基于区域分块和轻量级网络的人脸反欺骗方法
2022-12-18何希平牛园园
贺 丹,何希平,2*,李 悦,袁 锐,牛园园
(1.重庆工商大学 人工智能学院,重庆 400067;2.检测控制集成系统重庆市工程实验室(重庆工商大学),重庆 400067)
0 引言
人脸识别技术拥有非接触、低成本和方便快捷等特点,是个人身份认证的重要工具,也是各种安全应用领域的最佳选择;但应用在这些场合的人脸识别系统内部流程存在着较大的漏洞,无法准确识别摄像头获取的人脸究竟是真实的还是伪造的。因此,在人脸识别过程中如何很好地阻止这种表示攻击(如打印照片、视频回放、3D 面具等)欺骗人脸识别系统是迫切需要解决的问题。
早期基于手工特征的传统方法通过寻找真实人脸与欺骗人脸之间的差异性,一般从颜色、纹理、运动信息等出发,利用局部二值模式(Local Binary Pattern,LBP)[1]、加速稳健特征(Speeded Up Robust Feature,SURF)[2]等经典局部描述符提取帧级特征,最后将提取的特征输入分类器进行决策,主要包括基于图像纹理的方法[1]、基于运动信息的方法[3]、基于深度信息的方法[4]和基于心率信号的方法[5]。传统方法更注重人脸图像中的纹理特征和固有的几何特征,然后通过多特征融合来提升方法性能,这对于描述真实人脸和欺诈人脸之间的详细不变信息(例如颜色纹理、云纹)是稳定的;但这类方法提取特征的能力有限,分类器不能很好区分其细微差别,并且手工特征很容易受到外部环境的干扰,泛化性差。
近些年,深度学习的框架被广泛应用于活体检测领域。大多数 的人脸 反欺骗 方法基 于ResNet[6]、DenseNet[7]和MobileNetV2[8]等卷积神经网络,通常由二进制交叉熵损失函数进行监督;而少数方法通过设计不同的网络结构、新的损失函数来提高准确率。文献[9]中提出了基于空间梯度幅值的残差空间梯度块和多级短长时时空传播模块的网络结构,并且提出了细粒度监督损失函数(对比深度损失)进行监督。这些基于深度学习的方法能够自动提取图像有效特征,很大程度上避免了传统方法提取特征的单一性,但是这类方法对数据的覆盖度和数据量的大小要求较高,且模型泛化能力在某些复杂的真实场景中不尽如人意;同时,深度网络参数量和计算量过大,进而导致这些方法部署在移动端或嵌入式设备中变得具有挑战性。
为了解决上述问题,文献[10]中提出了轻量级网络FeatherNets,借鉴了MobileNetV2 的逆残差块,并提出了流模块减少参数量;但该方法需要融合其他7 种网络结构训练的结果,最后通过级联进行判断,一旦更换数据集,该网络必须重新训练7 种网络获得评分作为判断标准,融合和级联的操作也明显增加了时间复杂度,且不方便部署到移动设备中。文献[11]中提出了中心差分卷积(Central Difference Convolution,CDC)算子来增强模型的泛化能力和判别能力,CDC 算子能很好地描述不变的细粒度信息,但也不适合部署在移动设备中。
针对以上讨论,本文设计了一种基于区域分块和轻量级网络的人脸反欺骗方法,能以较少计算和存储成本的深度学习算法来进行人脸欺骗识别,并且有着较高的精度和泛化能力。本文的主要工作有:
1)训练阶段将全脸图像大小调整为112×112,再随机选取固定尺寸的局部图像作为网络输入,以减少网络参数量;测试阶段基于区域分块思想提出了测试数据扩增策略和组合决策方法,从而提高模型最终判断的准确率和泛化能力。
2)设计了一种轻量级的卷积神经网络LightFASNet(Lightweight Face Anti-Spoofing Network)用于特征提取和图像分类,借鉴了MobileNet V2 轻量级网络的设计思想,结合了中心差分卷积、注意力机制等模块进行优化设计,确保模型有高精度的同时极大地降低参数量。实验结果表明本文所设计的网络有着最少的参数量,并在CASIA-FASD 和REPLAYATTACKR两个数据集上达到了100%的准确率。
1 本文方法
如图1 所示,本文方法的处理流程分别围绕训练阶段和测试阶段两方面进行综合设计。在训练阶段,主要是训练样本随机分块策略设计和LightFASNet 的网络结构设计两个方面;在测试阶段,主要是对测试数据进行数据代表性扩增,并将它送入已经训练好的网络中提取特征,最后对扩增的样本进行组合决策。

