在线虚假评论识别中的数据贫乏问题研究
2022-12-15唐子旭秦广杰
张 文, 王 强, 唐子旭, 秦广杰, 李 健
(1.北京工业大学 经济与管理学院,中国 北京 100124; 2.山东浪潮新基建科技有限公司,山东 济南 250011)
0 引言
随着电子商务的飞速发展和在线评论数量的增长,大量的虚假评论充斥在网络环境中[1]。在线虚假评论是由商家招募评论者发布的欺骗性信息,其目的是借助在线虚假评论提高自身产品销量或打压竞争对手[2]。对于品质低的商品,正面的虚假评论可以提升商家自身口碑和商品销量,对于其他竞争对手的高品质商品,负面的虚假评论可以诋毁竞争对手,损害其声誉[3]。由于消费者无法从内容上辨别虚假评论,虚假评论的误导信息在很大程度上影响着消费者的购买决策[4]。因此,虚假评论的准确识别对于维护消费者的权益、维持电子商务交易市场的正常秩序意义重大,越来越多的学者开展对虚假评论识别的研究[5~8]。
Kumar等人提出一种无监督方法来检测在线评论中的异常行为。他们通过定义评论者行为的主要特征分布,并将这些特征分布组合成一个混合学习模型来自动识别虚假评论者[5]。Zhang等人利用深度神经网络,借助真实评论和虚假评论中的特征词向量识别虚假评论[6]。Ott等人采用人工标注的方法辨别虚假评论,结果表明人工标注对于虚假评论的识别率很低。为此,他们收集了首个在线好评数据集,其中包括芝加哥20个酒店的400条虚假好评和400条真实好评数据,这为后续虚假评论识别的相关研究提供了良好的数据集基础[7]。此后,Ott等人分别利用亚马逊提供的众包服务平台和网络爬虫方法收集了400条虚假差评和400条真实差评,基于在线好评数据集的基础上,构建了在虚假评论识别领域的1600条标准数据集[8]。随后他们用相同的模型和方法对虚假评论进行识别,结果表明使用包含虚假差评的数据集训练出的分类器能够更好地识别虚假评论。并且在扩充数据集后,机器学习模型对虚假评论识别效果显著提高。
机器学习相关技术的发展提升了在线虚假评论识别的准确率,然而现阶段机器学习模型缺少足够多的已标注数据来进行模型训练。就虚假评论而言,人工标注评论数据需要耗费大量的人力和时间成本,同时人工标注的评论数据也不具备可靠性。现阶段的研究还未真正解决虚假评论识别中模型训练数据贫乏的问题。为此,本文基于生成对抗网络(GAN, Generative Adversarial Networks)[9]提出评论数据集扩充方法GAN-RDE(GAN-Review Dataset Expansion),对有限已标注的评论数据集在机器学习过程中加以利用,通过生成器(Generative)学习已标注评论数据的分布特征生成符合评论数据特征分布的向量,以此来扩充模型训练数据,提升虚假评论识别的效率。GAN最大的特点在于引入了对抗机制,判别器(Discriminative)辨别来自训练集的真实数据与生成器的生成数据,生成器学习如何模拟产生更加接近数据集样本分布特征的数据,这种对抗机制使生成器生成的样本与初始评论数据极为相似,而判别器的辨别能力同时也得到了提高。此外,相较于传统机器学习方法,GAN能够将非监督学习转化为监督学习,使得其在非监督学习和半监督学习领域可以发挥更大的作用[10]。当训练数据较少时,生成器可以通过输入的噪点来生成多样化的“真实”数据,生成器生成的数据与训练集数据会在GAN训练过程中最终达到高度相似。因此GAN能够通过生成器生成的数据扩充初始评论数据集,解决虚假评论识别中模型训练数据贫乏的问题,在虚假评论识别研究中引入GAN具有现实意义。
