面向端到端目标检测神经网络的高效硬件加速系统设计
2022-12-20任仕伟刘朝钾李剑铮蒋荣堃王晓华薛丞博
任仕伟,刘朝钾,李剑铮,蒋荣堃,,3,王晓华,薛丞博
(1. 北京理工大学 集成电路与电子学院,北京 100081;2. 北京理工大学 重庆创新中心,重庆 401120;3. 北京理工大学 重庆微电子中心,重庆 401332)
卷积神经网络(convolutional neural networks, CNN)正广泛应用在计算机视觉领域[1]. 其中,图像目标检测作为计算机视觉中最重要的应用之一,正被使用在自动驾驶、安全防卫、姿态识别、医疗卫生、多目标检测等领域[2−4]. 但随着CNN 规模的不断扩大,海量浮点运算对计算平台的处理能力产生了更高的要求. 具备较高运算性能的图形处理器(graphic processing unit, GPU)由于高功耗和低硬件资源利用效率,令其无法搭载在功耗敏感且资源受限的边缘计算设备中. 而现场可编程门阵列(field programmable gate array, FPGA)平台由于其并行架构、低功耗等特性,正被广泛应用在硬件资源受限型与功耗敏感型设备中[5]. 因此,设计适用于FPGA 平台的高效目标检测CNN 硬件加速器是当前重点的研究方向.
目前,YOLO[6]及其演进版本YOLOv2[7]、YOLOv3[8]作为一阶CNN 目标检测器的代表,正得到广泛的应用. 而YOLOv3 相较于YOLOv2 引入的多尺度检测方案及更精细的网络结构虽增加了硬件加速器的设计复杂度[9],但也使其获得了更好的检测能力. 同时,YOLOv3-Tiny 在运算量及参数量上相较于YOLOv3标准模型均有更大程度的缩减,更适用于轻量化的边缘计算设备使用.
近期,基于FPGA 实现的YOLOv3-Tiny 硬件加速架构被相继提出[10−14]. YU 等[10]提出了一个基于FPGA 定 制 的 轻 量 化YOLOv3-Tiny 架 构,ZHEN 等[11]则通过优化算法提升卷积效率,YU 和ZHEN 利用FPGA 较少的片上硬件资源即实现了YOLOv3-Tiny硬件加速,但由于其数据吞吐量较低,仅分别能实现1.9 FPS 与4.6 FPS 的检测帧率,基本不具备实时检测能力. AHMAD 等[12]利用高性能FPGA 的硬件资源优势实现了一个高吞吐量的YOLOv3-Tiny 网络,但其硬件资源利用效率较低,且大量DSP 硬件资源的使用令其不利于在小型FPGA 上实现. 综上所述,为获得检测速度、检测精度及硬件资源的平衡,本文通过网络结构重组、层间融合与动态数值量化方式缩减YOLOv3-Tiny 网络规模;提出基于通道并行与权值驻留的硬件加速算法与基于乒乓存储阵列的紧密流水线处理流程,并复用硬件运算单元;最后构建目标检测硬件加速系统实现高效准确的端到端目标检测,并有效提升硬件资源利用效率.
1 目标检测神经网络与模型优化
1.1 YOLOv3-Tiny 网络与结构重组
待测图像输入至YOLOv3-Tiny 网络进行处理,并使用非极大值抑制算法(non-maximum suppression,NMS)[15]筛除重叠目标后可直接得到目标检测结果.YOLOv3-Tiny 网络由卷积(Conv)层、最大池化(Maxpool)层、批归一化(batch normalization, BN)层[16]、激活函数(ACT)层、填充(Pad)层、上采样(Upsample)层、拼接(Concat)层共同构成,其中激活函数层包括LeakyReLU 与Sigmoid 两类. 本文以卷积运算为中心重组网络,其他处理则设置在卷积运算前后,如图1所示. 网络由14 层以卷积运算为中心的网络层构成,图例为各网络层的组成,序号表明网络模型中每层网络与网络层类型的对应关系及执行顺序. 通过上述网络层的组合运算实现与YOLOv3-Tiny 原型网络完全一致的多尺度推理流程,并适应硬件加速器的流水线处理设计.

