基于交互式特征融合的嵌套命名实体识别
2022-12-13廖涛黄荣梅张顺香段松松
廖涛,黄荣梅,张顺香,段松松
(安徽理工大学计算机科学与工程学院,安徽淮南 232001)
0 概述
命名实体识别(Named Entity Recognition,NER)是从一个给定文本中识别并判断具有特殊意义的词以及所属类型,例如,人名、地名、组织机构名、专有名词等。命名实体识别在自然语言处理(Natural Language Processing,NLP)过程中具有重要意义,并被广泛应用在关系抽取[1]、信息检索[2]、机器翻译[3]、问答系统[4]等领域。
现有研究主要针对非嵌套命名实体(flat NER),在处理非嵌套命名实体时,现有方法将其作为序列标注的问题[5],但是无法准确地识别具有嵌套结构的实体。在GENIA数据集的某个嵌套命名实体“the CD28 surface receptor”中,“CD28”表示某种protein 实体,包含在另一种protein 实体“CD28 surface receptor”中,这种实体结构被称为嵌套命名实体(nested NER)。嵌套命名实体作为一种常见的语言现象,备受研究人员的关注。
近些年,研究人员在处理nested NER 时,基于转化的方法提出构建嵌套命名实体的超图结构。例如,文献[6]基于递归神经网络构建超图识别嵌套实体,设计表达性标记模式来识别嵌套实体,但该方法未考虑句子特征信息的提取。文献[7]基于条件随机场(Conditional Random Field,CRF)通过转移操作将嵌套结构转换为平面结构来预测实体类型,但该方法需要进行复杂的转换,并且在解码过程中耗费大量时间。除此以外,研究人员基于跨度的方法解决nested NER 问题。例如,文献[8]采用局部检测方法将给定文本划分不同片段,并将其编码成固定大小的表示,但该方法忽略了边界信息容易造成实体片段边界划分错误的问题。文献[9]提出额外的边界检测任务来预测实体边界的单词,但它与实体识别任务分开进行,忽略了边界信息与实体内部信息的联系。
本文提出基于交互式特征融合的嵌套命名实体识别模型。通过字符向量与字向量的交互融合,得到单词深层语义信息,采用双向长短时记忆(BiLSTM)网络提取句子级特征,对不同单词特征表示得到的句子级特征向量进行二次交互,并加入多头注意力机制捕获句子隐层序列表示的多重语义信息。为了增强实体边界信息的识别,构建粗粒度候选区间感知模块,并采用二元序列标记法过滤一些非实体区域。
1 相关工作
研究人员结合基于规则和机器学习的方法来处理嵌套命名实体[10]。文献[11]基于隐马尔可夫模型(HMM)[12]的方法检测最内部的实体提及,再通过基于规则的后处理方法检测外部提及。文献[13]提出CRF[14]识别生物医学文本中的蛋白质实体和基因实体。文献[15]在文献[13]研究的基础上,提出基于线性链条件随机场构建模型,有效提升生物医学文本中的识别效果。然而,基于规则的方法存在灵活性差、可扩展性差以及除字典之外的词查找能力不足的问题。
随着深度学习的不断发展,深度学习被用于各类NLP 任务中[16]。近年来,研究人员提出各种针对嵌套命名实体识别的方法,主要分为基于转化和基于跨度的方法。基于转化的方法将复杂的序列嵌套问题转化为标注型的序列标记任务,例如,JU等[17]提出堆叠的LSTM-CRF 识别嵌套命名实体,将每一层的输出作为下一层的输入,并在其相应的内部实体中编码信息,但该模型并没有关注上下文信息的有效性和实体边界信息,可能存在传播过程的错误级联问题。文献[18]提出以BiLSTM 作为编码器,LSTM 作为解码器实现序列到序列的序列标记模型,但模型在嵌套命名实体识别中需要大量人力来标注语料库中的转换以及复杂的特征工程。以往的实验结果表明,基于转化的方法需要大量的标记信息和复杂的特征工程,且操作复杂。