1 相关工作
1.1 支持向量机
支持向量机(SVM, Support Vector Machine)是机器学习算法中最为流行的监督学习模型之一,在给定样本信息情况下可以做线性和非线性的分类和回归分析。对于分类问题,SVM是一种基于统计学习理论的分类方法,它将向量映射到一个高维空间并在这个空间建立分割两类数据的超平面,在寻求最大间隔超平面的同时获取更佳的泛化能力[11]。在虚假评论识别的研究中SVM作为基础分类器得到了广泛应用。例如,Zhang等人利用SVM作为基础分类器,借助评论的文本词汇和评论的深度语法规则识别虚假评论[12]。Kumar等人在虚假评论者检测的研究中也使用SVM作为基础分类器对比不同算法的识别性能[5]。由于SVM特别适合于数据维度大但数据集较小的分类问题,因此本文在虚假评论识别问题上也采用了这种算法。
1.2 多层感知机
多层感知机(MLP, Multi-Layer Perceptron)是一类至少具有三层的前馈人工神经网络(ANN, Artificial Neural Network)[13]。每一层由一个或多个平行的人工神经元组成,每个神经元具有N个加权输入,并参考阈值和激活函数来确定其输出。相比于传统神经网络,MLP在输入层和输出层中间添加了多个隐藏层。在输入层、隐藏层和输出层之间,MLP实现上一层的任何一个神经元与下一层的所有神经元全连接。因此,MLP增加了模型的表达能力,提升了分类的准确率。MLP被广泛应用在虚假评论识别的研究中,Bhargava等人综合分析和比较了不同层数和不同输出维数的深度网络模型在虚假评论识别中的效果,并总结MLP在虚假评论识别中的优势[14]。鉴于MLP在分类问题中具有非常强的自适应和自学习能力,本文在虚假评论识别问题上选择多层感知机作为基础分类器。
1.3 生成式对抗网络
生成式对抗网络是一种新兴的训练生成模型框架,是判别器网络和生成器网络相互竞争和抗衡的特殊过程,其基本思想来源于对策论中的非合作博弈均衡[9]。其中,生成器网络负责学习数据集中样本的数字分布特征并尝试生成真实样本,判别器网络接收来自实际数据集的真实数据和来自生成器网络创造出来的生成数据。在未明确数据来源的情况下,需要自动区分真实数据与生成器生成的数据,并判断这些数据为真实数据的概率。因此一个GAN网络由生成器G和判别器D两部分组成,生成器G从先验分布中采集随机噪声作为输入,通过网络学习数据集数据特征并试图生成真实样本数据。判别器D的数据来源是生成器G生成的数据和数据集样本中的真实数据两种数据源融合后的数据,它需要判断当前输入是来自训练集还是由生成器生成,最终输出判断结果并反馈给生成器。生成器G与判别器D的相互作用如图1所示:

图1 生成式对抗网络结构图
在生成式对抗网络中,生成器G不断学习训练集中真实数据的概率分布,从随机分布pz(x)中接收噪声z作为输入,并尝试将其转化为可以以假乱真的样本数据。判别器D以真实样本数据以及来自生成器G的生成数据作为输入,其作用是对两种数据进行辨别区分,并将判别结果反馈给生成器G进行学习。其中判别器的输入包括真实数据的分布和生成数据的分布,并反馈判断结果让生成器G学习,从而让两个网络同时训练。
