基于联合Q 值分解的强化学习网约车订单派送
2022-12-13黄晓辉张雄杨凯铭熊李艳
黄晓辉,张雄,杨凯铭,熊李艳
(华东交通大学信息工程学院,南昌 330013)
0 概述
随着移动互联网技术的发展以及智能手机的普及,依托移动互联网平台的共享经济在各个行业逐渐涌现,并对人们的生活方式产生较大的影响。在交通出行领域,研究人员提出基于网约车平台的多种新型出行方式。文献[1]介绍网约车平台通过整合乘客与网约车之间的供需信息使其相匹配。网约车平台可以提高当前的交通效率,当乘客用智能手机设置目的地时,平台可自动采用智能方法匹配可用车辆。由于订单派送结果直接影响平台收入及乘客舒适度,因此订单派送问题也可以类比为PDP(Pickup and Delivery Problem)问题,其关键是将订单与可用车辆进行合理匹配。因此,通过合适的匹配方法来派送订单,使车辆的总行驶距离和用户的等待时间最小化,并增加司机的收入。
高效的订单派送和空间扩展性是构建智能派单系统的关键。如果一辆汽车绕道去接送客户,并且在接送过程中,司机还需考虑堵车问题,用户的总出行时间就会延长。文献[2]根据出行路径,将网约车与订单进行匹配,利用强化学习对司机的出行路径进行决策,同时,通过训练历史出行路径,提高出行效率,增加司机收益。但是该方法存在一定的局限性,在训练历史出行路径数据时仅考虑网约车到乘客初始位置的状态,因乘客出行会改变驾驶员的位置,导致网约车司机的未来收益减少。对于空间扩展性,文献[3]提出基于深度强化学习的网约车重定位原理,提前将网约车进行需求调度,考虑到一次性优化整个网约车平台的复杂性以及不同规模城市之间供需情况的差异,通常会划分自然地理边界来解决订单派送问题。由于每个城市具有不同的规模和交通模式,因此在网约车平台上为每个城市构建新的模型。
本文结合深度神经网络与多智能体强化学习(MARL),在基于联合Q值函数分解的框架VFD 下,提出两种方法ODDRL 与LF-ODDRL,使乘客整体等待时间最小化。通过将订单派送建模为分布式决策问题,具有集中训练、分散执行策略的优点,同时设计基于动作搜索的损失函数,将订单高效地与网约车司机相匹配,提高模型在不同规模网格上的可扩展性。
1 相关工作
1.1 基于组合优化的PDP 方法
