基于姿态估计的八段锦序列动作识别与评估
2022-12-21柴自强崔帅华
苏 波,柴自强,王 莉,崔帅华
(河南理工大学 电气工程与自动化学院,河南 焦作 454000)
健身功法八段锦动作舒展优美,具有强身健体、怡心养神等功效,练习时无需器械且不受场地局限。但是,多数练习者由于缺乏专业指导而动作不规范,导致健身效果不佳。动作识别与评估系统可以提供动作完整性、同步性的量化分析结果,辅助练习者规范动作,提高练习收益。
在传统的人体姿态识别系统中,测试者需要佩戴一些定制的传感器(例如体位、速度、惯性等)或通过专用摄像头来测量运动信息。文献[1]开发了一套可穿戴系统,通过加速度计、模数转换器以及WiFi模块来获取人体运动数据,进而估计其姿态。文献[2]提出了一种基于Kinect的人体运动识别方法,从Kinect相机获取骨骼特征点数据并计算特征向量,通过实时向量与预设向量进行匹配来识别动作。文献[3]设计了一种基于MEMS惯性传感器的无线网络模块,用来检测人体跌倒等异常行为。以上基于传感器的姿态识别方法需要依赖专用设备,便携性差且实施成本高。此外,可穿戴设备由于具有侵入性而存在一定的安全隐患。
随着计算机视觉技术的发展,基于图像的非接触式人体运动分析方法开始兴起。文献[4]设计了一种基于可见光图像的人体姿态情感识别方法,利用卷积姿态机(Convolutional Pose Machines,CPM)[5]算法提取并描绘出人体关键节点,进而识别分析人物情感。文献[6]从热图像中提取人的关节和骨骼信息,并且使用该信息进行人体动作识别。上述方法大多针对单幅图像或只适用于特定场合。在人体姿态检测方面,文献[7~8]提出的OpenPose是一种人体姿态估计模型,相较于其他算法模型有更高的检测速度和精度。
本文提出了一种基于OpenPose的人体动作识别与评估方法,如图1所示。该方法提取骨架坐标作为原始数据,设计并提取更显著的特征来训练分类器模型,从而对八段锦招式进行识别来获得动作序列,通过求取不同序列间的相似度来进行评估。
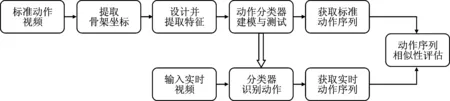
图1 总体流程图
1 基于OpenPose的姿态提取
OpenPose 算法可以实时处理多人姿态,能够在视频图像中检测人体关键点,在COCO、MPII数据集上都有较高的精确度,且鲁棒性强,可满足本文系统需求。
与以往先检测人后检测关键点[9-10]的人体姿态估计算法不同,OpenPose提出了人体关键点亲和场(Part Affinity Fields)思路:首先经过VGGNet-19[11]网络前10层提取原始图像特征;然后用两个并列分支分别预测人体关键点位置和关节之间骨架走向,并进行多阶段迭代;最后通过贪心算法组装每个人的肢体。该算法自下而上,检测速度不会随图中人数的增多而降低。
OpenPose算法检测的是人体头、颈、臂、腿等关节位置,每个关键点在图像中以像素坐标(x,y)表示,具体效果如图2所示,序号与身体部位对应关系如表1所示。

图2 OpenPose算法检测人体姿态效果图

表1 OpenPose算法关键点对照表
2 特征提取
2.1 坐标预处理
为了保证数据的有效性和特征的规范性,需要对OpenPose提取的原始骨架数据进行预处理,具体包括:
(1)坐标归一化。人体在运动过程中,距离镜头的远近会发生变化,图片尺寸不同也会导致x轴和y轴像素单位不统一。为了便于处理,需对坐标进行归一化。首先,对输入图片进行缩放,将宽高为(w,h)的图像先缩放成(1,h/w),并根据18个点的坐标计算出人体中心位置 (XC,YC)
(1)
(2)
其次,计算从颈部到臀部的高度H,这个高度对于不同动作具有不变性;最后,将每一个关键点减去中心坐标后除以H,得到归一化后的坐标(Xnew,Ynew),如式(2)所示。新坐标的人体姿态不变且归一化至画面中心,解决了图像大小或镜头远近变化导致坐标不统一的问题,有利于后续数据处理,效果如图3所示;