图1 本文方法流程Fig.1 Flow chart of the proposed method
1.1 随机区域分块
受注意力机制的启发,基于局部图像的特征学习方法在分类任务中取得了很好的效果。Brendel 等[12]通过使用局部图像作为网络输入,在ImageNet 数据集上取得了很高的精度。在人脸反欺骗任务中,欺骗信息遍布整个脸部区域[13],仅截取局部图像作为网络输入也能提取到相当丰富的特征,由于截取位置不固定,增加了很多随机因素,也很大程度上避免了网络训练时出现过拟合现象。此外,图像尺寸越小,模型的参数量和浮点数运算量(FLOating Point operations,FLOPs)也越小。
本文以随机选取的局部图像作为网络输入。首先,将尺寸不一的全脸图像统一缩放到112×112,并对全脸图像进行随机平移、旋转等操作,模拟真实场景中因采集方位变化的图像;然后,随机将全脸图像分割成固定大小(32×32、48×48、64×64 等)的不完全重叠的局部图像,再随机选择其中一块作为网络的训练输入。
1.2 LightFASNet结构设计
本文所提出的轻量级的人脸反欺骗网络(LightFASNet)的整体结构如图2 所示。

图2 LightFASNet的整体结构Fig.2 Overall structure of LightFASNet
在整个网络的设计中,为了保留更丰富的特征,第一层采用常规的卷积,而不是深度中心差分卷积;中间层则是由特征提取模块(Feature Extraction Module,FEM)和带SE(Squeeze and Excitation)的下采 样模块DSM-SE(Down-Sampling Module with SE)组成。FEM 和DSM-SE 改进和优化了MobileNetV2 的逆残差块,具有更少的参数量和更好的性能,其中DSM-SE 和FEM 组合后面也添加SE 模块[14](如图3(c)虚框内所示),SE 模块由全局平均池化层、两个全连接层和Sigmoid 函数组成,用来学习各特征通道的权重。最后将提取到的特征经过一个3 × 3 的深度卷积后直接平铺成2维向量,送入Softmax 进行分类。
1.2.1 FEM和DSM-SE
用于提取特征的主干网络由特征提取模块(FEM)和基于注意力的下采样模块构成,主要从MobileNetV2 的逆残差块(如图3(a)所示)和FeatherNet 改进而来。逆残差块主要由1 × 1、3 × 3 和1 × 1 卷积组成:第一个1 × 1 的卷积是通过设置一个扩张因子t来增加通道数,从而为后面的深度卷积提供更多的特征;中间的3 × 3 的深度卷积用于提取特征,和第2 个用来调整通道数1 × 1 的卷积构成深度可分离卷积,得到较好效果的同时降低参数量。在第2 个1 × 1 卷积后采用线性激活函数,目的是防止特征被破坏;最后加入残差连接,防止梯度爆炸导致精度消失。
本文提出的FEM 是用步长为1 的基于深度中心差分卷积的镜 像模块(DepthWise CDC based Ghost Module,DWCDCGM)替换前面的深度卷积,进一步降低模型参数量,FEM 的结构如图3(b)所示。
DSM-SE 是本文设计的下采样模块,通过将DWCDCGM步长设置为2 来进行下采样,并且在DWCDCGM 后增加注意力机制SE 模块,通过学习获得每个特征通道的重要性,从而抑制不太重要的特征。然后再新增一条带有步长为2 的平均池化层和1 × 1 卷积的分支,在FeatherNet、ShuffleNet[15]中也证明了该二级分支具有更好的特征聚合能力和网络性能提升[10],DSM-SE 具体结构如图3(c)所示。

图3 MolileNet V2、FEM和DSM-SE的结构Fig.3 Structure of MolileNet V2,FEM and DSM-SE
1.2.2 深度中心差分卷积
在人脸反欺骗任务中,最原始的卷积通常有采样和聚合两个步骤,因为它直接聚合局部强度信息,容易受到外界光照强度等因素的影响,导致模型的泛化能力弱;此外,它在描述细粒度的特征方面比较弱,模型难以学到欺骗人脸的细节特征,如纹理等[11]。文献[11]中提出的CDC 算子能很好地解决上述问题,空间差分特征具有较强的光照不变性,同时也能更好地学习到细节特征。
本文的FEM 和DSM-SE 中的卷积采用的是深度中心差分卷积(DepthWise CDC,DWCDC)。一般的CDC 是最原始的卷积和带有中心差分的卷积的组合,其计算公式如式(1)所示:

其中:f为输入特征图;w为卷积核的权重;p0表示输出特征图y的当前位置;pn是枚举X中的值,例如,对于3×3 的卷积核,步长为1 的卷积运算的局部位置信息为:X={(-1,-1),(-1,0),…,(1,1)};超参数θ∈[0,1],用于权衡强度级语义信息和梯度级详细信息之间的贡献,值越高表明中心差梯度信息越重要。当pn=(0,0)时,相当于中心位置p0本身,梯度信息总是等于0。当θ=0时,中心差分卷积就是最原始的卷积。将式(1)简化成方便代码实现的计算公式:
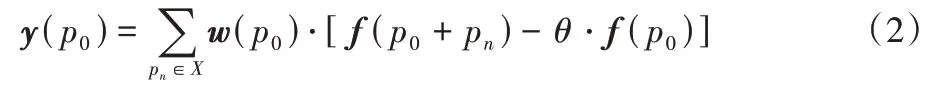
1.2.3 基于深度中心差分卷积的镜像模块
受文献[16]的启发,观察深度网络中每一层的特征图可发现:经过卷积层后输出的特征映射中通常包含大量冗余特征图,随着通道数成倍增长,其冗余的特征图也越多,因此,没有必要通过大量的滤波器来生成这些冗余特征图。本文通过以下步骤得到与MobileNet V2 中每一个模块同样数量的特征图:1)减少进行升维的1 × 1Conv,如MobileNet V2 用96 个1 × 1Conv,此处就使用48 个1 × 1Conv,从而减少一半的计算量;2)正常卷积操作,用3 × 3 DWCDC 对输入的48 个通道进行卷积操作;3)在变换的最后增加一个恒等映射,即将原有的输入特征图原封不动与变换后的特征图进行拼接,以此保留原有特征中的信息。将经过以上步骤的模块称之为DWCDCGM,具体结构如图4 所示。

图4 DWCDCGM的结构Fig.4 Structure of DWCDCGM
MobileNet V2 的部分模块和DWCDCGM 变换后的计算公式如式(3)(4)所示:


1.3 测试应用时的组合决策
1.1 节和1.2 节介绍了如何对训练样本进行处理,并设计了LightFASNet 进行特征提取。由于最终选取的训练样本为局部图像,虽能在一定程度上减少过拟合的风险,但也会因局部图像信息不完整、不充分导致测试时准确率降低。本文针对该问题,提出了测试数据扩增策略和组合决策方法。首先在每一张测试图像中选取N0张不完全重叠的局部图像,再对其进行旋转等变换扩增成N1张局部图像,然后把N1张局部图像送入训练好的模型中提取特征,最后通过组合决策得到分类结果。具体实施步骤如下。
1)将全脸图像分割成N0张不完全重叠的局部图像(N0=9),如图5 所示(以32×32 为例),计算公式为:

其中:n=0,1,…,N0-1;W′、H′为局部图像PIn的宽和高;W、H为全脸图像I的宽和高;Pn为第n张局部图像在全脸图像上的中心点坐标,以原始图像的左上角为坐标原点,Pn(1)和Pn(2)分别为PIn的中心点横纵坐标。图5 中,PI4的中心点坐标为(W/2,H/2),对应的i=j=0。另外8 张局部图像的中心点坐标可按式(6)计算:

图5 图像分割示意Fig.5 Example of image partitioning

其中:i=-1,0,1;j=-1,0,1;DW和DH表示每张局部图像中心点在横、纵坐标上相较于全图中心的偏离距离。
理论上,增强的9 张局部图像(如图5 所示)应全部处于全脸图像正中间,且完全不重叠;但当局部图像尺寸不满足3W′<W或3H′<H时,9 张局部图像一定会有重叠部分。为了取到尽可能少重叠的图像块,可分别按式(7)(8)计算相邻局部图像的中心点在横坐标和纵坐标方向的距离:

2)选择是否进行水平、垂直和水平垂直翻转,总共分成以下5 种方案:
方案一 只取局部图像,1 张原图像增强为9 张测试图像。
方案二 取局部图像并水平翻转,1 张原图像增强为18张测试图像。
方案三 取局部图像并水平、垂直翻转,1 张原图像增强为27 张测试图像。
方案四 取局部图像并水平、垂直、水平垂直翻转,1 张原图像增强为36 张测试图像。
方案五 取全脸图像并水平、垂直、水平垂直翻转,1 张原图像增强为4 张测试图像。
3)将经过步骤1)和步骤2)处理的局部图像分别作为一次模型测试时的输入,其图像数量记为N1,将其送入训练好的LightFASNet 中提取特征。受注意力机制启发,不同位置的局部图像的重要性有所区别,应进行学习或人工处理得到N1张图像的重要性。但本文围绕着轻量级出发,为了降低计算复杂性和减少参数量,本文最终对所有的输出组合取均值作为决策结果,然后通过Softmax 函数后得到该图像的预测结果O,计算公式为:
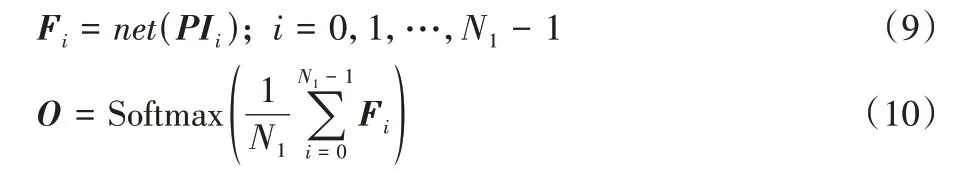
其中:net为本文设计的网络模型;Fi∈RB×2为模型的输出结果;PIi∈RB×C×W×H为输入图像(B为小批量,C为通道数);最终的输出结果为O∈RB×2。
2 实验设计与结果分析
本章将介绍使用的评价指标、数据集和实施细节,并基于不同方法、不同数据集、不同测试数据扩增方案和不同图像尺寸进行对比实验,以及CDC、注意力机制和DWCDCGM等模块的消融实验,从而验证本文方法的有效性。
2.1 数据集、评价指标和实验设置
数据集 为了验证本文方法的性能,分别在表1 中的REPLAY_ATTACK(后文简写为RA)[17]、CASIA-FASD(后文简写为CF)[18]和CASIA-SURF[19]数据集的Depth 模态上进行实验。

表1 实验数据集Tab.1 Experimental datasets
评价指标 在RA 和CF 数据集的内部实验中使用等错误率(Equal Error Rate,EER)和半总错误率(Half Total Error Rate,HTER)两个评价指标;而在数据集的交叉测试中仅使用HTER 作为评价指标。EER 为受试者工作特征曲线上错误拒绝率(False Rejection Rate,FRR)和错误接受率(False Acceptance Rate,FAR)相等时的均值,是人脸活体检测的错误率水平的体现。HTER 为FRR 和FAR 的均值,也是衡量人脸反欺骗性能的重要指标。两个指标的数值越小表示方法性能越好。在CASIA-SURF 数据集上,将平均分类错误率(Average Classification Error Rate,ACER)和准确率作为评价指标。
实验设置 本文方法基于Python 的PyTorch1.7 框架实现,GPU 为 NVIDIA GTX2060,CPU 为Inter Core i7-10875H,内存为16.0 GB。使用随机梯度下降(Stochastic Gradient Descent,SGD)优化器训练模型,损失函数是交叉熵损失函数,初始学习率为0.01,批处理大小为128,迭代次数为100次,总共循环10 次。
2.2 内部实验
2.2.1 最优输入图像尺寸的选择
为了确定最优的图像尺寸,分别在CF、RA 和CASIASURF 数据集上验证了6 组不同图像尺寸作为网络模型输入。实验结果如表2 所示。

表2 数据集内部用不同图像尺寸作为网络输入的实验结果 单位:%Tab.2 Experimental results of different image sizes within datasets as network input unit:%
由表2 易知,因为本文所设计的网络模型非常符合CF和RA 数据集,且这两个数据集的攻击类型较少、数据量丰富,所以任何图像尺寸作为输入都能达到100%的准确率。而在CASIA-SURF 数据集中,仅使用Depth 图像作为实验数据,当输入图像尺寸为96×96 时效果最好,在测试集上准确率达到99.49%且ACER 低至0.458 0%,这表明对于人脸反欺骗任务,原始图像包含的人脸完整信息并不是最有价值的,过多的人脸信息可能导致更高的过拟合风险。
2.2.2 最优测试数据扩增方案的选择
在1.3节中,本文提出了5种基于区域分块的测试数据扩增方案,为了验证所提方案的有效性,在CASIA-SURF(Depth)数据集上进行一系列实验。CF和RA 数据集在所有图像尺寸都有很好的效果,故不在这两个数据集上进行内部验证,实验结果如表3所示。
由表3 可知,局部图像中方案四的准确率最高、ACER 最低,全脸图像中选择增强方案也比不增强的效果好,这也进一步验证本文提出的基于区域分块的测试数据增强能有效提升模型的精度和泛化能力。