网约车订单派送体系结构如图1 所示。车辆与订单的合理匹配是网约车平台中的一项重要决策任务。文献[4]考虑为每个订单找到最近司机。文献[5]通过网约车平台给司机发送虚拟订单,使网约车提前调度到未来乘客可能多的地方,满足更多乘客的需求,提高司机收益。文献[6]使用人工编写的函数来估计出行时间和用户等待时间。文献[7]提出新型双特征协同转换器,通过新的循环位置编码方法嵌入车辆位置特征,使用Transform 设计有效的车辆路径解决方案。文献[8]提出基于自注意力机制的深层架构,并将其作为策略网络来引导下一个动作的选择,解决旅行商路径最短问题。文献[9]提出基于集中组合优化的新模型,该模型在短时间内将订单并发匹配多个车辆。但是上述方法大多需要计算所有可用的车辆派送订单,并对每个城市构建新的模型,难以用于大规模的网约车订单派送,扩展性较差。
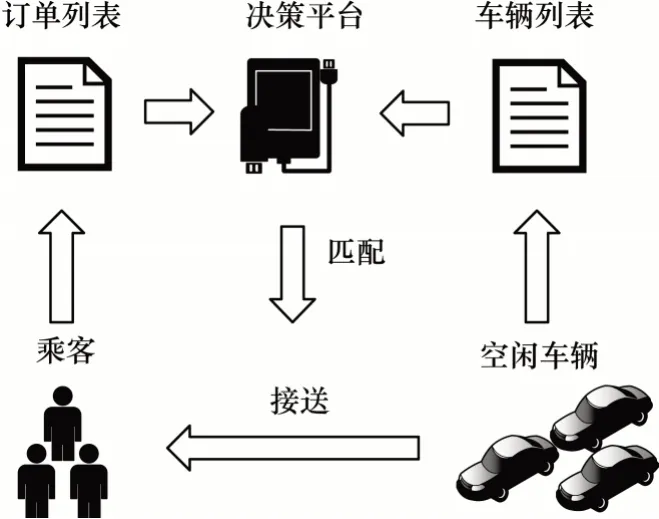
图1 网约车订单派送体系结构Fig.1 Structure of online car-hailing order dispatch system
1.2 基于强化学习的PDP 方法
文献[10]描述了PDP 问题如何从一个组合优化方法发展到一个包含半马尔可夫决策过程(Markov Decision Process,MDP)模型的深度强化学习方法。文献[11]将神经网络与异构注意力机制相结合,增强深度强化学习中的策略,侧重关注乘客的上车位置,该策略期望寻找网约车订单派送问题中的最优解。文献[12]利用model-free 强化学习来解决最优解问题,通过与复杂环境交互来学习策略。文献[13]将某一个区域的司机视为具有相同状态的智能体,简化了大规模订单派送场景中的随机供需动态。文献[14]考虑对异构车队约束的车辆选择解码器和基于路由结构的节点选择解码器,通过在每一步自动选择车辆和节点来构建解决策略,使得车辆的总行驶时间最小化。文献[15]通过深度强化学习理论对智能体的路径规划策略进行改进,文献[16]基于知识迁移学习方法,通过深度神经网络估计驾驶员的状态动作值函数,利用训练历史数据来达到跨多个城市的模型迁移目的。文献[17]提出一种新的方法,将多智能体强化学习转化为两个智能体不断交互的过程,使其在大规模智能体中更好地学习策略。文献[18]基于独立DQN 的方法学习分散的价值函数。文献[19]基于深度价值网络的批量训练方法来学习时空状态值函数,通过基于价值的策略搜索,将规划和引导与价值网络相结合,按需生成最优的重新定位行动。
在上述方法的基础上,本文基于VFD 框架来解决订单派送问题,VFD 框架由联合动作价值网络、独立动作价值网络、状态价值网络组成,并且为每个神经网络定义合适的损失函数,实现集中训练和分散执行的优势策略[20]。