图1 YOLOv3-Tiny 神经网络重组结构Fig.1 YOLOv3-Tiny neural network reconstruction structure
1.2 层间融合
卷积层负责提取图片特征信息,其表达式为

式中:IF表示输入特征图;W表示权重;B表示偏置;OF表示输出特征图;IC为输入通道;S为卷积步长;K为卷积核大小;oc为输出特征图通道;w与h为输出特征图内行列位置. 式(1)可被简化为

BN 层置于卷积层后,缓解网络训练过程中过拟合问题并加速训练收敛,其表达式为

式中 γ 、 β、x¯、 σ2参数均在网络训练过程中生成,并在推理过程中保持不变. 式(3)中OF为卷积层的输出,将式(2)代入式(3)中,可得

令式(4)中第一项与第二项系数分别为B′与W′,则将卷积层与BN 层融合. 层间融合后的权重W′与偏置B′由本地端通过式(4)预处理后再导入至FPGA 存储空间内,即可在硬件加速器中避免复杂的BN 层运算,节省硬件资源开销.
1.3 动态数值量化
若直接使用在GPU 平台训练得到的32 位浮点型参数输入至FPGA 平台进行推理运算,将消耗大量硬件资源以实现浮点运算[17]. 同时,32 位浮点型参数相对于量化数据位宽较大,需占用更大的DDR 数据传输带宽. 故需采用数值量化,用整型运算替代浮点运算,以获取硬件加速器运算性能的提升. 本文采用的数值量化表达式为

式中:float表示32 位浮点型数值;fix表示运算后的量化整型值;FIX_L表示量化宽度;FRAC_L表示小数位数;Round()对数值四舍五入取整;Clamp()将数值限定在量化整型值所能表示的最大范围内.
为兼顾检测精度与检测速度,本文采用16 位量化宽度进行数值量化. 同时,在不同网络层间采用不同的小数位宽度对权重、偏置及特征数据进行量化,即动态量化,以满足模型中不同网络层对小数位数的需求,提升模型精度.
2 硬件加速算法与流水线处理设计
2.1 基于通道并行与权值驻留的硬件加速算法
本文基于通道并行与权值驻留的硬件加速算法流程如图2 所示. 启动硬件加速算法后,读取双倍速率(double data rate, DDR)同步动态随机存储器指定地址空间内数据,在全部输出通道上与卷积核执行并行运算,依序执行循环,直至输出特征图数据均被回写至DDR 内. 通过并行加速算法,FPGA 平台的并行架构得到充分利用,有效提升了硬件加速器的吞吐量.

图2 硬件加速算法流程图Fig.2 Flow chart of hardware acceleration algorithm
硬件加速器在处理过程中需以直接存储访问(direct memory access, DMA)方式对数据传输带宽有限的片外DDR 发起大量数据访问请求,将增加数据读取至片内的等待时间. 本文采用权值驻留方式以减少访问片外DDR 的次数. 通过设置片上权重存储(random access memory, RAM),将本轮所需全部权重数据从DDR 中读取至该RAM 后,后续读取请求可直接从片上权重RAM 内获取权重数据,避免了读取权重数据对DDR 传输带宽的占用,减少了数据读取操作的总耗时.
2.2 基于乒乓存储阵列的加速器流水线处理流程
本文基于乒乓存储阵列设计的硬件加速器紧密流水线处理流程如图3 所示. 加速器需完成DDR 数据读取、运算处理及DDR 数据回写3 种操作. 通过设置两组完全相同的片上存储阵列,加速器交替向输入缓冲存放从DDR 读取的数据,并将输出缓冲内数据回写至DDR,有效缩短运算处理操作等待数据读写的空闲时间,并使得加速器处理总时间由耗时最长的操作决定,详细的系统性能评估方案于3.5 节提出.

