 不同算法的结果比较
为了更好地验证算法的有效性,将本文算法在CVC-ClinicDB数据集和KvasirCapsule-SEG数据集上与近几年提出的SOTA算法及一些经典的语义分割算法进行比较,包括U-Net、ResUNet、ResUNet-mod(Zhang等,2018)、ResUNet++(Jha等,2019)、SFA(Fang等,2019)、PraNet(Fan等,2020)、TransFuse(Zhang等,2021)、HarDNet-MSEG(Huang等,2021)、FANet(Tomar等,2022)、UACANet(Kim等,2021)、MSBNet(Wang等,2021)、NanoNet(Jha等,2021),如表4和表5所示。

表4 CVC-ClinicDB数据集不同算法的结果Table 4 The results of different algorithms in the CVC-ClinicDB dataset

表5 KvasirCapsule-SEG数据集上不同算法的结果Table 5 The results of different algorithms in the KvasirCapsule-SEG dataset
通过表4可以看出,本文算法在DSC、mIoU、precision以及recall的结果均优于早期的经典算法和近期提出的SOTA算法,同时与选择作为baseline的U-Net算法相比提升显著。通过表5可以看出,本文方法在胶囊胃镜数据集上的DSC、mIoU、precision等3个指标上都优于其他算法,虽然在recall指标上不如ResUNet,但是两者的差距仅有0.2%,仍然可以说明本文算法的有效性。为了更直观地说明本文算法的有效性,图8展示了选用数据集的可视化分割结果。可以发现,相较于U-Net,本文的算法可以更精确地分割息肉本体以及边缘部分,这也证明了算法的有效性。
3.5.5 混合数据集的结果
为了检测提出方法对使用不同设备捕获到的图像的性能,本文混合使用了CVC-ClinicDB和KvasirCapsule-SEG两个数据集,组成了一个全新的数据集CVC-KC。在实验阶段交替使用两个数据集中的全部图像作为训练和验证集,并将训练后的模型在另一个数据集上进行测试,表6和表7分别显示了混合数据集在两个数据集上的测试结果。可以看出,相较于传统的图像分割算法,本文方法在各项性能指标上都能够带来较大的效果提升,尤其是表6中本文模型在DSC上的涨幅接近17%,同时在召回率上的提升超过了20%。同样的情况也可以在表7中看到,本文模型在胶囊胃镜图像上训练后再在肠镜图像上的预测结果仍然优于baseline,但由于训练集的图像数量、椭圆/圆形的ground truth与测试集差距较大以及KvasirCapsule-SEG数据集图像较不均衡等因素,性能提升的差距并没有表6中所展示得那么显著,这一类问题可以通过使用更大数据集或者数据增强的方式得到改善。在图9展示了跨数据集分割的可视化结果,前两行是先在CVC-ClinicDB上训练后在KvasirCapsule-SEG上测试的结果对比;后两行是先在KvasirCapsule-SEG上训练后在CVC-ClinicDB上测试的结果对比。

图8 分割结果的可视化Fig.8 Visualization of segmentation results((a)input;(b)ground truth;(c)U-Net;(d)ours)

表6 使用CVC-ClinicDB作为训练集的交叉数据集的结果Table 6 The cross-dataset results using CVC-ClinicDB as the training set

表7 使用KvasirCapsule-SEG作为训练集的交叉数据集的结果Table 7 The cross-dataset results using KvasirCapsule-SEG as the training set

图9 跨数据集分割结果的可视化Fig.9 Visualization of cross-dataset segmentation results((a)input;(b)ground truth;(c)U-Net;(d)ours)
通过表6和表7的对比不难发现:在表6中使用了612幅图像的CVC-ClinicDB数据集进行训练后模型在KvasirCapsule-SEG数据集上的分割结果相较于传统的U-Net网络在DSC、mIoU、precision以及recall等4项指标上分别取得了16.73%、20.82%、2.11%以及21.88%的显著提升,具有明显的临床应用前景;而在表7实验中使用KvasirCapsule-SEG数据集进行训练的实验中虽然相较于U-Net有效果提升但是整体指标过低而不具备临床应用的可行性。这是由于KvasirCapsule-SEG数据集中图像数量限制的同时又与测试集图像存在明显差异性的原因,但参考图8仍可以看出本文模型在肠胃镜图像上方的息肉分割相较于U-Net在整体以及边缘处理上仍然具有明显优势,因此可以认为本文方法在临床应用特别是跨采集设备的图像分割方向上虽然具有应用前景但仍然需要足够数量的图像作为训练集才能保证分割结果的性能。
这进一步证明了在大多数结肠息肉数据集特别是采集设备跨度较大的情况下本文模型仍然具有一定的鲁棒性,从医师的角度来看,模型对于多种应用环境下的临床辅助诊断具有一定的准确性,为降低实际应用中的漏报率提供了一种可行的解决方案,对提高大肠癌筛查策略具有潜力。
3.5.6 模型显著性测试
显著性验证(significance test)作为判断两个乃至多个数据集之间是否存在显著性差异以及差异是否明显的方法应用于各种研究领域,在统计学中,显著性检验是“统计假设检验”的一种。对本文算法与baseline进行基于DSC数据的显著性测试,以排除本文实验所得数据的偶然性。
图10显示了两个数据集的指标对比,其中粉色箱型图为KvasirCapsule-SEG数据集,亮蓝色箱型图为CVC-ClinicDB数据集。两组DSC数据不满足正态分布,因此使用非参数检测的Wilcoxon符号秩和检验方法求得两数据集对应显著性差异概率值分别为0.006 835 937 5和0.037 927 273 453 751 33,均小于设定水准0.05,可以认为本文模型与baseline具有显著性差异。
4 结 论
本文针对结肠息肉分割中性能提升和边缘分割模糊这一问题提出了一种改进的基于编—解码结构模型,创新性地利用上、下游两个分割网络分别负责生成掩码注意力权重图以及语义分割,通过反向传播不断更新上游可训练网络生成的权重,在下游网络的解码步骤中使用生成的注意力图对特征图进行权重配置,并通过平均池化压缩权重图使其能够适配不同分辨率的特征图,同时融合了轻量化通道注意力模块,将下游网络跨越连接部分的权重图分割为多个子空间,针对各个子空间分别施加通道注意力,再将子空间合并,最终实现多频特征下的跨通道注意融合。然后进一步在CVC-ClinicDB和KvasirCapsule-SEG两个数据集上进行独立实验,并将两个数据集融合验证了本文模型在跨设备数据上的鲁棒性,实验数据证明其性能优于很多经典医学图像分割网络以及近期的SOTA网络。因此本文模型的优点就是相较于其他网络可以更好地细分割息肉的边缘部分并更能成功分割息肉中扁而小的部分,这些恰恰是经验不足的内镜医师容易忽略的。

图10 本文方法与baseline对比的箱型图结果Fig.10 Box plot results comparison between ours and with baseline((a) DSC;(b) mIoU;(c) precision;(d) recall)
此外,该模型不需要任何的后处理,这也是本文方法的一大优势,然而仍然需要一系列临床试验才能证明模型在应用上的有效性,希望这项工作能够在未来的临床应用中为更多内镜医师提供工作上的便利,为保障我国人民的身体健康做出贡献。
