联合多视角互投影融合的三维目标检测方法
2022-12-20赵亚男王显才高利刘语佳戴钰
赵亚男,王显才,高利,刘语佳,戴钰
(1. 北京理工大学 机械与车辆学院,北京 100081;2. 天津航海仪器研究所,天津 300130)
环境感知是智能车辆关键性技术,通过车载传感器获取周围环境信息,然后对信息做出分析反馈,主要任务之一是进行目标检测. 目标检测主要包含两个阶段:感兴趣区域生成阶段;三维包围框回归阶段,主要进行感兴趣区域提炼,划分目标类别及尺寸[1−2].
目前普遍采用多传感器融合的方式进行目标检测,主要有决策级融合与特征级融合两种方式. FpointNet[3]是一种典型的基于决策级融合二维区域建议网络,从图像中提取二维感兴趣区域,投影到三维激光雷达点云中获得三维视锥,之后输送到Point-Net 为基础的目标检测网络,进行三维包围框预测.ASVADI[4]等利用YOLOv3 网络,将RGB 图像和点云深度图与反射强度图结合,进行特征层融合. 姚钺等[5]利用Pointnet++提取特征并进行目标分类与包围框回归. VORA 等[6]提出了PointPainting 特征融合模式,将激光雷达点云数据投影到图像坐标,将图像上的分类关联到激光雷达点云,被赋予分类权重的激光雷达点云作为不同目标检测网络(如Point RCNN[7],Second[8],VoxelNet[9],PointPillar[10]等)的输入,增强分类性能.CHEN 等[11]提出一种多视图多模态融合模型-MV3D 网络,在激光雷达点云鸟瞰图上提取三维区域建议,投影到激光雷达前视图与图像平面,提取感兴趣特征,通过多次融合回归得到目标类别与三维包围框. SINDAGI 等[12]提出了MVX-Net 网络,将激光雷达点云数据投影到图像特征空间并体素化,非空的体素投影到图像特征空间后获得体素特征,输入到VoxelNet 网络中. SONG 等[13]将图像颜色信息扩展到体素通道,引入3D 离散卷积神经网络改进目标检测网络.
基于多传感器的目标检测方法虽然可以改善单一种类传感器局限[14],但是当前检测方法多集中于决策级融合,并且不同传感器信息分支在训练中容易退化,导致信息不能完全利用,并且对小尺度目标检测精度都有待提升.
文中提出一种基于图像和激光雷达点云数据的联合多视角目标检测方法,利用包含特征级和决策级融合的AVOD 网络,通过对多视角信息标注损失函数的优化,避免图像分支网络在训练时退化. 通过互投影池化层对不同模态数据进行特征级融合,对网络目标检测性能有所提高,尤其对小尺度如行人和骑车人目标检测精度提高显著.
1 联合多视角目标检测网络
网络使用来自激光雷达点云鸟瞰图数据和相机前视图RGB 图像数据,在两个阶段均进行融合操作,融合与检测在网络内不断交替进行,是包含特征级和决策级融合的深度融合网络. 文中整体框架如图1 所示.

图1 三维目标检测网络框架Fig.1 3D object detection network framework
联合多视角目标检测网络(AVOD)利用激光雷达和图像的信息进行融合,包括两个阶段:初始预测和检测回归. 分别包含数据预处理、特征提取、候选框推理、候选框融合、候选框筛选;候选框投影、特征融合、推理航向角、三维包围框尺寸、目标类别.其框架如图2 所示.

