机器学习中成员推理攻击和防御研究综述
2022-12-16马骁骥何志鹏侯哲贤朱笑岩伍高飞张玉清
牛 俊, 马骁骥, 陈 颖, 张 歌, 何志鹏, 侯哲贤, 朱笑岩,伍高飞, 陈 恺, 张玉清
1西安电子科技大学计算机科学与技术学院 西安 中国 710071
2西安电子科技大学通信工程学院 西安 中国 710071
3国家计算机网络入侵防范中心 中国科学院大学 北京 中国 101408
4海南大学网络空间安全学院 海口 中国 570228
5西安电子科技大学广州研究院 广州 中国 510555
6西安邮电大学网络空间安全学院 西安 中国 710121
7西安电子科技大学网络与信息安全学院 西安 中国 710126
8中国科学院信息工程研究所 信息安全国家重点实验室 北京 中国 100195
9中国科学院大学 网络空间安全学院 北京 中国 100195
1 引言
近年来, 海量可获得的数据、不断更新的硬件设备、强大的计算设施以及日益完善的智能算法, 极大地推动了人工智能(Artificial intelligence, AI)理论和技术的飞速发展, 促使传统行业的智能化变革。机器学习(Machine learning, ML)作为AI技术的一种实现方式, 在各个领域扮演者重要的角色并取得了巨大的成功, 比如图像识别[1], 自然语言处理[2], 图数据应用[3]、脑电路分析[4]、数据挖掘[5]、计算机视觉[6]、电子邮件过滤[7]、检测信用卡欺诈[8]、能源勘探等。虽然, 机器学习促使人们的生活更加方便、快捷和智能, 但其需要大量的数据进行训练, 而这些数据中包含隐私敏感数据, 比如用户文件、位置轨迹等信息。这使得机器学习的安全性、隐私性和公平性也面临着更加严峻的挑战。同时也使机器学习隐私安全问题受到了广泛的关注[9-10]。
众所周知, 机器学习会无意识记住它的训练数据信息, 从而容易遭受各种隐私攻击, 比如模型提取攻击[11], 属性推理攻击(也叫模型逆向攻击)[12], 特征推理攻击[13], 以及成员推理攻击[14]。其中, 成员推理攻击(Membership inference attacks, MIAs)主要推测一个数据样本是否被用来训练目标机器学习模型。这种攻击对个人造成了极大的隐私威胁, 比如: 通过识别某个医疗记录被用来训练一个和特定疾病相关的模型, 可推测某人的健康隐私信息。2019年的一项报告[15]特别强调: 成员推理攻击是隐蔽的隐私破坏。而且, 成员推理攻击可导致机器学习服务(Machine learning as a service, MLaaS)提供商违反隐私法规。比如, Veale等人[16]指出成员推理攻击增大了数据被视为隐私个人信息的风险。Homer等人[17]首次在生物领域提出成员推理攻击的概念, 其主要推测某个特定基因是否在基因数据集中。Shokri 等人[14]首次在机器学习领域提出针对分类模型的成员推理攻击。
目前, 已有很多英文综述研究机器学习中的不同的隐私攻击[18-24], 这些隐私风险综述主要侧重研究机器学习中的隐私安全, 介绍了成员推理攻击的基本概念以及基本的讨论, 并没有进行深入的归纳和总结。另外, 针对成员推理攻击和防御的综述一共有3篇[25-27], 其中2篇中文综述、1篇英文综述。表1从发表时间、使用语言、调研数量、攻击定义、威胁模型、攻击分类、攻击原因分析、防御分类、攻击应用介绍、评估机制和数据集11个方面比较已有的3篇成员推理攻击和防御综述与本文工作, 可以看出: 已有3篇综述[25-27]的调研文献数量逐渐增多,但仍缺少对2021年9月以后成员推理攻击和防御文献的总结和对比研究; 仅给出了基于二元分类器的MIAs定义, 缺少对基于评估机制和基于数据集差异的MIAs定义; 仅研究了黑盒和白盒两种威胁模型,缺少对灰盒威胁模型以及开源情况的归纳研究; 仅从攻击原理、攻击场景、背景知识、攻击的目标模型、攻击领域等方面对MIAs进行分类, 缺少从攻击数据集大小进行的分类, 而该因素在现实中对攻击者至关重要; 从信任分数处理、正则化、差分隐私和知识蒸馏对MIAs防御进行分类和比较, 不够细致和严谨; 缺少对MIAs攻击和防御评估指标和新兴领域所用数据集的归纳和总结。

表1 已有成员推理攻击和防御综述与本文比较Table 1 Comparisons of existing surveys of MIAs and Defenses with this paper
鉴于成员推理攻击发展迅猛, 现有的机器学习中的隐私安全综述[18-24]和成员推理攻击的中英文综述[25-27]并不能对成员推理攻击和防御进行全面的介绍和归纳, 为此我们对成员推理攻击和防御进行了系统性分析和研究, 调研了从2017年到2022年6月的190篇左右的相关文献, 跨越了图像分类、语音识别、自然语言处理、计算机视觉等领域, 其中成员推理攻击118篇, 成员推理攻击防御71篇。这些文献基本是发表在安全、隐私和机器学习领域顶级会议和期刊上的论文, 以及在公共平台上(如arXiv)上的预发表论文。其中四大安全高水平会议包括: IEEES&P、CCS、USENIX Security和NDSS; 人工智能高水平会议包括: ICML、AAAI、IJCAI和TPAMI; 计算机视觉高水平会议CVPR、ECCV等。表1表明: 我们的工作在调研数量、攻击定义、威胁模型、攻击分类、防御分类、评估指标和数据集等方面优于已有的3篇成员推理攻击和防御综述。
图1(a)展示了2017—2022年6月成员推理攻击和防御相关的研究数据, 可知从2017—2022年(6月)论文发表数量呈上升趋势。图1(b)和(c)显示了从2017—2022年6月, 成员推理攻击和防御按攻击场景、背景知识和攻击领域分类后, 分别对应的文献数量。可知, 成员推理攻击从集中式转变为分布式、黑盒演变到白盒、图像分类扩展到文本处理等领域。
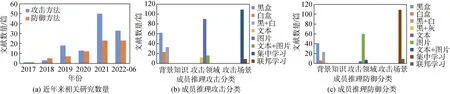
图1 近年来相关研究数量和成员推理攻击和防御分类Figure 1 The number of publications in recent years and classifications of the membership inference attacks and defenses
本文主要研究了成员推理攻击的定义、威胁模型、攻击方法、存在原因、防御机制、评估指标、使用数据集、实际应用以及有价值的现象与结论等,极大地增强了成员推理攻击综述的宽度和深度。主要包括6个方面的贡献:
1) 调研了189篇成员推理攻击和防御文献, 系统性对成员推理攻击的攻击原理、攻击场景、背景知识、攻击的目标模型、攻击领域和攻击数据集大小进行了梳理、归纳和总结, 并分析了不同成员推理攻击方法的优缺点;
2) 从目标模型的训练数据、模型类型以及模型的过拟合程度3个角度, 对成员推理攻击存在原因进行了深入剖析和归纳;
3) 从差分隐私、正则化、数据增强、模型堆叠、早停、信任分数掩蔽和知识蒸馏7个维度, 对成员推理攻击防御措施进行了分类和归纳, 并比较了不同防御方法的优缺点;
4) 从图片数据、文本数据、图数据以及二元数据4个方面, 对成员推理攻击和防御所使用的数据集进行了归纳和总结; 并统计分析了成员推理攻击和防御的14类评估指标, 对比了各自的优缺点;
5) 从隐私审计、知识产权保护和疾病预测3个方面, 介绍成员推理攻击被作为隐私审计工具、模型版权保护手段、疾病筛查方法等的现实应用;
6) 深入分析已有成员推理攻击和防御的优缺点,以及尚未解决的问题和原因, 对其面临的挑战和未来研究方向进行了展望。
2 成员推理攻击
本小节主要介绍成员推理攻击的定义、攻击原理、威胁模型以及成员推理攻击的分类。
2.1 成员推理攻击的定义
