基于多分辨率自蒸馏网络的小样本图像分类
2022-12-13仇真奚雪峰崔志明盛胜利胡伏原
仇真,奚雪峰,崔志明,盛胜利,胡伏原
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215000;2.苏州市虚拟现实智能交互及应用重点实验室,江苏 苏州 215000;3.苏州智慧城市研究院,江苏 苏州 215000;4.德州理工大学 计算机科学系,美国 拉伯克79401)
0 概述
深度神经网络(Deep Neural Network,DNN)在图像分类、目标检测、语义分割等方面取得较优的效果。研究人员通过增加网络的深度和宽度以提高神经网络精度,但通常增加的计算量与精度不平衡。为了使网络在计算资源受限的平台上运行,尽可能地提高网络模型的精度,知识蒸馏是网络模型压缩中常用的方法。与传统的知识蒸馏方法不同,自蒸馏(Self-Distillation,SD)[1]学习方法不需要预先训练教师网络,而是对具有相同架构的单个模型进行知识蒸馏,以减少对复杂教师网络训练所耗费的成本,最大程度地提高网络精度。然而,深度学习模型在学习过程中存在过拟合问题。研究人员可以从少量的样本中快速学习某一类事物。受此启发,小样本学习(Few-Shot Learning,FSL)[2]的概念应运而生。小样本学习旨在使深度学习模型根据训练任务之间的共性,将所学到的先验知识快速推广到只含少量标注样本的新任务中,极大地减少了样本数据的获取成本和难度,并且缓解了深度学习中存在的过拟合问题。因此,充分发挥小样本学习在图像分类任务上的潜力逐渐成为研究热点。
在小样本学习任务中,对于图像分类结果的可靠性有着严格的要求,而图像中相似冗余背景会对目标特征的识别存在显著干扰。当面对背景非常复杂并且含有大量冗余信息的输入图像时,注意力机制对感兴趣区域(Region of Interest,ROI)[3]着重处理有助于模型精准的分类。研究人员通过对提取图像中的感兴趣区域进行处理,从而忽略图像的冗余信息。基于度量学习的方法在小样本分类任务上取得较优的效果,在图像分类过程中根据顶层的特征进行度量学习。从特征提取的角度分析,顶层的样本特征分辨率较低,图像的通道信息、空间信息等细节信息基本丢失,导致小样本图像分类任务的精度降低。文献[4]分别使用空间注意力机制和通道注意力机制来减少分类过程中细节信息的损失,使模型获得较高的准确性。因信息减少和维度分离,这些注意力机制仅利用来自有限接受域的视觉表征。在这个过程中,它们失去了全局空间通道的相互作用,从而削弱了图像的全局表征信息。
本文提出一种多分辨率自蒸馏网络(Multi-Resolution Self-Distillation Network,MRSDN),用于解决小样本学习任务中图像空间冗余问题。通过多分辨率学习的方法扩充图像的输入信息。为了提升整体网络的性能,将改进的全局注意力机制(Global Attention Mechanism,GAM)融入自蒸馏学习方法中,利用顺序通道-空间注意机制模块来保留信息且放大全局跨维度的相互作用,以加快图像的处理速度并提高模型分类的准确性。
1 相关工作
1.1 小样本学习
现有的小样本方法可分为基于模型的方法[5-6]、基于优化的方法[7]和基于度量学习的方法[8-10]。基于模型的方法是通过构建合适的元学习模型,建立输入与预测的映射函数,并不断地在少量样本上更新参数来获得经验知识。文献[5]提出的元网络具有快速泛化能力,通过学习元级知识和不同任务中转移归纳偏差得到经验知识。基于优化的方法是在进行小样本学习任务时,考虑到使用梯度下降方法会造成模型的拟合度降低,通过调整优化的方式来完成小样本学习任务。文献[11]提出MAML 方法,以学习模型的初始化参数,在梯度下降优化步骤后最大限度地提高新任务的性能。基于度量学习的方法是通过度量支持样本和查询样本之间的距离,以实现不同样本相似性的度量,并根据最近邻原理来完成图像分类任务。文献[9]提出原型网络,在映射后的空间中距离越近的样本属于同一类别的可能性越大。每个类都有一个原型表示,类别的原型表示是获取支持集中所有向量的均值。网络根据聚类原理将输入图像映射到一个度量空间后,使用欧几里得距离计算查询集样本到每个原型之间的距离,将小样本分类问题转化为嵌入空间中的最近邻问题。基于度量学习的方法在小样本图像分类方面比其他两种方法具有更优的性能[8-10]。
