基于融合CNN和Transformer的图像分类模型
2022-12-18何明智朱华生李永健唐树银孙占鑫
何明智,朱华生,李永健,唐树银,孙占鑫
(南昌工程学院 信息工程学院,江西 南昌 330099)
近十年来,卷积神经网络(CNN)在图像分类任务中一直扮演着非常重要的角色,它具有十分优秀的特征提取能力。如Krizhevsky[1]等提出由分层卷积构成的AlexNet曾获得2012年的图像分类大赛冠军。而Simonyan[2]等提出的VGGNet将卷积操作推向更深层。Szegedy[3]提出的Inception模型则从通过组合不同大小的卷积核来提升网络的性能。He[4]等提出带有残差连接的ResNet解决了深层卷积神经网络出现的梯度爆炸和梯度消失的问题。Huang[5]等提出带有密集连接的DenseNet更能充分利用卷积层间的特征流。尽管CNN网络拥有出色的局部特征捕获性能,但在获取全局特征上能力不足。
近几年来,发展迅速的视觉注意力机制在一定程度上帮助传统的CNN网络获取全局特征信息。如Hu[6]等提出的SENet利用全局自适应池化层在通道域上捕获全局信息后压缩再加权到特征通道上。而Woo[7]等提出的CBAM则同时利用最大池化层和平均池化层分别对通道域和空间域信息重新整合后再加权。虽然利用池化运算能以较小的参数量和计算量获得全局特征表示,但池化运算不可避免地会忽略一些重要的细节信息。受非局部均值方法[8](non-local mean)的启发,Wang[9]等提出由自注意力机制构成的non-local模块,使特征图的每个位置的响应是全局位置特征的加权和,使得CNN获得全局特征信息。但基于整体2D特征图的自注意力运算量大,不利于在空间高分辨率进行的视觉任务。
而近年来,Transformer架构[10]在自然语言处理任务上获得的成功,让研究人员将Transformer引入到视觉任务中。Dosovitskiy[11]等在原生的Transformer架构上改进,提出基于视觉任务的Vision Transformer(ViT)。ViT将输入的图像划分成固定大小的特征块,经过线性变换后得到特征序列,然后对特征序列进行多头自注意力运算,既能充分获得长距离的特征依赖,同时也降低了运算量。作为优秀的特征提取骨干网络,ViT也被广泛应用于目标检测[12]和目标跟踪[13]等任务。但由于ViT直接对特征图划分成特征块序列,导致提取边缘以及局部特征信息能力减弱。因此在没有超大规模数据集预训练下,ViT在图像分类任务表现较差。针对这个问题,Chen[14]等提出加入卷积算子的友好型Transformer架构Visformer模型,它在较小规模的数据集上表现出色。而D’Ascoli[15]等提出的ConViT模型,则是将CNN的归纳偏置带到Transformer中,提升Transformer对图像样本利用率。Graham[16]等提出的Levit模型在图像划分前利用级联多个小卷积能获取图像的局部特征,同时增大卷积步长,对图像进行下采样,有效降低模型的参数量。而针对ViT模型复杂的位置编码,Zhang[17]等提出的ResT模型利用深度可分离卷积对特征块嵌入相对位置信息。
与以上现有模型不同,本文提出了一种基于融合CNN和Transformer的图像分类模型FCT(Fusion of CNN and Transformer,简称为FCT)。FCT模型由CNN分支和Transformer分支融合构成。在FCT模型中CNN分支不仅在低层次中向Transformer分支补充基础的局部特征信息,并且在模型的中、高层次中,CNN分支也能向Transformer架构提供不同的局部和全局特征信息,增强模型获取特征信息的能力,提升图像分类的准确率。
1 模型结构
1.1 整体模型结构
在基于深度学习的图像分类领域,局部特征和全局表示一直是许多优秀模型不可缺少的组成部分。CNN模型通过级联卷积操作分层地收集局部特征,并保留局部线索作为特征图。Vision Transformer则通过级联的自注意力模块以一种软的方式在压缩的特征块之间聚合全局表示。