机器学习中的成员推理攻击(MIAs)主要推测一个数据样本是否被用来训练一个目标机器学习模型。一个典型的MIA分为三个阶段: 训练、推测和攻击。现有成员推理攻击主要分为三类, 分别为基于二元分类器的MIAs、基于评估机制的MIAs和基于数据集差异的MIAs, 这三类MIAs的训练阶段相同, 主要区别在于推测和攻击阶段(主要由于攻击原理不同)。图2展示了基于二元分类器的MIAs的具体流程: 训练阶段主要是将目标数据集输入机器学习模型中, 并利用已有的机器学习算法(如, 决策树等)训练得到一个目标模型Γt, 然后该目标模型Γt被部署在各种机器学习平台上(如谷歌、亚马逊、微软等)用于提供机器学习服务(MLaaS)。用户可通过API接口查询目标模型Γt,获得查询结果, 并向机器学习平台支付相应的费用。预测阶段是指攻击者通过MLaaS的API接口,输入一些其认为和目标模型训练集分布相似的数据给目标模型Γt, 获得对应的输出概率, 并利用查询数据和输出概率训练一个二元分类器, 作为最终的攻击模型Γa。 ⊙
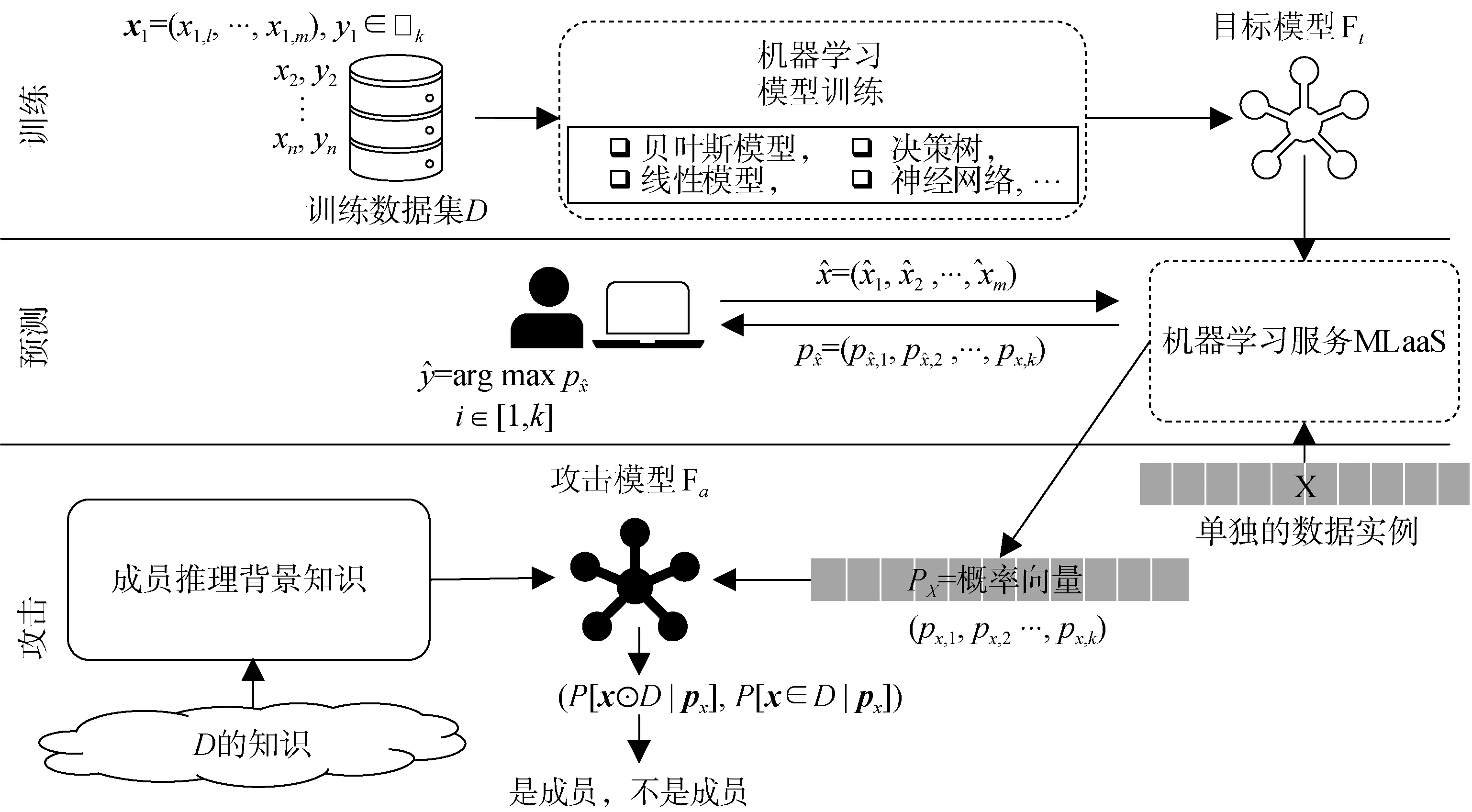
图2 基于二元分类器的成员推理攻击流程图Figure 2 The workflow of a Membership Inference Attack based on Binary-classifier
攻击阶段, 攻击者将某个感兴趣的数据点ix输入到目标模型中得到输出概率, 再将输出概率输入攻击模型Γa中, 如果Γa输出是“1”, 则认为ix是成员; 否则ix不是成员。
基于评估机制的MIAs在推测阶段首先制定一个阈值, 并通过API接口将需要攻击的数据输入目标模型Γt, 获得相应的模型输出(比如, 输出概率和输出标签), 攻击者不需要训练攻击模型; 在攻击阶段, 攻击者只需要比较得到的模型输出和预先定义阈值的相对大小, 如果模型输出大于预先定义的阈值, 则认为是成员, 否则认为是非成员。
基于数据集差异的MIAs在预测阶段构建两个数据集, 一个是目标攻击数据集, 另一个是非成员数据集, 其中目标数据集中既包含成员样本又包含非成员样本, 而非成员数据集只包含非成员样本;接着攻击者将这两个数据集中的数据样本输入目标模型Γt中, 获得对应的模型输出概率, 攻击者不需要训练攻击模型, 需计算这两个数据集模型输出概率间的最大均值差异(Maximum mean discrepancy,MMD); 在攻击阶段, 攻击者从目标攻击数据集中任意移动一个数据样本到非成员数据集, 比较移动该数据样本前后这两个数据集间MMD距离的相对大小, 如果移动该数据样本后, 这两个数据集模型输出概率的MMD距离变小, 则认为该样本是成员, 否则认为该样本是非成员。
2.2 成员推理攻击的威胁模型
根据攻击者所拥有的背景知识, 我们将成员推理攻击中的威胁模型分为3类, 即黑盒、灰盒和白盒威胁模型(参见表2)。
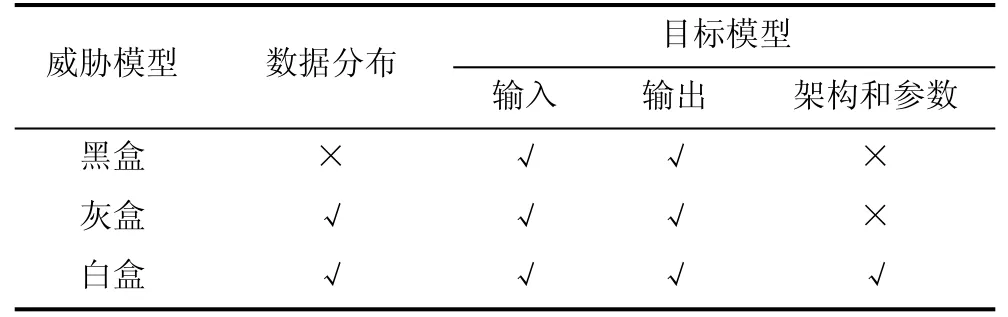
表2 威胁模型(敌手知识)Table 2 Threat models ( adversarial knowledge)
2.2.1 黑盒威胁模型
黑盒威胁模型(Black-box attacks)是指攻击者对目标模型的“训练数据知识”、学习算法、系统架构、学习参数一无所知, 其只能查询机器学习服务(MLaaS)中的目标模型, 并获得相应的预测输出, 其是3种攻击威胁中假设最弱的, 且在现实生活中最为常见。
2.2.2 灰盒威胁模型
灰盒威胁模型(Gray-box attacks)是指攻击者对目标模型的学习算法、系统架构、学习参数一无所知, 但其不仅可以查询目标模型, 获得相应的预测输出, 而且可获得和目标模型训练数据集分布相同的数据, 并利用相应的数据增强技术(如, GANs或VAEs)生成更多数据, 训练更强的攻击模型。灰盒威胁模型介于白盒和黑盒之间。
2.2.3 白盒威胁模型
白盒威胁模型(White-box attacks)是指攻击者可以获得目标模型的所有信息, 即目标模型的训练集数据分布、训练算法、系统架构、学习参数, 其是三种威胁模型中假设最强的, 也是现实中最不常见的。
2.3 成员推理攻击的分类
本小节, 主要从攻击原理、攻击场景、背景知识、攻击的目标模型、攻击领域和攻击数据集大小6个方面对成员推理攻击进行全面细致的分类和介绍,图3表示成员推理攻击发展历程。

图3 成员推理攻击发展历程Figure 3 The development of membership inference attacks
2.3.1 按攻击原理
已有研究[47-50]发现机器学习模型(如, 深度神经网络DNN)通常是过参数化的, 会记住其训练数据并存储在模型参数中[14,48,51]。根据成员推理攻击的不同攻击原理, 我们将已有成员推理攻击方法分为3类:基于二元分类器的MIAs、基于评估机制的MIAs和基于数据集差异的MIAs(参见表3)。

表3 根据攻击原理对成员推理攻击方法进行分类Table 3 Classifications of MIAs based on attacks’ principles
1) 基于二元分类器的攻击:
基于二元分类器的成员推理攻击是指: 攻击者利用一个或多个影子模型, 其主要模仿目标模型的性能, 根据已有数据和影子模型的预测输出训练一个二元分类器作为最终的成员推理攻击模型。
Shokri等人[14]提出一个有效的影子模型训练技术来训练一个二元分类器作为攻击模型, 采用多个影子模型。与R. Shokri等人[14]的方法相似, Long等人[52]测试一个样本“在”与“不在”训练集中时, 影子模型输出差异, 来区分成员和非成员。Long等人[53]主要在训练数据集中识别出“易受攻击样本”和“增强样本”, 并分别实施有目标和无目标的成员推理攻击。Salem等人[54]提出一个更一般的成员推理攻击,主要放宽了以前攻击的主要条件, 发现只有一个影子模型也可实施有效的成员推理攻击。
同时, Truex等人[55]提出了一个黑盒成员推理攻击的一般形式, 并联合不同机器学习模型研究模型选择对模型脆弱性的影响。Chen等人[56]首次研究机器去学习领域中无意识信息泄露问题, 提出一个新的基于版本差异的成员推理攻击方法。Shokri等人[57]用成员推理攻击研究了基于特征的隐私泄露模型解释。Liu等人[58]提出一个名为“SocInf”的成员推理攻击方法, 并利用构建的模仿模型对训练和测试数据表现的差异来区分成员和非成员。Chen等人[59]首次研究工业物联网中的成员推理攻击, 提出一个迁移遗传影子训练技术, 并放宽了已有的假设。Song等人[60]研究语言模型中的成员推理攻击, 提出一个新的针对深度学习模型审计技术。Wang等人[61]首次研究边缘智能中的成员推理攻击, 提出一个针对多等级边缘智能的攻击模型。
基于二元分类器的MIAs可在黑盒、灰盒、白盒3种情况下实施攻击, 但需要根据影子模型和额外数据训练二元攻击模型, 攻击开销有时较大。
2) 基于评估机制的攻击:
基于评估机制的成员推理攻击是指: 攻击者根据预先定义的成员评估机制来进行成员和非成员判断, 包括: 模型输出阈值、损失阈值、样本标签阈值、交叉熵损失阈值、对抗扰动和假设检验。
① 模型输出阈值:
基于模型输出阈值的成员推理攻击是指: 攻击者根据目标模型的输出信任分数制定一个阈值, 当某个样本的输出信任分数大于该阈值时, 认为该样本是成员, 否则不是成员。
Salem等人[54]提出了Global-TopOne和Global-TopThree攻击, 当某个样本的预测输出大于top1或top3特征阈值时, 认为该样本是成员。Irolla等人[62]通过理论证明: 信任分数在大多数情况下, 对成功的成员推理攻击起到了很少的表示作用。Bentley等人[63]研究目标模型的泛化误差如何影响黑盒成员推理攻击的有效性, 并发现泛化误差越大, 成员信息越容易泄露。Sablayrolles等人[64]基于参数分布的假设来研究成员推理攻击, 并推导出成员推理攻击的最优策略。