本文提出一种基于度量学习的方法,不仅使模型在训练过程中得到尽可能多的类,而且还强调每个类需要注意的时空特征,同时增大与其他类的差异。
1.2 自蒸馏学习
在深度学习的背景下,本文尝试获得一个规模较小的模型,能达到与规模较大模型相当的效果。然而,从头训练一个小模型难以实现上述目标。知识蒸馏通过预训练一个复杂的教师网络,并将其学到的特征表示蒸馏出来,并传递给参数量小的学生网络,使学生网络的性能接近预训练的教师网络,以实现知识迁移的目的。文献[3]提出一种自蒸馏框架,该框架提供可以在不同深度提炼知识的单一神经网络,使其在资源有限的边缘设备上进行自适应精度与成本的权衡。相比传统的知识蒸馏方法,自蒸馏学习是一段式蒸馏方法,能缩短模型的训练时间,并且相比其他改进的蒸馏方法,模型的精度也得到了提升,实现了模型在精度和计算成本之间的动态平衡。
自蒸馏学习方法根据增益信息的来源进行分类,主要分为伪孪生网络和深度监督两类。伪孪生网络是指两个较相似且权重独立的网络,使用的教师和学生模型是同一个模型,在时间维度上细分为同步蒸馏与多阶段蒸馏两个子类。同步蒸馏在自监督任务上规模较大的模型比小模型更加受益。为解决在小模型上自监督预训练的问题,文献[12]提出Distill on the Go 模型,利用在线蒸馏方法来改善小模型的表征学习效果。该模型使用两个权重独立的相同模型作为伪孪生网络,使用互学习的策略让两个模型在同一时刻相互学习,并分别作为教师和学生网络,使得两个模型在相同样本增强后的相似度上具有一致性。多阶段蒸馏核心思想是使用之前时刻的模型作为教师网络,以蒸馏之后模型作为学生模型。文献[13]提出一种有效的正则化方法进行多阶段蒸馏,通过提取模型本身的知识,生成具有更多信息的训练目标,并在训练过程中隐式地进行硬实例挖掘,有效地提高深度神经网络的泛化能力。深度监督是利用模型中较深层网络结构作为教师网络,蒸馏原始网络中较浅层的网络结构。文献[3]提出的自蒸馏框架是典型的深度监督方法,将深层网络分类器作为教师网络,通过对网络中的浅层部分进行蒸馏。本文提出的自蒸馏网络也是利用深度监督的方式,学生和教师模型来自于相同的卷积神经网络,将四层卷积作为深层网络,并对共享第二层卷积模块权重的浅层网络进行蒸馏,使模型能够在网络间进行知识转移,显著提高卷积神经网络的性能。
1.3 多分辨率网络与空间冗余
单尺度网络中的下采样操作可能会限制网络识别任意尺度对象的能力。最近,研究人员提出采用多尺度特征映射网络的方法,以充分利用图像的粗粒度和细粒度特征,在许多视觉任务上显著地提高了网络的性能,包括图像分类[14]、目标检测[15]、语义分割[16]和姿态估计[17]。
虽然通过深度神经网络获取的高分辨率特征图对于记录一些特定任务是必要的,但是通常在高分辨率特征上进行卷积操作会导致资源的消耗量增大。轻量级网络[18]对具有低分辨率输入的样本具有较优的识别率,并且在处理空间冗余问题上也取得了较优的效果。文献[19]利用Octave Conv 模块处理小尺度特征图,提高计算效率和分类性能。此外,文献[20]提出的AdaScale 网络能自适应地选择输入图像尺度,提高视频目标检测的精度和速度。
然而,现有的研究未考虑根据图像中的空间冗余信息来设计一个自适应模型。本文提出一种高效小样本图像分类模型,在低分辨率网络上,加入全局注意力机制对输入样本进行分类,利用融合策略将局部关系和全局关系自适应地融合在一起,最终将低分辨率网络中的粗粒度特征重用并融合到高分辨率网络中,将高频信息作为识别样本的补充,以提高模型提取图像表征的能力,从而显著地提高模型的精度。
2 多分辨率自蒸馏网络
2.1 问题定义
