基于知识提取的测试文档自动生成
2022-12-11孙晓韩杨子仪
孙晓韩,李 宁,于 杨,杨子仪,张 林
(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引 言
产品测试文档是一类特殊的文档,它记录产品测试活动留下的记录,并作为交付物,供产品的相关方使用,是产品的重要组成部分。这类文档的特点是与测试项目的数据有紧密联系,种类繁多内容复杂。此外,这类文档有严格的编制要求,存在大量的测试规范和文档编制规范[1-2]。文献[3]总结了软件文档编制的四方面要求:(1)准确性:产品文档描述的内容要与实际情况保持一致,并反映产品的最新更新;(2)完整性:产品文档中能够系统、详尽地描述产品所提供的全部功能;(3)及时性:产品文档可随时按需获得;(4)可用性:文档可以指导目标用户高效地完成工作。这些要求对于其他种类的文档编制也是必要的。
文档的计算机辅助编制技术,特别是软件产品的文档编制技术研究已有很长的历史[4-5]。以往的计算机辅助软件文档编写手段主要有:(1)通过办公软件、Dita[6]等写作工具或手工编写或填充模板;(2)通过 MarkDown[7]、reStructedText[8]等工具辅助,在软件开发过程中对代码进行标记,自动化地或半自动化地生成文档;(3)使用软件工具自动记录数据并生成文档;(4)开发专用的文档编写软件。这些文档编制方法都存在各自的优缺点。
首先第一种方法编写的文档可读性较好,但是主要依靠人工,费时费力,难以做到与系统同步更新;第二种方法能够做到与系统同步更新,但是需要进行大量的标注,带来额外的负担,且生成的文档类型有限,可读性较差;第三种方法自动化程度较高,但需要完善的软件工程环境的支持,一般工具形成的文档难以做到规范和全面,且难以进行灵活定制;第四种方法需要为不同的项目开发文档系统,而今天人们更希望以“低代码”的方式适应产品的变化。此外,当前大部分文档都是静态的,难以按需展现数据内容或实现交互式的信息检索。
当前随着软硬件开发技术的快速演进,以往的文档编制过程也显得低效而难以适应需要。以测试文档为例,软件测试是软件工程的重要环节,其主要产物是测试文档。测试文档要反映测试过程的活动,包括测试计划、测试需求、测试流程、缺陷跟踪和记录,等等。特别是大型软件测试经常包含成千上万个测试用例,记录这些测试案例和测试结果,使得测试文档的编写工作量很大。另一方面,敏捷开发方法和DevOps[9]的应用,强调持续集成(Continuous Integration,CI)和持续交付(Continuous Delivery,CD),使得传统的测试文档编制过程难以适应,一方面频繁的迭代和更新导致文档延迟交付,另一方面找不到掌握全面信息的文档编制人员,文档的开发成为了影响项目进展的瓶颈。
随着近年人工智能和自然语言处理技术的发展,计算机辅助写作技术逐渐成熟。广义的计算机辅助写作(Computer Aided Writing, CAW)以数据和知识为基础,将知识管理与认知技术相结合,辅助人工完成文档的编写[10]。在CAW中,数据到文本的生成(Data to Text,D2T)技术与该文关系较大。目前该领域已经取得了较多的研究进展,业界已经研制出面向不同领域和应用的多个生成系统,如基于数值数据生成天气预报文本[11]、体育新闻[12]、财经报道、医疗报告等[13]。数据到文本的生成技术一般包括以下阶段:数据的分析和理解,文本的规划以及遣词造句[14]。
测试文档的编写也可以看作是从测试记录和测试数据生成测试报告文本的过程。数据到文本的生成技术可以为之提供很好的借鉴。例如,可以基于测试规范构建测试过程的知识本体,通过对测试数据的分析,将其映射到知识本体,形成知识表达,然后借助测试文档模板和内容生成规则,最终生成测试文档。此外,可以借助CAW的动态模板技术和复合出版[15]的特点,在遵循测试文档编写规范的前提下,根据数据的形态个性化地展现报告内容。例如,对于重复的测试项,自动形成子章节内容,对于统计数据,根据需要展现成表格和图表,或借助智能标记和插件对测试结果进行检索。
综上,针对文档编制过程中的低效问题,该文按上述思路提出一种基于知识提取的测试文档自动生成方法,其可以实现测试文档的自动生成,有效提升了现实中软件产品测试的智能性、可复用性以及自动化程度。
1 测试文档生成方法及模型设计
该文的目标是为计算机产品的质量测试开发测试数据管理与测试文档生成系统。希望能够支持多类软件的测试,能够对测试结果进行语义检索,能够跨平台运行,能够保持测试文档的实时更新。经过调研得知,在计算机产品的质量测试中,一个被测系统一般由多部分子系统构成,每个部分均按多个测试项、多个指标和多轮次测试开展测试,有一套预先设计的电子表格文档用于记录测试数据,不同类型的被测产品对应不同的电子表格记录。一个中等规模的测试项目大约包含50张电子表格,500多项测试数据,一个复杂系统的数据量会数倍于它。可见数据的规模和复杂程度是很高的。一个典型的记录测试数据的电子表格局部如图1所示。