② 损失阈值:
基于损失阈值的成员推理攻击是指: 攻击者先根据目标模型对成员的输出信任分数计算成员的平均损失, 并制定一个阈值, 当某个样本的输出信任分数损失小于该阈值时, 认为该样本是成员, 否则不是成员。
Ye 等人[36]提出一个基于蒸馏的损失阈值攻击,AUC面积可达87.6%。Sablayrolles等人[64]基于参数分布的假设来研究成员推理攻击, 发现最理想的攻击仅依赖于损失函数。Yeom等人[65]在白盒场景下研究当一个训练样本的模型损失小于某个阈值(训练集的平均损失)时, 认为该样本是成员。
③ 样本标签阈值:
基于样本标签阈值的成员推理攻击是指: 攻击者根据目标模型的输出标签来识别成员, 当某个样本的预测标签和真实标签一致时, 认为该样本是成员, 否则不是成员。
Yeom等人[65]提出一种基于目标模型预测标签的成员推理攻击方法, 当样本的预测标签和其ground-truth标签一致时, 则认为其是成员。Choquette等人[66]通过评估模型对扰动后输入数据预测标签的鲁棒性来推测成员关系。Li等人[67]提出了基于决策的成员推理攻击——基于迁移和基于边界的攻击, 并研究多个防御机制。Rahimian等人[68]提出一种基于标签的样本攻击, 攻击成功率很高(如100%)。
④ 交叉熵损失阈值:
基于交叉熵损失阈值的成员推理攻击是指: 攻击者将已有数据输入目标模型得到预测的信任分数,计算这些信任分数的交叉熵, 并制定一个交叉熵阈值, 当某个样本的交叉熵小于该阈值时, 认为该样本是成员, 否则不是成员。Salem等人[54]提出了一种基于交叉熵损失阈值的成员推理攻击, 当某个样本的交叉熵小于制定的阈值时认为其是成员。Song等人[69]也提出了一个基于预测熵变化的新的成员推理攻击方法, 以及攻击风险评估准则。
⑤ 对抗扰动:
基于对抗扰动的成员推理攻击是指: 攻击者给样本添加扰动使得目标模型对该样本的预测标签发生变化, 并利用添加扰动的大小来识别成员和非成员。Choquette等人[66]通过评估模型对扰动后输入数据预测标签的鲁棒性来推测成员关系。Li等人[67]提出一种基于决策的成员推理攻击, 主要通过给样本添加的对抗扰动大小来判断成员和非成员。
⑥ 假设检验:
基于假设检验的成员推理攻击是指: 攻击者首先假设“成员条件”和“非成员条件”, 当某个样本的“成员条件”的概率大于“非成员条件”的概率, 认为该样本是成员, 否则不是成员。Long等人[52]提出了一个基于假设检验的实际成员推理攻击方法, 当样本假设检验的值小于一个切断的阈值时, 认为该样本是成员。同时, Long等人[53]根据成员样本对模型独特的影响, 在黑盒场景下提出基于假设检验的成员推理攻击方法。
基于评估机制的MIAs不需要训练攻击模型, 节省攻击成本, 但阈值选择有时花费时间较多。
3) 基于数据集差异性比较的攻击:
基于数据集差异性比较的成员推理攻击是指:攻击者利用在两个数据集中任意移动一个样本后,两数据集移动前后的距离差异进行成员和非成员的识别。Hui等人[70]利用差异比较提出一种实际盲成员推理攻击—BLINDMI, 并通过一个新的差异分布方法来提取成员语义信息。
2.3.2 按攻击场景
根据成员推理攻击实施的不同场景——集中式和分布式场景(参见图4), 我们将已有成员推理攻击方法分为2类: 集中式和分布式成员推理攻击(参见表4)。

表4 根据攻击场景对成员推理攻击进行分类Table 4 Classifications of MIAs based on attacks’ scenarios

图4 集中式机器学习和分布式机器学习Figure 4 Examples of centralized and federated machine learning
1) 集中式成员推理攻击(centralized MIAs):
集中式机器学习是指将所有用户或设备的信息收集到一个服务器上, 并利用机器学习算法进行训练得到对应的目标模型。
Jayaraman等人[71]提出一种现实假设中的成员推理攻击——Merlin, 利用基于正例预测值联合成员增益的机制来评估隐私信息泄露情况。Hilprecht等人[72]针对现有生成网络提出蒙特卡洛攻击和重构攻击, 分别在黑盒和白盒场景下对GANs和VAEs网络进行攻击。同时, Hayes等人[73]研究生成网络生成的样本如何泄露一般模型或过拟合模型的隐私信息。Chen等人[74]研究深度生成模型中的成员推理攻击,首次提出一个一般性的攻击模型——利用Parzen窗口密度估计近似计算一个样本由受害生成器生成的概率, 并根据概率的大小进行成员和非成员的判断。Leino等人[75]发掘模型内部特征和运作规律, 捕捉更有效的信息作为“成员证据”。
集中式MIAs将数据收集起来训练模型, 不需要上传训练梯度和参数, 但需要上传数据, 增加隐私泄露风险, 且对于某些不能公开收集的数据, 无法完成模型训练。
2) 分布式成员推理攻击(federated MIAs):
分布式机器学习是指各个用户或设备不需要上传自身数据, 仅从参数服务器上下载模型架构, 并在本地利用机器学习算法进行训练, 只将训练的梯度和参数上传给参数服务器, 参数服务器收集整合所有用户上传的梯度和参数, 更新全局模型。Nasr等人[76]提出一个联邦学习场景中基于梯度信息的成员推理攻击, 发现最后一层梯度信息的攻击效果好于利用泛化误差实施的成员推理攻击。Zhang等人[77]提出一种针对联邦学习的被动成员推理攻击, 主要利用生成对抗网络来增加数据多样性, 攻击成功率可达98%。Chen等人[78]提出一个用户层面的联邦学习黑盒成员推理攻击, 并采用生成对抗网络来增加数据量。Hu等人[79]提出了一个新的名为源推理攻击的联邦学习成员推理攻击方法, 可获得对训练成员源头的理想化评估。
同时, Melis等人[80]研究联邦学习中无意识隐私信息泄露问题, 并且利用这些信息可以发起被动或者主动的成员推理攻击。Wang等人[81]研究联邦场景下由恶意服务器发起的成员推理攻击, 在服务器端将GAN网络和多功能鉴别器相结合实施攻击。Gupta等人[82]研究深度回归模型用于神经影像中的成员推理攻击, 发现上传的训练参数仍可泄露数据隐私。
分布式MIAs不需要上传数据, 降低隐私泄露风险, 打破数据孤岛, 但存在恶意参与者或参数服务器, 增加隐私泄露风险。
2.3.3 按攻击者的背景知识
根据攻击者所拥有的背景知识——“训练数据知识”和“目标模型知识”, 我们将成员推理攻击分为黑盒、灰盒和白盒成员推理攻击(参见表5)。

表5 根据攻击者的背景知识对成员推理攻击进行分类Table 5 Classifications of MIAs based on attacks’ scenarios
1) 黑盒成员推理攻击:
黑盒成员推理攻击是指攻击者对目标模型的“训练数据知识”、学习算法、系统架构、学习参数一无所知, 只知道目标的预测输出。已有的大部分攻击都是黑盒成员推理攻击, 如基于二元分类器的MIAs[12,52-58]、基于评估机制的MIAs[64-69]、基于差异性比较的MIAs[70], 以及集中式MIAs[71], 其具体内容已在2.3.1和2.3.2节详细介绍过, 在此不再赘述。Kulynych等人[83]深入分析了黑盒成员推理攻击不同的脆弱性, 并提出一个满意的框架来解决现实中的这些问题。黑盒MIAs需要的背景知识最少, 在现实中最常见, 但仅依赖目标模型和影子模型输出易导致攻击效果有限。
2) 灰盒成员推理攻击:
灰盒成员推理攻击是指攻击者对目标模型的学习算法、系统架构、学习参数一无所知, 但是攻击者可以获得目标模型的预测输出和与目标模型训练数据分布相同的数据。Hui等人[70]基于差异比较提出一种实际盲成员推理攻击—BLINDMI-DIFF, 其在所有场景下通过一个新的差异分布方法来提取成员语义信息。灰盒MIAs需要适中的背景知识且攻击效果较黑盒有所提高, 但现实中有时无法获得与训练数据分布相同的数据, 导致攻击效果提升有限。