基于跨度的方法首先将句子划分为不同的跨度,然后用局部标准化的分数对这些跨度进行分类。XIA等[19]提出一种MGNER 神经网络架构,检测某一词段是否为实体词段,再用相同结构的分类器判断实体类型。YU等[20]结合词级嵌入和字符级别嵌入作为文本输入,经过BiLSTM 获取句子的上下文语义信息,使用双仿射模型对句子中带有开始和结束标记对的所有跨度分配分数并排序。SOHRAB 和MIVA[21]将嵌套命名实体识别看作分类问题,采用深度穷举模型自上而下地对设定区间L及L以下区间(L是人为设定数据)进行实体判断。以上基于跨度的方法虽然解决了基于转换方法中的问题,但忽略了在单词嵌入时不同特征之间的相互依赖关系,并且将不同单词特征表示直接相加,未捕捉深层单词语义信息。这两种方法学习句子中不同长度的所有候选跨度会耗费许多人力和时间。
综上所述,嵌套命名实体识别方法存在单词语义特征融合效果较差、边界信息检测不足的问题。本文对字级别嵌入和字符级别嵌入特征向量进行交互学习,采用二元序列标记法过滤非实体区间,得到只含有实体词的粗粒度候选区间,再对其进行细粒度划分。实验结果表明,本文模型避免了对不同长度的所有跨度进行识别,减少了计算时间和成本,通过字特征表示向量交互学习得到强语义信息,提高了实体识别的准确性。
2 交互式特征融合嵌套命名实体识别模型
2.1 模型架构
与大多数嵌套命名实体识别方法相同,本文基于跨度的方法构建嵌套命名实体识别模型。本文模型架构如图1 所示。整体结构分为五层:第一层为字嵌入层,获得字级别嵌入和字符级别嵌入的向量表示,并使两个向量交互学习获取强化的单词语义信息;第二层为基于BiLSTM 的特征交互表示层,经过BiLSTM 编码器捕获单词间的长依赖关系,并使两个隐层信息表示交互学习得到最终的上下文序列表示;第三层为基于特征融合的注意力机制层,使用多头注意力层进一步提取多重语义信息;第四层为粗粒度候选区间感知层,利用二元序列标记过滤一些非实体区间,得到粗粒度候选区间;第五层为细粒度划分及类别判断层,得到所有候选跨度的实体类别或非实体类别。
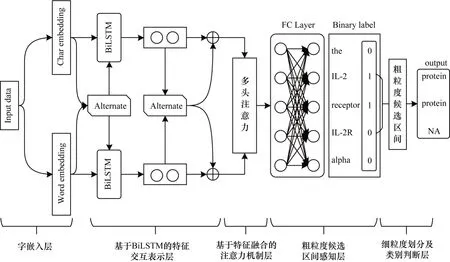
图1 本文模型结构Fig.1 Structure of the proposed model
2.2 字嵌入层
2.2.1 字嵌入
在字嵌入过程中,输入的句子被编码为X={X1,X2,…,Xn}。每个单词都有字级别嵌入向量和字符级别嵌入向量2 种类型的嵌入表示,分别得到字级别嵌入向量表示和字符级别嵌入向量表示(i表示第i个单词)。本文字嵌入的初始化使用了MIKOLOV等[22]和PENNINGTON等[23]提出的公开可用的预训练词向量。首先,根据数据集构建单词词汇表,然后,通过公开可用的预训练单词向量初始化词汇表以得到词向量表,在不断的训练过程中更新词向量得到最终单词的字级别表示向量。因此,本文采用BiLSTM 捕获字符级别的信息。首先,对数据集上所有字符构建字符表;然后,对每个字符随机初始化字符向量,此时将每个单词看作字符序列;最后,通过BiLSTM 网络得到最终单词的字符级别嵌入向量。单词的字符级别表示过程如图2 所示。本文第i个单词xi由和分开表示,为了方便后面两种特征向量交互学习,未对两种单词嵌入方式进行连接操作。