2 问题陈述
针对在线网约车平台管理大量PDP 问题,本文对空闲车辆和订单进行高效匹配。PDP 问题属于经典网约车管理问题的一个变种[21]。网约车订单派送示意图如图2 所示。本文使用四边形网格表示地图,地图中的节点对应不同路网的交叉点,它们之间的边对应于不同的道路。车辆和订单随机出现在每个网格上,每条道路上都有相应的成本,该成本对应一辆车穿过道路的时间。成本包括不同交通条件在内的因素,如天气、节假日等,由环境决定,不能人为的定义。

图2 网约车订单派送示意图Fig.2 Schematic diagram of online car-hailing order dispatch
本文将网约车订单派送问题建模成MDP。智能体是从驾驶员的角度定义。完整的行程转换包括订单派送、订单接受和完成。网约车平台对空闲司机进行订单派送,司机接受订单并前往乘客初始位置,把乘客带到目的地,完成订单。司机在行程转换中立即获得奖励,即路费。本文把司机的一次闲置运动视为一次零奖励运动,定义MDP 的关键要素G=(N,S,A,P,R,γ),分别表示车辆的数量、状态集合、联合动作空间、状态转移概率、奖励函数、折扣因子。
1)状态St。状态输入表示为一个三元素元组,即S=(l,t,1)元组中的元素,分别表示车辆的起始经纬度、时间、接单成功。
2)动作at。对司机的一段特定行程进行分配,它简单由行程起始地点和下车时间定义。设当前S0=(l0,t0,0)为分配行程时司机位置、时间和车辆空闲,S1=(l1,t1,1)为上车地点、时间和接单成功。因此,动作a=(l,t)。所有符合条件动作的空间用A表示。
3)奖励r。奖励函数在强化学习中非常重要,它在很大程度上决定了优化的方向。网约车通过接受订单到将乘客送到目的地完成订单,从而获得奖励。本文设计一个与每个订单的花费成比例的奖励函数,在每个单位时间步长中即时奖励序列的总和表示为Rt=rt+1+γrt+2+…+
4)动作价值函数Q(s,a)。司机采取动作时将获得累计奖励,直到一个时间步长结束。Q(s,a)=
5)策略π(a|s)。π(a|s)是一个将状态映射到动作空间或特定动作上的分布策略。学习型Q(s,a)的贪婪策略由π(s)=argmaxQ(s,a)得出。
6)状态值函数V(s)。如果司机从开始遵循策略,将获得预期累计奖励,直到时间步长结束。策略π假设使用了Q函数的贪心策略,状态值V(s)=
3 基于联合Q 值分解框架