2 基于GAN的评论数据集扩充
2.1 评论数据集扩充的整体流程与框架
本文基于生成式对抗网络提出评论数据集扩充方法GAN-RDE解决虚假评论识别中模型训练数据贫乏问题。评论数据集扩充的整体框架如图2所示。首先,对评论数据进行预处理。去除评论数据集中的停用词,并删除评论文本中的表情字符、多余的空格字符、没有实际意义的数字和字母,以提升评论文本质量。将初始评论数据划分为真实评论数据集和虚假评论数据集,并使用特征提取模型对初始评论数据集进行文本特征提取。其次,本文设计了用于扩充评论数据集的GAN,包括对生成器和判别器的训练。在训练GAN时,生成器输入与训练样本相同数量的随机噪声,并将输出结果和来自训练集的真实数据作为判别器的输入,让判别器通过相应标签和损失函数计算误差以进行模型训练。通过交替冻结生成器与判别器的网络参数,用生成器生成的数据与训练集中的真实数据一起输入到判别器当中,让判别器进行网络参数的更新,再从判别器网络输出的误差反馈给生成器以更新其参数权重,反复循环让两个网络相互学习以此来达到平衡。

图2 评论数据集扩充的整体框架
具体而言,本文首先将初始评论数据集的特征词词向量矩阵作为训练好的GAN模型的输入,分别生成真实评论和虚假评论的特征词词向量矩阵。然后,本文将GAN生成的真实评论与虚假评论特征词词向量矩阵与初始评论数据集的特征词词向量矩阵合并,得到扩充数据集的特征词词向量矩阵,以实现对真实评论和虚假评论数据集的扩充。最后,本文使用扩充评论数据集进行虚假评论的识别。本文以朴素贝叶斯、多层感知机和支持向量机作为基础分类器,使用扩充数据集后的特征词词向量矩阵训练基础分类器,验证数据扩后虚假评论识别的效果。同时,本文也对比多种虚假评论分类识别方法在评论数据集扩充前后的虚假评论识别效果,验证评论数据集扩充方法GAN-RDE对在线虚假评论识别中数据贫乏问题的解决能力。
2.2 基于GAN的评论数据集扩充
为解决虚假评论识别模型中训练集数据贫乏的问题,本文考虑通过GAN生成符合真实评论与虚假评论特征分布的向量来扩充数据集,并提出基于GAN的评论数据集扩充方法GAN-RDE,以此提升虚假评论识别的准确率。基于GAN的评论数据集扩充过程如图3所示。
使用两种特征提取模型N-gram[15]和TF-IDF[16]对800条真实评论数据集Rt(包括400条真实好评和400条真实差评)和800条虚假评论数据集Rd(包括400条虚假好评和400条虚假差评)进行文本特征提取,选择其中表现相对较好的特征提取模型得到的结果作为生成式对抗网络训练的输入数据,即真实评论数据集Rt的特征词词向量矩阵ET=[ew1,ew2,…,ewi]和虚假评论数据集Rd的特征词词向量矩阵ED=[ew1,ew2,…,ewj]。将真实评论数据集Rt的特征词词向量矩阵ET和虚假评论数据集Rd的特征词词向量矩阵ED作为生成式对抗网络的输入分别训练GAN。

图3 GAN-RDE过程