小样本学习方法在训练阶段可以构造多个不同的元任务,通过在这些元任务上进行学习,得到能够快速适应新任务的模型。与传统的分类任务不同,小样本学习的训练集Dtrain和测试集Dtest由来自同一类的样本组成,小样本学习旨在解决Dtrain和Dtest之间标签空间不相交的问题。本文遵循文献[21]定义的标准N-wayK-shot 分类场景来研究少镜头学习问题。为构建不同的新任务,支持集和查询集都会随机产生不同的类别组合,通过不断进行周期性迭代训练的方式,使任务更具有普遍性,网络能够提取图像之间的通用特征,以适应新的支持集和查询集。具体计算过程如式(1)和式(2)所示:

其中:Ssupport表示支持集;Squery表示为查询集;x与y分别表示支持集中图像以及其对应的标签;N×K与C分别表示支持集与查询集中图像的总数量。每次从目标数据集合Cbase中随机选出N个类别,再从已有的N个类别中随机选取k个样本作为支持集Ssupport,N-wayK-shot 再从已选的N个类别中随机选出m个样本组成查询集Squery,一组查询集和一组支持集组成一个task 任务。在学习不同的task 分类任务时,不同的task 之间类别不同,训练任务与测试的类别不相交。
2.2 整体框架
本文介绍MRSDN 的整体架构和网络细节。MRSDN 是由不同输入分辨率的网络组成,其中低分辨率网络与高分辨率网络共享第二层卷积模块。低分辨率样本由浅层子网络进行分类,其特征图具有最低的空间分辨率。同时,利用高分辨率网络识别图像中包含的高频信息,并作为识别样本的补充。最终将高分辨率网络对低分辨率网络进行蒸馏,不断优化低分辨率网络,并将低分辨率网络中的粗粒度特征重用并融合到高分辨率网络中,以提高模型提取图像表征的能力。多分辨率自蒸馏网络结构如图1 所示。本文提出的MRSDN 网络主要由多分辨率模块、全局注意力模块、自适应融合模块和自蒸馏模块四个部分组成。多分辨率模块可以学习不同分辨率图像的特征嵌入,并为输入图像生成丰富的深度局部描述符。每个查询图像和每个支持类的分布都可以在深度局部描述符的级别上表示。全局注意力模块可以放大显著的跨维度接受区域,以捕获全局维度的重要交互特征。自适应融合模块能联合学习得到的权值向量,将局部关系和全局关系自适应地融合在一起,然后采用非参数最近邻分类器作为动态分类器。自蒸馏模块是将深层网络分类器作为教师网络,对共享第二层卷积模块权重的浅层网络进行蒸馏。这四个模块以端到端的方式从头开始进行联合训练。

图1 多分辨率自蒸馏网络结构Fig.1 Structure of multi-resolution self-distillation network
2.2.1 多分辨率模块
现有研究在降低图像分辨率的同时,可以减少不必要的细节特征,使得部分图像的识别精度得到提高。受这种现象的启发,本文采用一种多尺度的体系结构和密集连接的方法来构建多分辨率网络。为生成具有高分辨率的新特征图作为输入,本文构建一个Regular-conv 层,该层由一个bottleneck 层和一个Regular convolution 层组成,并且每一层都包含一个批处理归一化(BN)层、一个ReLU 层和卷积层。首先,在Regular-conv 层的卷积过程中,采用双线性插值的方式对图像特征进行上采样,保证产生的特征具有相同的空间分辨率,然后,将得到的特征图通过密集连接进行融合。将Regular-conv 层中的Regular convolution 的stride 设为2,构建一个strideconv 层,并将其嵌入到带有下采样的融合块中,以减少末端的空间分辨率,进一步压缩子网络的特征映射,保证每次得到的分辨率都是最低的,再将得到的不同分辨率样本数据输入到网络中,并且为输入图像生成丰富的深度局部描述符,使得每个查询图像和每个支持类的分布都可以在深度局部描述符的级别上表示。