图2 单词的字符级别表示过程Fig.2 Character-level representation process of a word
单词Xi是由两种嵌入方式表示,本文定义xw表示句子的字级别向量表示,xc表示句子的字符级别向量表示。因此,句子的输入以两种不同的形式嵌入到分布空间中,如式(1)和式(2)所示:

2.2.2 嵌入单词表示向量交互
两种单词表示向量可以通过强化学习来挖掘深层次的字语义信息和字符构成的单词信息。本文通过两次交互机制来强化特征之间的信息融合。

其中:mul 表示不同数据之间的信息交互,经过第一次信息交互,字级别表示向量和字符级别表示向量分别带有对方的信息,强化了单词的信息表示。此时的两种单词表示向量包含了强化的单词语义信息。单词表示向量第一次交互过程如图3 所示。
2.3 基于BiLSTM 的特征交互表示层
BiLSTM 分别采用顺序和逆序对每个句子进行计算,以有效利用上下文信息,并且不存在梯度爆炸的问题[24]。本文融合字级别嵌入与字符级别嵌入来表示单词语义信息,在BiLSTM 网络编码层中捕获句子上下文信息,再将两个隐层状态交互学习并融合得到最终上下文序列表示,通过多头注意力机制进一步得到句子的深层语义信息,该过程如图4 所示。

图4 基于BiLSTM 的特征交互表示流程Fig.4 Procedure of feature interaction representation based on BiLSTM
2.3.1 BiLSTM 特征提取

2.3.2 特征交互
本文通过对隐藏状态的句子特征向量进行强化训练,获取深层语义信息,引入Softmax 激活函数更新不同特征的权重,同时让两个隐藏状态句子特征向量与权重矩阵进行交互,从而达到提高有用信息比重、降低非实体信息比重的目的。该过程如式(11)和式(12)所示:

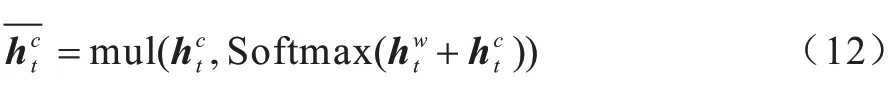
字级别嵌入向量与字符级别嵌入向量经过两次交互之后,最终包含单词语义信息和句子上下文信息的隐藏状态序列表示H={h1,h2,…,hn}。每个隐藏单元ht满足式(13):

2.3.3 基于特征交互的多头注意力
多头注意力通过多个子空间表示来提升模型关注不同特征的能力,有利于后续实体的边界分类和类型分类。因此,本文在BiLSTM 后加入多头注意力来获取上下文信息的依赖关系。其中,缩放点积注意力的计算如式(14)所示:

其中:AAttention(Q,K,V)表示注意力分数;Q表示查询向量;K表示键向量;V表示值向量表示键向量维数的平方根。
多头注意力层本质指进行两次以上的注意力头运算[25],对于基于BiLSTM 的特征交互表示得到的隐层序列状态表示,单头注意力计算如式(15)所示:


其中:MMH为多头注意力层的计算结果;Wc为权重参数。
2.4 粗粒度候选区间感知层
在粗粒度候选区间感知层中,本文采用二元序列标记法给每一个文本标记实数,其中实体词被标记为1,非实体词被标记为0,以判断每个词是否属于某个或多个实体,以便过滤掉一些非实体的区域,找到只含有实体词的粗粒度候选区间,进而划分出不同层的实体词,避免对所有不同跨度类型的区间进行实体判断,减少了计算的时间成本。隐藏层特征序列输出经过一个全连接层和Sigmoid 激活函数得到每个词属于实体内部或实体边界的实体词概率p。
本文设定当粗粒度候选区间感知层中每个词被预测属于实体词的概率p大于(不包含)0.5 时,即视为实体词。粗粒度候选区间全为实体词,对于每个粗粒度候选区间interval(i,j)=(Xi,Xi+1,…,Xj),Xi表示输入文本的第i个词,此时定义粗粒度候选区间的左边界信息为区间第一个词的句子级信息hi,右边界信息为区间最后一个词的句子级信息hj,整体信息为区间的所有词句子级信息表示的平均值。即每个粗粒度候选区间interval(i,j)向量表示如式(17)所示:

其中:hk表示输入句子中第k个单词的隐藏状态特征表示。
句子的粗粒度候选区间感知层使用二元交叉熵函数作为损失函数Lword,如式(18)所示:
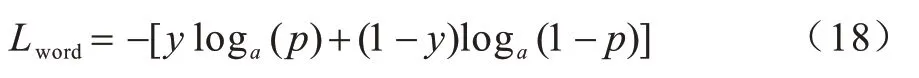
其中:y表示所判断词的真实标签;p表示所判断词为实体词的概率。
当模型进行训练时,若输入的句子X={X1,X2,…,Xn},且在区间(Xi,Xi+1,…,Xj)内都是实体,则对应的二元序列标签yi,yi+1,…,yj都为1,不在任何实体中的词被标记为0。句子的粗粒度候选区间感知层在当前批次的损失如式(19)所示:

其中:Lword表示粗粒度候选区间感知层的损失函数;wordi表示当前训练批次的第i个词;mx表示当前训练批次词的个数。当模型进行训练时,在训练集上运用反向传播算法对式(19)进行最小化,达到优化模型的目的。
2.5 细粒度划分及类别判断层
本文通过过滤一些非实体区域得到粗粒度候选空间。细粒度划分及类别判断层将对粗粒度候选区间进行划分,得到不同层的细粒度候选区间,通过一个全连接层和Softmax 层判断实体类别或非实体类别。细粒度划分及类别判断层的结构如图5 所示。

图5 细粒度划分及类别判断层的结构Fig.5 Structure of fine granularity division and category judgment layer
在大多数句子中含有的实体词较少,且连续实体词的长度也较短,因此,采用枚举的方法对粗粒度候选区间的细粒度进行划分。其中,细粒度区间的向量表示和粗粒度候选区间的向量表示方法保持一致。将细粒度区间的向量表示输入到由全连接层和Softmax 输出层构成的区域,用于分类该细粒度区间属于哪种实体类别或者不属于任何实体类别。本文的细粒度区间分类损失函数采用交叉熵损失函数,如式(20)所示:

其中:yinterval,c表示细粒度区间是否属于实体类别c的二元标签(1 表示属于,0 表示不属于);pinterval,c表示细粒度区间属于实体类别c的概率。实体类别总共有N个。
同理,细粒度划分及类别判断层在当前批次上的训练损失函数如式(21)如示:
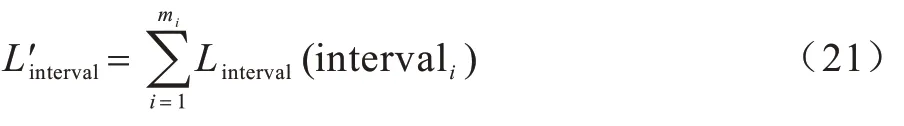
其中:Linterval为细粒度划分及类别判断层的损失函数;intervali为当前训练批次的第i个细粒度区间;mi为当前训练批次细粒度区间的个数。当模型进行训练时,在训练集上运用反向传播算法对式(21)进行最小化,达到优化模型的目的。
由于粗粒度候选区间感知层和细粒度划分及类别判断层共享相同的编码器BiLSTM,因此整个模型可以看成多任务训练,模型在训练集上的损失函数L为多任务训练损失的加权平均值,如式(22)所示:

其中:λ为超参数,0<λ<1,表示粗粒度候选区间感知层在整个 模型损失 中的权重和分别为粗粒度候选区间感知层和细粒度划分及类别判断层的损失函数。经验证,当λ取0.4 或0.9 时,本文的实验效果最优。
3 实验设计与结果分析
3.1 实验数据集
为验证模型的有效性,本文在嵌套的NER 数据集GENIA 上进行实验。对于GENIA 数据集,本文使用文献[26]发布的预处理版本。该数据集在属于医学领域的GENIA v3.0.2 语料库上建立,包含DNA、RNA、protein、Cell-line 和Cell type 实体类型。本文训练集、验证集和测试集的比例为8.1∶0.9∶1。GENIA 数据集的统计数据如表1 所示。

表1 GENIA 数据集的统计数据Table 1 Statistics data of GENIA dataset
3.2 训练数据标注方法
在实验部分,本文采用IOB2 标注方法对训练数据进行标注,单层的IOB2 标注方法无法标注嵌套命名实体,多层IOB2 标注方法可以对包含多个实体含义的实体词进行多列标注。IOB2 的标签I 用于文本块内的字符,标签O 用于除文本块之外的字符,标签B 用于在该文本块前面接续一个同类型的文本块情况下的第一个字符。多个文本块和每个文本块都以标签B 开始。
在标注时首先计算最大嵌套层数N,标注时对每个词标注N列,由内至外标注各层实体信息。在GENIA数据集上某一嵌套命名实体标注内容如图6 所示。

图6 多层IOB2 标注格式实例Fig.6 Example of multi-layer IOB2 annotation format
3.3 实验参数设置
本文所提模型基于PyTorch 框架,预训练的字级别嵌入的向量维度为200 维,字符级别嵌入的向量维度为200 维并随机初始化。模型参数设置如表2所示。表3 所示为本文的实验环境与配置。