表3 数据集内部使用不同数据增强方案的对比实验结果Tab.3 Comparison of experimental results of using different data enhancement schemes within dataset
2.2.3 消融实验
前文介绍了CDC 算子、DWCDCGM 和注意力机制,其中引入CDC 算子是为了提高模型的泛化能力,提出DWCDCGM是为了使得设计的网络结构更加轻量化,而注意力机制则是提高模型准确率和泛化能力。基于以上讨论,在各个数据集上进行消融实验:在CASIA-SURF 数据集内部验证DWCDCGM 和注意力机制对模型准确率的提升和参数量的减少,输入图像尺寸为96×96,其中SE1 是DWCDCGM 后的注意力机制,而SE2 是DSM-SE 或FEM 后的注意力机制。通过跨数据集测试来验证CDC 算子和注意力机制对模型准确率和泛化能力的提升,输入图像尺寸也为96×96。消融实验结果如表4 所示。
表4 的实验结果表明:在数据集内部实验中,当所有模块都应用时ACER 最低,而SE1 和SE2 模块都不同程度地提升了模型的准确率,DWCDCGM 减少了参数量且精度保持不变;在跨数据集测试中,SE1 模块对模型泛化能力的提升最大,CDC 算子次之。

表4 LightFASNet架构中不同模块的消融实验结果Tab.4 Ablation experimental results of different modules in LightFASNet architecture
2.3 与其他方法对比实验
2.3.1 数据集内部测试对比实验
本文首先在CF 数据集和RA 数据集上进行了一系列实验,并与现有方法进行比较,使用的评价指标是EER 和HTER;然后在CASIA-SURF(Depth)数据集上进行实验,并且与ResNet18、MobileNet V2 等方法进行对比,用ACC、ACER和参数量等作为评价指标,验证本文模型的高效性和轻量化;最后通过对比分析本文方法和其他方法在相同设备上预测一张图片的时间,进一步验证模型是否具备部署至移动设备的条件。
由表5 可知,本文方法在这两个数据集上的EER 和HTER 都为0,即准确率均达到100%,明显优于其他对比方法,这也证明本文方法的高效性。

表5 CF和RA数据集上各方法的对比实验结果 单位:%Tab.5 Comparison of experimental results of different methods on CF and RA datasets unit:%
由表6 可知,本文方法在CASIA-SURF 数据集的Depth 图像上取得了最高的准确率和最低的ACER,而且模型的参数也是最少,FLOPs 仅低于FeatherNet,模型的预测时间与FeatherNetA 和FeatherNetB 基本一致,并且少于其他三种方法,结合上述五个指标可知本文所提出的模型符合部署至移动设备和嵌入式设备的标准。

表6 CASIA-SURF(Depth)数据集上各方法的对比实验结果Tab.6 Comparison of experimental results of different methods on CASIA-SURF(Depth)dataset
综合分析表5、6 的结果,本文所设计的网络模型已经达到各方面较优,并且方便部署在嵌入式设备。
2.3.2 跨数据集测试对比实验
为了验证本文方法的泛化能力,在RA 和CF 数据集上进行交叉测试,即在其中一个数据集上训练得到效果最好的模型,然后在另外一个数据集上进行测试,使用HTER 作为评价指标,实验结果如表7 所示。
由表7 可知,本文方法在各个数据集内部取得了目前最高的准确率;在跨数据集测试部分的实验效果并非最好的,部分实验略差于3DPC-Net 等方法。很显然,两个数据集的成像质量、攻击类型都有一定的差别,而且本文追求轻量化的网络结构,在特征提取方面有一定的不足,导致其跨数据集测试结果并非最好。关于跨数据集的效果不好,可以考虑将两个数据集混合训练,从而提高准确率。

表7 不同方法在CF和RA数据集上交叉测试的对比实验结果Tab.7 Comparison of experimental results of different methods for cross test on CF and RA datasets
3 结语
本文提出了一种全新的基于区域分块和轻量级网络的人脸反欺骗方法,并在测试时根据区域分块设计了数据扩增策略和组合决策方法,这极大地提高了模型的精度。该模型通过设计DWCDCGM 去除冗余特征图,减少了模型参数,并在每个下采样模块后添加注意力机制能保证模型在减少参数量的同时保持高精度;为了提高模型的泛化能力,该模型将深度卷积替换成深度中心差分卷积。实验结果表明,本文方法在3 个数据集上取得了很好的效果,明显优于其他对比方法,并且具有较少参数量;端到端的网络结构使其方便部署在移动设备上;但是由于本文追求网络轻量化,导致其泛化性能不够先进。在未来的工作中,将在保持模型轻量化的前提下,考虑如何进一步提高模型的泛化性能。