为了充分利用局部特征和全局表示,本文提出了一个融合网络结构FCT。FCT模型利用来自卷积分支的局部特征逐步提供到Transformer分支用以丰富局部细节,使得FCT网络模型获得局部特征和全局表示。
如图1所示,FCT模型主要由卷积stem块、CNN分支、Transformer分支以及全局自适应池化层和全连接层组成。stem块由大小为7、步长为2、填充为3的卷积和大小为3、步长为2、填充为1的最大池化层构成,它用于提取初始局部特征(例如边缘和纹理信息),然后将初步处理后的特征图传递给两个分支。CNN分支与Transformer分支分别由多个卷积模块和Transformer模块组成,这种并行结构可以使CNN分支和Transformer可以分别最大限度地保留局部特征和全局表示。而Patch Embedding则作为一个桥梁模块,用于将完整的特征图线性映射成特征块序列,并逐步地把局部特征图传递给Transformer分支,使CNN分支的局部表示特征图能和Transformer分支的全局特征表示图相融合。为了使网络枝干产生层次表示,随着网络的深入,Patch Merging在Transformer分支中起到下采样的作用,它可以减少特征块序列的数量,使特征块数量减少到原来的四分之一,从而有效地降低整体网络的运算量和参数量。最后,将特征图输入到自适应平均池化层中,压缩成1×1序列,然后通过全连接层输出参数结果。
1.2 CNN分支
如图1所示,CNN分支采用特征金字塔结构,其中特征图的分辨率随着网络深度的增加而降低,同时通道数在不断增加。本文将整个分支分为4个stage,每个stage包含两组卷积,而根据ResNet-18[4]所定义,每个卷积组由两个大小为3、填充为1的卷积,以及输入和输出之间的残差连接组成。从stage2开始,每个stage的第一个卷积的步长为2,其余为1。在整个CNN分支中,每个stage都拥有两个卷积组。ViT模型通过一个步骤的Patch Embedding将一副图像线性映射为特征块序列,导致局部细节的丢失。而在CNN网络中,卷积核在有重叠的特征映射上窗口滑动,这样能保留精细的局部特征。因此,CNN分支能够连续地为Transformer分支提供局部特征细节。
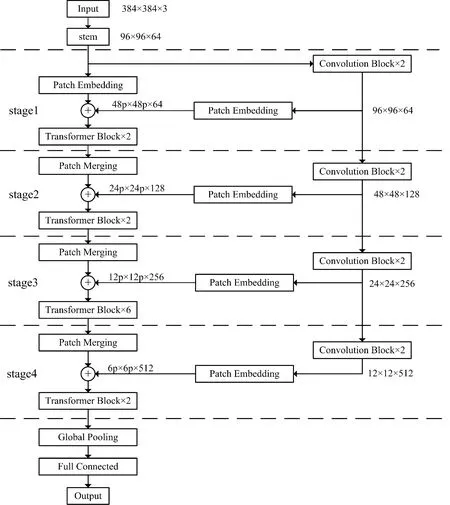
图1 FCT模型结构图
1.3 Transformer分支
1.3.1 Transformer块
与ViT模型不改变特征序列的数量和通道数不同,本文的Transformer分支通过Patch Merging下采样构成特征金字塔结构,其中特征序列的数量随着网络深度的增加而减少,同时通道数与CNN分支相对应的stage相同,也在不断增加,用以更好地与CNN分支传递的特征信息相融合。本文将整个分支区分为4个stage,每个stage包含不同数量的Transformer块。每个Transformer块由多头自注意力(MHSA)模块和多层感知机(MLP)模块(包含向上映射全连接层和向下映射全连接层,以及包含两层GELU非线性激活层)组成。每一层的多头自注意力块和MLP块中的残余连接之前都使用层次归一化[18](LayerNorm,LN)。Transformer模块可用下式所表示:
(1)
(2)
其中z为输入的特征序列,l为Transformer模块的层次。
在整个Transformer分支中,stage1~stage4的MHSA模块的头部数量分别为1、2、4、8。而每个stage中Transformer模块的数量分别为2、2、6、2。
1.3.2 特征块线性映射Patch Embedding
标准的Transformer架构的输入为等长的特征序列,以ViT为例,它在Patch Embedding层将一幅三维图像x∈h×w×3分割成大小为p×p的特征块。这些特征图块被线性映射为二维特征块,其中x∈n×c,而n=hw/p2。一般地,ViT模型将特征块尺寸设计为14×14,特征块数量为16×16。为了减少参数量和运算量,在本文中,FCT模型将特征块设计为2×2的大小。如图1所示,第一个Patch Embedding模块将宽高为96×96,通道数为64的特征图划分成宽高分别为48个2×2的特征块,即48p×48p,通道数仍然为64。
