基于引导信息的双目立体匹配算法
2022-12-11魏东,何雪
魏 东,何 雪
(沈阳工业大学 信息科学与工程学院,辽宁 沈阳 110870)
0 引 言
深度信息是自动驾驶、机器人、物体检测等计算机视觉应用中非常重要的信息。通过对双目立体相机拍摄得到的两个图像进行立体匹配,计算参考图像的稠密视差图,是获取深度信息的重要途径之一。
Zbontar和LeCun首次将CNN应用到立体匹配中,利用卷积神经网络(MC-CNN)[1]计算匹配代价。FlowNetC[2]、DispNetC[3]等算法将立体匹配通过端到端的有监督深度学习方式实现,采用编码-解码的结构回归视差。文献[4-5]利用从边缘检测任务中获得的边缘信息补充视差图中丢失的细节信息。SegStere[6]将语义特征融入特征图中,并设计语义损失项来改善视差学习效果。
近年来,注意力机制在许多计算机视觉任务中也得到了广泛的应用[7-11],将注意力机制应用在立体匹配任务上,可以有效捕捉图像中有用的区域,从而提升立体匹配算法性能。PASMNet[12]中的视差注意力机制(Parallax-Attention Mechanism,PAM)针对固定的最大视差阻碍了具有较大视差变化的图像对在进行匹配代价计算时,由于差异回归的模糊性导致不合理的代价分配问题,采用将极线约束与注意力机制相结合,计算沿极线的特征相似性的方法来解决。
虽然基于PAM的立体匹配方法可以避免以上问题,仍然难以克服边缘处误差较大、视差不连续以及一些遮挡和弱纹理区域误匹配率较高的问题。
针对以上问题,提出在视差注意力机制上引入语义和边缘引导信息的立体匹配算法以提高匹配精度。
1 算法设计
为了解决立体匹配算法在物体边缘处和遮挡区域匹配精度较低的问题,在边缘处匹配误差较大的主要原因是卷积操作引起的细节信息丢失,可以引入边缘特征信息来弥补。在弱纹理和视差不连续区域匹配误差较大的主要原因是在这些区域上进行视差估计的匹配特征不足,可以通过语义分割获得更多的特征,如个体的语义一致性等特征,使得在弱纹理和视差不连续区域更好地实现特征匹配。算法整体网络结构如图1所示,包括边缘提取(Edge extraction)、特征提取(Feature extraction)、视差注意力机制(PAM)、语义信息提取(Semantic information extraction)、视差估计(Disparity prediction)、视差优化(Refinement)六部分。

图1 网络结构
该网络将左右图像送入VGG网络进行特征提取,获取不同尺度的图像特征,同时把左右图像送入HED[13](Holistically-nested Edge Detection)网络提取边缘细节信息。将经过特征提取得到的特征与边缘信息进行融合,送入PAM回归匹配代价,在特征中引入边缘细节改善由于遮挡使回归的视差图中物体边缘处误差较大的问题。PAM通过矩阵乘法计算匹配代价,得到视差注意力图,再利用输出模块回归视差注意力图得到初始视差图。把经过特征提取网络得到的最后1个尺度特征送入DenseASPP[14]网络得到语义特征图。将初始视差图和语义特征图级联送入沙漏型网络进行视差优化,融合语义信息改善弱纹理和视差不连续区域,得到最终的视差图。
1.1 基准网络
基准网络是PASMNet,网络结构如图2所示。左右图像经过沙漏网络特征提取,将提取的特征送入级联的视差注意力模块回归匹配成本,然后使用输出模块从匹配成本中获得一个初始视差。最后,利用沙漏网络进一步细化初始视差,以产生最后的视差图。