表2 本文模型参数设置Table 2 Parameter settings of the proposed model

表3 本文实验的软硬件环境Table 3 Software and hardware environment of the proposed experiment
本文分别采用准确率P、召回率R和综合评价指标F1 值作为评价标准。
3.4 不同模型的对比实验
为验证本文所提模型的有效性,本文模型与嵌套命名实体识别的基线模型进行对比。对比模型如下:1)文献[27]基于超图方法联合建模识别实体边界、实体类型和实体头部;2)文献[8]提出基于局部检测方法识别嵌套命名实体;3)文献[28]引入分隔符概念,提出一种新的基于多图方法;4)文献[21]列举所有可能的实体跨度,并将其作为潜在的实体提及,使用深度神经网络对实体提及进行分类;5)文献[29]提出BILU-NEMH模型,将超图模型与编码模式和神经网络相结合,有效地捕获无界长度的嵌套提及实体。
在GENIA 数据集上不同模型的评价指标对比如表4 所示。
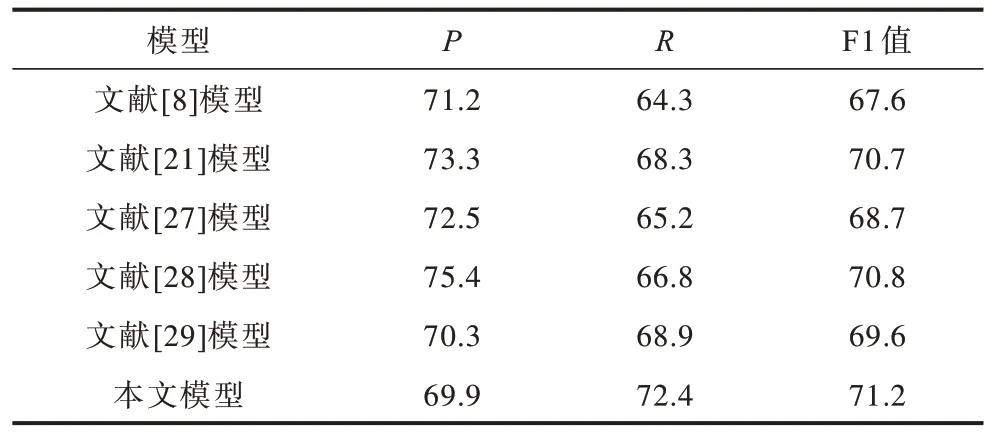
表4 在GENIA 数据集上不同模型的评价指标对比Table 4 Evaluation indexs comparison among different models on GENIA dataset %
从表4 可以看出,相比对比模型,本文模型的召回率R和F1 值都达到了最优。其中,文献[28]模型的性能次优。其原因为:虽然文献[28]提出的模型能够处理实体重叠的情况,但是在GENIA 数据集上,大多数模型提到的实体都是在一个嵌套的结构中,而不是在实体重叠的结构中。
相比对比模型,本文模型的召回率比最优模型(文献[29]模型)提升3.5 个百分点,F1 值相比最优模型(文献[28]模型)提升0.4 个百分点。这可能是由于本文模型经过特征交互融合和信息共享来优化实体正确识别的效果,也使得分类器更好地分类实体类别。因此,本文模型在召回率和F1 值上都有所提升。
表5 所示为本文模型在五种实体类别识别中的P、R和F1 值以及文献[21]模型在五种实体类别识别的F1 值。总计数据是在整个数据集的实体类别识别中的R、P、F1 值。文献[21]模型在RNA、protein实体类型上的识别效果优于本文模型,在其余实体类型上本文模型的性能都有不同程度的提高。因此,本文提出的基于交互式特征融合模型能有效改进句子隐藏信息的提取效果,对后续嵌套命名实体的识别起到了重要的作用。