网约车平台要实现高效的订单匹配,需要对外部环境有一个基本认识,主要包括订单的位置信息、时间等,综合考虑车辆当前状态的即时奖励和下一个状态的长期价值,通过最优策略函数选择最佳动作。VFD 架构的核心思想是将原有的联合动作值函数转化为拥有最优动作的新函数。在t时刻,某区域的车辆最优联合动作相当于每辆车的最优动作集合,在集中训练阶段易于因式分解的分布式决策任务的执行。
对于联合动作价值函数Qj:SN×AN→R,其中a∈AN是一个历史联合动作,如式(1)所示:

3.1 整体结构
VFD 框架克服现有方法中联合动作值函数分解的可加性和单调性的约束,能够分解所有可分解的任务。联合Q值分解函数的框架如图3 所示,该框架由3 个独立的网络构成:1)独立动作价值网络,主要是通过神经网络获得在t时刻某区域内每辆车的动作值Qi(si,ai);2)联合动作价值网络,主要是通过隐藏特征得到在t时刻某区域内车辆的联合动作值Qj(s,a);3)状态价值网络,用于弥补联合动作价值网络学习到的动作值Qj(s,a),并与通过独立动作价值网络得到所有车辆动作值之和Q'j(s,a)的差距。通过对3 个神经网络进行集中训练,每辆车在分散执行期间使用自己因式分解的独立价值函数Qi采取动作。

图3 联合Q 值函数分解的框架Fig.3 Framework of joint Q-value function decomposition
3.1.1 独立动作价值网络
对于每辆车,独立动作价值网络根据其自身的历史观察si输入,并将产生的动作值Qi=(si,ai)作为输出。通过计算给定的动作值来确定动作,如式(2)所示:

其中:Q'j为所有车辆的动作值之和;Qi(si,ai)为每辆车的动作值。
3.1.2 联合动作价值网络
联合动作价值网络的Qj值用于近似所有车辆的动作值之和,将车辆所选动作作为输入,生成所选动作的Q值并作为输出。为了提高网络的可扩展性和训练效率,联合动作价值网络的设计是通过所有车辆独立动作价值网络确定的动作来更新联合动作价值网络。联合动作空间N是复杂的,随着车辆数的增加,寻找最优动作能提高复杂度,而独立动作价值网络通过线性时间的个体最优动作的分散策略,获得最优动作。联合动作价值网络共享独立动作价值网络的底层参数,并且结合独立动作价值网络的隐藏特征这些共享的参数可用于扩展训练。
3.1.3 状态价值网络
状态价值网络通过计算标量状态值Vj,用于弥补与真实学习到的Qj(s,a)之间的差距,如果没有状态价值网络,部分可观测性将限制Q'j的复杂性,状态值与给定状态s的选定动作无关。因此,状态价值网络不利于动作的选择,而是用于计算式(3)和式(4)的损失值。与联合动作价值网络相同,使用单个网络的组合隐藏特征作为状态价值网络的输入,以提高空间扩展性。
