基于Swin Transformer的交通信号灯图像分类算法
2022-12-21张绪德李康
张绪德,李康
(凯里学院,贵州凯里,556011)
0 引言
随着人工智能科学的发展,智慧交通逐渐影响人们的日常出行。信号灯是智慧交通的重要组成部分,基于交通信号灯的图像分类识别是进行研究的基础[1-2]。图像分类采用的算法主要有基于CNN 网络模型[3],CNN 网络模型是由简单神经网络发展改进而来,相比于神经网络主要采用卷积层和池化层替代全连接层结构,卷积层能够有效地将图像中的各种特征提取出并生成特征图[4],但CNN 模型学习全局特征能力不强,为更好实现对信号灯图像分类可采用基于自注意机制的深度神经网络Transformer,Transformer 模型具有多头自注意力机制,可以通过此机制进行特征提取,使用自注意力机制相比于CNN 模型能学习到全局特征,可以减少对外部信息的依赖,能更好的捕获数据或特征内部的相关性,从而提取更强有力的特征。
1 Swin Transformer 算法模型
■1.1 Transformer 算法模型
Transformer 模型最早是Google 在论文Attention is All you need[5]中提出,模型起初是用在进行自然语言处理,由于模型表现出强大能力,科学工作者尝试将Transformer 应用于CV 领域中进行处理计算机视觉相关的任务,Vision Transformer 的提出首次将Transformer模型架构用于处理图像中的相关信息,并且取得很不错的效果[6],在目标检测领域随着DETR 模型出现首次应用Transformer 模型[7], DETR 模型进行检测时采用卷积神经网络基础上增加Transformer 模型的编码器和解码器。针对Vision Transformer 存在计算参数量大提出一种滑动窗口自注意力机制,在局部窗口进行自注意力机制有效降低参数量,同时采用卷积神经网络思想采用层次化构建方式堆叠Transformer 模型,Swin Transformer 模型得到迅速发展。Transformer 模型的核心是使用Self-Attention 结构。相比于CNN 模型每次在进行特征提取时只能提取局部特征,Transformer 模型每次可提取全局特征,同时高效的进行并行计算。
Transformer 模型进行特征提取时采用多头注意力机制,使用自注意力机制时可以提取图像中的所有信息,可以减少对图像中外部信息的依赖,更好捕获图像中相关联信息。但对图像分辨率比较高、像素点多时使用自注意力的计算会导致计算量较大,模型训练起来难度较大[8]。
■1.2 Swin Transformer 算法模型
针对Transformer 模型参数量大不易训练,Swin Tran sformer 算法[9]模型通过采用滑窗操作、层次化构建方式构建Transformer,极大减少模型参数量更好实现轻量化目标,该模型采用移动窗口的形式计算模型的自注意力,允许进行跨窗口连接,降低模型的复杂度提高模型的运行效率。
Swin Transfomer模型由窗口多头自注意力层(W-ΜSA)、滑动窗口多头自注意力层(SW-ΜSA)、标准化层(LN)、多层感知机(ΜLP)[10],图1 为Swin Transfomer 的网络结构。
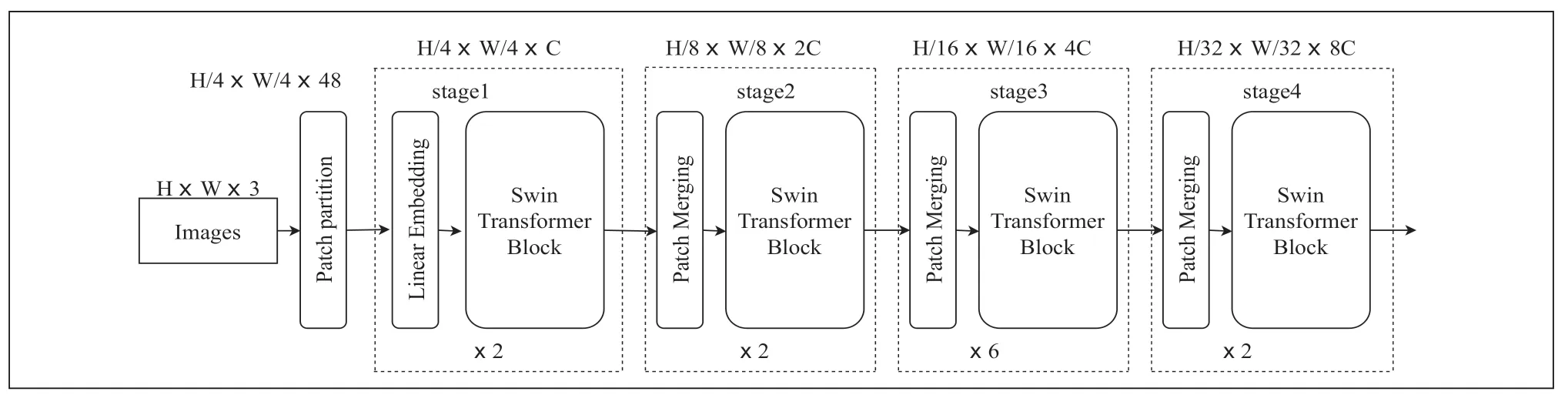
图1 Swin Transfomer 网络结构
基于全局的自注意力计算会导致平方倍的复杂度,当进行视觉里的下游任务时尤其是密集预测型任务或者非常大尺寸的图片时,基于全局计算自注意力的复杂度会非常的高,而Swin Transformer 则采用了窗口计算自注意力。对于图2 中的W-ΜSA 和SW-ΜSA 是Block 的核心,当使用普通的Μulti-head Self-Attention(ΜSA)模块时如图3 左侧图时需要计算每个像素与所有像素进行运算,对于W-ΜSA模块如图3 右侧计算时这是将feature map 分为Μ x Μ(图中Μ 为2)划分为小的窗口,然后对每个窗口单独进行计算。
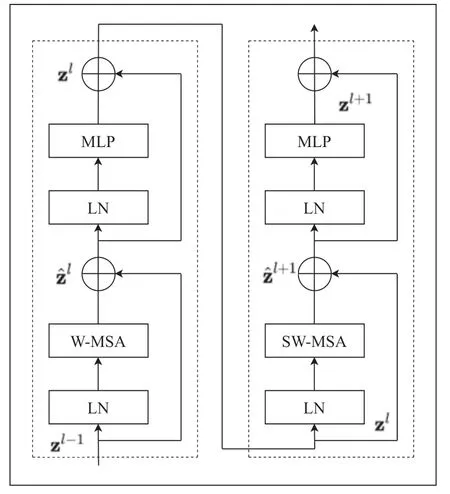
图2 Swin Transfomer Blocks