图2 联合多视角目标检测深度融合网络系统架构Fig.2 The architecture of deep fusion network system for joint multi-view target detection
1.1 特征提取与区域建议网络
AVOD 网络第一阶段由特征提取网络和区域建议网络组成,初步完成精度较低、召回率较高候选框的生成,尽量避免漏检.
1.1.1 多尺度特征提取网络
特征提取网络综合了VGG-16 网络和特征金字塔网络(FPN)结构[15]. 选定原型为VGG-16 的特征提取器,将各自模态信息进行特征提取. 网络层数加深后,仅VGG-16 特征提取器得到的特征图分辨率会越来越低,对于小尺度目标而言,其特征随着不断的下采样而丢失,使得网络丢失小尺度目标检测能力,因此引入特征金字塔以解决多尺度目标特征提取问题.特征金字塔的结构可以获得所需的深层次网络蕴含的语义信息,同时保留浅层网络蕴含的原始细节信息.
特征金字塔是编码器加上解码器结构,编码由VGG-16 完成,解码是一个通过逐步分层恢复分辨率的过程,利用反卷积对上一特征图进行上采样,保证提升分辨率的同时保留高层语义信息.
1.1.2 空间3D 候选框生成
首先进行空间3D 先验框的构建. 先验框是一系列被预设好具有不同尺寸、宽高比的框,旨于尽快对目标定位,提高召回率,引入3D 先验框对激光雷达点云鸟瞰图进行目标先验框的处理. 通过K-means聚类得到样本先验框尺寸,以轴对齐的方式编码获得6 个参数(cx,cy,cz,dx,dy,dz)表示的先验框,其中(cx,cy,cz) 为中心点坐标,(dx,dy,dz)为先验框各维度尺寸. (cx,cz) 在x、z平面上采样,间隔为0.5 m,cy取决于传感器与地面垂向距离.
该网络将车辆聚类为两种尺寸,将行人与骑车人聚类为一种尺寸,每种尺寸设置两个角度(0°、90°)的位姿,粗略表示目标的不同航向角. 需要筛选并移除稀疏激光雷达点云得到的空白先验框,保证每帧数据10 k~100 k 个有效框. 根据空间3D 先验框获取不同模态下的特征图区域,并将有效框通过坐标转换分别投影到鸟瞰图和RGB 图像上,经过裁剪及双边滤波调整分辨率为3×3,便于进行区域融合.
对于复杂场景而言,先验框数量可能保留到100 k,需要使用1×1 卷积核对特征图降维以减轻后续网络运算负担,其作用体现在保留不同维度信息的同时大幅减少运算量,同时实现不同模态特征图跨通道特征级融合. 拼接不同模态的同一先验框中特征图进行拼接,再利用1×1 卷积对新张量进行卷积运算.

式中: ωi为待学习的权重;fo为特征图每个通道包含像素值;b为偏移量.
之后将融合后的特征图送到两个全连接层,进行前背景推理和三维包围框回归,得到规范化后的参数( ∆tx,∆ty,∆tz,∆dx,∆dy,∆dz) ,其中( ∆tx,∆ty,∆tz)是规范化后的中心偏移量,( ∆dx,∆dy,∆dz)为规范化后的尺寸缩放量.

损失函数计算采用Smooth L1 与交叉熵函数的多任务策略,对三维包围框和目标二元分类分别进行计算,损失函数为

式中:i为先验框序号;pi为此先验框被判定为目标的概率;ti为 先验框尺寸参数向量;Nobj为先验框数目,个;Lobj为 交叉熵损失函数;为先验框正负样本标志(1 为正样本,0 为负样本); λ为超参数,是用于平衡二元分类任务和包围框回归任务权重的参数,其值默认为 λ =5;Nreg为目标框数目;Lreg为Smooth L1损失函数;是此先验框对应样本值.
对背景框判定,以鸟瞰图先验框和样本2D 交并比(IoU)[16]为判据,具体如表1 所示,被判定为背景框的先验框不加入计算,既不是目标框也不是背景框的不参与训练,达到初步筛选的目的. 利用二维非极大值抑制算法进一步剔除冗余目标,保留IoU 阈值为0.8 且最多不超过前1 024 个的目标框,以便提高召回率,降低漏检.

表1 样本2D IoU 判定指标Tab.1 Sample 2D IoU judgment indicators
1.2 目标检测网络
在得到粗略估计的候选框三维尺寸之后,进行候选框尺寸的精细回归,计算航向角与目标类别判断,同时进行特征第二次融合.
对三维包围框尺寸估计时首先考虑编码方式.主要有两种常用编码方式:利用六面体的8 个顶点编码和轴对齐方式编码. 第一种方式能获得准确的尺寸估计,但是所需参数量较多;第二种利用中心点坐标和沿3 个坐标轴的棱长编码(第一阶段使用),所需参数量较小,但是不能编码航向角信息. 本阶段采用新的编码方式对三维包围框尺寸编码,使用底面4 点以及2 个高度值(底面、顶面与地平面高度)的方式编码六面体,不仅可以获得准确的尺寸估计,而且所需参数量较小,编码方式如图3 所示.