图3 硬件加速器的流水线处理流程Fig.3 Pipeline processing flow of hardware accelerator
3 目标检测硬件加速系统设计
3.1 目标检测系统总体架构
基于FPGA 的目标检测神经网络系统总体架构如图4 所示,由处理器系统(processor system, PS)以及可编程资源(programable logic, PL)端的硬件加速器组成,通过用户数据报协议(user datagram protocol,UDP)与上位机互联,实现端到端的目标检测. 神经网络硬件加速器以运算处理器(processing engine, PE)阵列为核心,与片上存储阵列、池化阵列以及激活函数阵列进行数据交互与运算处理.

图4 目标检测硬件加速系统总体架构Fig.4 Overall architecture of object detection hardware acceleration system
本系统PEs 阵列包含的PE 数量由NPEs参数确定,每个PE 负责一个输出通道上的数值运算,其余模块均依据NPEs参数作相应变化,具有良好的可扩展性,其数量关系如表1 所示. 片上权重RAM 与权重寄存器阵列位宽均为144 bit,以同时读取单个卷积核3×3×16 bit 的参数量,MAX_IC表示权重RAM 中可驻留权重的最大输入通道数. 144 bit 位宽的输出数据RAM 与池化数据RAM 可同时存储9 组PEs 阵列或池化阵列的16 bit 输出数据,故其仅需PEs 数量的1/9 即可存储全部输出数据,ceil()为向上取整函数. 同时,输入数据RAM、输出数据RAM、池化数据RAM、权重存储阵列均以2.2 节中所描述的乒乓存储方式构建,故数量均为需求值的两倍,以实现PEs 阵列的紧密流水线运算,节约等待数据缓冲的时钟周期.