多分辨率模块的结构如图2 所示。初始层可以用于生成尺度中的基本特征,它只包括图2 中的垂直连接。本文把初始层的垂直布局看作是一个微型的“H”层卷积网络(H 是网络中基本特征的数量),所提的网络在初始层具有两个尺度的基本特征。初始层生成基本特征,MRSDN 可以被划分为两个网络,这些网络进一步由不同的Conv 块组成,以学习不同分辨率图像的特征嵌入。其中,将空间低分辨率的特征映射送入浅层网络中,以避免卷积运算时所引起的高压缩代价,并将空间高分辨率的图像送入深层网络中获得图像的高级映射,使这两种分辨率网络分别得到图像由粗到精的表征,丰富整个网络的表达能力。最终,浅层子网络使用其对应的基本特征图获取图像低分辨率特征,并结合深层网络中第二层卷积模块的高分辨率特征来进行分类任务。

图2 多分辨率模块结构Fig.2 Structure of multi-resolution module
2.2.2 全局注意力模块
传统通道注意力的计算方法是通过计算每个通道的权重,然后将获得的权重应用于每个特征通道,从而学习到不同通道的重要性。为了计算这些通道的权重,每个通道都需要标量值来生成注意力权重,该标量一般都是通过全局平均池化的操作获得,这样会导致空间信息大量丢失,并且通道维数和空间维数之间的相互依赖性也不存在。虽然CBAM 模型缓解了空间相互依赖的问题,但是依然存在一个问题,即通道注意力和空间注意力的计算是相互独立的。为减少图像的信息损失并放大全局维数交互特征,本文设计一种有效的全局注意力机制,采用CBAM 中的顺序通道-空间注意机制,并重新设计子模块。全局注意力模块结构如图3 所示。

图3 全局注意力模块结构Fig.3 Structure of global attention module
本文给定输入特征图F1∈RC×H×W,中间状态F2和输出F3的定义如式(3)和式(4)所示:

其中:MC和MS分别为通道注意力图和空间注意力图;⊗表示元素级乘法。
在通道注意子模块中,本文使用三维排列的方式来保留三维信息,并利用一个两层的多层感知器来放大跨维的通道-空间依赖关系。为关注空间信息,本文在空间注意子模块中使用两个卷积层进行空间信息融合。同时,由于最大池化会减少信息,且产生负向贡献,因此本文删除了最大池化操作,进一步保留特性映射。因此,空间注意模块有时会显著增加参数量。为防止参数量的显著增大,本文采用带有通道混洗的组卷积。通道注意力与空间注意力模块结构如图4 所示。

图4 通道注意力与空间注意力模块结构Fig.4 Structure of channel attention and spatial attention modules
文献[22]提出的ResNeSt 模型在进行分组卷积时,采用通道间稀疏连接使每个卷积操作只作用于所需的特征图,以减少模型的参数量与计算量,并避免因内存频繁交互所耗费大量时间。但是该操作阻塞了不同组之间的信息传递,削弱了图像的全局表征信息,并且在进行组卷积之后,容易出现欠拟合现象,从而导致模型的精度下降。为保证经组卷积之后不同组的特征图之间能进行信息交流,本文采用通道混洗的方法对组卷积之后的特征图进行重新组合。通道混洗的具体方式如下:假定将输入层分为k组,总通道数为k×n,首先将维度拆分为(k,n)两个维度,然后将这两个维度转置变成(n,k),最后重新Reshape 成一个维度,从而实现均匀的通道混洗目的。
对于来自前一层的特征图,本文利用通道混洗的方式将该组的特征图分为多个不同的子组,再将这些子组特征输入到下一层的组中。这样可以充分发挥组卷积的优点,使采用组卷积的输入来自不同的组,因此信息可以在不同组之间流转,丰富了不同维度的信息交互。相比CBAM 等典型的注意力机制,本文方法在保持精度的同时降低计算成本,在减少信息损失的同时放大了全局交互特征。
2.2.3 自适应融合模块
MRSDN 通过Conv Block 定义了查询分布和支持类分布之间的联合非对称分布度量,同时考虑到不对称的局部关系和全局关系,分别使用KL 散度计算全局关系和I2C 测度产生的局部关系,并设计一种融合策略将局部关系和全局关系自适应地融合。本文采用一个可学习的二维权值向量w=[w1,w2]来实现这种融合。由于KL 散度表示不相似性,因此本文使用KL 散度的负值来获得相似性。查询Q和类S之间最终融合的相似度定义如式(5)所示:

自适应融合模块结构如图5 所示,对于一个5-way 1-shot 任务和一个特定的查询Q,I2C 分支或KL 分支的输出是一个5 维相似向量。本文将这两个向量相连接,得到一个10 维的向量,利用核大小为1×1 的一维卷积层,膨胀值为5,通过学习二维权值w得到一个加权的5 维相似向量。此外,在一维卷积层之前还添加一个批处理归一化层,以平衡I2C 分支和KL 分支集联后产生的相似冗余。最后,使用非参数最近邻分类器得到最终的分类结果。同时,交叉熵损失也被用来学习整个网络。

图5 自适应融合模块结构Fig.5 Structure of adaptive fusion module
2.2.4 自蒸馏模块
在深度学习网络中,绝大多数预测任务使用Softmax 层给大量标签分配概率分布。然而,这种处理方式存在一个问题:与正确标签相比,模型为所有的错误标签分配了很小的概率,而实际上对于不同的错误标签,其被分配的概率可能存在很大的差异。由于宏观上这些概率都很小,这一部分知识在训练过程中很容易被淹没,在知识蒸馏的过程中浪费许多先验概率。为充分利用这种类别之间的相似性,文献[23]提出利用参数T来改变概率分布,使映射曲线变得更加平缓。概率分布如式(6)所示:

对于每个输入类别x,模型产生对应logit向量z(x),通过提高参数T使得Softmax 层的映射曲线更加平缓,因而实例的概率映射将更集中。因此,通过缩放教师网络的Softmax 输出PT(X)和学生网络的PS(X),使用损失函数LKD对学生网络进行训练,如式(7)所示:
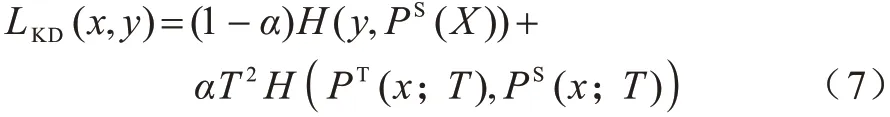
其中:H为交叉熵损失;α为超参数。本文根据目标卷积神经网络的深度和原始结构,分出一个浅层神经网络作为学生网络,在训练期间深层网络被视为教师网络。与传统的自蒸馏方法不同,本文将注意力机制融入到自蒸馏学习中,并构建一个从深层到浅层的反馈连接,使网络能够从图像的多分辨率角度进行表征学习,从而加强网络的整体特征表达能力。MRSDN 通过共享不同层次的注意力权重,并将不同层次网络提取到的注意力特征图送入分类器中,分别得到高维与低维预测的概率分布,然后根据预测的概率分布,通过深层网络对浅层神经网络进行蒸馏。相比Distill on the Go 模型[12]使用的两个权重独立的相同模型作为伪孪生网络,本文方法有助于连续层次之间的交互学习,能够更快地在全局特征中提取图像的通用特征,将教师网络较强的特征提取能力嵌入到学生网络中,极大地提升了学生网络的性能。
3 实验与结果分析
本文在常用的数据集Mini-ImageNet 和Tiered-ImageNet 上对设计的网络框架进行对比,以验证小样本分类问题的性能,通过消融实验验证模型中相关模块的有效性。本文项目代码地址为https://github.com/MRSDN/Project,相关数据集地址为https://lyy.mpi-inf.mpg.de/mtl/download。
3.1 数据集
小样本分类任务中两个经典的数据集分别为Mini-ImageNet 和Tiered-ImageNet。Mini-ImageNet是ImageNet 的子集,包含100 个类,每个类别包含600 张图像。本文把样本集分为64、16 和20 个类,分别用于训练、验证和测试。Tiered-ImageNet 总共有608 个类别,每个类别有1 281 张图像。在该数据集上,本文对其拆分为351、97 和160 个类别,分别用于小样本学习的训练、验证和测试。对于Mini-ImageNet 和Tiered-ImageNet 数据集,所有图像的分辨率都调整为84×84 像素。
3.2 基线模型