图3 三维包围框编码方式Fig.3 Encoding method of 3D bounding box
回归后的目标共10 个参数,相比于8 个角点编码方式所需的24 个参数大幅减少,回归后10 个参数包 括8 个 角 点 偏 移 量 ∆x,∆y和 2 个 高 度 偏 移 量∆h(∆x1,···,∆x4,∆y1,···,∆y4,∆h1,∆h2). 维护得到的角点,并约束4 个角点构成一个矩形,选择各边中点,将对边中点连线,取较长边作为坐标轴基准,具体实现如图4.

图4 4 个角点确定方法Fig.4 Determination method of four corner points
AVOD 网络航向角编码方式如图5 所示,计算方法基于一个二元向量隐式表达航向角,即(xor,yor)=(cosθ ,sinθ ),使[− π,π]中的每一角度都有唯一单位向量相对应,保证航向角唯一性.

图5 航向角编码方式示意图Fig.5 Schematic diagram of the heading angle coding method
损失函数由三维包围框尺寸计算、航向角估计与目标类别三个任务损失函数构成. 使用原始的256 通道特征图,将来自区域建议网络的候选框投影到特征图上获得候选特征,对投影后的特征图调整分辨率到7×7 像素,并对元素取平均后融合. 融合后的特征通过三个每层2 048 个节点的全连接层,分别输出三维包围框、航向角估计、目标类别,其中目标类别使用交叉熵代价函数来计算,其余两个使用Smooth L1 损失函数计算. 最后对包围框筛选,利用2D 非极大值抑制算法输出检测结果. 得到AVOD 网络的损失函数计算式(5):

式中:Lcls为 交叉熵函数;Lreg为3D 包围框的Smooth L1 损失函数;Lang为航向角估计的Smooth L1 损失函数;Ncls为先验框数目;Nreg为目标框总数目. 根据鸟瞰图中IoU 来判别候选框类型,对于车辆目标,鸟瞰图IoU>0.65 时为正样本;对于行人和骑车人,IoU>0.55 为正样本,并参与到计算之中.
1.3 多视角标注信息联合损失函数
优化网络检测头部分损失函数计算:将图像前视图与激光雷达点云鸟瞰特征图作为两个分支,以各模态样本标注为基准监督学习,计算各自损失函数,针对性地优化特征提取网络,防止图像特征提取网络退化,框架如图6 所示.

图6 多视角标注信息联合损失函数Fig.6 Joint loss function of multi-view annotation information
对不同模态信息处理中加入全连接层,首先进行包围框尺寸和目标类别的预判,之后将预判结果与标注信息对比,计算各模态损失函数.

式中:Lsub-cls为分类模块损失函数;Lsub-reg为包围框尺寸计算损失函数;N为目标框的总数量,为前视图正样本数量,为鸟瞰图正样本数量,单位(个);I为选出正样本目标框的筛选函数,为正值;、分别为图像和鸟瞰图分支对第i目标框的分类估计值;和为图像和鸟瞰图的标注信息;、为包围框尺寸偏移量和伸缩量;和为对应的标注信息.
对于正样本的判定,基于包围框与标注信息框的交并比来划分. 在鸟瞰图中,车辆类别的交并比大于0.65 为正样本,小于0.55 为负样本,行人与骑车人类别的交并比大于0.45 为正样本,小于0.4 为负样本;在前视图中,车辆类别的交并比大于0.7 为正样本,小于0.5 为负样本,行人和骑车人类别交并比大于0.6 为正样本,小于0.4 为负样本. 对于不属于正负样本的目标框来说,不参与损失函数统计. 最终得到多视角标注信息网络的联合损失函数AVOD-MLI(multi-view label information):