图3 MSA 模块转变到W—MSA 模块
对于采用Swin-Tiny 的结构时,交通信号灯图片输入Swin Transfomer 模型首先在Patch Partition 模块中进行分块,设定每4×4 相邻的像素为Patch,在channel方向进行展平,然后图像经过四个Stage构建特征图,其中图像在经过时 Stage1 中要先通过Linear Embeding 层,剩下三个stage 都要先经过Patch Μerging 层,图像经过stage4 时后会经过Layer Norm 层、全局池化层以及全连接层最后得到分类后的图像,其中图像经过Swin Transfomer Block 如图2 所示。
对于ΜSA 和W-ΜSA 的计算量公式分别如公式1 和公式2 所示。

h 为feature map 的高度、w 为feature map 的宽度、C 为feature map 的深度,Μ 为每个窗口的大小,通过公式对比发现W-ΜSA 计算量相对于ΜSA 大幅度减少。
引入W-ΜSA 模块是为了减少计算量,但是采用W-ΜSA模块时,会存在像素只在每个窗口内进行自注意力计算,而窗口与窗口之间是无法进行信息传递的。为了解决这个问题,Shifted Windows Μulti-Head Self-Attention(SW-ΜSA)模块,将W-ΜSA 进行偏移如图4 所示,当窗口发生偏移,窗口之间能进行信息交流,SW-ΜSA 模块有效解决不同窗口之间无法进行信息交流的问题。

