融合多维特征的高校专利价值分级方法及其实证研究*
2022-12-17高道斌
张 彪,吴 红,高道斌
0 引言
高校是国家创新系统中的重要行为主体,截至2020年12月,其发明专利有效量达442,523项[1],但产业化率仅3%[2]。为促进高校科技成果转化,2020年教育部、国家知识产权局和科技部联合发布的《关于提升高等学校专利质量 促进转化运用的若干意见》指出树立高校专利等科技成果只有转化才能实现创新价值、不转化是最大损失的理念;2021年“每万人口高价值发明专利拥有量(件)”写入“十四五”时期经济社会发展主要指标。此外,随着新兴技术复杂度的提高,企业在仅凭自身研发体系和资源构成愈加难以取得或保持创新优势时[3],逐渐通过专利转让、许可等形式吸收高校的技术成果、实现技术升级[4]。面对海量专利,校企双方都希望能够通过技术转移将高校专利的技术价值转变为产业价值。然而,并非所有高校专利都具有高价值,也并非所有高校专利都能发生技术转移。因此,如何全面客观评估高校专利价值、准确测算高校专利的技术转移潜力成为推动高校技术成果与市场对接、促进成果变现以及协助企业定位高价值专利迫切需要解决的问题。本文拟就该问题进行探索。
1 文献综述
专利价值是衡量人类知识产权水平的主要测度标准[5],学者就如何客观准确评估专利价值展开了探索。早期的专利价值评估主要基于经济学方法,包括成本法、市场法、收益法[6],近期也有学者提出实物期权法[7]、潜在维权成本评估法[8]。经济学方法多用于评估企业专利的资产价值,计算公式的参数估计主观性强,现实中较少使用。当前对专利价值评估方法的研究,更多是从两方面展开讨论。
(1)指标评价方法。部分学者通过对指标赋权评估专利价值。Zhang等[9]使用信息熵对审查时长、权力要求数量、同族专利数等指标进行加权,并使用协同过滤技术排除创造性低的专利,进而确定高价值专利。伊惠芳等[10]提出一种柔性的动态确权专利价值评价框架,采用熵权法对指标赋权,并利用多属性决策方法识别高价值专利。部分学者借助机器学习构建评估模型。Kim等[11]将被引次数作为专利价值的代理变量,选取相似专利数、权利人历史被引数等指标,使用随机森林、逻辑回归等方法构建专利价值评估模型。冉从敬等[12]以有无技术转移为依据划分专利价值,从指标易获取性角度选取发明人数量、3年内被引用次数等指标,并采用主成分分析方法对指标进行筛选,最后基于人工神经网络构建高校专利价值评估模型。
(2)文本分析方法。Park等[13]提出采用专利文本中的SAO结构代表技术方案,通过预测TRIZ演化趋势判断专利价值。詹文青等[14]基于语义标注专利文献和技术需求的技术问题、技术功能、技术效果等技术特征词组,计算专利文献和技术需求的相似性,根据相似度排序识别潜在高价值专利。郭烨等[15]认为专利价值的核心是技术水平的高低,据此提出一种基于功能分析的专利价值评估方法,在专利功能句抽取的基础上从重要性、性能、成本、有害性等角度分析专利价值。
综上,指标评价方法多是从专利自身属性特征出发,从技术、经济、法律等层面选取评估指标,采取主、客方法对指标赋权或构建机器学习模型评估专利价值。文本分析方法强调专利文本信息包含的技术方案是专利价值的重要来源,主要基于TRIZ理论对专利的技术方案进行表征,通过对技术方案进行定量分析评价专利价值。上述方法对专利价值评估均有一定作用,但少有研究能够将指标评价和文本分析进行有效结合,从专利自身属性特征和专利文本语义信息的角度全面判断专利价值,而且当前研究多是将专利笼统分为高价值专利、低价值专利,未能细化专利价值的层级结构。基于此,本研究在借鉴已有研究成果的基础上,提出一种融合专利自身属性、文本信息等多维特征的高校专利价值分级方法,旨在为高校准确评估专利价值、适时对外提供实践路径,也为企业寻求高校高价值专利提供决策参考。