本文将MRSDN 与近年来前沿的小样本图像分类模型进行比较,基线模型主要有:1)MAML 模型[11],能够将先验知识公式化为跨任务的通用初始化,以快速适应新的任务,而强制共享初始化可能会导致任务间产生冲突,冲突程度在不同任务以及神经网络的各个层之间存在不同的差异;2)L2F 模型[24],是一种动态控制强制共享初始化的方式,以降低强制初始化对给定任务和神经网络各层先验知识的影响;3)MetaOptNet-RR 模型[25],使用线性预测器作为MAML 中的基础学习器来提高泛化能力;4)MatchingNet 模型[26],是一种通用的网络架构,利用训练样本嵌入空间中的注意力机制来预测测试样本的类别;5)RMN-RPN 模型[27],是一个基于度量学习和注意力机制的小样本学习的新框架,能够更好地度量图像的相似性;6)ProtoNet 模型[28],通过神经网络得到样例的向量化表示,然后计算向量化表示之间的相似度或者距离来判断样例是否为同一类别,与MatchingNet 相同,在度量特征向量的距离上都使用了固定的度量方式;7)IMP模型[29],与ProtoNet 表示每个类的原型方法不同,利用无限混合原型自适应地表示简单和复杂的数据分布;8)ECMF 模型[30],是一种学习嵌入的方法,利用嵌入式类模型的方式代替ProtoNet 中类原型的学习;9)RelationNet 模型[31],不仅在样本的嵌入阶段进行学习,而且在距离度量方式上也发生了改变;10)CovaMNet 模型[32],通过计算查询样本与每个类别的分布一致性,构建协方差度量,并将其作为关系测度;11)ATLNet 模型[33],是一种自适应任务感知局部表示网络,在整个任务中自适应地选择重要的局部块;12)DN4 模型[34],采用基于局部描述符的图像到类的度量,寻找与输入图像最接近的类别;13)ADM 模型[35],相比于DN4 的非对称度量,更适用于基于度量的小样本学习。
本文通过多组实验对这些网络模型的相关代码进行重现,在训练小样本学习过程中存在每组数据随机获取的特性,实验结果的误差在标准范围内,验证了本文基准网络模型的准确性。
3.3 实验设置
本文所有的实验均在Ubuntu18 的环境下测试,根据深度学习的特点,模型的性能在很大程度上取决于网络结构的设计和参数的初始化。本文选择Conv64 作为特征提取器,在训练和测试阶段按照标准的元学习方法,即在训练和测试的每一个任务中数据严格按照N-wayK-shot 形式。本文均采用5-way 1-shot 和5-way 5-shot 的形式来得到模型的准确率。每次新任务都随机抽取5 个类别,每个类别的训练数据只有1 个样本,即组成一个5-way 1-shot任务,在每个类别上只有5 个样本的情况下训练本文模型。在训练过程中,本文选用Adam 作为优化器,网络学习率设置为0.001,每训练10 000 次学习率减半。由于Tiered-ImageNet 数据集规模较大并且类别复杂,因此每训练25 000个任务后,即训练250 次后,学习率减少1/2。在测试过程中,从测试数据集中随机抽取600 个批次的分类结果的平均准确率作为评价标准,以衡量模型的精度。本文提出的MRSDN 网络是以端到端的形式进行训练,不需要在测试阶段进行微调。
3.4 结果分析
本文在Mini-ImageNet 和Tiered-ImageNet 数据集上对MRSDN 网络和基线网络进行对比。实验结果表明,与其他的先进网络相比,本文所提网络在分类任务上的准确率有较大的提升,说明本文模型能够有效地用于小样本的分类任务。
3.4.1 在Mini-ImageNet 数据集上的结果分析
为了评估模型的性能,本文在Mini-ImageNet数据集上将MRSDN 网络与其他的小样本分类网络进行对比。在Mini-ImageNet数据集上,不同网络的分类精度如表1 所示。本文网络在5-way 1-shot、5-way 5-shot 任务上都具有较优的表现。

表1 在Mini-ImageNet 数据集上不同网络对5-way任务的分类精度对比Table 1 Classification accuracy of 5-way tasks by different networks on Mini-ImageNet dataset