图2 PASMNet网络结构
PASMNet使用视差注意力计算匹配代价,与3D cost volume计算匹配代价不同的是:视差注意力是将极线约束与注意力机制相结合,沿极线计算特征相似性,如图3所示。具体来说,对于左图像中的每个像素P,在右图像沿极线上的所有像素中找到特征最相似的像素。
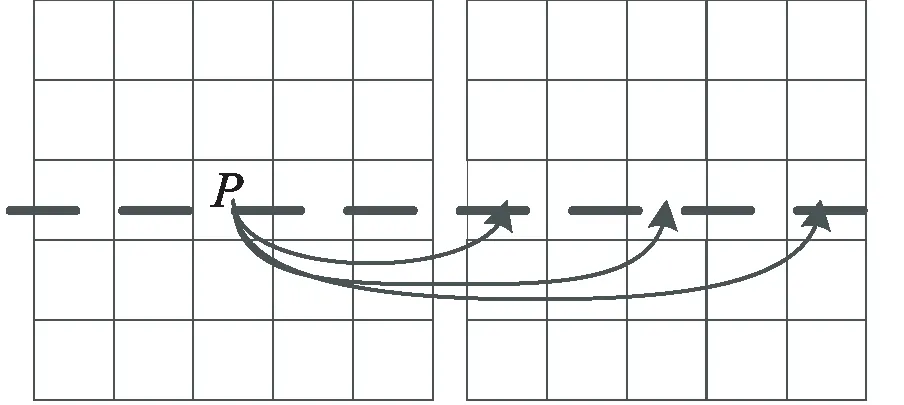
图3 视差注意力
PAM由3个视差注意力模块级联组成,每个视差注意力模块由4个相同的结构块构成,如图4所示。C为匹配代价表示两个像素之间的特征相关性,沙漏型网络提取的特征经过卷积层得到特征映射A、B∈RH×W×C,将A、B送到1×1卷积以进行特征匹配。具体来说,A送入1×1卷积以生成查询特征映射Q∈RH×W×C,同时B送入另一个1×1卷积中,生成一个关键特征映射K∈RH×W×C,再将其重塑为特征空间是RH×C×W的特征映射。然后,在Q和K之间执行矩阵乘法,通过矩阵乘法,可以有效地将沿极线的任意两个位置之间的特征相关性编码到视差注意力图中。
将级联的视差注意模块得到的匹配代价送到输出模块。输出模块如图5所示,其中匹配代价C首先被送到Softmax层,以分别产生通道数为1的视差注意力图M,对得到的视差注意力图回归计算得到初始视差,计算公式如公式(1):
(1)
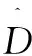

图4 视差注意力模块

图5 输出模块
1.2 特征提取
特征提取部分使用VGG网络,VGG网络可以产生丰富的多尺度几何信息特征,如图6所示。VGG网络可以获取多个尺度的特征,第1、2、3尺度特征用于视差注意力模块,第5尺度特征用于语义信息提取模块。
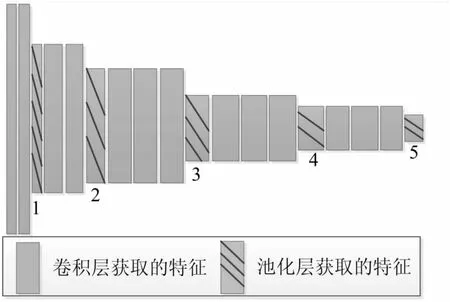
图6 VGG网络结构
1.3 边缘提取
边缘是由于图像中像素值发生较大变化而导致不连续的结果,它存在于目标与背景、目标与目标、区域与区域之间。针对立体匹配中边缘误差较大和遮挡问题,引入边缘细节可以得到改善。在深度学习出现之前,边缘检测有几种常用的方法,如Sobel、Canny等。传统的边缘检测算法到现在还在使用,但是过于依赖人工设定阈值,不能在通用场景下工作。
该文使用HED算法提取边缘,如图7所示。HED是以VGGNet与FCN作为基础网络进行改进,将VGG网络的多个特征层的输出,利用FCN全卷积网络,通过权重融合实现各个层相连接,得到边缘特征。