2 研究方法
专利价值来源于多个方面,主要受技术本身的创新水平、专利撰写质量以及发明人知识积累影响[16-17]。对应以上3个影响因素,本研究将融合以下3个维度的特征实现对高校专利价值更准确的评估:专利文本语义特征,专利文本语义信息包含的技术方案能够反映技术的创新水平[15];专利自身属性特征,技术、法律、经济3个层面的专利自身属性特征是现有研究中通过专利撰写质量评估专利价值的重要可量化指标[10];发明人特征,发明人能力越强则其创造的专利具有的价值越高[18],据此设计能够直接体现发明人能力与专利价值关联的指标。以上述特征为基础,采用机器学习算法构建高校专利价值评估模型,预测专利发生技术转移的概率,并划定阈值将专利价值分级细化,以期更准确、更细粒度地对高校专利价值进行评估与分级。本研究框架如图1所示。

图1 研究框架
2.1 专利数据分类
专利价值通常使用被引频次[11]、专利强度[19]、交易价格[20]、有无技术转移[12]等作为代理变量,而高校专利价值最直接的体现就是通过转让或许可等方式转移至企业。考虑到交易价格的私密性和获取难度,本研究以有无技术转移作为专利价值的分类准则。主要获取3类数据:类别一,已发生技术转移的专利,其技术转移概率为1;类别二,直至失效也未发生技术转移的专利,其技术转移概率为0;类别三,当前有效但未发生技术转移的专利。类别一、类别二数据主要用于模型构建,类别三数据用于展现模型预测的效果。
2.2 多维特征获取
(1)专利文本语义特征。专利价值核心在于其技术水平的高低[15],而技术水平的高低则取决于专利文本中技术方案的描述。从专利技术自身拥有的技术方案出发进行价值分析,关键在于如何对专利文本语义特征进行有效表征。现有研究多借助TRIZ,通过对功能语句分析实现价值评估[21]。这种方法通常需要人工解读,效率较为低下。随着人工智能技术的发展,自然语言处理中的词向量方法实现了对各类文本语义特征的自动编码。Word2Vec[22]是常用的词向量模型,相比于one-hot等高维、稀疏的表示法,Word2Vec训练出的词向量是低维、稠密的,而且利用了词的上下文信息,语义信息更加丰富,解决了向量稀疏和语义联系两个问题。但是,Word2Vec忽略了词语与整个句子之间的联系,对于局部与主体之间的特征表达得不够准确。直到2018年,Bert[23]通过海量语料预训练,结合不同语境动态获取词语在上下文中不同的语义特征,有效克服了Word2Vec的缺陷,可以将语义特征从词级别深化到句子级别[24],能够更好地对专利文本语义特征进行表征。
本研究拟采用12层Encoder的Bert模型,模型输入是专利文本,输出是768维的句向量。由于句向量维度过于庞大,可能会增加冗余信息对模型性能的干扰,而且不同的特征之间可能会存在某种相关性,导致后续构建的模型消耗时间过长且难以获得最优的参数,进而使模型性能降低,因此本研究采用主成分分析方法(PCA)对句向量进行降维处理,将句向量的前d个主成分作为专利文本语义特征,以特征向量形式进行存储。