图3 坐标归一化效果图
(2)冗余关键点去除。由于八段锦及日常动作主要是四肢的运动,与面部无关,因此剔除双眼与双耳坐标(序号14~17)。用鼻子抽象代表头部的位置信息,将关键点减少至14个,使得后续提取特征时更为简化。
2.2 特征计算与提取
经过上述预处理后,每一帧的归一化关节位置就是最原始的特征。为了有效识别不同动作,本文主要从空间和时间上来考虑,设计出有助于区分动作类型的更显著特征。
2.2.1 空间几何特征
空间几何关系属于静态特征,主要为单张图片中肢体直接表达的信息,例如关键点坐标空间像素位置以及关节之间的角度、距离,具体如表2所示。

表2 空间几何特征
本文定义了距离和角度,两者各12组。以L1、θ1为例,L1是关键点1~3的距离,θ1是关节1~2和关节2~3之间的夹角,其几何特征示意图如图4所示,计算式如式(3)、式(4)所示。

图4 几何特征示例图

(3)
(4)
式中,a=d(1-2);b=d(1-3);c=d(2-3)。
2.2.2 时间运动特征
运动特征反应了人体在连续时刻的变化,例如某些关节、肢体的摆动速度等。关键点速度的计算方式为某个关节点在相邻帧Tk到Tk+1上x与y方向上各自的位移除以间隔时间t,如式(5)所示。
(5)
其中,t与视频帧率F有关,当F为25 frame·s-1时,t为0.04 s。
为了实现基于序列的特征提取,需要不断地从视频序列中提取新的特征,并实时地从序列中去除旧的特征。滑动窗口算法满足上述需求,其实施过程如图5所示。大小为N的窗口用于存储基于时间序列的数据,随着时间的推移,窗口定向移动,新数据被添加到窗口的头部,尾部的数据被推出。持续该过程,直到窗口遍历所有数据。根据滑动窗口内N帧视频序列所对应的关键点数据,计算空间几何特征和时间运动特征,最终聚合而成的特征向量如表3所示。

表3 基于视频序列的特征列表

图5 滑动窗口算法实施过程
3 动作分类器建模与测试
3.1 基于KTH的数据集建模与测试
为了证明本文所提出的算法的普适性,首先在公开数据集KTH[12]上进行实验。KTH数据集共有599段视频,包括25名受试者在不同场景下进行的6种人类动作(拍手、挥手、拳击、慢跑、快跑和走路),分辨率为160×120像素,部分示例如图6所示。

图6 KTH数据集样例
通过OpenCV算法将视频做抽帧处理,并将训练集与测试集按照7∶3进行划分,各类样本数如表4所示。

表4 KTH数据集样本量
为了比较几种特征之间的组合效果以及滑动窗口大小对准确率的影响,本文进行了定量试验分析。首先,将滑动窗口大小固定为10帧,以验证不同特征及组合对识别率的影响。设置分组实验如下:(1)第1组实验单独使用空间几何特征,即关节点空间位置、躯干角度、躯干长度;(2)第2组实验单独使用时间运动特征,即关节点速度;(3)第3组实验将空间特征与运动特征融合。由于数据量较大,故分类器选用MLP(Multi-Layer Perceptron),隐藏层为3层,其中神经元个数分别为60、70和0,并采用ReLU作为激活函数。实验结果如表5所示。