定理1联合动作价值函数Qj(s,a)被Qi(si,ai)分解,如式(3)和式(4)所示:

3.2 损失函数
集中训练有2 个主要目标:训练联合动作价值函数,计算真正的动作价值;转化后的动作价值函数Qj应近似联合动作价值函数,它们的最优动作是等价的。本文使用DDQN 方法来更新网络[22],设计全局损失函数,将3 个损失函数加权组合,如式(5)所示:
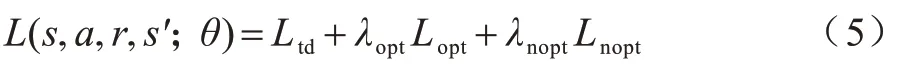
其中:r表示在智能体观测环境执行动作a后,状态s转换到下一状态s'所获得奖励;Ltd表示估算实际动作价值的损失函数,通过学习Qj使误差最小化;Lnopt和Lopt表示满足式(3)和式(4)的因式分解损失函数,Lnopt的作用是验证在样本中选择的动作是否满足式(4),则进一步确认Lopt得到的最优局部动作是否满足式(3)。因此,本文通过定义损失函数来实现式(3)和式(4),根据网络对样本中所采取的动作是否满足式(3)或式(4),但是这样验证式(3)和式(4)所得到的动作将需要过多的样本。由于在训练中很少采取最优动作,因此本文VFD 框架的目标是学习Q'j和Vj对给定的Qj进行因式分解,在使用Lnopt和Lopt进行学习时,通过修正Qj使学习更加稳定。λopt和λnopt是2 个损失的权重常数,损失函数如式(6)~式(8)所示:

在上述3 个损失函数中,Ltd使用标准时序差分TD-error 来更新需学习的联合动作值Qj(s,a),Lopt和Lnopt通过Qj(s,a)来引导独立动作值之和(s,a)与标量状态值Vj(s)的更新。
根据式(4),在ODDRL 中通过独立动作价值函数Qi和状态价值函数Vj来更新联合动作值Qi,导致神经网络无法准确地构建Qi因式分解函数。式(4)条件可能会影响非最优动作,从而降低训练过程的稳定性或收敛速度。在此基础上,本文提出另一种方法LF-ODDRL,如定理2 所示。

ODDRL 算法流程如下:
算法1ODDRL 算法

4 实验结果与分析
4.1 模拟平台