GAN训练完成后,输出真实评论的特征词词向量矩阵EGT=[et1,et2,…,etm]和虚假评论的特征词词向量矩阵EGD=[ed1,ed2,…,edm]。对1600条评论数据集R(包括400条真实好评、400条真实差评、400条虚假好评和400条虚假差评)进行文本特征提取,得到评论数据集R的特征词词向量矩阵ER=[ew1,ew2,…,ewj]。然后将GAN生成的特征词词向量矩阵EG(包括EGT和EGD)与评论数据集R的特征词词向量矩阵ER合并,得到扩充数据集R′的特征词词向量矩阵E=[ew1,…,ewi,…,ewj,et1,…,etm,ed1,…,edn]。最后使用扩充数据集R′训练分类器,借助机器学习中的4个评价指标:准确率(A, Accuracy),精准率(P, Precision)、召回率(R, Recall)、F-度量值(F-Measure),对比GAN-RDE方法扩充评论数据集前后虚假评论的识别效果,判断GAN是否能够用于评论数据集的扩充,并提升虚假评论识别的准确率。
3 实验验证
3.1 数据集
MyleOtt等人[7]在2011年收集了首个好评的标准数据集,其中包括美国芝加哥20个酒店的400条真实好评数据Rt1和400条虚假好评Rd1。在此基础上,他们又在2013年收集了差评的标准数据集,其中包括了400条真实差评Rt2和400条虚假差评数据Rd2[8]。400条真实好评数据Rt1和400条真实差评Rt2构成了真实评论数据集Rt,400条虚假好评Rd1和400条虚假差评数据Rd2构成了虚假评论数据集Rd。这1600条评论数据构成本文机器学习的训练与测试实验数据集R,其中评论数据集扩充实验是基于数据集Rt和Rd。
3.1.1 评论数据的预处理
本文使用NLTK库去除评论数据集中的停用词,由于停用词如“the”、“am”、“a”、“is”、“at”等没有什么实际含义,不会给出任何有助于数据模型的信息,因此需要从评论当中去除这些词。在使用模型进行特征提取时,使用N-gram和TF-IDF两种特征提取模型得到的数字特征维度都比较大,而对于深度神经网络意味着训练难度的提升。因此实验中使用特征选择方法进行降维,以便于GAN训练的实验。数字特征进行降维后会有信息损失,但不影响本文提升模型准确率的研究内容。降维后TF-IDF模型维度为500,N-gram模型提取的特征维度为2000。
3.1.2 特征提取模型
TF-IDF和N-gram模型中得到的向量维度和特征的差异会导致分类效果的不同,本文使用SVM权衡两种特征提取模型之间的选择。将实验数据集数据划分为5个fold,其中4个fold数据集子集作为训练集训练SVM模型,1个fold数据集子集作为验证集用于模型验证,利用验证集计算模型的性能指标,如准确率。使用网格搜索寻求模型的最优调参,模型在数据集上拟合时,将模型的各个参数设置在一定的区间,参数值所有可能的组合都会被评估,从而计算出最佳的组合。
对于测试集400条数据,使用N-gram模型提取训练数据集特征训练SVM时,SVM将400条测试集数据中的179条评论识别为虚假评论,221条评论识别为真实评论。使用TF-IDF模型提取训练数据集特征时,SVM将400条测试集数据中的210条评论识别为虚假评论,190条评论识别为真实评论。SVM虚假评论识别结果表明,使用两种不同的特征提取模型的SVM对虚假评论识别的结果相差不大,SVM虚假评论识别的准确率都为0.86,但由于N-gram得到的向量维度很高,会使得深度学习中网络变大从而增加训练难度,因此选用维度相对较低的TF-IDF作为实验中的特征提取模型,将TF-IDF提取到的特征向量作为生成式对抗网络的输入。