3) 白盒成员推理攻击:
白盒成员推理攻击是指攻击者可以获得目标模型的所有信息, 即目标模型的训练集数据分布、训练算法、系统架构、学习参数。2.3.2节介绍的集中式MIAs[72-75]和分布式MIAs[76,80]都属于白盒成员推理攻击, 在此不再赘述。
Rezaei等人[84]在白盒场景下, 研究深度模型中成员推理攻击的不可行性。Carlini等人[85]研究基于深度学习的生成序列模型中的白盒成员推理攻击。Sablayrolles等人[86]在白盒场景下, 提出针对成员推理攻击的贝叶斯优化策略。Song等人[87]研究深度学习中, 白盒和黑盒的成员推理攻击和数据版权保护问题。Ha等人[109]提出成员特征分解网络, 从数据特征的角度来研究成员推理。Gu等人[110]设计了联邦学习中局部和全局攻击推理算法。Zhang等人[111]提出了一种基于对抗鲁棒性的成员推理攻击增强方法。Pichler等人[112]研究了一个不诚实的中央服务器的框架。Watson等人[113]提出成员推理攻击可以从难度校准中获得巨大好处。Hu等人[139]提出了一种基于成员推理的过度代表性攻击。Rezaei等人[146]提出已有成员推理攻击性能报告具有误导性。白盒MIAs攻击效果最好, 但需要的背景知识最多, 现实中很难实现。
2.3.4 按攻击的目标模型
根据攻击者所攻击的目标模型, 我们将成员推理攻击分为针对分类模型的MIAs、针对回归模型的MIAs、针对嵌入模型的MIAs、针对生成模型的MIAs、针对临床语言模型的MIAs和针对彩票网络的MIAs(参见表6)。
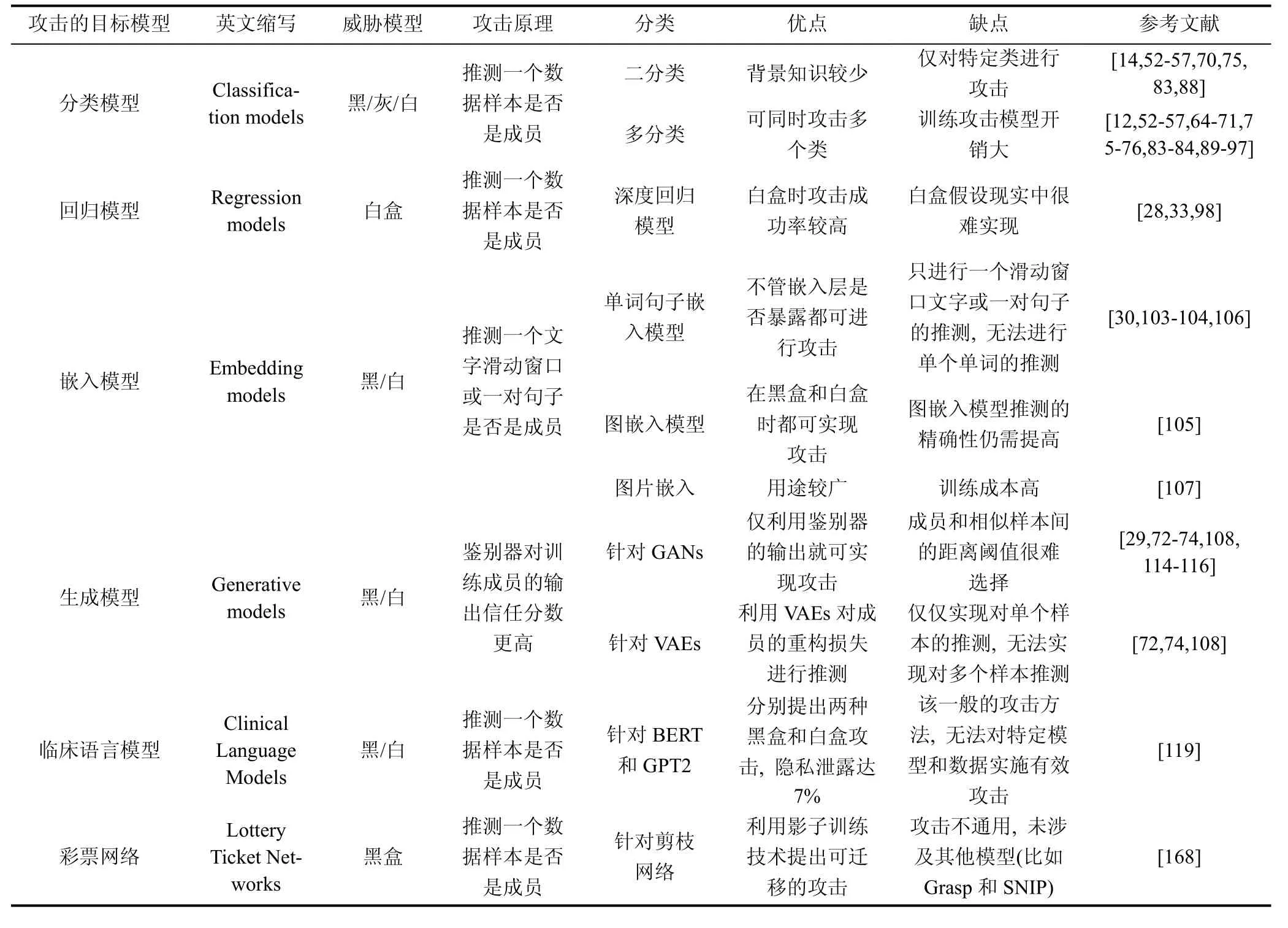
表6 根据攻击的目标模型对成员推理攻击进行分类Table 6 Classifications of MIAs based on target models
1) 分类模型的MIAs:
针对分类模型(classification models)的MIAs包括针对二分类模型的MIAs和针对多分类模型的MIAs。
① 针对二分类模型MIAs:
针对二分类模型的MIAs是指攻击者攻击的目标模型是二分类模型, 主要判断某个样本是否是该二分类模型训练集中的成员。已有的部分MIAs针对二分类模型, 如基于二元分类器的MIAs[14,52-57]、基于差异性比较的MIAs[70]、集中式MIAs[75]和黑盒MIAs[83], 其具体内容已在2.3.1、2.3.2和2.3.3节介绍过, 在此不再赘述。Humphries等人[88]在理论和实验上研究了差分隐私在什么情况下会遭受成员推理攻击。
② 针对多分类模型MIAs:
针对多分类模型的MIAs是指攻击者攻击的目标模型是多分类模型, 主要判断某个样本是否是该多分类模型训练集中的成员。已有的部分MIAs针对多分类模型, 如基于二元分类器的MIAs[14,52-57]、基于评估机制的MIAs[64-69]、基于差异性比较的MIAs[70]、集中式MIAs[71,75]和分布式MIAs[76,80], 黑盒MIAs[83]和白盒MIAs[84], 其具体内容已在2.3.1、2.3.2和2.3.3节介绍过, 在此不再赘述。
Song等人[89]首次联合研究机器学习服务中隐私性和安全性的关系。Truex等人[90]提出了一个成员推理攻击一般的表示形式, 研究模型在什么样的条件下易遭受黑盒成员推理攻击。Rahman等人[91]系统性研究了差分隐私模型中的成员推理攻击。Li等人[92]提出模型泛化误差与成员推理攻击脆弱性间的数字关系。Kaya等人[93]研究了正则化在抵御成员推理攻击中的有效性, 并给出正则化的下界。Liu等人[94]首次提出一个机器学习中推理攻击的整体风险评估方法——ML-DOCTOR。Chang等人[95]研究了算法的公平性如何影响训练数据隐私泄露, 其从成员推理攻击角度分析组公平性的隐私风险。He等人[96]研究图神经网络中(graph neural networks, GNNs)基于节点的成员推理攻击。Iyiola等人[97]也研究了图神经网络中的成员推理攻击问题。
针对分类模型的MIAs可在不同情况下进行攻击, 且攻击效果较好(比如, 攻击精确率85%, 召回率接近100%), 但需要训练多个影子模型, 使得攻击模型训练开销较大。
2) 回归模型的MIAs:
针对回归模型的MIAs是指: 攻击者预测一个样本是否被用来训练一个回归模型(比如, 深度回归模型)。Tan等人[33]提出一个过度参数化的未被充分探索的隐藏代价。Gupta等人[98]首次提出深度回归模型中的成员推理攻击, 结合参数梯度、激活函数、模型预测和样本标签的构造攻击模型。
3) 嵌入模型的MIAs:
嵌入模型是指将原始的目标(比如, 文字、句子和图)映射成实值向量的数学函数, 主要为了捕捉和保存原始目标的重要语义信息。针对嵌入模型的MIAs是指: 攻击者推测一个样本是否在嵌入模型的训练数据集中。Song和 Raghunathan[103]首次提出单词和句子嵌入模型中的成员推理攻击, 主要推测一个文字滑动窗口或一对句子是否在嵌入模型的训练数据集中。Mahloujifar等人[104]表明即使嵌入层和嵌入模型不暴露给攻击者, 仍会遭受成员推理攻击。Duddu等人[105]首次研究图嵌入模型中的成员推理攻击, 提出一个黑盒影子模型攻击以及一个基于信任分数的白盒成员推理攻击。Klakow等人[106]研究了在各种预训练词嵌入模型(如GloVe、ELMo和BERT)上的隐私泄露问题。Liu等人[107]提出了第一个在对比学习上预训练的图片嵌入器中的成员推理攻击(EncoderMI方法)。
针对嵌入模型的MIAs可适用单词嵌入、图嵌入、图片嵌入等不同情况, 攻击准确率可达83.04%,但假设攻击者的背景知识较强, 现实中实现困难且攻击模型训练成本较高。
4) 生成模型的MIAs:
针对生成模型的MIAs主要是指: 攻击者推测一个样本是否被用于训练一个生成模型, 包括: 生成对抗网络(GANs)和变分自动编码器(VAEs)。2.3.2节介绍的集中式成员推理攻击[72-74]主要是针对生成模型。
Liu等人[108]提出一个共同的成员推理方法, 其对于不同的输入数据需要重新训练新的神经网络,而集合成员推理攻击方法[73]仅利用生成器合成的固定数据。文献[72,74,108]统一表明VAEs比GANs更易遭受成员推理攻击。Wu等人[114]提出各种针对成员推理攻击方法来研究泛化好的GANs的隐私泄露情况。Mukherjee等人[115]提出一个新的生成对抗网络架构privGAN, 其生成器不仅要欺骗鉴别器, 而且还能抵御MIAs。Webster等人[116]通过构建一个新的成功的成员推理, 来挑战GANs生成的图片是新创造的假设。
针对生成模型的MIAs可攻击不同生成模型(如GANs和VAEs), 但很难选择合适的攻击阈值(如, 距离阈值), 无法对多样本实施攻击。
5) 临床语言模型的MIAs:
针对临床语言模型的MIAs主要是指: 攻击者推测一个样本是否被用于训练一个临床语言模型。Jagannatha等人[119]提出一个针对临床语言模型的MIA, 主要针对针对BERT 和GPT2模型, 分别提出两种黑盒和白盒攻击, 隐私泄露达7%, 但对特定模型和数据无法实施更准确攻击。
6) 彩票网络的MIAs:
针对彩票网络的MIAs主要是指: 攻击者推测一个样本是否被用于训练一个彩票网络, 彩票网络是指利用剪枝技术得到一个神经网络的子网络。Bagmar等人[168]利用影子训练技术提出一个针对彩票网络的成员推理攻击, 且不同网络的攻击具有可迁移性, 但其只适用于ResNet18和ResNet50, 对Grasp和SNIP模型无法实施攻击。