与有监督学习问题相比,多智能体强化学习的交互性给训练和评估带来更多的困难。常见的解决方案是建立环境模拟器[23-24]。模拟器作为多智能体强化学习方法的训练环境,以及它们的评估器,是整个训练和学习的基础。文献[25]通过训练真实的历史数据产生模拟订单。在本文实验中,使用文献[26]的模拟平台模拟订单的生成,实现分配订单的过程。根据每辆网约车在平台上第一次的位置和时间进行初始化,驾驶员随后的动作由模拟器决定,如进行空闲移动或者离线/在线操作。模拟器经过仔细校准,对比模拟数据与真实数据,使两者的误差在允许范围内。
在基于网格模拟器中,将城市定义为图2 所示的一张四边形网格的地图。在每个时间步,模拟器提供一个环境、一组空闲车辆和可用的订单。所有模拟订单与真实订单都具有相同的属性。为了提高模拟器的效率,每个乘客通过相同的网络同时计算动作值。因此,这个网络的输出是一个矩阵,其行表示乘客,其列表示每个乘客可以匹配的车辆。(i,j)的矩阵值是第i名乘客和第j辆车匹配的动作值,每个乘客与列表中Q值最大的车配对,使得奖励最大化,并且乘客的等待时间最小化。模拟器训练过程示意图如图4 所示。
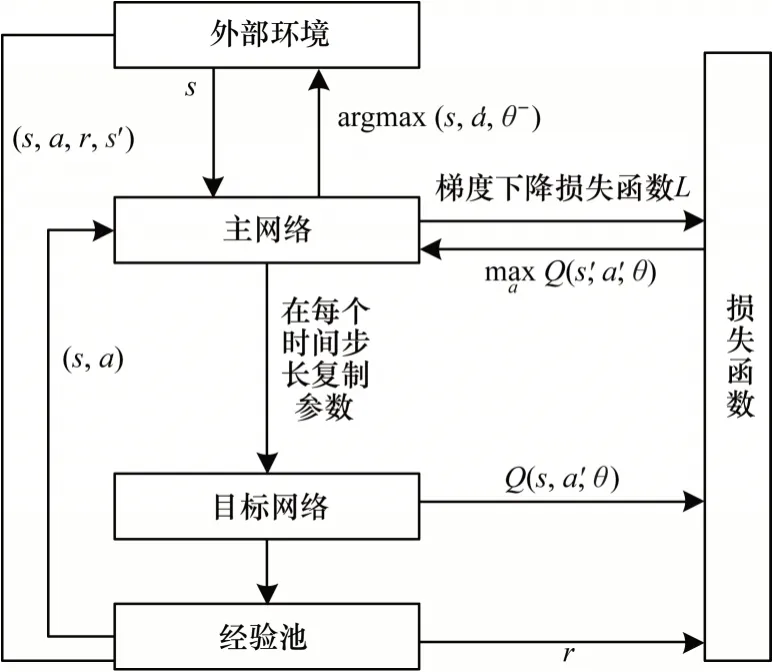
图4 模拟器训练过程示意图Fig.4 Schematic diagram of simulator training process
4.2 实验结果
为了分析方法的性能,本文采用Random、Greedy、DQN 和QMIX 作为基线方法。
1)Random:模拟没有任何订单派送的场景,只在每个时间步长随机分配闲置订单,并随机派送给网约车。
2)Greedy:贪婪方法被作为基线方法,并将其与各种强化学习方法进行对比。贪婪方法遵循先到先得(FCFS)策略。因此,较早要求用车的乘客会获得更高的优先权。每个乘客根据距离(曼哈顿距离)配对到一辆车。
3)DQN:文献[27]提出一种基于Q 学习网络的动作价值函数近似方法,该网络的参数化是由一个具有4 个隐层的多层感知机(MLP)组成,隐层之间采用ReLU 激活函数激活,并对Q 网络的最终线性输出进行转换,使得车辆与环境之间进行局部交互,从而捕获全局的动态需求与供应变化关系。
4)QMIX:考虑了全局状态,将联合动作价值网络函数分解为独立价值函数并进行分散执行[28],使联合动作值最大化的联合动作等于使独立动作值最大化的一组动作。全局状态动作值允许每辆车贪婪地选择与它们独立动作值相关的动作。