3.2 实验结果
理论上由于初始评论数据数量较少会导致基准分类器对虚假评论识别的准确率不高,在使用真实评论数据集Rt和虚假评论数据集Rd完成GAN训练的基础上,生成器G可以很好的捕捉评论的分布特征来生成符合真实与虚假评论特征分布的向量,以此来扩充训练集数据量,提高基准分类器对虚假评论识别的准确率。这是一种数据增强的方法,将原始数据用于训练GAN,然后根据训练得到的GAN模型生成扩充数据用于基准分类器的训练。在实验中训练好的GAN生成器G生成一些符合真实与虚假评论特征分布的向量,使用这些向量来扩充初始评论数据集R。使用GAN-RDE方法扩充数据前后基准分类器的虚假评论识别结果对比如表1所示。

表1 GAN-RDE方法扩充数据前后基准分类器的虚假评论识别结果对比
GAN-RDE方法扩充数据后,Naïve Bayes对虚假评论识别准确率均由75%提升到87%,其余各评价指标也均有提高。MLP和SVM对虚假评论识别准确率均由86%提高到了91%。相比于未扩充数据前的虚假评论识别结果,GAN-RDE方法扩充数据后,MLP的召回率和F1值均提高了14%;SVM召回率和F1值分别提高了11%和6%。相比于未扩充数据前的真实评论识别结果,GAN-RDE方法扩充数据后的MLP识别精确率、召回率和F1值分别提高了17%、8%和8%;SVM识别精确率和F1值分别提高了12%和2%。

图4 GAN-RDE前后虚假评论识别方法在不同训练比例上的准确率
为验证本文提出的评论数据集扩充方法GAN-RDE对在线虚假评论识别中数据贫乏问题的解决性能,本文将在机器学习领域被广泛使用的分类器朴素贝叶斯(Naïve Bayes)[7],基于深度学习的虚假评论识别方法多层感知机MLP,以及机器学习算法中最为流行的监督学习模型支持向量机SVM纳入对比实验,观察使用GAN-RDE方法前后虚假评论识别结果的差异。图4显示了使用评论数据集扩充方法GAN-RDE前后的朴素贝叶斯、多层感知机和支持向量机在不同训练比例上对虚假评论的识别结果对比。
从图4可以看出通过评论数据集扩充方法GAN-RDE扩充数据后,在不同训练比例上,朴素贝叶斯、多层感知机和支持向量机在虚假评论识别的准确率方面都有显著提升。结果表明训练完成的生成式对抗网络很好的学习到了初始评论集的特征分布,用GAN生成的向量可以扩充评论数据集并让数据得到增强,使得基准方法对虚假评论识别的效果得到提升。因此,本文提出的评论数据集扩充方法GAN-RDE能够很好的解决虚假评论识别中的数据贫乏问题,提升虚假评论识别的准确率。
3.3 参数敏感度分析
GAN的主要参数设置会改变GAN-RDE方法扩充评论数据集的结果,进而影响虚假评论识别准确率。本文使用穷举搜索的方式,探究GAN的主要参数设置对最终虚假评论识别准确率的影响。在GAN参数寻优的过程中,影响GAN训练效果以及GAN-RDE方法扩充评论数据集结果的参数主要为在线评论文本的特征维度(l)、生成器G的输入特征数量(dG)和判别器D的输入特征数量(dD)。本文在这三个参数寻优时借助穷举搜索的思想,在保持其他参数不变的情况下只改变某一参数的大小,进而对比不同参数设置对基准分类器准确率的影响。表2显示了GAN主要参数设置对使用GAN-RDE方法扩充评论数据集后基准分类器准确率的影响。