表1 硬件加速器各模块设置与数量Tab.1 Setting and number of hardware accelerator units
3.2 运算处理器设计
运算处理器负责特征图数据与权值的乘加、偏置及输入通道维度上数据的累加、数据溢出处理与动态量化4 种操作,其硬件结构如图5 所示.
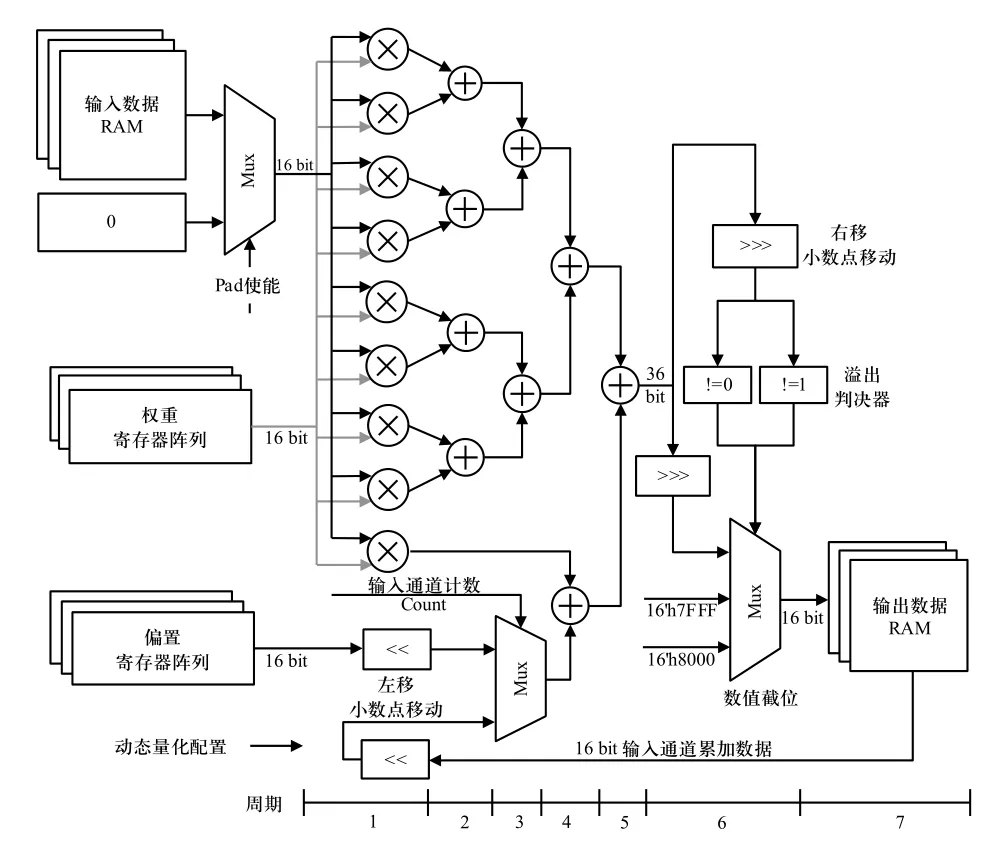
图5 运算处理器PE 的硬件结构Fig.5 Hardware structure of processing engine
每个PE 由9 个16 bit 乘法器及其它运算与控制逻辑组成. 输入数据选择器(Mux)可控制输入零元素以实现特征图边缘填充. PE 内部为全流水线架构,支持数据的连续输入与运算. 最后PE 需完成数据溢出处理,输出数据将被限定在量化宽度可表示的范围内. PE 中的左右移位模块根据量化参数配置完成数据截断和待加数的小数位对齐. 为实现1×1 卷积运算,将3×3 卷积核矩阵除(0,0)位置的元素设置为0,并仍按3×3 卷积流程运算,通过该设计即可复用PE 完成不同卷积核尺度的运算.
3.3 池化单元与激活函数单元设计
池化单元与激活函数单元的硬件结构如图6 所示,负责对PEs 输出数据做池化与激活函数处理.
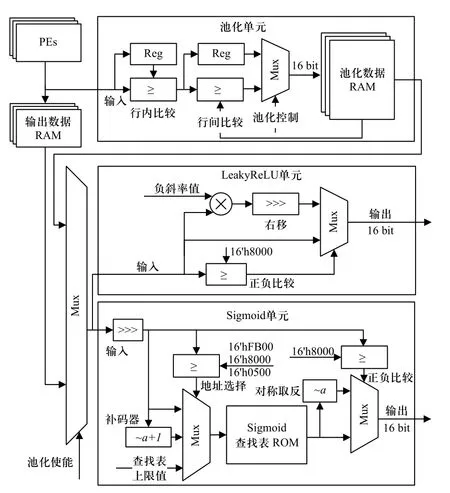
图6 池化单元与激活函数单元的硬件结构Fig.6 Hardware structure of pool unit and activation unit
若硬件加速器使能池化单元,则PEs 的运算结果被直接输入至池化单元以流水线方式处理,避免了卷积层与池化层间数据对片外DDR 的反复读写.该单元利用缓冲寄存器Reg 实现行内数值比较,利用池化数据RAM 回环实现行间数值比较,其由外部状态机控制,以相同硬件结构实现任意步长的池化运算.
激活函数单元包括LeakyReLU 单元与Sigmoid单元,在数据回写至DDR 前实现激活函数处理.LeakyReLU 单元利用一个乘法器实现对输入值的非线性处理. Sigmoid 单元使用查找表构建,由于Sigmoid 函数关于(0,0.5)中心对称,且在输入大于+5 时输出值相似,故查找表ROM 内仅存储输入为0~+5范围内1 280 个采样点的Sigmoid 函数输出值,通过两组Mux 实现地址选择与输出数值中心对称处理,以片上ROM 替代了Sigmoid 函数中指数、除法等硬件难以实现的结构.
3.4 数据存储与读写处理流程设计
片外DDR 内数据存储方式与片上数据处理流程需和所设计的硬件加速器流水线相匹配,本节以3×3 卷积运算为例说明,如图7 所示. 每层输入特征图dihw与输出特征图oohw按照相同顺序存放在DDR内,以使本层的输出特征图可按相同存储顺序直接作为下一层的输入特征图被读取. 由于采用输出通道并行方式执行卷积运算,每一轮次处理需读取单个输入通道下对应的全部输出通道的权重,因此权重数据wiokk按照输出通道优先方式存储于DDR 内,可使权重数据读取时地址连续,增加猝发读取长度,提升权重数据的读取速率.