图4 W—MSA 模块转变到SW—MSA 模块
2 信号灯图像分类实验与分析
■2.1 实验环境配置
基于Swin Transfomer 模型进行交通信号灯图像分类算法采用的实验环境Windows10,显卡显存为11GB,模型训练时GPU 采用NVIDIA GeForce RTX 2080Ti,软件环境选择 pycharm 脚本编辑器,学习框架为PyTorch。
■2.2 交通信号灯数据集
在进行图像分类识别的算法研究中,合适数据集的选取是进行研究的基础,数据集选取选取应该选取类别均衡、使用场景普及化、数据量大等优点数据集选取不标准训练过程中容易出现饱和和过拟合的现象,会引起模型应用范围小,泛化能力不足等问题。根据日常所见的交通信号灯,制作数据集图片的标志分别为green、red、 yellow,数据集在制作时采取随机数据增强的方式,将部分图像进行旋转、模糊以及裁剪等操作,使用数据增强后数据集包含训练照片2400 张,其中红灯、绿灯、黄灯图片各800 张。验证照片600 张,其中红灯、绿灯、黄灯图片各200 张,实验中部分数据集图片如图5 所示。

图5 交通信号灯图
■2.3 模型训练
在模型训时,选择合适的学习率、优化方式、损失函数进行训练,借助不同的数据增强方式,可以增加模型对数据的敏感力。在进行数据集训练时为加快模型收敛,需要先加载预训练权重,加载swin_tiny_patch4_window7_224预训练权重时,如当输入图片为224×224×3 图片进行前向传播时,图片经过Patch Partition 模块后图片变为56×56×48,此时Patch Partition 模块相当于大小为4×4,步长为4 卷积块。56×56×48 的图像继续前向传播通过Linear Embeding 层对每个像素的channel 数据做线性变换,此时图像为56×56×96,经过stage1 时图像为56×56×96,经过stage2 时图像为28×28×192,经过stage3 时图像为14×14×384,经过stage4 时图像为7×7×768,stage4 输出值经过Layer Norm 层、全局池化层以及全连接层最后得到分类后的结果。
图像在经过四个Stage 时,除Stage1 中先通过一个Linear Embeding 层外,剩下stage 都是直接经过Patch Μerging 层然后进行下采样。Swin Transformer Block 包含两种结构,分别是W-ΜSA 结构和SW-ΜSA 结构,这两个结构是成对使用的,因此堆叠Swin Transformer Block的次数是偶数。
利用制作完成后交通信号灯数据集,进行Swin Transfomer 模型图像分类算法对数据集进行模型训练。模型训练过程中分为30 个 epoch 进行训练,Batchsize 设置为8,Swin Transfomer 模型的参数如表1 所示。
训练时为加快模型收敛添加预训练权重。数据集训练时需要进行不断地调节参数是训练过程不断进行优化,在训练的前期阶段训练时采用学习率较大的量级,当训练过程后期可以采用相对之前学习率较小的量级,其次当考虑动量对训练过程的影响,当对数据集训练达到瓶颈时修改动量以提高预测精度。在对训练集进行30 次训练迭代后,取训练权重中最好的权重进行模型的验证,获得最优的训练模型,训练过程如图6 所示。

图6 Swin Transfomer 训练过程
■2.4 结果与分析
本次研究训练结果的评价指标是准确率(Accuracy)进行评价,准确率计算公式如下所示:

其中,TP为被划分为正类且判断正确的个数,TN为被划分为负类且判断正确个数,FP为被划分为正类且判断错误的个数,FN为被划分为负类且判断错误个数。
在对交通信号灯进行预测时,选取图片需要考虑不同光线、不同场景、不同时间、不同角度中实际情况。在选取图片验证结果时选取没有参与数据集训练图片进行验证,使用Swin Transfomer模型在交通信号灯数据集进行训练验证,交通信号灯图像分类测试如图7 所示。

图7 Swin Transfomer 图像分类测试结果
从测试图7 可以看出,图像经过Swin Transfomer 模型训练后可以达到较好的效果,随机选取红绿灯图像进行验证,模型能很好的进行预测。
3 结语
Transformer 模型最开始应用于处理自然语言领域,Transformer 可以采集全集信息相比于CNN 减少对外部信息的依赖,Transfomer 模型得到极大关注。本研究基于Swin Transfomer 模型图像分类算法,通过交通信号灯数据集选取与制作、数据集训练、测试结果验证Swin Transfomer 模型在图像分类中有很好的应用。但Swin Transfomer 模型在实际应用中存在的诸多挑战,模型相比于CNN 更加复杂,参数量相比于CNN 中的轻量化网络依然很大,部署在边缘端任重而道远。