为了测试ODDRL 和LF-ODDRL 方法在订单派送中的有效性和鲁棒性,本文在不同的网格、乘客数量和车辆数的情况下进行3 组实验,所提方法在整体上都优于其他方法。如QMIX 方法能够分解联合动作价值函数,确保全局最优动作和局部最优动作的一致性,使得动作值最大化,但是通过神经网络学习全局与局部之间的关系,确保全局动作值与局部动作值的单调性,仅解决了小部分可分解任务的问题。因此,该方法存在一定的局限性问题。本文方法克服了联合动作值分解可加性和单调性的约束,以确保联合动作和独立动作是相同的,从而提高学习效率和扩展性。
本文将网约车和乘客数量设置为固定的,在100×100 的网格上,使用把所有乘客送达目的地所持续的总时间作为评判指标,6 种方法的总时间对比如表1 所示。P和C分别表示在固定人车网格中每回合初始的乘客数量和车辆数量,当P=7,C=2 时,ODDRL 和LF-ODDRL 两种方法相对于QMIX 接送乘客持续总时间分别减少了6%和18%,当有大量车辆和乘客时,如P=25,C=20,持续总时间分别减少了10%和18%。实验结果表明,本文方法能有效解决网约车不足和充分问题。
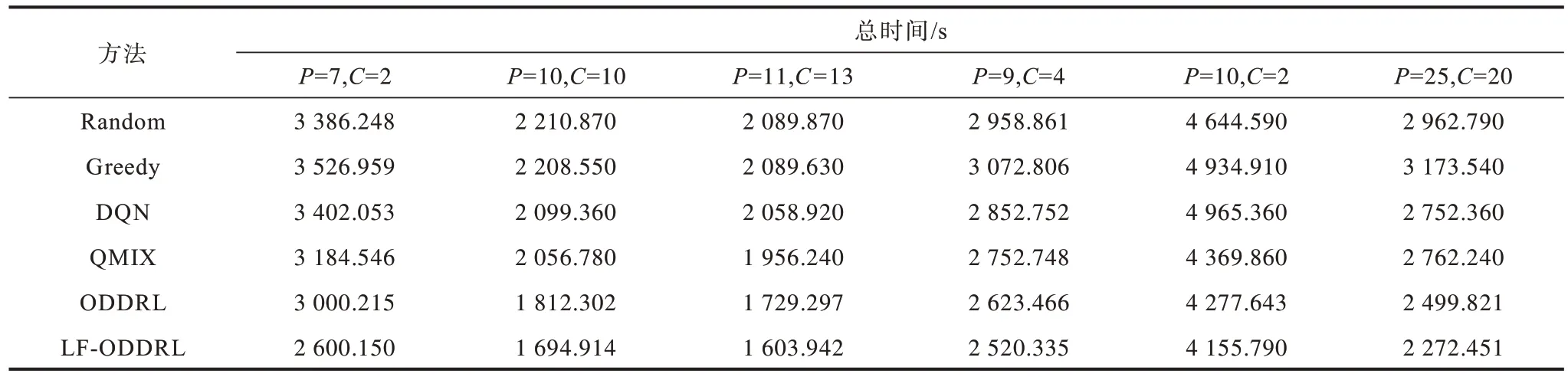
表1 在100×100 网格上不同方法接送乘客的总时间对比Table 1 Total time for picking up passengers comparison among different methods on 100×100 grid
为进一步衡量方法的可伸缩性,在10×10 和500×500 网格上,不同方法接送乘客持续总时间随网约车和乘客数量的变化曲线分别如图5 和图6 所示。其中Random、Greedy、DQN 方法都是针对单个智能体,并没有联合所有智能体集中训练和分散执行的策略,因此,其结果并不理想。QMIX 方法虽然考虑集中训练和分散执行的策略,但是需联合动作值和独立动作值呈现单调性,阻碍了对非单调性结构动作值函数的学习。而本文方法却弥补了这些缺点,不仅联合车辆共同学习,还针对不同规模的网格构建ReLU 激活函数和训练订单派送的策略Q 网络,并且设计新的损失函数来缩小(s,a)与Qj(s,a)的差距。实验结果表明,ODDRL与LF-ODDRL 都优于其他4 种基线方法,说明本文方法具有较优的扩展性。
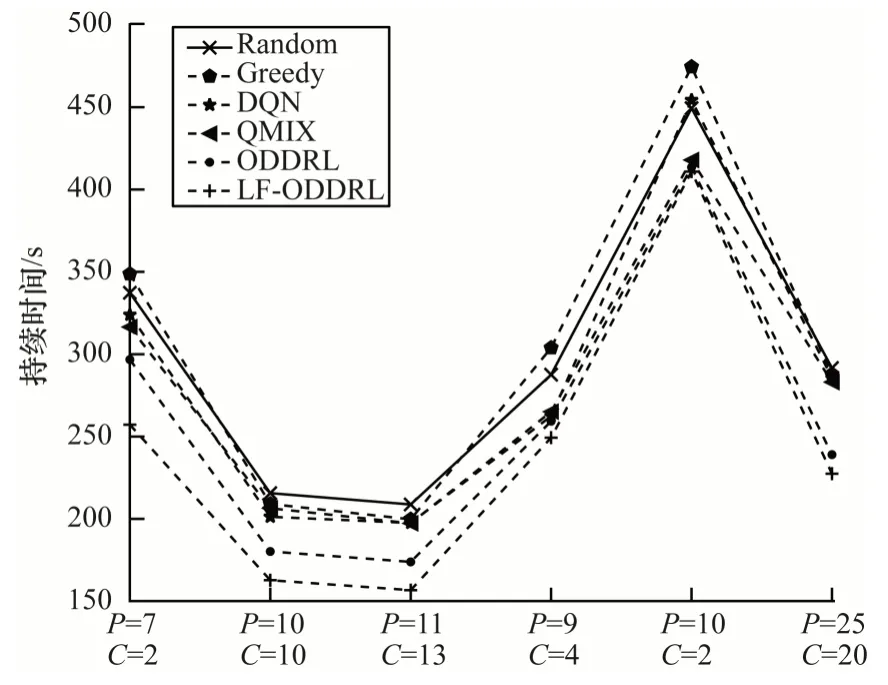
图5 在10×10 网格上不同方法接送乘客的总时间对比Fig.5 Total time for picking up passengers comparison among different methods on 10×10 grid
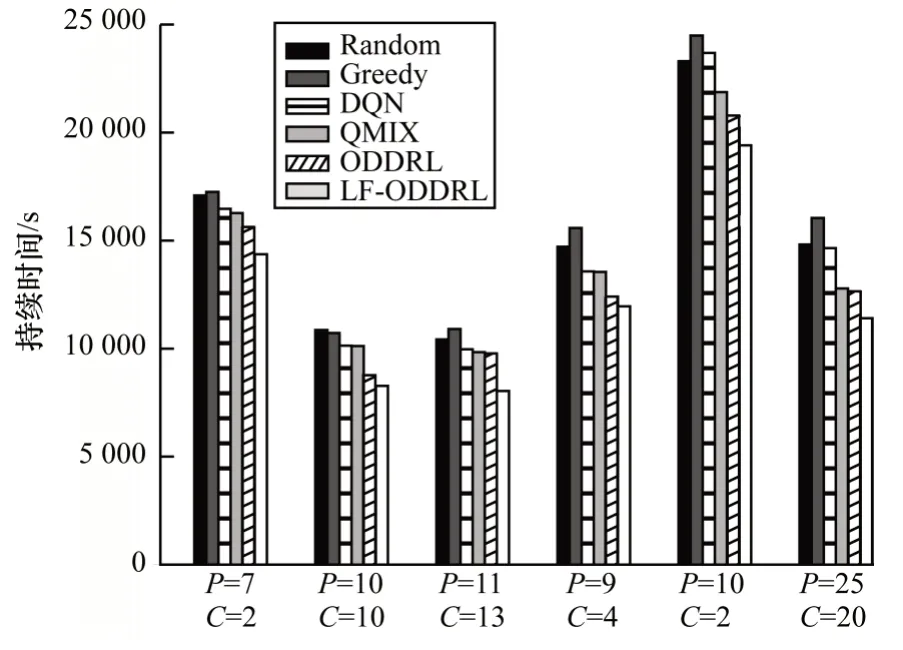