三维包围框的尺寸偏移和航向角的损失函数利用Smooth L1 函数实现,目标分类的损失函数利用交叉熵函数实现, λ作为超参数来权衡各任务损失函数权重.
2 双视角互投影融合方法的AVODMPF 网络
2.1 AVOD-MPF 网络框架
AVOD 网络的数据融合发生在特征层,通过拼接后按元素求平均的方式进行融合,为了保证拼接时特征图分辨率一致,经由池化层进行裁剪. 这种融合方式可能会使不同模态数据相互干扰,从而削弱特征.
文中通过加入互投影池化层来改进网络的融合阶段,改进后的网络可以优化不同模态数据特征融合,充分利用了激光雷达点云的稀疏性,将互投影池化层插入到VGG 特征提取网络之后,即特征金字塔的编码器之后,解码器之前,改进后的网络称为AVOD-MPF(mutual projection fusion,MPF)网络,局部网络结构如图7.
2.2 互投影池化层
通过坐标互投影,将激光雷达点云变换到图像前视图,并将图像变换到激光雷达点云鸟瞰图,从而获得激光雷达点云在前视图的特征图以及图像在激光雷达点云鸟瞰图上的特征图,结构如图8 所示. 通过相机与激光雷达的坐标转换矩阵P∈R3×4进行前视图与鸟瞰图之间的转换,如下式:
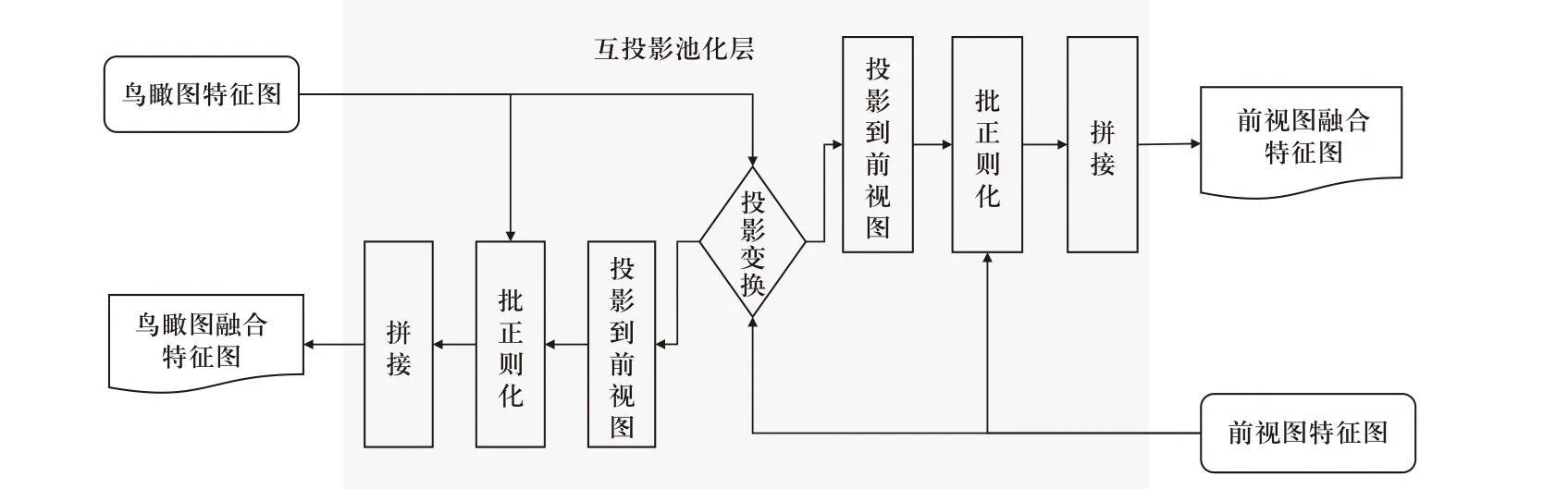
图8 互投影池化层融合Fig.8 Mutual projection pooling layer fusion

式中:(x,y) 为鸟瞰图像素坐标;(u,v)为图像的像素坐标;f(x,y)和g(u,v)为 两个特征图;k(u,v)为运算核;X=[x y z1]T,P12是P前两行的子矩阵.
通过上述转换会造成一个(u,v) 对应多个(x,y)的状况,并且多个(x,y) 点近似为直线( λx,λy),影响运算,因此依据激光雷达点云的稀疏性进行稀疏化,进行非齐次转换. 假定前视图尺寸Lf×Wf,鸟瞰图尺寸Hb×Wb, 激光点云记为({xi,yi,zi),i=1,2,···N},则得到转换方程式为