(2)专利自身属性特征。本研究的专利自身属性特征即各大专利数据库规范化的字段信息及专利著录项目中常被用以评估专利价值的指标[6]。结合已有研究,依据《专利价值分析指标体系操作手册》从技术、法律、经济3个层面选取广泛使用的指标,如表1所示。
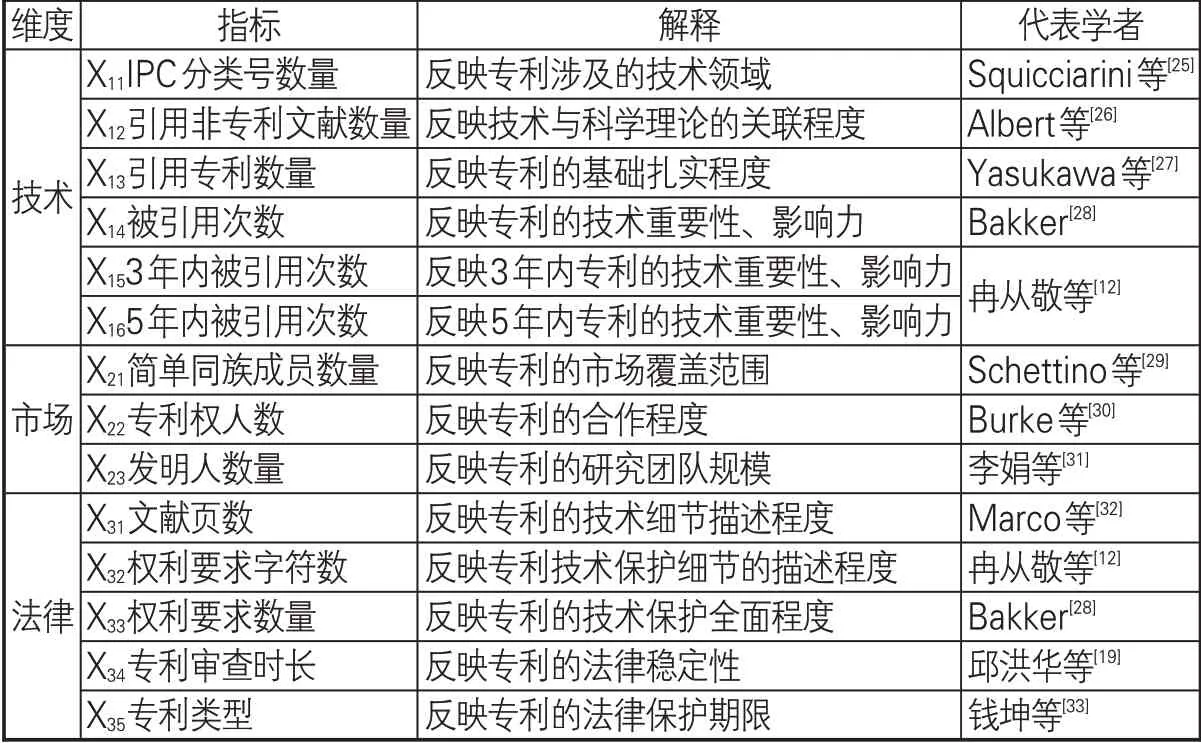
表1 专利自身属性特征
(3)发明人特征。发明人是专利的直接关联者,虽有部分学者注意到发明人对专利价值的重要影响,并采用第一发明人职称、第一发明人职务、第一发明人所在单位等指标表征发明人的能力,但职称、职务等多是从侧面体现发明人的综合能力[34],难以与专利价值产生直接联系。因此,本研究设计了能够更直接体现发明人能力与专利价值关联的指标。专利发明人通常有多个,为了便于计算,使用第一发明人作为发明人的代表,具体指标如下:
Y1:第一发明人授权专利参与数目。正向指标,参与数目越多,则第一发明人的专利被授权能力越强,以有效专利数与失效专利数的和表征,不包含未授权专利。
Y2:第一发明人技术转移率。正向指标,技术转移率越高,则第一发明人的科技成果转化能力越强,计算方法如公式(1)所示。其中,a代表第一发明人参与授权的专利中发生转移的数量。
Y3:第一发明人资源浪费率。负向指标,资源浪费率越大,则第一发明人的科技成果转化能力越弱,计算方法如公式(2)所示。其中,b代表第一发明人参与授权的专利中直至失效也未发生转移的专利数。
Y4:第一发明人的技术覆盖面。正向指标,技术覆盖面越广,则第一发明人的技术掌握越全面,以第一发明人参与专利的IPC分类号前4位总类数进行表征。
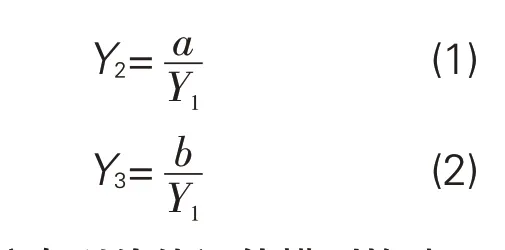
2.3 高校专利价值评估模型构建
本研究采用机器学习的二分类算法构建专利价值评估模型,在进行模型构建之前,需要对专利文本语义特征、专利自身属性特征、发明人特征3个维度的特征进行融合处理。采用d维特征向量表示专利文本语义特征,将14个指标转化为14维的特征向量表示专利自身属性特征,使用4维特征向量表示发明人特征,然后将以上3个特征向量进行横向拼接,最后生成d+18维特征向量,并进行归一化处理。模型输入为d+18维的特征向量,模型输出为技术转移概率。为验证本研究方法的有效性,采用逻辑回归(LR)、随机森林(RF)、高斯贝叶斯(GaussianNB)、K近邻(KNN)、梯度提升算法(GBDT)、支持向量机(SVM)、极端梯度提升算法(XGBoost)、BP神经网络(BP)、自适应增强(Adaboost)9种常用的机器学习算法进行对比,并从中挑选性能最好的模型用以预测未知数据集的技术转移概率。
采用准确率Accuracy、查准率Precision、查全率Recall和调和平均值F1共4个指标对模型的性能进行评估,计算方法如公式(3)-(6)所示。式中M表示测试集中预测正确的数目,N表示测试集总数目,TP表示测试集中实际发生技术转移且被预测正确的数目,PN表示测试集中预测可能发生技术转移的数目,TN表示测试集中实际发生技术转移的数目。通过绘制ROC曲线、计算AUC值展示最优模型的性能。

2.4 专利分级
在验证模型有效性的基础上,使用高校专利价值评估模型预测每项专利发生技术转移的概率P,P∈[0,1],步长为0.1,总共分为10级。专利发生技术转移的概率P越大,价值越高。具体级别与概率分布如表2所示。
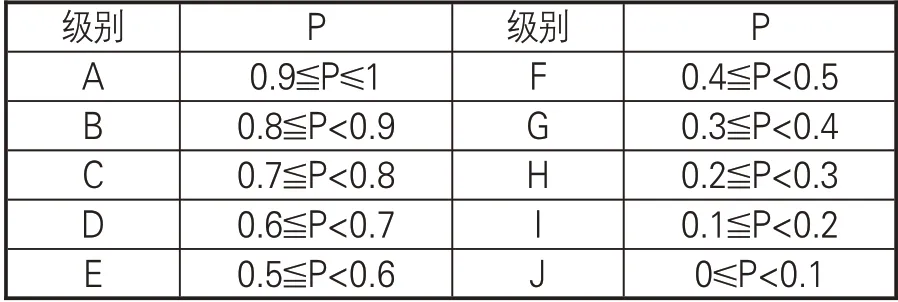
表2 专利级别与概率分布
3 实证研究
