深度学习在阿尔茨海默病诊断中应用近5年文献的可视化分析
2022-12-20蒋嘉蕊牛振东
蒋嘉蕊,牛振东
北京理工大学计算机学院,北京市100081
0 引言
人口老龄化已成为世界性的普遍现象。预测到2030年,世界65岁以上老年人将从2000年的4.2亿增加到近10 亿[1]。阿尔茨海默病(Alzheimer's disease,AD)是一种神经退行性疾病[2],在65 岁及以上老年人中越来越普遍,其特征是神经元及其连接进行性不可逆损伤,导致认知功能下降和丧失。根据认知障碍程度,AD分为症状前、轻度认知障碍和痴呆阶段[3]。
目前,AD尚无法治愈[4],早期诊断和预防尤为重要。过去AD 的确诊多取决于患者死亡脑组织检查[5]。随着计算机技术的不断发展,计算机辅助AD 早期诊断逐渐流行,研究方法主要包括机器学习和深度学习。机器学习已被广泛应用[6]。深度学习作为机器学习的一个分支,近年来取得很大发展[7]。深度学习采用端到端的学习方式,省略图像分割、特征提取和特征选择的过程[8],分类效果优于机器学习,日益受到重视。
本文对近5 年深度学习在AD 诊断中应用研究的热点和趋势进行可视化分析。
1 资料与方法
1.1 文献检索
检索Web of Science(WoS)核心数据库。时间范围为2017 年1 月1 日至2021 年12 月31 日。检索式为deep learning AND Alzheimer disease AND disease diag‐nosis。剔除资讯、会议类论文,采用软件自带的去重功能和人工去重,删除与本主题无关、字段值缺失等文献。共检索出文献306篇。
1.2 方法
采用CiteSpace 6.1.R3 软件[9-11],分别从年发文量、国家、机构、作者、关键词、共被引文献等方面进行可视化分析。其中,时间分段选择“2017-2021”,时间分区选择“1”;阈值选择“TOP N”,N=50;网络剪裁在“Pathfinder”“Pruning the merged network”和“Pruning the sliced networks”三种算法中选择。
2 结果
2.1 年发文量
近5 年来,深度学习在AD 诊断相关领域研究热度逐年递增,发文量呈上升趋势,见图1。

图1 相关文献年发文量趋势图
2.2 国家/地区
节点设定为Country,得到55 个节点,105 条线(图2)。发文量最多的国家为中国102 篇,其次是美国76 篇,韩国42 篇,英国31 篇,印度28 篇。中心性最高的国家是美国0.56,其次为西班牙0.25,英国0.21,德国0.20,韩国0.19。美国、韩国、英国在发文量和中心性方面均处于领先,在该领域具有重大影响力。我国发文量虽排名第1,中心性只有0.05。

图2 国家/地区合作网络
2.3 机构
节点设定为Institution,得到662 个节点,1 738条线(图3)。发文量最多的机构为中国科学院10 篇,其次为高丽大学9 篇,深圳大学8 篇,北卡罗来纳大学8 篇,上海交通大学8 篇。中心性最高的是中国科学院0.17 和中国科学院大学0.13,其次为南京航空航天大学0.13、高丽大学0.11、北卡罗来纳大学0.11。

图3 研究机构合作网络
2.4 作者
节点设定为Author,得到876 个节点,2 760 条连线。发文量最高的作者是Liu M (11 篇),他提出一种基于卷积神经网络(convolutional neural network,CNN)的多模型深度学习框架,用于结构MRI数据进行海马自动分割和AD 分类[12-13]。发文量排名前5 的还有Zhang Y[14-15](10 篇)、Wang Y[16](9 篇)、Liu Y[17](8 篇)、Kim J S[18](7篇)。
2.5 关键词
2.5.1 突显分析
节点设定为Keyword 进行突显分析,出现5 个突显关键词(图4),分别为AD 疾病诊断、鲁棒性、网络、连接性、人工神经网络。越来越多的模型关注鲁棒性,有研究提出一种通用算法来训练数据不完整的LSTM网络,提高模型的鲁棒性[19]。