1.3.3 相对位置编码
位置编码(Position Embedding)对于利用特征块序列的顺序至关重要。在ViT中将一组可学习的参数添加到输入标记中来编码位置关系。设x∈n×c为输入,θ∈n×c为可学习的位置参数,则位置编码的嵌入可表示为
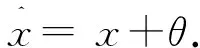
(3)
然而,使用这种可学习的相对位置编码需要固定特征块的长度,这限制了改变特征块长度的处理。在本文的模型中,利用深度可分离卷积获取特征序列的位置编码关系后,加权到输入序列中[15],可表示为
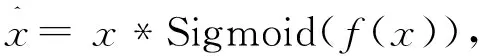
(4)
其中f为深度可分离卷积操作。
1.3.4 特征块融合Patch Merging
随着网络的深入,特征块的融合能减少特征序列的数量。每个特征块融合层将每组2×2相邻特征块连接,并对连接特征应用线性层,这样可以使特征序列的数目减少到四分之一,输出的通道数增大到输入通道数的2倍。通过加入Patch Merging,使整体网络模型形成层次结构,使CNN分支的每个stage输出特征通道数与Transformer分支的每个stage输入特征序列的通道数相等。而CNN分支的每个stage输出的特征图尺寸大小为Transformer分支每个stage输入序列数量的两倍。CNN分支向Transformer分支传递特征图,特征图经过Patch Embedding处理后,得到的特征块序列与上一个stage的Transformer层输出特征块序列的大小、数量以及通道数都相等,因此CNN分支传输的特征信息能和Transformer分支融合。
1.4 分支融合
由于CNN分支与Transformer分支上处理的特征结构有所差异,因此,CNN分支的特征图需要先映射成特征序列,再加入相对位置编码,Transformer分支上的特征块序列则需要下采样,减少特征块序列的数量。融合其两个分支可由下式表示:
zl=PM(zl-1)+Pos(PE(f(xl-1))),
(5)
(6)
其中z∈n×c为输入的特征块序列,x∈h×w×c为输入的特征图,l表示层次,PM表示特征块融合(Patch Merging),T表示Transformer模块,Pos表示嵌入位置信息(Position Embedding),PE表示特征块线性映射(Patch Embedding),f为卷积模块。由图1可知,FCT模型将每个stage的CNN分支都将该层次的局部特征以及全局表示信息传递到Transformer分支,使得模型融合了丰富多样的局部和全局特征信息。
2 实验与分析
2.1 实验环境
本文实验的设备CPU为Xeon(R)CPU E5-2680 v4,GPU为NVIDIA GeForce RTX 3060。本文使用的Python版本为3.7.4,Pytorch版本为1.9.0。
2.2 实验数据集
本文使用Oxford Flowers-102[19]和Caltech-101[20]作为实验数据集。Oxford Flowers-102为英国常见的102个花卉类别的图像数据集,每个类包含40到258幅图像,每幅图像具有较大的比例、姿势和光线变化,一共包含8 189幅图像。Caltech-101由101个类别的物体图片组成,每个图像都使用单个对象进行标记,每个类包含大约40到800幅图像,图像大小不一,总共8 677幅图像。以上两个数据集均按照6∶2∶2的比例随机划分成训练集、验证集和测试集。本文实验的数据增强策略仅使用随机剪裁和随机水平翻转。随机剪裁是在数据训练时将输入的图像数据首先按不同的大小和宽高比进行随机裁剪,然后缩放所裁剪得到的图像为384×384分辨率。随机水平翻转是在随机剪裁操作后,以0.5的概率随机水平翻转。本实验仅使用上述数据集所包含的图像,不使用额外的图像进行训练。
2.3 训练参数