2.3.5 按攻击的不同领域
根据成员推理攻击涉及的不同领域, 我们将其划分为图像分类、自然语言处理、计算机视觉、音频、推荐系统、迁移学习、对比学习、图神经网络、在线学习、机器去学习、医疗场景、工业物联网和边缘智能等领域(参见表7)。
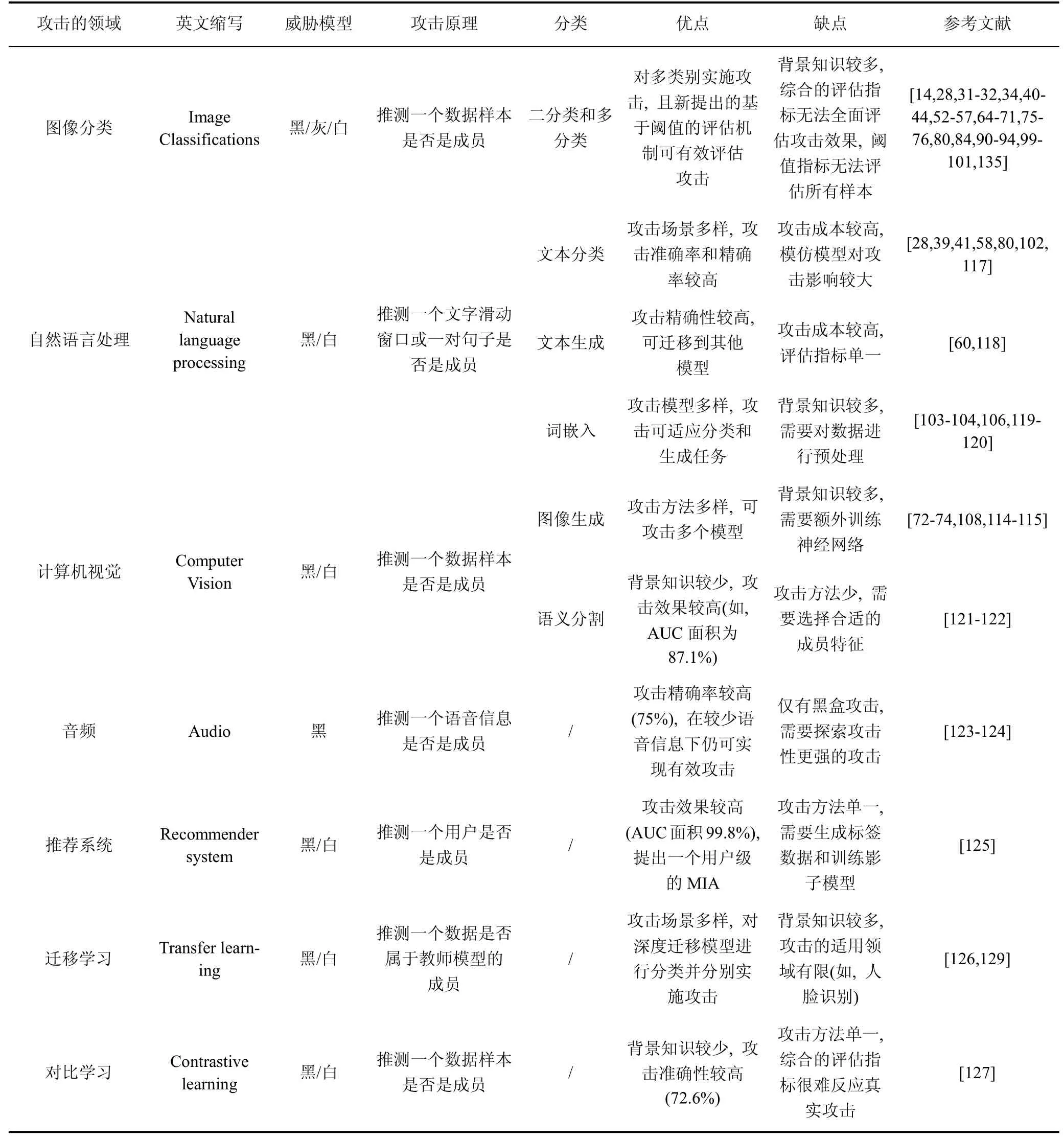
表7 根据攻击的不同领域对成员推理攻击进行分类Table 7 Classifications of MIAs based on different domains
1) 图像分类:
针对图像分类的MIAs是指攻击者判断图像分类领域的MIAs。已有大部分成员推理攻击针对图像分类, 如基于二元分类器的MIAs[14,52-57]、基于差异性比较的MIAs[70]、基于评估机制的MIAs[64-69]、集中式MIAs[71]、白盒MIAs[75-76,80,84]、分类模型MIAs[90-94], 其具体内容已在2.3.1、2.3.2、2.3.3和2.3.4节详细介绍过, 在此不再赘述。

续表
Jagielski等人[28]提出利用一个或多个模型更新的新成员推理攻击。Zhang等人[31]提出语义分割模型中单标签隶属度推断攻击。Rezaei等人[32]提出一种利用目标模型对语义相似样本输出差异的攻击。Yuan等人[34]提出了一种剪枝神经网络的自注意成员推断攻击。GMR等人[40]研究隶属度推理攻击对传统机器学习算法的影响。Li 等人[42]提出了一个用户成员推理攻击。Del等人[43]提出了基于训练模型识别数据隐私风险的标准方法。Pedersen 等人[44]提出攻击者可通过简单攻击策略达到隐私损失的下限。Long等人[52]研究实际场景中的成员推理攻击, 并设计了一个新的可在样本个体层面而不是聚集的训练集层面的攻击方法。Jayaraman等人[71]发现均衡的先验概率在实际中不可行, 并提出一个新的成员推理攻击Merlin。Carlini 等人[99]提出了一个似然比攻击。Mahloujifar等人[100]提出了攻击者进行成员推理攻击的增益边界。Duddu等人[101]提出了SHAPr指标, 用来量化模型对单个训练数据的记忆。
针对图像分类的MIAs可对多类别实施攻击, 且新提出的基于阈值的评估机制可有效评估攻击, 但背景知识较多, 综合的评估指标无法全面评估攻击效果, 基于阈值的评估指标无法评估所有样本。
2) 自然语言处理:
针对自然语言处理的MIAs是指攻击者判断自然语言处理领域的MIAs。根据不同的任务, 其可分为三类: 文本分类中的MIAs, 文本生成中的MIAs和词嵌入中的MIAs。
① 文本分类中的MIAs:
针对文本分类中的MIAs是指攻击者判断某个分类文本数据是否是训练集成员。Zhong等人[39]提出一种新的隐私泄露差异符号, 其量化了不同子组间的MIAs。Li等人[41]提出了黑盒成员推理攻击l-Leaks。Liu等人[58]提出一个名为“SocInf”的黑盒成员推理攻击方法。Melis等人[80]研究联邦学习中无意识隐私信息泄露问题。Yang等人[102]研究递归网络中的成员推理攻击。Wunderlich等人[117]研究了差分隐私分层文本分类中的隐私-可用性平衡问题, 并识别超出平衡的网络架构。
② 文本生成中的MIAs:
针对文本生成中的MIAs是指攻击者判断某个生成的文本数据是否是训练集成员。Song等人[60]研究语言模型中的成员推理攻击, 提出一个新的针对深度学习模型审计技术。Hisamoto等人[118]研究黑盒场景下端到端模型的成员推理攻击问题。
③ 词嵌入中的MIA:
针对词嵌入中的MIAs是指攻击者判断某个词或句子是否是嵌入模型的训练集成员。2.3.4节嵌入模型的MIAs[103-104]主要研究词嵌入中的MIAs。Jagannatha等人[119]在黑白盒场景下, 设计和评估了Bert和GPT2模型的隐私安全。Carlini等人[120]研究语言模型GPT2训练数据泄露情况。Klakow等人[106]研究了各种预训练词嵌入模型(如GloVe、ELMo和BERT)上的隐私泄露问题。
针对自然语言处理的MIAs攻击场景多样, 攻击实现83.04%的准确率, 83.2%的f1分数, 并可迁移到其他模型和任务(如, 分类和生成任务), 但需要的背景知识较多, 模仿模型对攻击影响较大, 且需要对数据进行预处理。
3) 计算机视觉:
针对计算机视觉的MIAs是指攻击者判断计算机视觉领域的MIAs, 包括图像生成中的MIAs和图像语义中的MIAs。
① 图像生成中的MIAs:
针对图像生成中的MIAs是指攻击者判断某个生成的图像是否是训练集成员。集中式MIAs[72-74]和生成模型[108,114-115]主要针对图像生成中的MIAs, 具体内容已在2.3.2和2.3.4节介绍过, 在此不再赘述。
② 图像语义分割中的MIAs:
针对图像语义分割中的MIAs是指攻击者判断某个分割图像是否是训练集成员。He等人[121]研究了语义图像分割领域的成员推理攻击问题, 并提出相应的隐私防御方法。Shafran等人[122]发现具有高维输入输出的数据易遭受成员推理攻击, 并研究图像变换和语义分割模型中的成员推理攻击。
针对计算机视觉的MIAs攻击方法多样, 可攻击多个模型, 攻击效果较高(如, AUC面积为87.1%),但背景知识较多, 且需要额外训练神经网络, 以及选择合适的成员特征实施有效攻击。
4) 音频:
针对音频的MIAs是指攻击者判断某个音频数据是否是训练集成员。Shah等人[123]研究语音识别模型中的成员推理攻击, 可实现60%的黑盒攻击准确率和召回率。Miao等人[124]主要研究语音服务中的黑盒成员推理攻击, 设计了一个音频审计器且准确性可达80%。针对音频的MIAs攻击精确率较高(如,75%), 在较少语音信息下仍可实现有效攻击, 仅有黑盒攻击, 需要探索攻击性更强的攻击。
5) 推荐系统:
针对推荐系统的MIAs是指攻击者判断某个用户是否是推荐系统训练集成员。Zhang等人[125]首次研究了推荐系统中的成员推理攻击, 提出一个新的方法来表示不同列表中的用户, 并采用一个影子推荐器来训练攻击模型。该方法攻击效果较高(AUC面积99.8%), 提出一个用户级的MIA, 但攻击方法单一, 需要生成标签数据和训练影子模型。
6) 迁移学习:
迁移学习是指将各大预训练模型(称作教师模型)应用于下游任务(称作学生模型), 用于提高学生模型的准确性。针对迁移学习的MIAs是指攻击者根据学生模型推测某个样本是否是教师模型训练集的成员。Chen等人[126]研究深度迁移学习中的隐私风险,并提出了隐私防御方法。同时, Liew等人[129]研究了迁移学习中的成员推理攻击问题, 提出一个新的策略从集成信息中进行推测。
针对迁移学习的MIAs攻击场景多样, 对深度迁移模型进行分类并分别实施攻击, 但背景知识较多,攻击的适用领域有限(如, 人脸识别)。
7) 对比学习:
针对对比学习的MIAs是指攻击者根据对比学习的模型差异, 推测某个样本是否是源域的训练集成员。He等人[127]首次研究对比学习中的成员推理攻击, 发现在图片数据集上训练的对比学习模型遭受成员推理攻击要小于属性推理攻击, 并提出一个隐私保护对比学习方案。该方法背景知识较少, 攻击准确性较高(如, 72.6%), 但攻击方法单一, 综合的评估指标很难反应真实攻击效果。
8) 图神经网络:
针对图神经网络的MIAs是指攻击者判断图神经网络领域的MIAs。根据不同的任务可以分为知识图谱的MIAs、节点分类中的MIAs和图分类中的MIAs。
① 知识图谱的MIAs:
针对知识图谱的MIAs是指攻击者判断某个样本是否是知识图谱训练集成员。Wang等人[128]研究知识图谱中的成员推理攻击, 其主要在4个标准的知识图嵌入模型上实施成员推理攻击。