图4 关键词突显分析
2.5.2 共现分析
节点设定为Keyword,得到259个节点,959条线(图5)。除检索词外,频次排名前5的关键词依次是轻度认知功能障碍、分类、磁共振成像、CNN 和痴呆。中心性排名前5 的关键词依次是选择、静息态磁共振成像、迁移学习、特征排序和结构磁共振成像(struc‐tural MRI,sMRI)。见表1。

图5 关键词共现图

表1 高频及高中心性关键词
2.5.3 聚类分析
节点设定为Keyword,通过LLR 进行聚类,Mo‐dality Q=0.67,Mean Sihouette=0.86,聚类结构显著,且聚类效果良好[20]。见图6和表2。
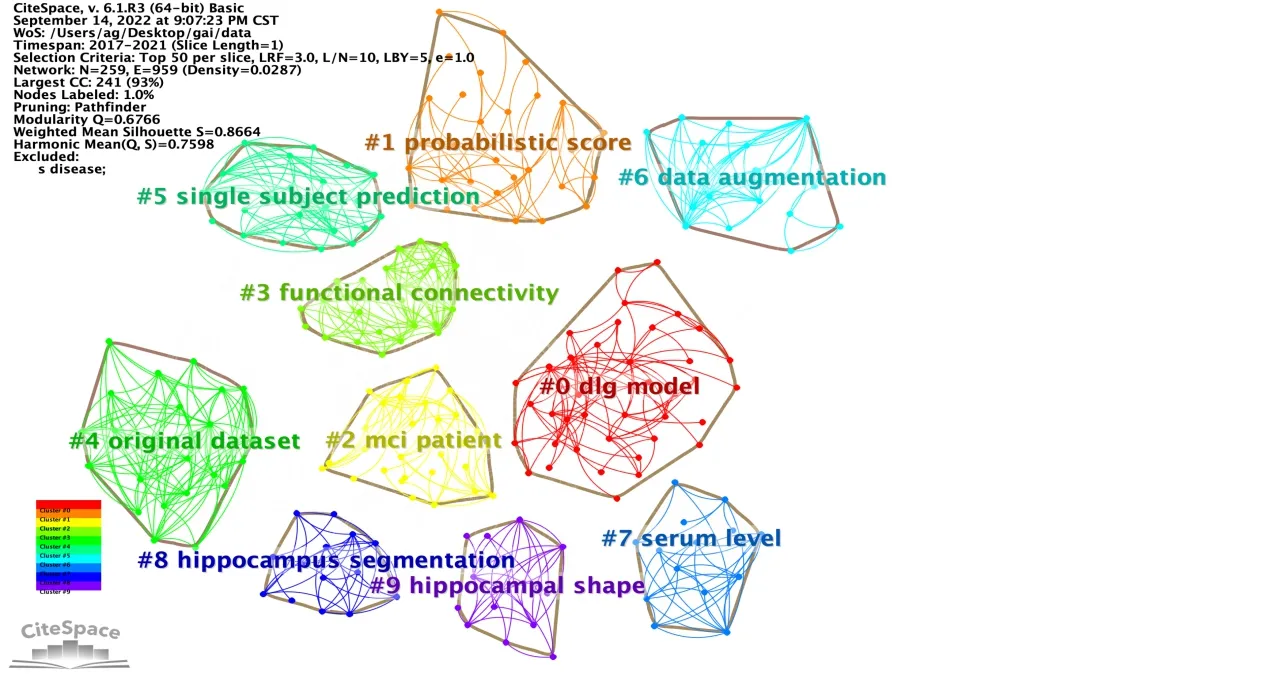
图6 关键词聚类