图7 数据存储方案及读写处理流程Fig.7 Scheme of data storage and flow of read and write processing
在启动硬件加速器后,首先执行第1 轮DDR读取操作,加速器读取输入特征图d[0,0:2,:]与权重w[0,:,:,:]至片上存储阵列,并以并行滑窗方式完成第一轮卷积运算,随后读取DDR 中d[1,0:2,:]与w[1,:,:,:]完成第2 轮数据读取与卷积运算. 经过i轮处理后所有输入通道的前3 行数据均完成卷积与累加处理,得到所有输出通道下对应的第1 行输出数据. 此时执行第1 轮DDR 写入操作,将数据分别回写至DDR内的o[:,0,:]中,完成单行输出特征图数据的存储. 以此类推,直至完成本层硬件加速处理.
池化单元与激活函数单元均可在PEs 卷积处理后使能或旁路,仅增加数据处理流水线长度而不改变数据读写及处理的流程. 上采样在读取输入特征图数据时实现,在行内读取每个特征图点时,数据经复制后再写入输入数据RAM 内实现行内上采样,同时需对同一行数据进行两次读取以实现行间上采样.拼接层需读取DDR 不同地址空间内的两层特征图数据,因此仅需通过改变读取地址即可实现特征图的拼接操作.
3.5 系统性能评估
单轮硬件加速器处理的各部分理论耗时如式(6)所示,分别为DDR 数据读取时间Tread,PEs运算处理时间Tprocess与DDR 数据回写时间Twrite.WDDR表示DDR 的数据传输带宽,Tread由所需读取的输入特征图及权重总数据量与DDR 数据传输带宽之比得到,由于单轮处理中只读取一次偏置数据,故读取偏置时间可被忽略.Tprocess由单轮硬件加速器处理所需总周期数与加速器运行时钟频率fCLOCK之比获得. 所需写入的输出特征图总数据量与DDR 数据传输带宽之比即为DDR 数据回写时间Twrite.

由于硬件加速器的紧密流水线处理流程,其单轮次处理的理论总时间由3 个时间中的最大值决定.同时,设计采用输出通道并行架构,通道并行数量与NPEs参数相同,当网络层的输出通道数O大于NPEs时,需启动多轮硬件加速器处理以完成单层网络层内所有输出通道的运算. 因此,单层网络层处理的理论总时间如式(7)所示.

4 实验结果与分析
4.1 实验环境建立
本文采用UltraScale+ XCZU9EG 作为测试平台,所设计的硬件加速器以Verilog 语言编写并通过Vivado 软件综合实现. ARM 处理器可向硬件加速器发送控制指令,实现不同参数配置下的硬件加速运算,并通过控制UDP 加速器实现数据高速传输. 同时,本文基于C#语言实现上位机软件,其通过UDP网络与硬件加速系统通信,并利用多线程技术向FPGA 传输待测图像或对FPGA 回传特征图进行后处理与结果显示. 上位机与硬件加速系统以流水线处理各任务,使系统具备高速连续的目标检测能力. 以上模块共同构成基于YOLOv3-Tiny 的端到端目标检测硬件加速系统,系统实物图如图8 所示.

图8 目标检测硬件加速系统实物Fig.8 Hardware acceleration system of object detection
4.2 测试结果及性能评估
在实际测试环境下,本文以硬件加速器每秒钟可执行乘加操作数(giga operations per second, GOPS,G为109次)评估其整体吞吐量与性能,其由单张待测图像在网络推理过程所需的理论乘加操作数与实际检测执行时间的比值确定. 同时,根据吞吐量GOPS 与FPGA 片上LUT、BRAM、DSP 硬件资源使用量的比值评估其片上各硬件资源利用效率. 其中,DSP 作为FPGA 中最关键且稀缺的高速乘法运算硬件资源,因此DSP 效率是评估硬件加速器整体效率的关键指标.
为达到系统性能与硬件资源效率间的平衡,本文设置NPEs为32、MAX_IC为512 对硬件加速器进行FPGA 综合实现. 硬件加速器运行频率为300 MHz,功耗为4.12 W,其使用了36.0 k LUT、41.3 k FF、199 BRAM36k、298 DSP 的FPGA 硬件资源,达到了96.6 GOPS 的吞吐量与17.3 FPS 的检测帧率,其具有0.32 GOPS/DSP 的DSP 效 率,2.68 GOPS/kLUT 的LUT 效率与0.49 GOPS/BRAM 的BRAM 效率.
在使用浮点数值的GPU 平台与在本文使用动态量化数值的FPGA 平台分别执行YOLOv3-Tiny 神经网络,对MS COCO 2017 验证集进行目标检测,其部分结果如图9 所示. 经测试,使用动态量化数值的FPGA 平台的检测精度mAP50为31.5%,相较于使用浮点数值的GPU 平台仅下降1.6%. 在可接受的检测精度损失下,缩减了网络规模,提升了FPGA 硬件加速器整体运算性能.