② 节点分类中的MIAs:
针对节点分类中的MIAs是指攻击者判断图中某个节点是否是训练集成员。He等人[96]研究图神经网络中基于3个节点级的成员推理攻击。yiola等人[97]也研究了图神经网络中的成员推理攻击问题。Duddu等人[105]首次研究图生成模型中的图嵌入隐私泄露问题。
③ 图分类中的MIAs:
针对图分类中的MIAs是指攻击者判断某个样本是否是图分类网络的训练集成员。Wu等人[130]首次研究图神经网络中的成员推理攻击, 提出基于训练和基于阈值的攻击, 发现已有的图模型可遭受成员推理攻击且f1分数达到70%。
针对图神经网络的MIAs攻击场景多样, 可实现医疗和金融知识图谱的攻击, 攻击准确性较高(如,72.6%), 但需要的背景知识较多, 采用综合的评估指标会造成评估结果不准确。
9) 在线学习:
针对在线学习中的MIAs是指攻击者判断某个样本是否是在线学习的训练集成员。Salem等人[131]研究了在线学习场景下的成员推理攻击, 比较黑盒在线学习数据集更新前后的差异, 并提出四种基于编码器-解码器形式的攻击。该方法所需背景知识较少, 提出单个和多个样本攻击, 但攻击方法单一, 需要构造编码器和训练影子模型。
10) 机器去学习:
针对机器去学习中的MIAs是指攻击者判断某个被去掉的样本是否是机器去学习模型的训练集成员。Chen等人[132]首次研究机器去学习领域中无意识信息泄露问题, 提出一个新的基本版本差异的成员推理攻击方法。该方法提出两种机器去学习中的评估指标, 但攻击方法单一, 需生成后验概率, 并重构特征。
11) 医疗场景:
针对医疗场景的MIAs是指攻击者判断某个样本是否是医疗模型的训练集成员。Wu等人[133]表明其攻击会以很高的置信度重构真实医疗影像以及临床记录, 并提出一些防御机制。该方法攻击效果较好, 可重构医疗图片, 但攻击方法单一, 需训练攻击模型。
12) 工业物联网:
针对工业物联网的MIAs是指攻击者判断某个样本是否是工业物联网的训练集成员。Chen等人[59]首次研究工业物联网中的协作成员推理攻击, 提出一个迁移遗传影子训练技术, 并放宽了已有假设,但综合的评估指标无法准确反应攻击效果。
13) 边缘智能:
针对边缘智能的MIAs是指攻击者判断某个样本是否是边缘智能系统中的训练集成员。Wang等人[61]首次提出一个针对多等级边缘智能的攻击, 但攻击准确性无法反应攻击真实情况。
2.3.6 按攻击的数据集大小
根据成员推理攻击可攻击的数据集大小, 我们将其划分为攻击整个数据集和攻击部分数据集两类(参见表8)。

表8 根据攻击数据集大小对成员推理攻击进行分类Table 8 Classifications of MIAs based on the size of the attack datasets
1) 攻击整个数据集:
针对攻击整个数据集的MIAs是指攻击者利用成员推理攻击方法可以对数据集所有样本进行攻击,其主要在所有样本上采用综合的评估指标(比如, 准确率、精确率、召回率、f1分数等)。已有大部分成员推理攻击主要攻击整个数据集, 其具体内容已在2.3.1、2.3.2、2.3.3、2.3.4和2.3.5节详细介绍过, 在此不再赘述。
针对攻击整个数据集的MIAs使用综合的评估指标可以对整个测试集中所有样本进行评估, 但是召回率和f1分数在大多数情况下很高, 精确率在某些情况下很低, 且有高的假阳率, 严重损害攻击者的利益。
2) 攻击部分数据集:
针对攻击部分数据集的MIAs是指攻击者利用成员推理攻击方法只对数据集中特定精心挑选的样本进行有效攻击, 而对其他样本无法实施攻击, 其主要通过设计不同的评估机制, 并选择满足条件的阈值来实施基于评估机制的成员推理攻击。已有小部分成员推理攻击主要攻击部分数据集, 其具体内容已在2.3.1、2.3.2、2.3.3、2.3.4和2.3.5节详细介绍过, 在此不再赘述。
针对攻击部分数据集的MIAs利用不同的评估机制, 根据设定的特定阈值, 对满足阈值条件的样本, 可降低假阳率, 提高攻击质量, 但是这些攻击只对满足阈值要求的样本可实施较高质量攻击, 对其他样本无法实施有效攻击。
3 成员推理攻击存在的原因
已有一些工作[63,65,136-137]分析了成员推理攻击存在的原因, 但仍缺乏更科学严谨的解释。本小节, 主要从目标模型的训练数据、模型类型、过拟合程度三个角度, 分析成员推理攻击存在的原因。
3.1 目标模型的训练数据
目标模型训练数据集越具有代表性, 其遭受隐私泄露的风险越低。因为训练数据很好地表示了整个数据集的分布, 利用其训练出的模型能很好的捕捉和表征数据特征, 从而使得目标模型有很好的泛化性。文献[12]表明: 训练数据越多, 越不容易区分成员和非成员。然而, 现实中数据类型繁多, 且没有一个系统客观评估训练数据代表性的方法, 从而导致训练得到的目标模型极易遭受各种隐私攻击(如, 成员推理攻击), 极大地破坏了机器学习的安全性和隐私性。
3.2 目标模型的类型
除目标模型的训练数据外, 已有研究[55]表明目标模型的类型对其遭受成员推理攻击的风险起着至关重要的作用, 其通过对DNN、逻辑回归、朴素贝叶斯、k-近邻和决策树等模型进行成员推理攻击后,发现: 决策树是6个模型中攻击精确率最高的, 而朴素贝叶斯则是最低的, 原因是对于朴素贝叶斯模型来说, 单个训练数据只能在边缘影响给定类的预测;而对于决策树模型而言, 一个样本就代表一个独一无二的特征, 可使决策树产生一个新的分支, 并改变分类边界。因此, 不同的模型遭受攻击的风险不同。
3.3 目标模型的过拟合
除目标模型的训练数据和类型外, 已有研究[14,54,65,74-75]表明目标模型的过拟合是导致其遭受成员推理攻击的最主要原因。文献[138]表明造成模型过拟合的主要原因是模型的高复杂性和训练数据集有限的数据量。深度学习模型通常是过参数化的,而且具有很高的复杂性, 会有很强的能力记住噪声或者给定数据集的细节信息[47-50]。此外, 机器学习模型在训练时需要重复的在相同的样本训练很多个epochs, 从而导致训练样本很容易被模型记住。同时,有限的训练数据量很难完整表示整个数据分布, 限制了模型泛化性, 从而很难捕捉成员和非成员特征。
4 成员推理攻击的防御
本小节, 主要从差分隐私、正则化、数据增强、模型堆叠、早停、信任分数掩蔽和知识蒸馏七个方面介绍ML模型中成员推理防御(参见表9)。图5是MIAs防御发展历程。

图5 成员推理攻击防御发展历程Figure 5 The development of membership inference attacks’ defenses
4.1 基于差分隐私
利用差分隐私技术抵御成员推理攻击[32,65-66,70-71,74-75,88,90-92,114,140-145]是指攻击者给样本添加噪声抵御MIAs。
1) 差分隐私抵御分类模型中的MIAs
Shokri等人[14]首次讨论了差分隐私抵御成员推理攻击。Yeom等人[65]从理论上将差分隐私和机器学习联系起来。Rahimian等人[68]提出一种只在预测阶段给输入样本的logits添加噪声方法(DP-Logits), 并限制查询的次数。Truex等人[90]评估了在类别差异和不平衡数据上训练时, 差分隐私如何影响模型。Rahman等人[91]首次系统性地评估了成员推理攻击在差分隐私深度神经网络上的攻击效果, 发现其会降低模型可用性。随后, Jayaraman等人[141]在多个差分隐私机制上进行了系统性研究。
2) 差分隐私抵御生成模型中的MIAs