图7 HED网络结构
1.4 语义信息提取
针对立体匹配中视差不连续、弱纹理区域,引入语义分割获取的语义信息可以得到改善。使用深度学习方法之前,语义分割方法比较常用的是TextonForest和基于随机森林分类器等方法。现在很多使用深度学习进行语义分割的模型基本上都是由FCN改进的,但是FCN模型需要池化操作,池化操作可以通过扩大感受野进而能够很好地整合上下文信息,但通过池化进行下采样操作也使分辨率降低,削弱了位置信息,而语义分割中对齐操作需要丰富的位置信息。
该文使用文献[13]提出的DenseASPP算法提取语义信息,网络结构如图8所示,DenseASPP将ASPP和DenseNet中的密集连接相结合,具有更大的感受野和更密集的采样点。扩张卷积用于解决特征图分辨率和感受野之间的矛盾;用密集连接获得更好的性能,将每个扩张卷积使用密集连接的方式输出结合到一起。
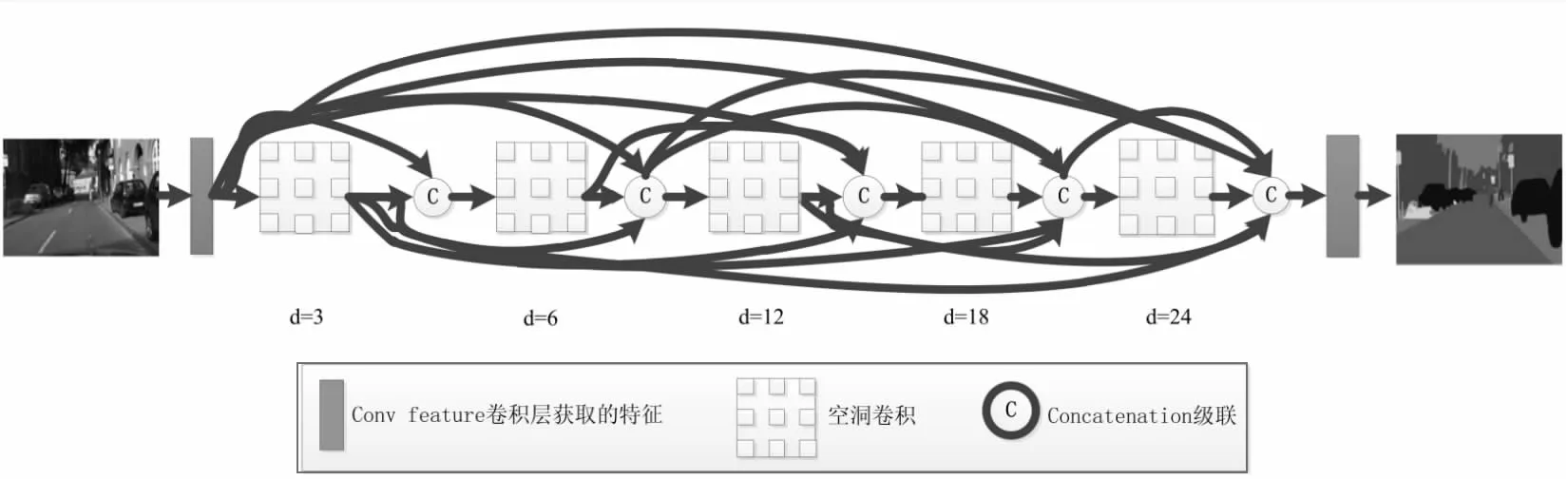
图8 DenseASPP网络结构
1.5 损失函数
使用Groundtruth视差数据在有监督学习的模式下对模型进行端到端的训练,为了更好地监督生成边缘清晰、物体表面平滑和语义明确的视差图,利用常规的视差回归损失。
对于视差回归,采用smoothL1损失函数来训练视差分支,与L2损失相比,smoothL1损失具有很好的鲁棒性和对异常值的低敏感性[15-16]。
损失函数定义如下:
(2)
smoothL1定义如下:
(3)

2 实验结果
2.1 数据集及评价指标介绍
将所提方法在SceneFlow[2]上进行评估。SceneFlow是一个大规模的合成数据集,包括分辨率为540×960像素的35 454组训练图像以及4 370组测试图像,且提供了稠密的视差图作为Groundtruth。使用端点误差(End-Point-Error,EPE),即预测视差图与实际视差图的平均绝对误差,和t像素(t-pixel,tpx)误差作为评价指标。
2.2 实验环境、参数设置及效果图
在SceneFlow数据集上训练网络。在训练阶段,将左右图像随机裁剪为256×512像素的图像作为输入。所有模型均采用Adam方法进行优化,批次大小为2。初始学习率设定为前5个epoch的1×10-3,后15个epoch的学习率降低到1×10-4。所有实验都是在NvidiaGTX1080 GPU的PC上进行的。图9分别为SceneFlow数据集中部分数据的左图、预测视差图和视差真值图。

(从上到下依次为输入左图、预测视差图、视差真值图)
2.3 消融实验、实验环境及效果图
特征提取:VGG网络可以获取多个尺度的特征,用于视差注意力模块和语义信息提取模块。VGG网络可以产生丰富的多尺度几何信息特征,可以实现更好的性能。
引入边缘信息:将边缘信息与特征提取的特征融合,引入到视差注意力模块中,对边缘信息融合特征位置进行实验。从表1中可以看出,将边缘信息与特征提取中池化后第1、2、3尺度特征融合与池化后第3、4、5尺度特征融合对比, EPE从2.614增加到3.809,1px/3px错误率从19.112/12.195增加到28.825/18.273。并在PAM网络上EPE减少了31.32%。因此,将边缘信息与池化后第1、2、3尺度特征融合引入PAM模块中可以取得更好的效果。引入语义信息:从特征提取中获取的不同尺度特征中选出一个特征送入语义信息提取模块提取语义信息,利用语义信息进行视差优化。对送入语义信息提取模块的不同尺度特征选取进行实验。从表1中可以看出,传入特征提取中池化后第5个尺度特征比池化后第1个尺度相比,EPE从2.685增加到2.711,1px/3px错误率从18.551/12.121增加到19.415/12.754。并在PAM网络上EPE减少了29.45%,因此,利用特征提取模块中第5个尺度的特征进行语义信息的提取,可以使得最终的视差估计取得更好的效果。