从表1 可以看出,本文提出的MRSDN 与其他的小样本分类网络相比,在Mini-ImageNet数据集上的精度得到显著提升。与ATLNet网络相比,本文网络在5-way 1-shot和5-way 5-shot任务上的准确率分别提高2.04 和1.13 个百分点。通过分析可知,ATLNet 虽然可以自适应地识别和加权不同的关键局部部分的重要性,但是未同时考虑局部与全局关系的不对称性。MRSDN 考虑到非对称度量更适合于基于度量的小样本学习,设计一种融合策略将局部关系和全局关系自适应融合,并通过多分辨率模块和自适应特征融合模块获得标签得分,不仅能融合多个分辨率的预测分数,还能平衡不同分辨率之间的预测结果,从而得到更高的分类精度。Mini-ImageNet 是一个多种类的数据集,因此在该数据集上的实验结果从侧面验证了本文模型具有较优的鲁棒性。
3.4.2 在Tiered-ImageNet 数据集上的结果分析
相比Mini-ImageNet 数据集,Tiered-ImageNet 数据集不仅具有较大的数据量并且每个类别包含数量不等的多个图像样本。为验证模型的泛化能力,本文在Tiered-ImageNet 数据集上采取5-way 1-shot、5-way 5-shot 两种实验方式进行对比,实验结果如表2所示。

表2 在Tiered-ImageNet 数据集上不同网络对5-way任务的分类精度对比Table 2 Classification accuracy of 5-way tasks by different networks on Tiered-ImageNet dataset
从表2 可以看出,与其他小样本分类网络相比,基于多分辨率自蒸馏网络的MRSDN 在Tiered-ImageNet数据集的5-way 1-shot、5-way 5-shot 任务上具有较优的分类精度。在5-way 1-shot 和5-way 5-shot 任务上,与ADM 网络相比,本文网络的准确率分别提高3.55 和2.78 个百分点。ADM 网络采用一种任务感知训练策略,以增强度量的效果,而本文所提的MRSDN 网络能够从不同分辨率角度提取图像更细致的特征信息,在此基础上,利用自蒸馏的方法有效地优化模型的训练策略,以缓解网络在训练过程中存在的过拟合问题,以提高模型的精度。MRSDN 在不同数据集上具有较强的图像表征能力和较优的泛化性能。
3.5 消融实验
为分析每个模块对网络模型产生的影响,在Mini-ImageNet数据集上本文使用控制变量法进行消融实验。本文消融实验结果如表3 所示。表中MRM 表示多分辨率模块,GAM 表示全局注意力模块,SDM 表示自蒸馏模块,ADM 表示自适应融合模块。

表3 消融实验结果Table 3 Ablation experiment results
当模型消去多分辨率模块,仅存在单分支图像输入时,本文考虑到反向传播对模型训练过程产生的影响,去除作用相似的自蒸馏模块。实验结果表明,多分辨率模块能够从不同的分辨率角度提取特征,减少图像的空间冗余信息,有利于更好地表达图像的细节信息,使模型的分类精度得到显著提高。若不考虑全局特征的交互,会导致模型对于图像的抗噪声能力降低,模型的分类精度较低。因此,本文在5-way 1-shot、5-way 5-shot 任务上引入自蒸馏学习方法,同时使用多分辨率模块和全局注意力模块提高网络的性能,从而极大地抑制网络的过拟合现象。
4 结束语
本文提出一种用于小样本图像分类的多分辨率自蒸馏网络(MRSDN)。从多分辨率角度,利用浅层子网络处理图像的粗粒度特征,同时,通过高分辨率网络学习更加精细的特征。从空间和通道特性角度,使用自适应融合模块将全局与局部关系相融合,有针对性地提取图像之间的空间和通道信息,提高网络提取图像特征的能力,通过自蒸馏学习的方法实现模型内高效的知识迁移。在Mini-ImageNet 和Tiered-ImageNet 两个数据集上的实验结果表明,MRSDN 具有较优的小样本图像分类性能。后续将考虑构建多组不同分辨率表示的学生网络,以提取图像的关键特征,并改变网络中共享权重的模块数量,进一步提升小样本图像分类的准确率。
