基于Flink的网络内容分析系统设计与实现*
2022-12-16赵佳欣石明翔白硕
赵佳欣,韩 钰,石明翔,李 硕,白硕
(北京城市学院信息学部,北京 100074)
0 引言
在新媒体时代,各式各样的网络内容呈现爆炸式增长的趋势,互联网的各类社交媒体平台已成为公众获取信息、表达观点的重要平台,人们表达观点的同时也增加了因网络舆情内容引发的各种事件。传统的网络分析系统是利用复杂、高成本的硬件结合人力来实现的,存在一定的局限性和不稳定性,已经不能满足实际需求。
随着我国科学技术不断发展进步,一些学者也曾尝试利用大数据技术解决网络舆情分析系统的海量数据实时处理需求,例如谌志华利用Hadoop技术进行数据处理,利用HDFS 进行数据存储。但是Hadoop 主要是面向静态数据的批处理,未能很好地解决复杂高速的实时处理和分析的问题[1]。因此,本文尝试利用大数据架构Kappa、实时计算框架Flink、数据存储Iceberg 及文本挖掘相关技术及算法,实现《基于Flink的网络内容分析系统》。通过本系统可更加精准快速地分析海量网络内容,帮助有关部门提高对网络内容的监管效率,达到对网络环境保护、净化的目的,从而维护社会的和谐安定。
1 系统架构及功能流程
本系统使用Kappa 架构[2]搭建,系统由应用服务层、数据计算层、数据存储层、数据清洗处理层和数据采集层构成,主要功能包括数据采集、数据清洗处理、文本挖掘、数据计算、数据多维分析及可视化展示,其系统架构如图1所示。
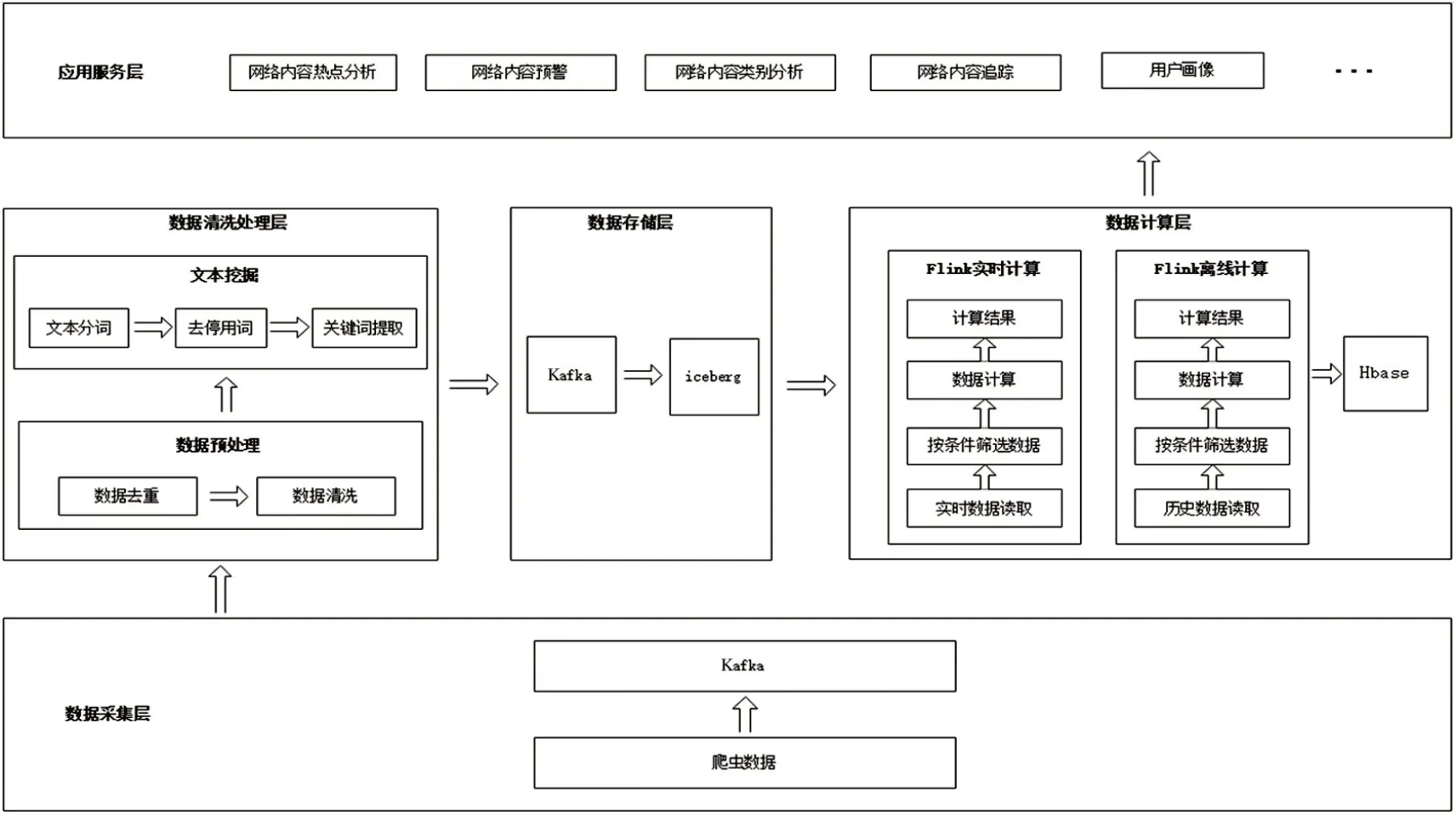
图1 系统架构
首先数据采集层会通过爬虫的方式获取数据并将其提供给Kafka,数据清洗处理层再按照顺序依次对数据进行数据去重、数据清洗,之后将完成预处理的数据执行文本分词、去停用词、关键词提取等文本挖掘流程,接着数据存储层通过消息队列Kafka 将数据保存至Iceberg,然后数据计算层利用Flink 并根据应用服务层实际需求进行实时计算和离线计算,离线计算的结果保存至Hbase。当应用服务层发送请求时,将实时和离线的计算结果分别发送至应用服务层。最后应用服务层将内容呈现给用户。
2 系统实现
2.1 数据采集层
数据采集层负责以微博网站为数据源采集数据,数据集包括100w条数据,数据项分别是网络内容的链接、热搜数、发布时间、转发数、评论数、点赞数及发布者ID、名称、关注数、粉丝数和历史发布内容相关信息等内容。
2.2 数据清洗处理层
数据清洗处理层是利用Flink 的在线流式处理。从Kafka 获取到网络爬虫数据后,首先进行数据预处理,然后通过创建前缀字典树构建有向无环图的方式再结合动态规划算法得到分词结果[3],经过停用词筛选后利用TF-IDF 算法抽取关键词,并将其输入到Kafka中。Flink清洗处理流程如图2所示。