有研究[114,140,150-155]用差分隐私抵御生成模型中的MIAs。Hayes等人[32]首次评估了MIAs在差分隐私生成对抗网络(DP GAN)[152]中的攻击效果,隐私预算会影响攻击效果。Wu等人[114]系统性的证明使用差分隐私训练GANs的泛化误差有界限。Chen等人[140]发现差分隐私可降低GANs的MIAs风险, 但会导致GANs生成的样本质量变差, 并增加计算开销。Hu等人[147]提出了一种新的针对GANs的MIAs防御方法。 Chen等人[148]提出了一个新的防御框架RelaxLoss, 能抵御广泛的攻击。Bernau等人[149]评估了差分隐私可变自动编码器的强重建MIAs。Alvar等人[156]提出了对抗性知识提炼抵御图像翻译模型中的MIAs。Chen等人[157]提出一种增强型混合训练的防御方法。Yang等人[171]提出了一个通过VAE和扩展的差异隐私机制构建隐私保护系统框架。
虽然, 差分隐私给成员隐私提供了理论保障,但其几乎不能提供一个可接受的隐私-可用性平衡,当隐私预算较大时会导致模型不可用[141]。
4.2 基于正则化
正则化技术主要通过降低目标模型的过拟合来抵御成员推理攻击, 根据已有防御方法[14,54,69-70,92,144,159-161], 我们将从L2正则化[14]、Dropout[162]、标签平滑[163]、对抗正则[159,161]、Mixup +MMD[70,92], 介绍基于正则化的MIAs防御方案。
1) L2正则化
基于L2正则化的MIAs防御是指攻击者给损失函数添加L2正则化保护数据隐私。Shokri等人[14]主要将L2正则化添加到其损失函数中降低模型的过拟合并保护数据隐私。
2) Dropout
基于dropout的MIAs防御是指攻击者随机去掉一些神经元来保护数据隐私。Salem等人[54]也采用dropout方法抵御MIAs。Srivastava等人[162]首次提出利用dropout来保护数据隐私, 在每次训练的过程中任意去掉一些神经元。
3) 标签平滑
基于标签平滑的MIAs防御是指攻击者对标签进行平滑处理来保护数据隐私。Szegedy等人[163]提出一种标签平滑的成员推理攻击防御方法, 将样本的原始标签分布和一个给定的分布进行混合计算,并作为最后的标签。
4) 对抗正则
基于对抗正则的MIAs防御是指攻击者采用生成对抗网络的对抗思想来保护数据隐私。Hu等人[159]研究GANs的各种变体遭受成员推理攻击的情况,并提出一种基于Least Square GANs (LSGANs)的增强对抗正则方法来保护隐私。随后, Nasr等人[161]采用对抗正则的方法抵御MIAs, 提出一个基于生成对抗网络的MIN-MAX博弈的方法。
5) Mixup + MMD
基于MMD+Mix-up的MIAs防御是指攻击者结合MMD和Mix-up技术来保护数据隐私。Li等人[92]提出基于MMD+Mix-up的正则化矩阵法实现隐私保护。Hui等人[70]在Mixup + MMD防御方法上验证他们攻击方法BlindMI-DIFF的可行性。
基于正则化的MIAs防御方法可任何情况下保护数据隐私, 但很难提供满意的隐私和可用性平衡。
4.3 数据增强
基于数据增强的MIAs防御是指攻击者对数据进行增强处理来保护数据隐私。Kaya等人[160]提出一个损失排序相关性机制来评估不同机制间的相似性,并提出实际的隐私-可用性平衡的数据增强方法。该方法可通过数据降低过拟合, 但其需要额外数据,进一步增大防御成本。
4.4 模型堆叠
基于模型堆叠的MIAs防御是指攻击者将多个弱模型组合成一个强模型保护数据隐私。Salem等人[54]利用模型堆叠来抵御成员推理攻击, 主要将若干个弱的机器学习模型组合成一个强的机器学习模型,从而降低泛化误差。该方法联合多个模型的优点可实现更强的防御, 但是联合相同模型效果欠佳, 联合不同模型又增大防御开销。
4.5 早停
基于早停的MIAs防御是指攻击者利用很少的训练epochs来实现高的模型攻击准确性和低的隐私风险之间的平衡。Song等人[69]比较了他们的成员推理防御方法和早停方法。该方法可在训练阶段控制epochs, 通过简单操作实现防御, 但是epochs大小不好控制, 需要花费训练时间和成本。
4.6 基于信任分数掩蔽
基于信任分数掩蔽的隐私保护方法通过隐藏目标分类器输出的真实信任分数来保护成员隐私。主要包括: 只输出前k个信任分数(top-k); 只输出预测标签; 给信任分数添加精心设计的噪声。
1) top-k信任分数向量
Shokri 等人[14]首次在全连接网络中发现top-3信任分数仍不能抵御基于影子模型的MIAs。Salem等人[54]利用部分的信任分数实现和利用完整信任分数相似的攻击效果。
2) 只输出预测标签
文献[14]表明只返回预测标签可降低攻击准确率。Li等人[67]提出了基于输出标签的成员推理攻击,Choquette等人[66]也研究了只有输出标签的MIAs,发现只输出预测标签仍会泄露数据隐私。
3) 添加噪声的信任分数
Jia等人[142]提出一个基于对抗样本的“Mem-Guard”防御方法, 主要给信任分数添加噪声。Song等人[69]重新评估了Mem-Guard[142]的有效性, 发现Mem-Guard[142]仍易遭受成员推理攻击。
基于信任分数掩蔽的MIAs防御方法无需重新训练目标模型, 不影响目标模型的分类准确性, 但不能提供足够的隐私保证。
4.7 基于知识蒸馏
知识蒸馏是指利用大的教师模型的输出来训练一个小的学生模型, 将大的教师模型上的知识迁移到小的学生模型上, 并允许学生模型拥有和教师模型相似的准确率[172]。基于知识蒸馏的MIAs防御是指攻击者利用知识蒸馏处理数据后再进行模型训练。Shejwalkar等人[144]提出一种成员隐私蒸馏方法确保在防御时模型的可用性以及新的标准。Zheng等人[173]提出两个互补性知识蒸馏。基于知识蒸馏的MIAs防御方法减少对隐私数据的依赖, 但蒸馏数据的好坏影响防御效果且难以衡量, 仍存在隐私泄露风险。
5 成员推理攻击的评估指标和数据集
本小节, 总结了成员推理攻击和防御的评估指标以及使用的数据集。
5.1 评估指标
本小节, 主要介绍目标模型和攻击模型的评估指标(参见表10)。

表10 成员推理攻击评估指标Table 10 Evaluation metrics of Membership inference attacks
5.1.1 目标模型的评估指标
1) 准确率(model-side accuracy): 是指预测正确的样本占所有样本的比例;
2) 泛化误差(generalization errors): 目标模型训练准确率和测试准确率之间的差, 反映目标模型的过拟合程度; 泛化误差越大, 目标模型的过拟合程度越高。
5.1.2 攻击模型的评估指标
1) 攻击准确率(attacker-side accuracy)是指: 攻击模型预测正确的样本占所有样本的比例;
2) 攻击精确率(attacker-side precision)是指: 在预测为正例的样本中, 攻击模型预测正确的正例占所有预测为正例的比重;
3) 攻击召回率(attacker-side recall)是指: 攻模型预测正确的正例占所有真实正例的比例;
4) 攻击f1分数(attacker-side f1-score): 是指攻击精确率和召回率的调和平均数;
5) 攻击假阳率(attacker-side false positive rate,FPR)是指: 攻击模型预测错误的反例占所有反例的比例;
6) 成员优势(attacker-side membership advantage)是指: 攻击模型的召回率和假阳率之间的差, 其反应攻击模型预测一个样本是成员的优势;
7) AUC面积: 是ROC曲线下的面积, ROC曲线是指横轴是FPR, 纵轴是TPR(recall), 且ROC曲线越靠近左上方分类模型性能越好; AUC面大, 攻击模型性能越好;
8) 沙普利值(shapley values, SV)是指: 当一个样本“在”与“不在”训练数据子集中时, 目标模型的预测准确率的平均变化率;
