基于残差密集网络的红外与可见光图像配准*
2022-12-16罗银辉王星怡吴岳洲
罗银辉,王星怡,吴岳洲
(中国民用航空飞行学院计算机学院,四川 广汉 618307)
0 引言
图像配准是一项将不同的图像变换到同一坐标系下并产生相应变换矩阵的技术,也是实现图像融合、图像拼接以及目标检测的基础[1]。随着配准技术的快速发展,以及红外图像和可见光图像能提供互补信息的特性,红外与可见光图像的配准技术越来越引起研究人员的关注,但它们的配准难度较大。
现有的红外与可见光图像配准方法主要是基于区域、基于特征和基于神经网络的方法。基于区域的方法通过寻找两个图像对间的最小距离来达到配准的效果,但这类算法普遍对灰度敏感[2]。文献[3]利用带窗口灰度权重算法(GWW)实现了更高的匹配精度和匹配效率。文献[4]提出了一种基于显著性梯度的归一化互信息算法,并拥有更高的收敛性和配准率。基于特征的方法通过建立可靠的特征匹配来解决图像对间的尺度差异,但这类算法对图像质量要求较高且难以提取共有特征点[5]。文献[6]在轮廓图像中检测图像角点,将其作为特征点,实现了高精度的图像配准。文献[7]通过改进SIFT 梯度定义,来克服图像灰度,提高了配准精度。基于神经网络的方法通常采用端到端的网络实现图像配准,这是最近较为新颖的方向。文献[8]通过学习模态不变特征来实现图像配准,提升了配准精度。
本文针对难以提取红外与可见光图像相似特征的问题,以及受文献[9]提出的无监督深度单应性方法的启发,提出了一种基于残差密集网络的红外与可见光图像配准方法。本文通过引入残差密集网络(residual densenetwork,RDN)[10]来自适应提取深层特征和浅层特征,从而获得足够多的有效特征并实现较高精度的图像配准。
1 方法设计
1.1 网络框架
基于残差密集网络的红外与可见光图像配准方法的网络框架如图1 所示。首先,灰度图像对Ia和Ib分别通过特征提取网络(FEN)和掩码预测网络(MPN)来产生对应的特征映射和掩码。然后,分别将对应的特征映射和掩码相乘,得到加权特征映射Ga和Gb,并将其通道级联产生Ga,b。最后将Ga,b送入到由ResNet-34 组成的单应性网络中,得到两个灰度图像对的偏移矩阵H,进而产生变换矩阵来实现配准。
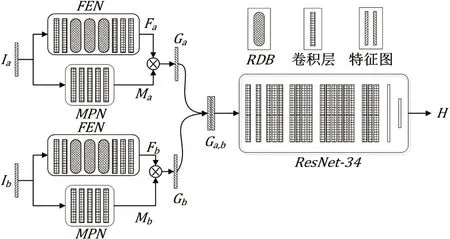
图1 网络框架
1.1.1 特征提取网络FEN
由于特征提取的好坏严重影响预测图像的质量,而红外图像和可见光图像的巨大成像差异也为配准工作带来了巨大挑战,因此本文构建了特征提取网络(feature extraction network,FEN)来提取图像对的多层次特征。FEN 是基于残差密集网络来进行构建的,分别从局部和全局两个角度来提取特征,并通过融合将浅层特征和深层特征结合到一起,从而,自适应地学习更有效的特征,其网络框架如图2所示。

图2 特征提取网络框架
首先,源图像Ik(k=a,b)经过两个卷积层,分别得到浅层特征F-1和F0,然后通过三个残差密集块(residual dense block,RDB)提取密集特征,其计算公式如下:
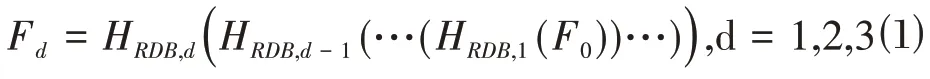
其中,HRDB,d(·)表示第d 个RDB 的运算;Fd表示第d 个RDB提取的密集特征。
其次,对三个RDB 的局部密集特征进行融合,得到多层次局部密集特征FGF,其计算公式如下:

其中,HGFF()· 表示对三个RDB 的融合运算,其中它由1×1和3×3卷积块组成。
最后,利用全局残差学习来提取特征,从而得到稠密的特征映射,并通过一个卷积层来得到单通道特征映射Fk,其计算公式如下:

其中,ω表示卷积层的权值;σ表示ReLU 激活函数。为了简单起见,这里省略了偏置项。
1.1.2 掩码预测网络MPN
为了突出显示特征映射中的重要特征,构建了掩码预测网络(mask prediction network,MPN)来细化特征。MPN是基于全卷积神经网络(fully convolutional network,FCN)[11]来进行构建的,它所产生的掩码对特征映射进一步加权,从而产生加权特征映射,其计算公式如下:

其中,Mk表示MPN所产生的掩码。
1.1.3 单应性网络
单应性网络是使用ResNet-34 网络架构来进行构建的,它将通道级联后的特征映射Ga,b作为整个网络的输入,从而得到红外图像与可见光图像之间的偏移矩阵H,该矩阵是由八个值所组成的。然后通过直接线性变换(direct linear transformation,DLT)[12]将偏移矩阵H变换为变换矩阵Hab,用于源图像的变换,从而达到图像配准的效果。
1.2 损失函数
本文选取Triplet Loss[9]作为网络的损失函数,它根据学习到的深度特征来计算损失,而不像传统损失函数那样直接比较图像内容,这样将有助于网络进行更好的优化,其计算公式如下:

其中,Ia和Ib分别表示红外与可见光图像的灰度图;Hab表示将Ia变换到Ib的同一视角下的变换矩阵,Hba亦同理;和分别表示使用对应灰度图与变换矩阵相乘后得到的扭曲图像;I表示三阶单位矩阵;λ和μ表示超参数,且λ=2.0,μ=0.01。
2 数据集与评价指标
2.1 数据集
2.1.1 训练集与测试集
为了验证本文方法的有效性,从OTCVBS、INO和TNO 等公开数据集中分别选取115 张和42 张图像对用作训练集和测试集。
2.1.2 数据集预处理
首先,训练集的数据量较少,因此采用数据增广的方法来增加数据量。其次,使用文献[13]中的数据集制作方法来生成未配准的红外和可见光图像对。同时,在原红外图像中选取与未配准图像块具有相同角点位置的图像块,以生成已配准的红外图像IGT,并用于评价指标计算,从而减少红外图像和可见光图像本身差异所带来的误差,每幅图像的像素为128×128。最后,对未配准的红外和可见光图像对进行标准化和灰度化,以获得整个网络的输入图像对Ia和Ib。
2.2 评价指标
为了评估所提方法的配准效果,本文选取结构相似性(structural similarity,SSIM)[14]、平均角点误差(average corner error,ACE)[15]和互信息量(mutual information,MI)[16]作为本文的评价指标。取x和y分别为预测红外图像和已配准红外图像,并以此来计算评价指标。
SSIM 值越大,表示图像配准效果越好,计算公式如下:

其中,μx和μy分别表示图像x和y中所有像素的均值;σx和σy分别表示图像x和y的标准差;σxy表示两个图像的协方差;c1和c2表示维持稳定的常数。
ACE 是指预测红外图像与已配准红外图像的四对顶点坐标的均方误差,值越小表示配准精度越高,其计算公式如下:

其中,xij和yij分别表示预测红外图像和已配准红外图像四对顶点的某一坐标;n表示测试集中共有的图像对总数。
MI 值越大,表示图像配准效果越好,其计算公式如下:
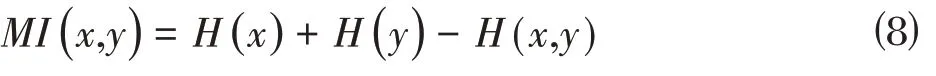
其中,H(·)和H(x,y)分别表示熵和联合熵的计算函数。
3 实验结果与分析
3.1 实验环境与参数设置
本文实验在Windows10 操作系统上进行的,CPU 为Intel i9-10980XE,GPU为NVIDIA GeForce RTX 3090,采用的深度学习框架是Pytorch。在训练过程中,本文使用Adam 作为网络优化器,初始学习率设置为0.00001,batch_size 设置为24,epoch 设置为50,其中每迭代一个epoch,学习率下降0.8。
3.2 主观评价
本文在三组场景上对CAU-DHE[9]和本文方法进行了对比测试,其配准结果如图3所示,其中配准结果是由预测红外图像的蓝色通道和绿色通道与已配准红外图像的红色通道进行融合所得的,同时对局部区域进行放大以便观察配准细节,若出现重影则表示此处未配准。由图3 可知,本文方法的配准效果略好于CAU-DHE。首先CAU-DHE 的第一组配准图像边缘出现了黑边,而本文方法却可以实现全景对准。其次本文方法的细节处对准效果也略优于CAU-DHE。

图3 图像配准结果
3.3 客观评价
为了定量验证本文方法的优势,与CAU-DHE 在42 组测试图像对上进行了对比测试,评估结果如表1所示。由表1可知,本文方法在SSIM、ACE 和MI等评价指标上比CAU-DHE 分别提升了0.4%、21.5%和1.4%。提升的主要原因是使用了更为优异的特征提取网络来提取红外图像与可见光图像的多层次特征,并得到更优异的配准图像,但也是由于这一原因,耗时也多花了0.143s。
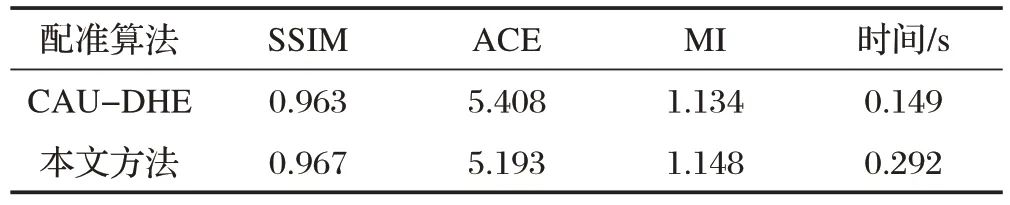
表1 配准算法评估结果
4 结束语
针对现有图像配准方法难以提取红外与可见光图像有效特征的问题,本文提出了一种基于残差密集网络的红外与可见光图像配准方法。该方法通过引入残差密集网络来提取图像对的深层次特征,然后再通过掩码对特征进行加权,从而产生更精细的特征,最终实现了较高精度的配准。