图9 目标检测结果对比Fig.9 Comparison of object detection results
YOLOv3-Tiny 目标检测网络在本文FPGA 硬件加速器与在CPU、GPU 平台上实现的性能对比如表2 所示,输入图像像素尺寸为416×416. 本文所设计的硬件加速器吞吐量为96.6 GOPS,是CPU 平台的1.1 倍,但功耗相较于CPU 平台下降了15.8 倍. GPU平台的功耗是本文硬件加速器的53.4 倍,但吞吐量仅增加16.5 倍. 从能效比上看,相较于GPU 与CPU,本文硬件加速器分别有3.2 倍与17.4 倍的提升,具有最佳的能效比. 同时,本文设计的硬件加速器功耗仅为4.12 W,更适用于功耗敏感型的边缘计算设备.

表2 与CPU 和GPU 计算平台的性能对比Tab.2 Comparision with CPU and GPU computing platform
4.3 性能对比及分析
本文设计的基于FPGA 的YOLOv3-Tiny 硬件加速器与先前其他同类硬件加速器[10−14]的性能对比结果如表3 所示. 本文的硬件加速器吞吐量与DSP 效率分别为96.6 GOPS 与0.32 GOPS/DSP. 与YU[10]的设计相比,本文的硬件加速器吞吐量与DSP 效率分别是其9.2 倍与4.6 倍. ZHENG[11]使用优化算法提升卷积效率,本设计的吞吐量与DSP 效率分别是其4.2倍与2.0 倍. AHMAD[12]使用了7.7 倍于本设计的DSP数量实现加速器,但吞吐量仅提升了4.8 倍,同时其硬件部分设计仅包含卷积和BN 层处理且报告的是理论峰值吞吐量,而本设计实现了所有网络层的加速功能,DSP 效率是其1.6 倍. PESTANA[13]设计的全可配加速器利用2.8 倍于本设计的DSP 实现,但吞吐量仅提升了1.9 倍,硬件资源利用效率较低,本设计的DSP 效率是其1.5 倍. ADIONO[14]使用通用卷积乘法实现加速器,本文根据其报告的执行时间将原文的峰值吞吐量转换为整体吞吐量,本文性能与DSP效率分别是其2.1 倍与1.7 倍. 综上所述,本文提出的基于YOLOv3-Tiny 网络的目标检测硬件加速器在保持较高整体吞吐量的同时减少了硬件资源使用量,与其他文献相比具备最佳的DSP 效率与LUT 效率以及良好的BRAM 效率,平衡了系统性能与硬件资源用量的关系,更适用于在硬件资源敏感型设备中实现高效端到端目标检测.

表3 与其他YOLOv3-Tiny 硬件加速器的性能对比Tab.3 Performance comparision with other YOLOv3-Tiny hardware accelerator
5 结 论
本文提出了一种基于YOLOv3-Tiny 网络的端到端高效目标检测硬件加速系统. 通过网络结构重组、层间融合与动态数值量化方式实现网络模型缩减,并基于通道并行与权值驻留的硬件加速算法与紧密流水线处理流程实现了硬件加速器的高效处理. 最后,设计了一套基于FPGA 的目标检测硬件加速系统. 与其他同类硬件加速器相比,拥有最佳的DSP与LUT 硬件资源利用效率,并具备高效准确的端到端目标检测能力,适合在硬件资源敏感与功耗敏感的边缘计算设备中应用.