图1 一个典型的记录测试数据的电子表格(局部)
一般的测试文档自动生成系统会简单建立电子表格单元格到测试文档模板中标识项的映射,通过模板填充生成测试文档[16]。但是这样处理会存在多个问题:(1)无法对测试数据进行有效的管理和后续利用,例如对测试结果进行动态查询;(2)深度依赖被测的产品的种类,如果换一种产品则需要重新编程,无法达到“低代码”的目标;(3)缺少灵活性,记录测试数据的电子表格一旦结构发生变化,将需要重建映射。
笔者认为,要改进上述问题,需要一种有效的方式来管理测试数据。由于测试数据记录与具体的被测产品相关,灵活多变,要将其体现在标准的测试文档内容中,构建的流程如下:
第一步:对不同类型产品的测试数据进行分析和知识提取,得到测试结果的结构化语义表示;第二步:将提取后的测试结果结构化表示映射到通用的测试本体,形成稳定、通用的知识表示并加以存储;第三步:构造知识本体到测试文档的映射关系,将测试结果通过模板填充或格式转换形成测试文档。其中,第一步对应D2T的数据理解过程;第三步对应D2T的文本规划和遣词造句过程;其中第二步是该文特有的。在自然语言处理中,D2T生成的是自由的文本,不需要特定的结构和格式约束,而测试文档需要符合相关的编制规范,对于不同的产品测试类型,测试文档的撰写方式是基本一致的,因此需要对测试结果进行规范化的表示并保存到测试知识库中。

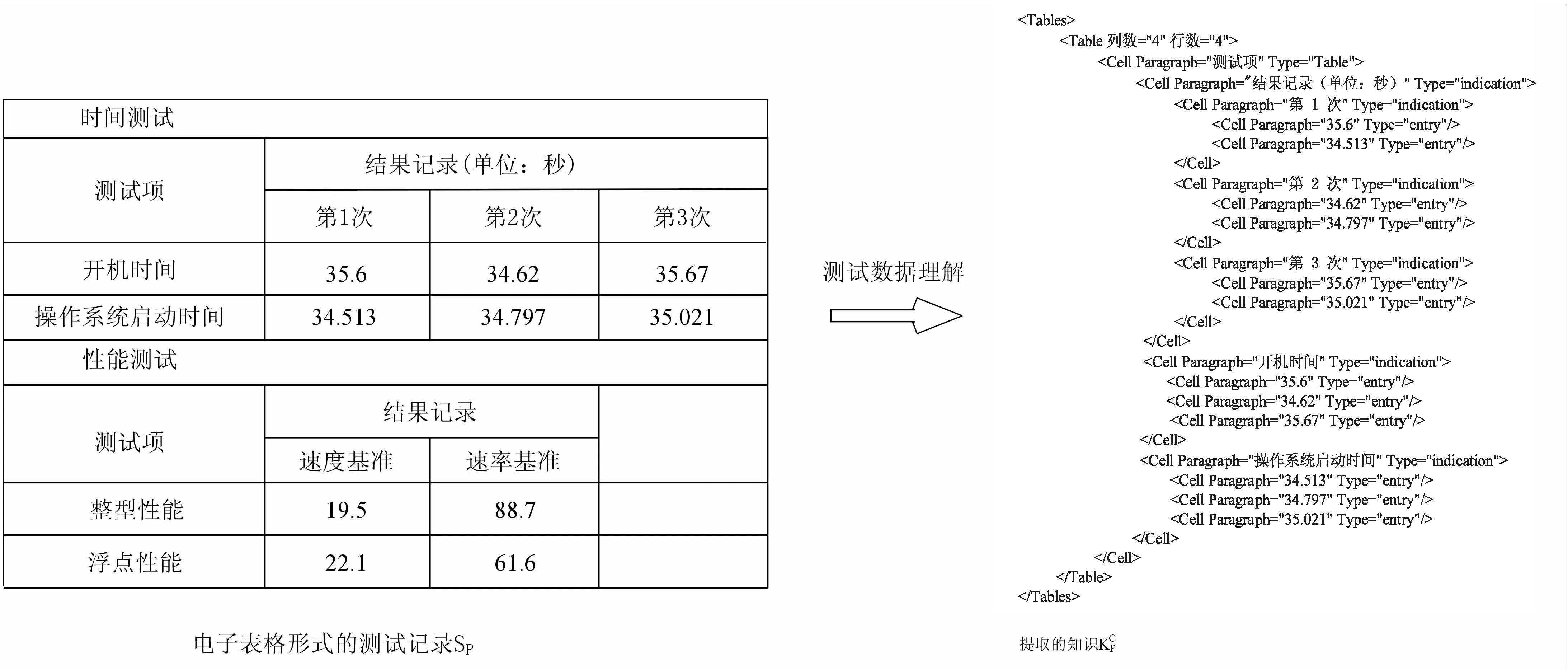
图2 测试文档生成过程(1)