由多模态数据的对应性,可以将式(11)转化为
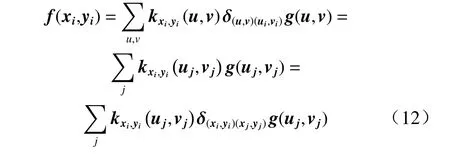
其中,

多传感器数据投影是双向进行的,可以在不同视角下形成特征图. 在拼接前对每一特征图进行归一化处理,利用批正则化层来实现;将前视图特征图与稀疏矩阵相乘并与鸟瞰图数据的特征图相拼接融合,类似的鸟瞰图的特征图以同样方式与前视图特征图相拼接融合. 其中稀疏矩阵X尺寸为LfWf×HbWb, 尺寸为Hb×Wb×A的特征图转化后为尺寸HbWb×A的矩阵F. 最终得到特征图T=MF,其尺寸为LfWf×A.
3 验证与分析
3.1 三维目标检测评价指标
KITTI 数据集[17]本身根据各种状况将目标进行划分,三种难度级别为:简单(最小包围框高度≥40像素,目标完全可见,截断≤15%)、中等(最小包围框高度≥25 像素,目标部分可见,截断≤30%)、困难(困难:最小包围框高度≥25 像素,目标难以看见,截断≤50%),划分依据主要是目标大小、遮挡以及截断情况.
文中网络主要针对车辆、行人、骑车人进行目标检测,并在验证集上统计标注样本和目标检测结果,利用三维平均精度AP3D来评价目标检测网络在三维尺度的检测精度.
3.2 训练策略与设备
对于目标检测任务,KITTI 数据集拥有大量的图像和激光雷达点云数据用于训练,针对不同尺度的目标训练了两种模型,分别对应车辆、行人以及骑车人,为了确保网络改进结果的合理性与有效性,分别对原AVOD 网络、AVOD-MLI 网络、AVOD-MPF 网络分别进行训练并进行结果对比.
文中所用的训练机配置为:32 GB 内存,11 G 显存,Nvidia 1080Ti 显卡,IntelCore i7-8700K @3.70 GHz ×12 的CPU,在Ubuntu 16.04 操作系统下进行,深度学习框架为Tensorflow.
3.3 训练过程与结果验证
3.3.1 AVOD 网络训练及结果
使用ADAM 优化器对模型参数进行优化,设定初始学习率为0.000 1,指数衰减,共120 k 次迭代训练,每100 k 次训练进行一次衰减,衰减系数定为0.1.全连接层引入dropout 方法,并利用批正则化方法.区域建议网络中设定建议框样本为512 个,第2 阶段的检测网络1 024 个样本,正负样本各一半,并将此两个网络进行联合训练.
网络训练的总损失值由两部分:检测网络损失(AVOD 损失)以及区域建议网络损失(RPN 损失)构成,如图9 (a)所示. 其中AVOD 损失包含AVOD 回归损失与AVOD 分类损失,如图9 (b)所示,回归损失为主要影响要素,占据AVOD 损失极大比例,且趋势与之相似. 对AVOD 回归损失进行分析,如图9 (c)所示,包含回归定位损失与回归航向角损失. 模型在训练中损失值随迭代次数增加而呈下降和收敛之势,最后训练损失到达0.615 2.

图9 AVOD 网络训练过程中损失函数值的变化Fig.9 Changes in loss function values during AVOD network training
选取F-pointNet 网络进行对比,结果如表2 所示.

表2 AVOD 网络在验证集上的AP3DTab.2 AP3D of AVOD network on validation set
表中可以看出AVOD 网络具有更好的车辆目标检测精度,对于困难和中等类别的车辆检测精度分别提高了8.37%、5.34%,处理有遮挡和截断目标的效果较好,但是对于小尺度目标的检测精度较低.
3.3.2 AVOD-MLI 网络训练及结果
使用ADAM 优化器,初始学习率0.000 1,指数衰减,每100 k 次迭代进行一次衰减,衰减因子0.1.使用最小批尺寸为1 的Xavier 对鸟瞰图特征提取网络初始化,图像数据特征提取网络加入预训练的ImageNet 权重. 区域建议网络仍设定512 个建议框样本,第二阶段的检测网络1 024 个样本,正负样本各一半.
AVOD-MLI 网络训练时损失值如图10 所示.AVOD-MLI 网络的AP3D,与AVOD 网络对比如 表3 所示.