9) 难度校准分数(calibrated score)是指: 目标模型对某个样本的成员分数(模型对数据样本的损失)与影子模型对该样本的成员分数的差值;
10) 隐私风险分数(privacy risk scores)是指: 攻击者在观察了目标模型对一个样本的表现后, 判断其来自于训练集的后验概率;
11) 正例预测值(positive predictive value, PPV)是指: 当给一个样本添加噪声后模型的预测损失变小的比例, 以及目标模型对单个样本损失的下界阈值和上界阈值, 当一个样本添加噪声后同时满足三个阈值要求时, 攻击者认为样本是成员, 否则是非成员;
12) 基于蒸馏的损失阈值(distillation-based loss threshold)是指: 攻击者将模型在蒸馏的数据集上进行训练, 并根据不同模型和的数据集设定一个在可忍受假阳率范围内的阈值, 当某个样本的损失阈值大于该设定的可忍受假阳率阈值时, 认为该样本是成员, 否则是非成员;
13) 低假阳率下的真阳率机制(a true-positive rate at low false-positive rates metric)是指: 攻击者在对数尺度上绘制ROC曲线, 并报告一个固定的低假阳率下的真阳率的大小;
14) Log损失值(log loss value)是指: 攻击者首先定义log损失值, 再根据训练集中的数据样本的邻居个数选择易受攻击样本, 计算一个样本对另一个样本的影响分数以及增强样本, 当这些易受攻击样本的模型损失大于该log损失值时, 认为该易受攻击样本是成员, 否则是非成员。
5.2 数据集
本小节, 我们将MIAs数据集划分为图片数据、文本数据、图数据以及二元数据(参见表11), 其主要被用于分类、生成新数据、分类和生成、以及语义分割等任务。
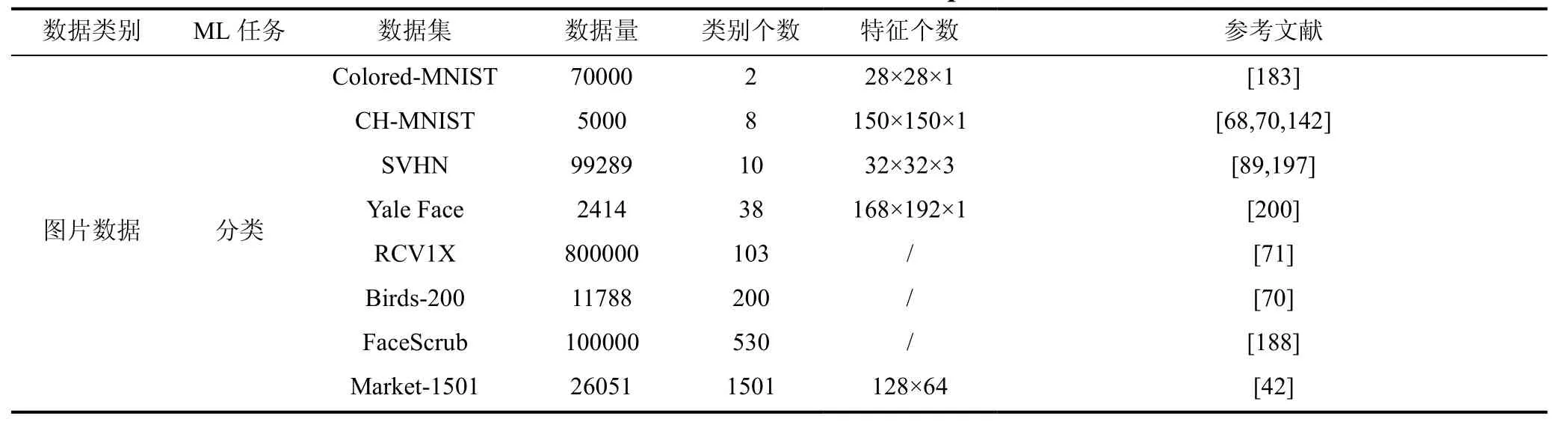
表11 成员推理攻击和防御中所使用的数据集Table 11 Datasets used in Membership inference attacks
6 成员推理的应用
成员推理攻击不仅可以推测数据隐私, 而且在现实中也有一些应用。
6.1 隐私审计
已有一些开源工具[38]和机器学习图书馆[37]利用成员推理攻击进行ML模型隐私评估。Song等人[35]设计了一个针对文本生成模型的隐私审计模型, 评估某个文本是否被未授权使用。Ye等人[36]基于假设检验提出一种新的成员推理攻击方法, 可被用作模型隐私审计和评估的一种工具。Miao等人[158]提出一个语音审计模型, 可推测用户的语音数据是否被非法训练和使用。

续表

续表
6.2 知识产权保护
文献[165]利用基于影子模型的成员推理攻击方法[12]筛选成员样本, 并任意选择20%成员样本嵌入目标模型中, 实现目标模型的版权保护。成员推理技术还被用于系统发布前的隐私质量评估, 判断模型是否具备发布标准, 以及监管部门对用户个人隐私的非法滥用、对用户位置[46,170]和信用进行监测。
6.3 疾病预测
成员推理在医疗领域[166-167]也得到了广泛应用,比如推测某个基因是否在基因库中, 或某人是否患有某种疾病。
7 主要挑战和未来研究方向
本小节, 我们将讨论成员推理攻击和防御的主要挑战和潜在研究方向, 为该领域的研究者提供一些建议(参见表12)。

表12 成员推理攻击防御主要挑战和未来研究方向Table 12 Main challenges and future research directions of membership inference attacks
7.1 成员推理攻击的主要挑战和研究方向
7.1.1 研究全面高效的成员推理攻击方案
目前, 几乎所有研究主要关注成员样本的预测和评估, 很少涉及非成员样本的检测。而现实的成员推理任务中, 大部分都是非成员样本, 且攻击者对其需要评估的样本一无所知, 此时已有的攻击无法准确评估成员和非成员。此外, 成员评估的 f1 分数和召回率几乎在大部分情况下都很高, 而精确率有时很低,进一步增加了攻击者区分的难度, 甚至误导攻击者得出错误结论。因此, 如何全面有效评估现实中的成员和非成员是成员推理攻击面临的一大挑战, 研究全面高效成员推理攻击方案是一个亟待解决的问题。
7.1.2 研究针对非过拟合模型的高效攻击方法
已有研究表明成员推攻击在过拟合模型中取得了巨大的成功, 但现实生活中攻击者由于拥有的背景知识有限, 其很难确定一个模型是否过拟合。同时,随着软硬件技术的飞速发展和革新、易获得的的海量数据, 会不断提升训练模型的质量, 进一步降低其过拟合的风险。因此, 已有的针对过拟合模型的成员推理攻击是否对非过拟合模型也有效还有待进一步探索和研究, 需要研究针对非过拟合模型的高效攻击方法。
7.1.3 研究其他模型和领域的成员推理攻击方法
机器学习中的众多模型和领域已遭受成员推理攻击, 如分类模型、生成模型等。但对一些新兴模型和领域(如自监督学习、元学习、同质联邦学习等)的成员推理攻击研究较少; 而这些模型在机器学习中扮演着越来越重要的角色, 探索和研究针对这些模型和领域的成员推理攻击方案, 将有助于对其进行更好的隐私防御, 从而推动机器学习的蓬勃发展。
7.1.4 研究成员推理攻击的其他用途
已有成员推理攻击主要研究如何提高攻击成功率, 也有少部分文献研究利用成员推理攻击方法进行模型隐私安全审计等任务。但已有应用只涉及机器学习很小的范围, 也处于刚起步阶段, 还需进一步完善。因此, 成员推理攻击在机器学习其他任务上的用途仍需探索和研究。比如, 联邦学习中如何准确确定某个参与者的身份, 如何根据成员信息研究有效的机器去学习方案等等。
7.2 成员推理防御的主要挑战和研究方向
7.2.1 研究优化高效的成员推理攻击防御方案
已有的成员推理防御方案虽已取得一定的防御效果, 但是机器学习场景繁多、模型多样, 其很难防御所有场景和模型中的成员推理攻击。因此, 需结合密码学、对抗训练等知识对已有防御方法进行优化和改进, 并探索和研究新的鲁棒性更强的成员推理攻击方案。
7.2.2 研究隐私可用性平衡的成员推理防御方案
差分隐私成员推理防御方案虽具有一定的理论保障, 但其会破坏模型可用性; 而其他防御方法不具有理论保障, 也很难兼顾隐私和模型效用。因此,需要研究和设计一个隐私-可用性平衡的成员推理攻击防御方案。
7.2.3 研究针对其他模型的成员推理防御方案
目前, 成员推理防御方案主要针对分类模型,但是对其他模型(如生成模型等)的成员推理防御方案还很少。同时, 对于无监督模型来说, 很难评估其是否过拟合。因此, 如何判断一个模型的过拟合程度,并设计有效的成员推理防方案是未来的研究方向。
7.2.4 研究不同设置下成员推理防御方案
目前, 大部分成员推理攻击和防御方案主要针对整个数据集的所有样本, 但很少研究不同设置下成员推理方案的有效性, 而现实中类别个数、特征分布不均衡的现象(如长尾现象)很常见, 探究不同设置对成员推理攻击的影响, 以及如何提出针对不同设置的成员推理防御方案, 仍是一个开放和值得研究的问题。
8 总结
本文首先介绍了机器学习在实现人工智能时取得的巨大成功, 以及面临的隐私安全威胁, 尤其是成员推理攻击; 其次, 介绍了成员推理攻击的定义和威胁模型, 并从攻击场景、背景知识、目标模型、攻击原理、攻击领域、攻击数据集大小等方面对成员推理攻击进行全面细致的分类和归纳; 然后, 从目标模型的训练数据、模型类型、过拟合程度分析成员推理攻击存在的原因; 随后, 从差分隐私、正则化、数据增强、模型堆叠、早停、信任分数掩蔽和知识蒸馏这七个方面对现有成员推理攻击防御措施进行分析和比较。接着, 总结了成员推理攻击和防御的评估指标、数据集, 以及其在现实中的应用; 最后,分析讨论了其面临的隐私威胁和挑战, 并给出未来研究方向, 进一步推动该领域繁荣发展。