GAN主要参数敏感度分析结果表明,在线评论文本的特征维度l最优为500,此时GAN训练效果最好,各基准分类器的准确率达到最高。在线评论文本的特征维度小于500时,基准分类器的准确率会随着特征维度的增加而提升。而当在线评论文本的特征维度大于500时,GAN训练无法达到最优的效果,基准分类器的准确率会随之降低。在线评论文本的特征维度小于500时,特征维度的不足导致基准分类器的分类准确率无法达到最优。特征维度大于500时,特征维度的冗余导致了基准分类器分类精度的下降。生成器G输入特征数量dG最优为500,当生成器输入特征数量小于500时,输入特征数量的不足影响GAN的训练效果,导致GAN生成的特征词词向量矩阵不能很好地学习评论数据集数字特征,进而降低了基准分类器的准确率。生成器的输入特征数量超过500时,生成器G的输入特征数量的大小对基准分类器的准确率没有提升。这表明在给定生成器输出维度的情况下,如果输入特征数量超过其最优值,生成器并不会学习到在线评论更多的特征。判别器的输入特征数量dD和在线评论文本的特征维度l设置为500时,基准分类器的准确率达到最高。判别器的输入特征数量小于500时,特征维度的不足会降低GAN的训练效果进而导致基准分类器的分类准确率无法达到最优。因此,加入更多的特征信息能够提升基准分类器的分类准确率。判别器的输入特征数量大于500时,基准分类器的准确率会下降,这是由于特征维度的冗余降低了GAN训练效果,并导致基准分类器准确率下降。
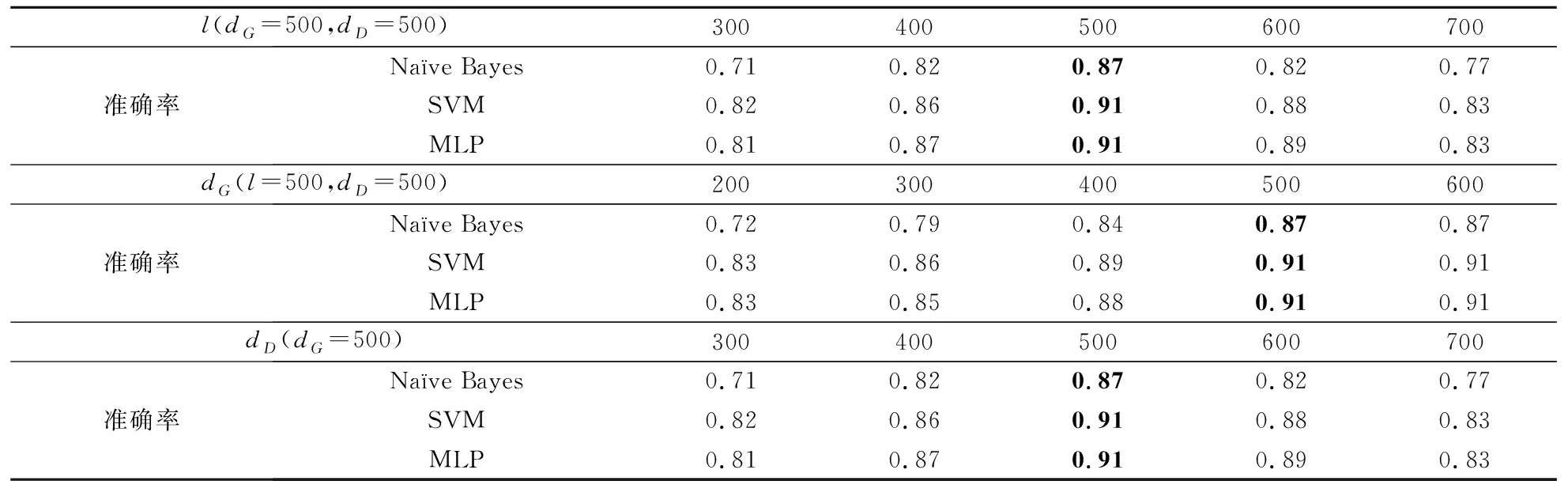
表2 GAN主要参数敏感度分析
4 结论
为解决现阶段虚假评论识别方法中训练集数据贫乏的问题,本文在Ott等人采集的数据集基础上尝试使用生成式对抗网络对在线评论数据集扩充方法进行研究。通过训练生成式对抗网络,为虚假评论识别模型提供足够量已标注的评论数据来进行模型训练,以此提升虚假评论识别的准确率。本文的贡献可总结为两点:
·本文提出了评论数据集扩充方法GAN-RDE。通过合并GAN训练得到的符合评论特征的向量和初始评论数据集的特征词词向量矩阵,生成更多数据样本以扩大训练数据量。GAN-RDE方法可以很好地解决现阶段虚假评论识别方法中训练集数据贫乏的问题。
·本文基于标准评论数据集,借助生成式对抗网络实现对数据集的扩充,使得基准虚假评论识别方法准确率得到提升,因此本文认为生成式对抗网络相关方法和思路对于虚假评论研究领域具有一定意义,可以在相关领域当中引入生成式对抗网络相关方法来进行虚假评论的识别和研究。
本文不足之处是没有在GAN生成器和判别器中采用更为复杂的神经网络结构,近年来生成式对抗网络获得了深度学习领域的广泛关注,许多学者对其展开研究并衍生出了基于生成式对抗网络的复杂模型,如DCGAN、WGAN等模型[17]。这些复杂模型在原有生成式对抗网络的基础上改进了其应用范围,广泛应用在图像和文本领域,对本文中训练的模型具有一定改进作用,未来可以采用其它训练模型改进评论数据集扩充方法,提升实验效果。