图6 在500×500 网格上不同方法接送乘客的总时间对比Fig.6 Total time for picking up passengers comparison among different methods on 500×500 grid
在10×10 和500×500 的网格上,本文给网约车和乘客数量分别设置域值,并进行训练和测试,接送乘客所持续的总时间如表2 所示。在500×500 的网格上,当最大乘客数和车辆数都为20 时,ODDRL 与LF-ODDRL 相对于QMIX 接送乘客所持续的总时间分别减少了2%和12%,说明VFD 在应对可变的乘客数和车辆数时,具有更强的学习能力,以更好适应可变的环境。
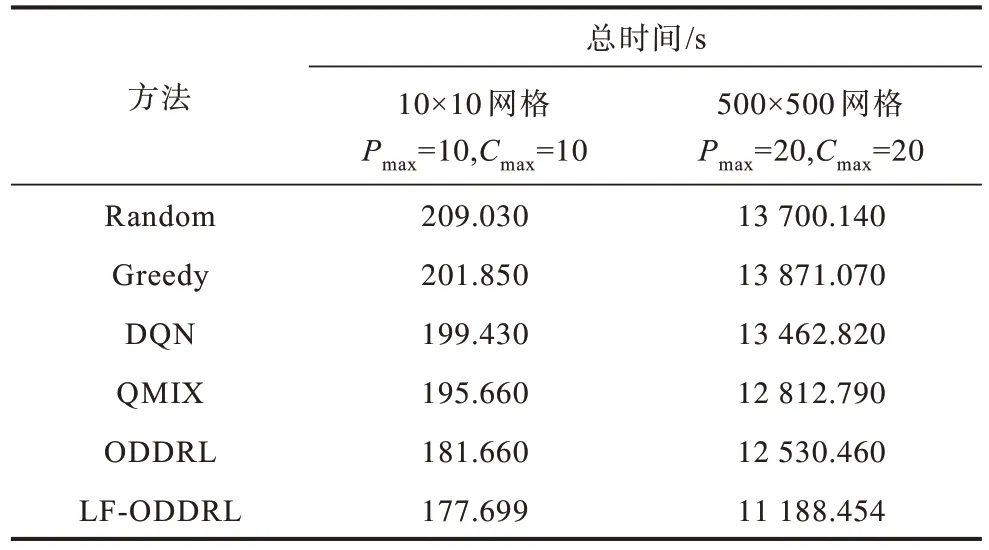
表2 不同方法接送乘客的总时间对比Table 2 Total time for picking up passenges comparison among different methods
为验证本文设计动作搜索损失函数的有效性,本文在10×10 网格P=7,C=2 的条件下进行实验。不同方法的损失值对比如图7 所示。本文设计的损失函数是从当前的Q 网络中找出最大Q值对应的动作,利用这个选择的动作在目标网络中计算目标Q值。从图7 可以看出,LF-ODDRL 的收敛速度和效果都优于ODDRL 方法。
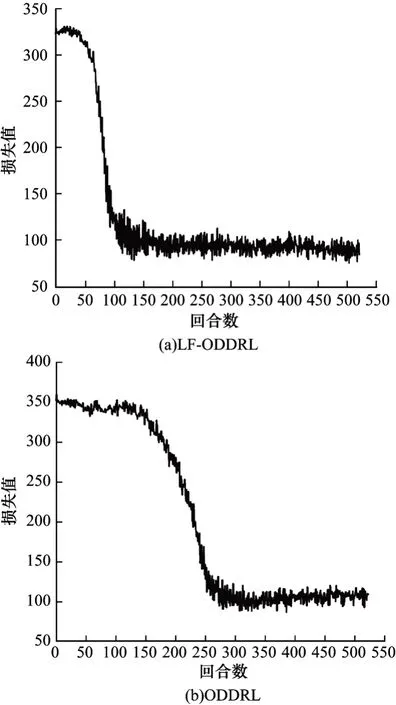
图7 不同方法的损失值对比Fig.7 Loss values comparison among different methods
5 结束语
本文基于VFD 框架提出多智能体强化学习方法ODDRL 和LF-ODDRL,用于解决PDP 问题。将订单派送建模为一个分布式决策问题,把初始的联合动作值函数分解为多个独立的值函数,使联合动作值函数中的动作与独立动作值函数中的动作相一致。将每辆车以分布式的方式执行动作,通过集中训练和分散执行的方式确定车辆与订单之间的最佳匹配关系,达到优化平台长期运作效率的目的,同时最大程度缩短接送时间,提高乘客舒适度。实验结果表明,相比Random、Greedy、DQN 等方法,ODDRL 和LF-ODDRL 能够有效缩短接送时间,在不同规模网格上具有较优的扩展性。后续将原始车辆GPS 数据与乘客的个人偏好及其目的地距离相结合,最大化缩短接送时间,从而提高乘客和司机的出行效率。