表1 SceneFlow消融实验
从表1中可以看到,在PAM网络上分别引入边缘和语义信息都可以降低错误率,提升网络性能。当边缘和语义信息同时引入时,EPE在PAM网络上提升了39.23%,实验证明引入边缘和语义信息可以有效提升网络回归视差图性能。
图10是不同网络结构得到的视差图对比,矩形框1处物体边缘、3处圆柱体边缘和5处耳机边缘在PAM+Edge网络得到的视差图对应位置与PAM网络得到的视差图对应位置对比边缘轮廓更圆滑且误差较小;矩形框2处长矩形与矩形框1处物体遮挡处在PAM+Edge网络得到的视差图对应位置与PAM网络得到的视差图对应位置对比边缘轮廓更清晰准确;矩形框2处长矩形和矩形框5处耳机在PAM+ Semantic网络得到的视差图对应位置与PAM网络得到的视差图对应位置对比内部视差相对统一、视差连续;矩形框4处的长方体和矩形框6处的处圆柱体由于弱纹理导致特征匹配有误的问题在PAM+Semantic网络得到的视差图也得到改善。而且在同时引入边缘和语义信息的PAM+Edge+Semantic网络得到的结果整体效果好于分别引入边缘和语义信息。通过可视化的结果可以更直接看到引入边缘信息得到的视差图边缘更平滑,降低边缘处误差,引入语义信息后视差图中视差不连续和弱纹理处效果有提升,这得益于边缘和语义信息的引入能指导生成更加精准的视差图。

(从上到下依次为PAM网络、PAM+Edge、PAM+Semantic、PAM+Edge+Semantic)
2.4 与其他算法比较
在SceneFlow数据集中的量化误差指标比较如表2所示。从表2中可以看出,文中方法与基准网络PASMNet进行对比,将PASMNet的误差降低了49.05%,相对于其他经典的匹配算法在计算端点误差时,误差率较小。
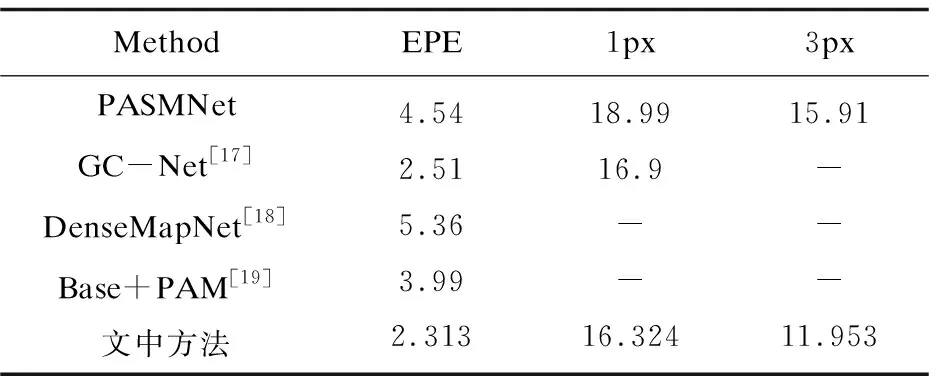
表2 SceneFlow测试结果
3 结束语
为改善立体匹配中边缘处的误差较大和遮挡、视差不连续、弱纹理等区域匹配精度不高的问题,提出一种在利用视差注意力机制进行立体匹配时引入边缘和语义信息的立体匹配算法。在利用视差注意力机制进行匹配代价计算过程中引入边缘信息,改善边缘处的误差较大、遮挡问题,以提高整体匹配精度;在视差优化过程中引入语义信息,改善视差不连续、弱纹理问题,以提高整体匹配精度。通过实验表明,该算法在SceneFlow数据集上将基准网络PASMNet[12]的误差降低了49.05%。该算法相较于基准方法虽然精度有所提升,但是需要大量的数据集进行训练,因此,在小数据集上的效果表现不好。在未来的研究中需要对网络结构进一步优化,可以考虑如何减小网络大小,这可能进一步改善视差的估计效果。