3.1 数据采集
本研究对云计算领域专利进行实证分析,数据来源于智慧芽专利数据库(以下简称“智慧芽”)。智慧芽对专利引文、发明人、专利权人、权力转移、专利许可等字段信息进行了收录与规范化处理,而且可以将各字段信息以csv格式导出,是本研究较为理想的专利数据库。文章根据专家意见并参照已有研究[35-36]制定如下检索式:TA:(“云计算”OR“云安全”OR“云服务”OR“分布式存储”OR“云存储”OR“云平台”)。经初步检索发现,云计算领域高校专利数据中,类别一仅有315件,而类别二有1,065件,采用以上数据不仅容易导致模型陷入对小数据集的过拟合,而且模型的普适性也不够强。为解决此问题,本研究借鉴学者以中国专利数据代替纯高校专利数据的思路[12],在保留高校专利特征的前提下,增加模型训练的数据量,丰富数据特征,以有利于提高模型的普适性,减小过拟合的风险。具体检索方式如下:
以智慧芽中的中国发明专利和实用新型专利为数据源,使用上述检索式,筛选条件“法律事件→权利转移OR许可”,检索到2,588件专利作为正样本,标签为1;筛选条件“简单法律状态→失效&法律事件→未发生权力转移或许可”,检索到3,319件专利作为负样本,标签为0;筛选条件“简单法律状态→有效&法律事件→未发生权力转移或许可&当前专利权人→大学”,检索到3,242件专利,作为高校专利待分级的数据(预测集)。检索时间为2021年11月11日。
3.2 数据处理
(1)数据集划分。剔除信息不完整的专利,得到正样本2,427个、负样本3,249个、预测集3,122个。为避免数据类别分布不平衡降低模型效果,对负样本进行欠采样,随机去掉部分样本,得到2,427个负样本。将正负样本合并,随机划分80%为训练集(3,883个样本),20%为测试集(971个样本)。
(2)多维特征获取。对于专利文本语义特征,使用Python编程调用肖涵在github上公开的bert句向量生成接口①,将每项专利的摘要转化为768维的句向量,调用scikit-learn机器学习库的PCA算法计算累计方差贡献率与特征数的关系(见图2)。当累计方差贡献率为0.7时,特征数为40,即句向量的前40个主成分可以保留原始数据70%的信息。因此,将句向量维度降至40,最终每项专利的文本语义特征使用40维的特征向量表示。对于专利自身属性特征,可根据智慧芽下载的专利著录项目结合专利文献计算得到。对于发明人特征,首先获取云计算领域授权专利的第一发明人姓名,然后根据2.2中的发明人特征计算方法得到每个第一发明人的Y1、Y2、Y3、Y44个指标,最后根据第一发明人的姓名与各项专利对应。将40维的专利文本语义特征向量、14维的专利自身属性特征向量、4维的发明人特征向量进行横向拼接,得到58维的特征向量,最终训练集、测试集、预测集的结构分别为3,883×58、971×58、3,122×58的矩阵。

图2 累计方法贡献率—特征数关系
3.3 模型构建与评估
本研究训练集数据样本较少,采用五折交叉验证进行模型参数调优,即将训练集分成5份,轮流将其中4份作为训练数据,1份作为验证数据,最后求5次实验的平均准确率评估模型的性能。借助scikit-learn机器学习库采用2.3所述的9种机器学习算法进行模型构建,模型的参数调优见表3。

表3 机器学习算法相关参数设置