表2 主要聚类及其包含关键词
应用的医学影像技术主要有sMRI、正电子发射断层扫描(positron emission computed tomography,PET)、功能磁共振成像、脑电图。sMRI 可以无创地捕捉AD 患者脑萎缩的演变[21]。正电子发射断层扫描可通过注入放射性示踪剂捕捉AD 典型的淀粉样沉积[22]。功能磁共振成像是分析大脑网络功能连接的主要神经影像模式[23]。脑电图是一种低成本、无创的测量网络,可以记录大脑的电活动,脑电图的异常,如节律减慢、复杂性丧失和通道之间的同步改变,可能提示脑退化[24]。
常用数据集有阿尔茨海默病神经影像学倡议(Al‐zheimer's Disease Neuroimaging Initiative,ADNI)、开放获取系列成像研究数据集(Open Access Same Time Information System,OASIS)。ADNI 的主要目标是测试MRI、PET 和其他生物标志物,以及临床和神经心理评估是否可以结合起来测量轻度认知障碍和早期AD 的进展[25-26]。OASIS 由横断面和纵向面数据集组成,是仅次于ADNI 的核心数据资源[27]。针对AD 检测的心理测试主要包括简易精神状态检查[28]。AD 早期诊断问题主要可以分为三类:二元分类[29-30]、多元分类[31]和预测[32]。采用的深度学习结构主要有CNN 和深度生成模型(deep generative model,DGM)。CNN 包括2D-CNN[33]和3D-CNN[34-35]两种。DGM 包括自编码器[36-37]、深度信念网络、受限玻尔兹曼机[38-39]。
2.6 参考文献
2.6.1 共被引分析
节点设定为Reference,被引频次排名前5 的文献见表3。其中Liu 等[40]Multimodal neuroimaging feature learning for multiclass diagnosis of Alzheimer's disease被引频次最高,该研究设计一种基于多层神经网络的新型诊断框架,融合多模式神经成像特征以帮助诊断AD,在AD 二元分类和多元分类中都实现了性能提升。Basaia 等[41]Automated classification of Alzheimer'sdisease and mild cognitive impairment using a single MRI and deep neural networks通过比较来自不同中心、神经成像协议和扫描仪的数据,克服数据来源单一的限制,达到结果的可靠性和可重复性。

表3 高频次被引文献
2.6.2 突显分析
节点设定为Reference 进行突显分析(图7)。Suk等[42]Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis突显时间最早,研究使用堆叠自编码器学习用于AD 分类的MRI和PET脑图像的多层次和多模态特征。

图7 参考文献突显分析
3 讨论
本研究采用CiteSpace 对近5 年深度学习在AD 诊断中的应用的相关文献进行可视化分析,结果显示,发文量逐年增加,说明深度学习在AD 诊断领域的可行性。美国、韩国、英国在发文量和中心性方面均领先。我国发文量虽排名第1,但中心性只有0.05,未来应注意增加与其他国家的合作,提高国际影响力。
AD 诊断越来越依赖于脑影像技术。通过对关键词和参考文献的分析发现,该领域使用的医学影像技术主要有MRI、PET、脑电图等。早期研究多采用单一脑影像技术即单模态神经成像方法进行辅助诊断,近年来倾向采用多种医学影像技术整合,即多模态成像方法进行辅助诊断。多模态成像方法的时间和空间分辨率更好,具有生物信息功能互补等特性,在分类上也更具优势[43]。由上述技术采集的数据形成数据集,常用有ADNI 和OASIS。进一步研究应将上述数据与临床和神经心理评估数据及其他生物标志物相结合,以提高分类和预测的准确性。
AD 早期诊断问题主要分为3 类:二元分类[28-29]、多元分类[30]和预测[31]。目前的研究多集中在对AD 早期诊断的二元、多元分类,对于MCI 到AD 转换预测的研究较少。
CNN 是最多研究者选择的深度学习模型[44]。深度学习能进行数据驱动的自动特征学习,消除了选择相关特征的主观性。通过应用非线性的层次结构,深度学习能够对非常复杂的数据模式建模。采用深度学习方法进行AD诊断的准确率不断提高。
采用深度学习进行AD 诊断也存在一些问题。标记AD 诊断医学图像是一项耗时且昂贵的任务[45];当前数据样本量尚不充分,而依靠数据增强和迁移学习缓解数据量不足问题的技术仍有局限[46]。进一步研究要不断降低数据采集成本、并尽可能采集互补性更强的多模态数据,不断丰富研究数据;应优化基准测试平台,探索不同数据模式之间的关联,克服因数据集、分类模式和受试者数量差异造成的研究间无法比较的局限,提高模型预测精度。
本研究选用单一数据库进行分析,对年份、语种、文献类型进行了限制,导致许多研究未纳入统计,有待进一步完善。
利益冲突声明:所有作者声明不存在利益冲突。