图2 Flink清洗处理流程
当进行中文分词计算任务时,首先需要建立前缀字典树,它可根据字符串的公共前缀来减少查询时间,最大限度地减少字符串比较[4]。然后构造出有向无环图再依据n-gram 算法计算出最大概率路径进而得到最终的分词结果。在n-gram 算法中需计算出每句话的概率,设s 表示句子,由i 个词序列w1,w2,w3...wi组成,所以句子的概率可通过公式⑴来计算,但由于计算过于复杂,通常采用公式⑵的方式来计算
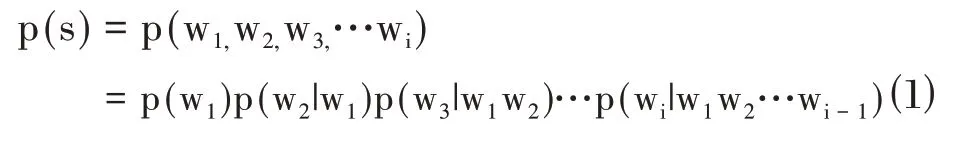

在利用TF-IDF 算法提取关键词的过程中,由于特定内容在篇幅长的文章里有更高的词频,为了防止偏向于篇幅长的网络内容,在计算时会将词频归一化[5]。可依据公式⑶、公式⑷、公式⑸来计算词频和逆文档频率,进而提取出关键词。其中tfd,t表示词语t 在语料库d 中出现的频率,nd,t表示词语t 在语料库d 中出现的次数,|D|代表语料库中文件总数,dft表示包含词语t的语料库个数。
TF计算公式:

IDF计算公式:

2.3 数据存储层
数据存储层负责按需向数据计算层提供数据。系统中拥有海量的数据,需要Kafka 作为消息队列进行消息的缓冲,保证系统的高效性及稳定性[6]。除此之外,系统还包含多种业务模块,数据湖Iceberg 作为保存数据的中间件,支持隐藏分区和分区进化的特性,便于数据写入和业务数据分区策略更新。Flink 数据写入Iceberg流程如图3所示。

图3 Flink数据写入Iceberg流程
Iceberg 拥有ACID 的能力可以降低数据入库到处理流程的延迟问题。它支持流任务和批任务使用相同的存储模型,可更好实现Flink流批一体的特性。在数据计算层执行实时计算任务时,Iceberg 还支持流式读取增量数据,可快速读取到上游数据,保证当前任务的正常运行[7]。Flink 查询Iceberg 数据流程如图4所示。
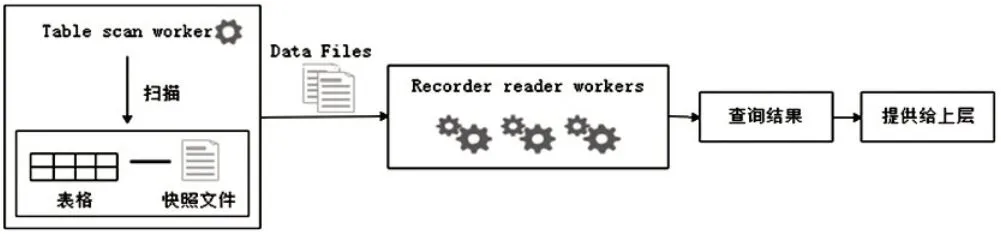
图4 Flink查询Iceberg数据流程
2.4 数据计算层
数据计算层负责将数据从Iceberg 中抽取,然后进行数据分析计算,将得出的结果提供给应用服务接口。该层采用Flink进行高吞吐低延迟的计算,因其具有很好的抗压能力[8]。当网络爬虫的数据不断输送到消息队列中时,Flink 可按顺序消费数据。由于Flink流批一体的特性,在具体实现时能做到精准快速地完成任务。本层的计算内容包括热点计算、追踪计算、类别计算、趋势计算及用户画像计算。在进行数据计算时,分为实时的流处理计算和离线的批处理计算。实时流式计算负责统计本日的数据,离线批式计算负责统计本日之前的所有历史数据,最后,将两组计算结果汇总,返回给应用服务层[9]。具体每部分的Flink算子设计和计算流程如图5所示。
2.5 应用服务层
应用层是系统前端部分,负责与用户进行直接交互,可将用户的请求发送至应用服务接口,待其处理后返回相应结果并展示。该层包括网络内容的热点分析、趋势分析、类别分析、追踪分析和用户画像等功能。
3 实验与分析
为了验证系统的执行效率,本文集群环境采用3台虚拟机,一个为主节点Master,两个子节点Slave1、Slave2,虚拟机硬件配置均为16G 内存和512G 硬盘,使用的操作系统为Centos7 64 位。在实验中,利用搭建好的集群处理不同量级的数据,并将其执行效率与Hadoop、Spark 执行效果进行对比,不同平台执行效率如图6所示。

图6 平台执行效率
实验结果表明,在处理低量级数据时Hadoop平台、Spark 平台和Flink 平台的执行效率没有明显的差别。但随着数据量的增加,不同平台的执行效率逐渐有了显著差异。Hadoop平台和Spark平台的响应时间大幅增加导致执行效率变低[10],而Flink 平台在处理大量数据时仍能做出快速响应。实验结果证明本系统的执行效率随着数据量的增大,依然能做到快速响应,表现出系统良好的执行效率。
4 结束语
本文依托于大数据架构Kappa,利用实时计算框架Flink、数据存储Iceberg、消息队列Kafka 及文本挖掘相关算法包括n-gram算法和TF-IDF算法,实现《基于Flink 的网络内容分析系统》,用于对网络内容进行实时分析。在系统实现过程中,本文重点解决了实时数据处理、Flink 流批一体任务执行、实时分析网络内容等技术难题,并通过实验结果的对比分析证明了系统无论是在运行效率还是可扩展性上都有着良好的表现。