测试集评估结果如表4所示。使用9种机器学习算法构建的专利价值评估模型acc值最低为90.216%,最高为97.631%,p值最低为91.071%,最高为97.131%,r值最低为89.027%,最高为98.137,f1值最低为90.052%,最高为97.631%。从各项指标的评估结果来看,模型性能较为优异,能够证明本研究所提方法的有效性。

表4 模型测试集评估结果
选用4项评估指标均最高的RF模型绘制ROC曲线(见图3),AUC值为0.99699,与已有研究[12]相比,在同一领域的数据集上AUC值提升22个百分点,能够充分证明本研究所提方法的优异性能。因此,将构建的RF模型应用到未知数据集上,预测专利发生技术转移的概率。

图3 RF模型的ROC曲线
3.4 高校专利分级结果
使用RF模型对预测集的技术转移概率进行预测,并将预测结果按照2.4所述规则进行专利价值分级,结果见图4。云计算领域不同等级的高校专利价值呈现出明显右偏态分布,F、G两个级别的专利数量最多,其余等级的专利数量较少,这与现有学者提出的少数专利产生多数价值[37]、专利价值呈现右偏分布[38]的观点一致,能够证明本研究预测分级的结果可信性。A-E(5个)级别的技术转移概率大于等于0.5,具备较高的价值,总计占比14.87%;F-J(5个)级别的技术转移概率小于0.5,价值较低,总计占比85.13%,说明云计算领域的高校高价值专利仅占少数,多数专利价值偏低[12]。价值最高的A级别专利仅占3.24%,而F、G两个级别的专利分别占35.65%、37.7%,说明大多数高校专利的技术转移概率介于0.3~0.5。基于以上结果,建议拥有高等级专利的高校可以谋求技术合作,构建专利组合打包出售,推进科技成果转化;企业也可根据自身需求与相关高校对接,促进技术升级。同时,对于级别较低的专利,高校也应及时止损,减少资源浪费。

图4 专利价值分级
4 结语
客观、准确地对高校专利价值进行评估,是促进高校专利合理运营、实现成果变现,进而推动企业实现技术升级的重要环节,对构建产学研深度融合的技术创新体系具有积极意义。针对现有研究未能结合指标、文本等多维特征,专利价值划分粒度粗糙的问题,本研究提出了融合多维特征的高校专利价值分级方法:首先,从高校专利价值的3个重要来源出发,使用时下流行的Bert预训练模型表示专利文本语义特征,设计与专利价值直接关联的发明人特征,并与专利自身属性特征相融合;其次,采用机器学习算法构建高校专利价值评估模型,预测专利发生技术转移的概率;最后,对技术转移概率划定阈值,将专利价值的粒度细化为10个等级。对云计算领域进行的实证研究表明,本研究所提方法能够有效将专利文本语义特征、专利自身属性特征、发明人特征进行融合,构建的模型与现有研究相比AUC值提升22个百分点,提高了高校专利价值评估结果的准确性和科学性,为高校专利价值评估提供了新的研究思路。该方法未来可应用于高校专利运营、专利推送、企业专利成果引进、产学研合作等场景。比如,高校可借助本方法对校内各领域专利进行分级评价,将等级高的专利打包出售实现成果变现,促进科技成果转化;企业可对领域内高校专利进行分级评价,精准引进高价值专利,还可筛选拥有高等级专利的高校作为备选合作伙伴,促进技术升级。不足之处在于:本研究的多维特征仅限于文本、数值型信息,而专利文献中存在的大量图片信息并没有得到有效利用。因此,在后续研究中,将探索融合更多类型的特征,以期对高校专利价值实现更为准确、客观的评价。
注释
①bert句向量生成接口开源网址:https://github.com/hanxiao/bert-as-service。