图10 AVOD-MLI 网络训练损失值变化曲线Fig.10 AVOD-MLI network training loss value change curve

表3 AVOD-MLI 网络在KITTI 数据集上的AP3DTab.3 AP3D of AVOD-MLI network on KITTI dataset
从表3 可以看出AVOD-MLI 网络对于车辆目标效果不明显,可能是由于对于车辆目标而言,较大的尺寸差异造成激光雷达点云特征图的分支占据了较大比例,图像分支未能带来显著提升. 对于小尺度目标来说,激光雷达点云特征反而被削弱,图像特征能够带来更多的纹理信息,因此对于行人目标和骑车人目标而言,提升更为明显,对于行人目标,不同难度目标分别提高了1.18%,1.79%,2.75%.
3.3.3 AVOD-MPF 网络训练及结果
引入ADAM 优化器,初始学习率0.000 1,指数衰减,每30k 次迭代进行一次衰减,衰减因子0.8.使用最小批尺寸为1 的Xavier 对鸟瞰图特征提取网络初始化,图像数据特征提取网络加入预训练的ImageNet 权重. 区域建议网络仍设定512 个建议框样本,第2 阶段的检测网络1 024 个样本,正负样本各一半.
AVOD-MPF 网络训练时损失值如图11 所示. 随着迭代次数增加,网络总损失逐渐收敛,终值为0.269 5,如图10(a)所示,AVOD-MPF 检测网络变化值与AVOD-MPF 回归损失分别如图11(b)、11(c)所示,学习率如图12 所示.

图11 AVOD-MPF 网络训练损失值变化曲线Fig.11 AVOD-MPF network training loss value change curve
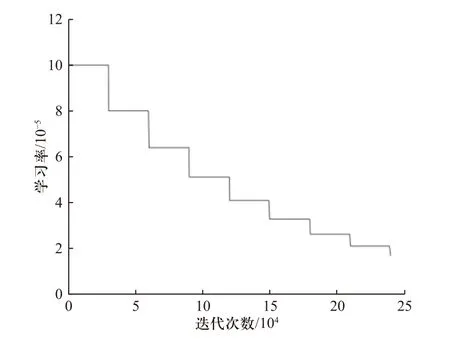
图12 AVOD-MPF 网络训练学习率Fig.12 AVOD-MPF network training learning rate
行人和车辆检测如图13 和图14 所示,其中13(a)和14(a)为最终3D 目标检测结果;图13(b)和14(b)为第1 阶段网络处理结果,实线框为建议框,虚线框为检测框;图13(c)和14(c)为整体网络回归结果,虚线框为标注框,实线框为检测框.

图13 行人检测示例Fig.13 Example of pedestrian detection

图14 车辆检测示例Fig.14 Vehicle detection example
AVOD-MPF 网络的AP3D与AVOD 网络对比如表4 所示.
表3 和表4 数据显示加入互投影池化层的 AVODMPF 网络保留了AVOD 网络本身对于车辆目标检测的优势,相比于F-pointNet 网络,对遮挡严重的车辆目标检测精度提高了8.62%. 同时提高了AVOD 网络对小尺度目标的检测精度,对于中等难度目标来说,AVOD-MPF 网络将行人检测精度提高了2.03%,骑车人检测精度提高了2.34%,说明加入的互投影池化层能够提升网络性能,改善了原AVOD 网络小尺度目标检测精度不高的问题.

表4 AVOD-MPF 网络在KITTI 数据集上的AP3DTab.4 AP3D of AVOD-MPF network on KITTI dataset
4 结 论
提出一种基于视觉与激光雷达的多视角互投影融合的三维目标检测方法,改进对车辆检测精度较高的AVOD 网络,通过互投影的方式加强不同模态信息数据关联并进行特征级融合. 相比于其他算法以及原网络来说,文中使用的AVOD-MPF 网络方法具有明显优势,实验数据和结果表明,本方法不仅能够实现三维目标检测时特征级和决策级融合,而且在保留AVOD 网络对车辆目标检测优势的同时,也提升了对行人和骑车人等小尺度目标的检测精度,对于有遮挡的目标复杂场景也有较好的适应性,为小尺度目标检测提供了一种新的思路.