表5 不同特征组合类型下的识别率
随后,固定使用融合特征,将滑动窗口的大小设置为2~20(单位为帧),其它参数不变。当滑动窗口为9帧时,识别的平均准确率最高,可达96.7%,如图7所示。当滑动窗口不断增大,特征的维数也随之增加。为简化特征,采用主成分分析法[13]将特征减少到固定大小,即100维,降维后的各主成分的方差值占总方差值的比例为97%以上,既保留了特征的有效主成分又减小了计算量。
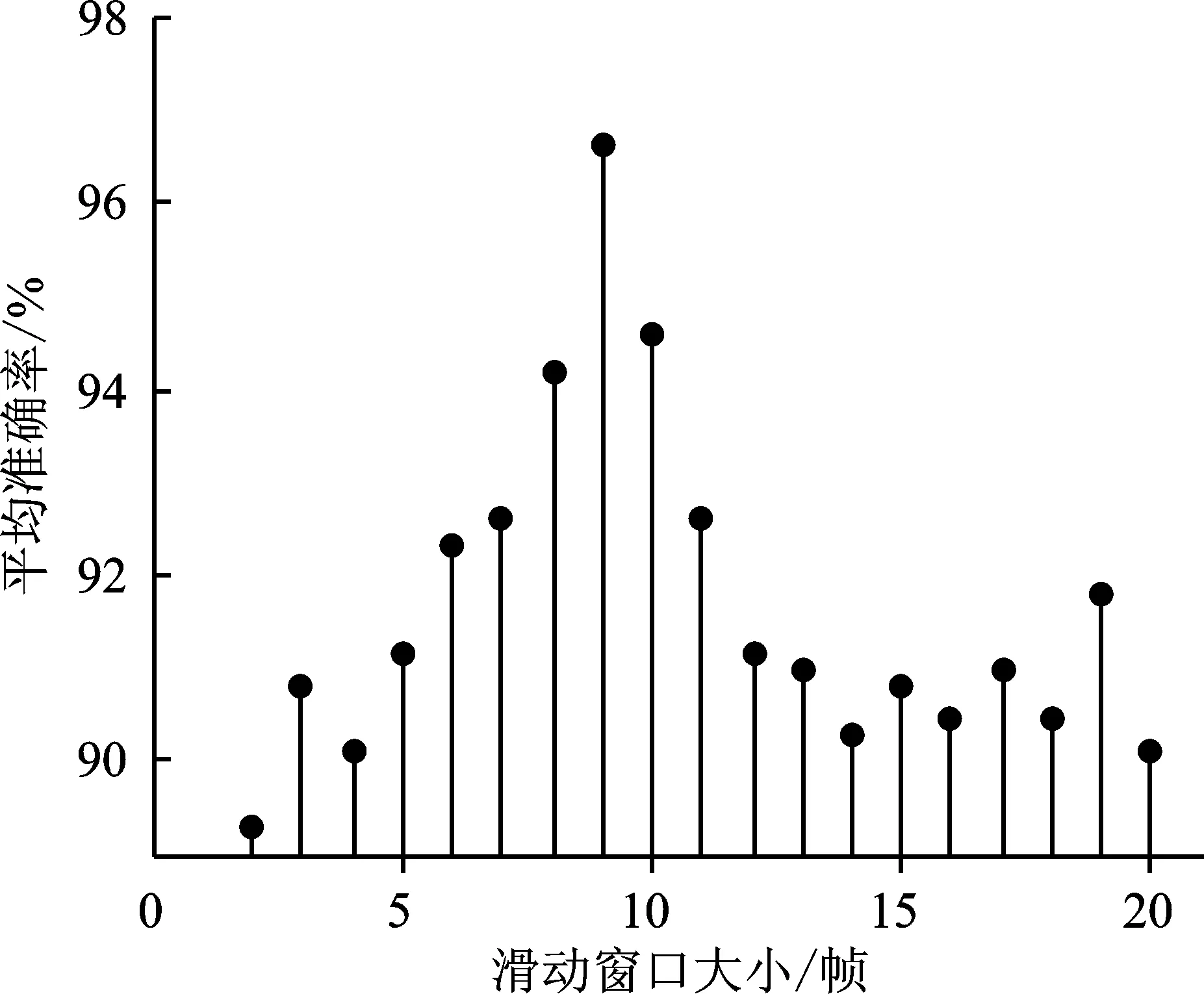
图7 滑动窗口大小对准确率的影响
从表5可以看出,单一的空间特征或运动特征在分类器中的识别率均低于融合特征,因此将空间特征与运动特征进行融合,将提升识别准确度。图8为融合特征情况下预测结果的混淆矩阵,其中“boxing” “handclapping”“handwaving”“walking”的识别准确率都达到了95%以上,而“running”和“jogging”的准确率略低,这可能是受到两者之间动作相似的影响。识别结果样例如图9所示。

图8 KTH数据集识别结果混淆矩阵

图9 KTH数据集识别样例
表6为不同方法在KTH公开数据集上的准确率对比结果。文献[14]提取光流和加速稳健特征(Speeded Up Robust Features,SUPF)后,通过支持向量机(Support Vector Machines,SVM)进行动作识别(光流+SURF)。文献[15]将图片背景减除后,提取密集轨迹(Dense Trajectories,DT)特征并结合SVM来实现(DT+SVM)。文献[16]采用卷积神经网络(Convolutional Neural Network,CNN)自动提取图像特征进行动作识别。本文提出的识别方法在该数据集上取得了较好的识别效果,证明了算法的有效性及普适性。

表6 KTH数据集不同方法准确率对比
3.2 基于八段锦数据集的建模与测试
将网上采集的3段由专业人员在不同背景、着装下的标准教学视频与个人拍摄的规范练习视频组成八段锦动作数据集,经过抽帧处理成连续图片。本文从八段锦前3个招式:“两手托天理三焦”、“左右开弓似射雕”以及“调理脾胃臂单举”中挑选了8种主要动作进行建模识别,动作样例如图10所示。