本文实验模型训练的优化器为AdamW[21],学习率为0.000 1,权重衰减率为0.01,迭代次数为110。为了能加快模型收敛,本文使用学习率余弦衰退周期地对学习率进行动态调整,设置迭代20次为一个周期。
2.4 热力图可视化
本文在一幅有多朵花的图像上分别对FCT、ResNet-18、ViT-base使用Grad-CAM[22]计算得到3个不同的模型的注意力热力图,如图2所示。ResNet-18能精确地识别出图像里面位于中心位置的花朵,但是没有识别出另外的花朵;ViT-base模型虽然都能感受到所有花朵的位置,但是无法获得更精确的细节信息。与ResNet-18和ViT-base模型识别的结果相比,FCT模型既能感受到所有花朵的位置,又能获取花朵的关键局部细节。因此FCT可以通过Transformer分支的自注意力模块获得特征全局表示,也能从CNN分支的卷积模块获得局部细节的信息,令局部信息和全局信息有效融合。

图2 热力图可视化
2.5 对比实验
在Oxford Flowers-102和Caltech-101上,除了测试FCT模型以外,还测试了传统的CNN模型(ResNet-18、ResNet-50)、原始的Transformer模型(ViT-base)和将Transformer融合卷积的模型。由表1可知,在没有大规模数据的预训练下,原始的Transformer模型ViT-base表现较差。其他文献基于Transformer架构融合卷积的方法虽然能改善ViT的准确率,但是分类的准确率仍然无法达到传统CNN模型效果。在Oxford Flowers-102上测试本文提出的FCT模型分类准确率比ResNet-18高5.84%,比ResNet-50高2.09%,比Visformer-tiny高9.64%。在Caltech-101数据集上,FCT模型分类准确率比传统CNN模型高约2%,比其他Transformer架构模型优势明显。本文提出的融合CNN与Transformer的图像分类模型FCT,充分地利用了CNN的低层次局部特征以及高层次的全局特征,使网络模型拥有丰富的特征信息,提高模型的分类准确率。
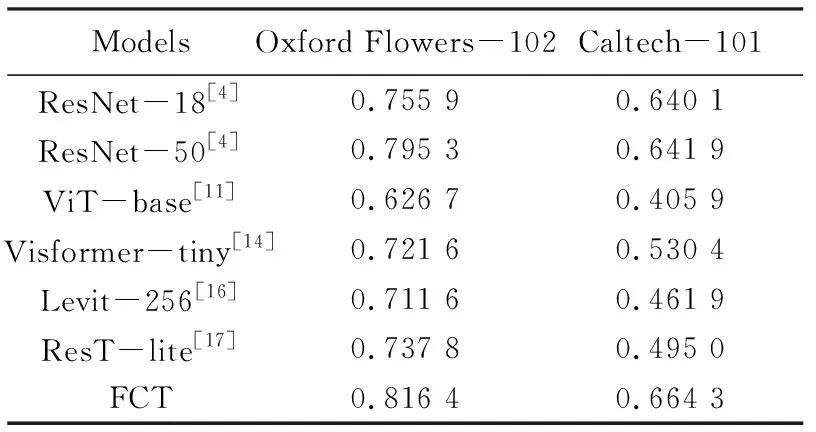
表1 不同模型的测试集准确率
2.6 消融实验
图3为stem卷积层和CNN分支、Transformer分支分别融合后测试结果的可视化图。由图3可知,CNN+stem分支(ResNet-18)对原图中三个花朵的部分,更集中关注能明显识别为花蕊的区域,其感受区域比较局部。而Transformer+stem分支对原图中三个花蕊的位置都能感受到,但是感受区域过大,超出了花蕊的位置。FCT模型融合了CNN的局部感受和Transformer的全局感受,能将三个花蕊的位置识别出来。

图3 模型各分支识别效果可视化
本在Transformer分支上不同层次上的分类准确率,结果如表2所示。由表2可知,随着从低层到高层卷积分支的融合,模型分类准确率在不断提高。实验结果说明,CNN分支不仅在低层次传递局部细节特征能提升模型的分类性能,而且在高层次的全局特征表示上也对提升模型的分类效果发挥了重要的作用。

表2 逐步融合不同层次卷积的分类准确率
3 结束语
针对传统的CNN模型拥有出色的局部特征提取能力,但捕获全局表示能力较弱,而视觉Transformer模型可以捕获特征全局表示,但容易忽略局部细节的不足等问题,本文提出了一种基于融合CNN和Transformer的图像分类模型FCT。FCT利用CNN分支的卷积算子来提取图像的局部特征,利用Transformer分支的多头自注意力机制来捕获全局表示。在Oxford Flower-102和Caltech-101数据集上验证,FCT模型的图像分类准确率明显优于传统的CNN模型和Vision Transformer模型。下一步将探索融合模型中,Transformer分支向CNN分支传递全局特征信息的结构设计,使Transformer分支以及CNN分支同时拥有优秀的获取局部特征和全局表示的能力,进一步提高模型的分类准确率。