表5 不同模型在各实体类别上的评价指标对比Table 5 Evaluation indicators comparison among different models on various entity categories %
3.5 消融实验分析
在深度学习模型的训练过程中,单词嵌入对模型的整体效果起关键作用。嵌入向量的结合方式,即单词特征向量表示的不同融合方法,对模型的整体效果也起到重要的作用。为验证嵌入时不同单词特征向量以及句子特征向量的交互对整体模型产生的效果,本文进行交互对比实验,除引入的交互策略不同以外,其他模型的参数设置均相同。三组对比实验如下:1)F-Alternate+BiLSTM+att,加入第一次交互,即进行单词嵌入向量的交互,通过BiLSTM 获取隐层序列信息,再通过多头注意力机制获取句子级信息;2)BiLSTM+S-Alternate+att,只进行第二次交互,即包含隐层序列状态信息的两种特征向量进行交互,之后加入多头注意力机制获取句子深层上下文信息;3)BiLSTM+att,不进行特征向量的交互,将两种单词嵌入表示向量直接拼接,并将其作为句子级输入,通过BiLSTM 得到隐层状态序列表示,再由多头注意力机制得到句子级深层语义信息。消融实验结果如表6 所示。
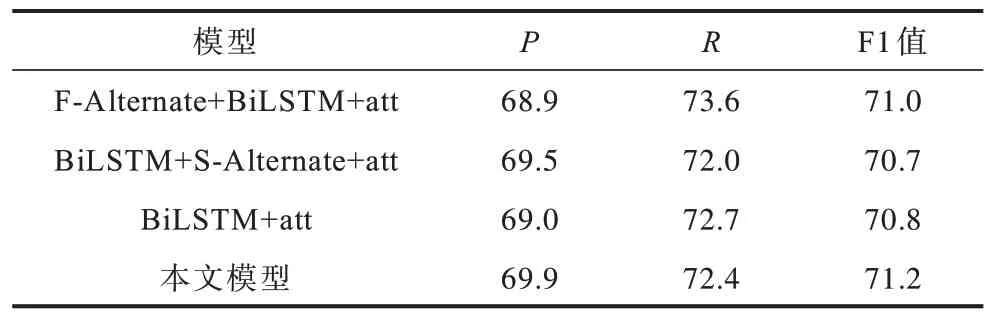
表6 消融实验结果Table 6 Ablation experiment results %
本文以BiLSTM+att 模型作为基准,对本文模型、F-Alternate+BiLSTM+att模型、BiLSTM+S-Alternate+att 模型进行对比。从表6 可以看出,F-Alternate+BiLSTM+att 模型与基准模型相比,F1 值和R分别提高0.2 和0.9 个百分点,这是由于此时两种单词表示向量各带有对方的信息,提取到了字与字符之间的依赖关系。BiLSTM+S-Alternate+att 模型的F1 值与R均低于基准模型,这可能是BiLSTM 在获得两种特征表示向量之前,未进行数据交流,将交互之后的信息作为噪音过滤掉,导致最终隐藏序列状态的信息获取不足。相比基准模型,本文模型F1 值和P分别提高0.4 和0.9 个百分点,说明第一次单词表示向量的交互使得字级别向量与字符级别向量分别带有对方的隐藏信息,获得两者之间的依赖关系,而第二次交互了句子级隐层序列特征向量,不仅加强了自身深层语义信息的获取,还增强了字级别特征与字符级别特征之间的信息交互。
为验证多头注意力机制对模型的影响,本文实验对比了基于特征交互的多头注意力模型与未加入多头注意力机制的模型,除了引入的注意力机制不同,其他模型的参数设置均相同。实验结果如表7 所示。

表7 引入多头注意力机制后不同模型的评价指标对比Table 7 Evaluation indicators comparison among different models after introducing multi-head attention mechanism %
相比F-Alternate+BiLSTM+S-Alternate模型,本文模型的F1 值提高1.5 个百分点,P和R各有不同程度的提升。因此,多头注意力机制对于文本深层语义信息的提取以及学习句子长依赖关系具有重要的意义。
结合以上结果表明,基于交互式特征融合和多头注意力机制可以提取句子的深层语义信息,得到隐藏序列向量表示,有效地提高模型的性能。
4 结束语
现有嵌套命名实体模型在字嵌入过程中存在不同特征融合效果较差,以及无法捕获特征依赖关系和单词强语义信息的问题,本文提出一种基于交互式特征融合的嵌套命名实体识别模型。通过引入多头注意力机制学习句子长距离依赖关系,从而得到深层语义信息。采用二元序列标注法过滤非实体词,降低时间消耗。实验结果表明,本文模型能有效提取句子的深层语义信息。下一步将引入BERT 预训练模型,对实体与词语之间的关系以及边界信息获取方式进行研究,增强模型识别效果。