图10 八段锦数据集样例
自制数据集样本数如表7所示,训练集与测试集按7∶3进行划分。

表7 自制数据集样本量
在八段锦动作模型训练时,直接采用融合特征,使用MLP作为分类器,调节滑动窗口大小。当N=6帧时,识别的平均准确率达到98.7%。识别结果如图11和图12所示。
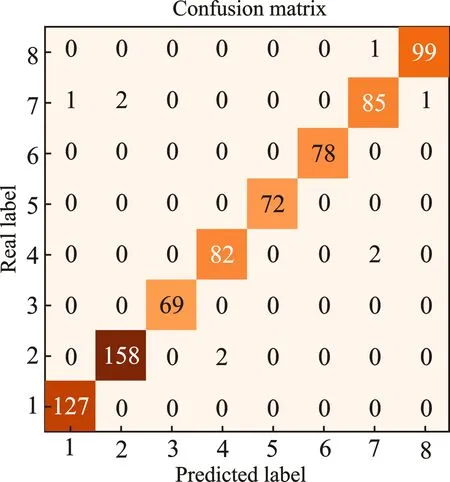
图11 八段锦动作识别结果混淆矩阵

图12 八段锦动作识别样例
4 动作序列相似性评估
经过分析,八段锦多为重复性套路动作,例如第1式“两手托天理三焦”是由图10中前3个动作循环组成,因此可以通过动作识别模块将教学视频中的动作序列提取出来,设为标准序列。对于用户练习视频,可以提取实时动作序列与标准序列进行对比,以此来进行评估。
求解序列相似性问题的常用方法有计算欧氏距离、余弦相似度和动态时间规整(Dynamic Time Warping,DTW)距离等。由于每个人的动作快慢不同,因此得到的动作序列长短也各不相同。对于长度不同的时间序列,DTW算法能更有效地求出相似度,因此本文采用DTW算法来进行序列间的比对。
4.1 DTW
DTW最早由文献[17]提出,并用于口语单词的识别。文献[18]对手势特征进行了提取,并基于DTW算法计算模板手势和实时手势之间的最短距离,实现了动态手势识别。
定义序列A(a1,a2,…,an)和B(b1,b2,…,bm)的长度分别为n和m,构造一个m行n列的矩阵网格,如图13所示。网格中第i行第j列的值表示bi与aj两点之间的距离,记为d(i,j)。根据式(6)计算A序列前j个点与B序列前i个点的累积距离D(i,j),即当前格点距离d(i,j)与可以到达该点的最小的邻近元素的累积距离之和。该距离可以表征两序列的相似度,距离越小相似度越高。

图13 DTW算法原理图
D(i,j)=d(i,j)+min[D(i-1,j),D(i,j-1),D(i-1,j-1)]
(6)
4.2 动作序列去噪与简化
采用动作识别模块处理视频后,可得到由每一帧图像动作类型构成的动作序列。由于视频帧是连续的,因此在某个连续的动作状态下,不会突变成另一个动作。根据这一点对噪声进行过滤,如图14(a)所示,连续动作1中出现了一帧动作2,则动作2被视为噪声去除。与此同时,为了简化序列,使其便于处理,本文设定了1个阈值K,将连续K帧表示同一动作的图像抽象成一个状态,过程如图14(b)所示。对于动作1和2,假设K=10,则连续10帧的同一动作将被简化成一帧。经过去噪与简化后的标准八段锦动作的模板序列如图14(c)所示。

图14 动作序列处理图
为测试该方案的可行性以及不同K值对DTW结果的影响,提取4组不同的八段锦视频:专业人员A、B的动作作为优秀动作,此外拍摄两组规范性较差的视频作为对照动作,并将所有视频统一为标准mp4格式,帧率为25 frame·s-1左右。经过动作检测与提取序列后,得到4组长度不同的动作序列,依次为0、1、2、3。分别计算不同K值情况下的DTW距离d01、d02、d03,计算结果如表8所示。

表8 不同K值下的DTW距离
由表8可知,当K取10或者15时效果较好,d01值较小且远小于d02、d03,代表两组标准八段锦动作序列距离小,相似度高;而序列2、序列3与标准序列0间距较大,意味着动作不完整,规范性差。
通过分析不同人的套路动作序列与标准序列间距离,可以评估每个人的动作完整性以及速度掌控能力,DTW值越小,则代表测试者的动作与标准动作越相似。
5 结束语
本文提出了一种基于姿态估计的人体动作识别与评估方法,利用OpenPose获取人体关键点坐标,针对人体行为特性设计了空间几何与时间运动特征。实验结果表明,构建的分类器可以有效识别日常动作及八段锦招式。本文采用的DTW算法可以有效表征练习者八段锦动作序列与标准动作序列的总体相似度,但未对关键帧动作进行细化分析,后续研究可以针对各个招式的动作细节进行量化评分,为练习者提供更为精准的练习指导。