图3 软件文档生成过程(2)
2 测试数据理解与知识提取

大量的电子表格中的测试数据是以非关系型的方式记录的,例如,图1中有多个表格嵌套,不符合关系型范式。因此需要与之相适合的层次模型表示数据及其关系,XML数据显然是最好的选择。从自由设计的电子表格中提取出XML并非易事。例如,图1的电子表格并没有明确的与XML数据的对应关系。为此需要进行表格逻辑结构的识别,以获得测试数据的知识表示。
设计了以下的表格逻辑结构识别算法。
从逻辑结构来看,表格模板是由单元格集合C和单元格间关联关系集合R组成的一种数据存储结构。其中单元格集合C为:
C={c|c∈T1∪T2}
(1)
式中,T1={Header},T2={Data,HeaderData}。Data表示数据型单元格,在表格模板中,Data不含内容。Header表示表头型单元格,它是一种只含表头信息而不含数据信息的单元格。HeaderData表示表头数据型单元格,它既含表头信息,又能被填入数据。
单元格间关联关系分为两种:层次关系(表示为Hie)和指示关系(表示为Ind)。层次关系集合H为:
(2)
(3)

R=H∪I
(4)

图4 表格模板示例

(5)
如果所有单元格两两不重复组合形成的集合为P,则:
P=R∪N
(6)
由此可知,若要提取表格的逻辑结构,必须要确定表格的单元格集合C和单元格间关联关系集合R。其中,C的确立依赖于表头型单元格集合T1、其他单元格集合T2的确立,即表头型单元格的识别。并且,关联关系集合R是在已知T1、T2集合的基础上建立的,故表头识别是逻辑结构识别的首要任务。
该文构造了一种全连接神经网络分类器来区分Header和HeaderData。神经网络由输入层、隐含层和输出层组成,它依靠神经元内的激活函数构造输入与输出的非线性关系。全连接神经网络结构如图5所示。经验证,在表头识别任务中,隐含层采用ReLU激活函数比其他激活函数更能使模型快速地趋于收敛,所以在隐含层该文方法采用ReLU激活函数。在输出层,由于Softmax函数可以将多分类转化为概率,所以该文方法采用Softmax激活函数。此外,针对分类问题,交叉熵函数便于梯度下降反向传播,因此,采用交叉熵函数作为网络的损失函数。

图5 全连接神经网络的整体结构
为了在反向传播中降低交叉熵,需要以一定的力度调整网络参数。交叉熵与参数的偏导数指明了以多大力度调整该参数,以W11为例,经过一次反向传播后,它的新值Wnew11更新情况如公式(7)所示:
(7)
式中,ETotal为交叉熵,η为学习速率。经过多次反向传播,网络参数可以更新为最优值。
网络的配置参数如表1所示。其中Full为隐含层,η为学习速率。

表1 全连接神经网络的网络参数
在关联关系识别中,首先剔除绝对无关联的单元格对,然后基于规则将表格分割成较小的逻辑块,再应用 Siamese-BiLSTM 模型对其进行关联关系识别,并根据识别结果中相关联的单元格对,构建表格逻辑结构树。对应图1,识别出的逻辑结构树见图6。

图6 图1的表格逻辑结构识别结果(简化表示)
电子表格理解的具体算法详见文献[17]。
3 测试知识库构建
如前文所述,在获得测试数据的知识表示之后,为了形成规范的测试文档,需要构建一个通用、稳定的测试知识本体。由于测试的概念体系是一个典型树状结构,并不适合用关系型数据来描述,因此采用XML Schema来描述测试数据的本体结构,对应图1,测试知识本体的局部结构如图7所示。

为了将来有效利用测试数据,并为测试文档生成做准备,需要有效管理各个测试项目的Kp,为此采用XML数据库管理系统eXist来进行测试知识的管理。
eXist是一个开源的原生XML数据库管理系统[18],能够很好地支持数据索引,支持XSLT,XQuery和Java开发,特别是能够支持无预定义的存储结构,这样能够很好地适应测试数据结构的变化。此外eXist可以通过建立共享目录和文件拷贝简便地实现数据入库,对于非专业的测试人员非常方便。
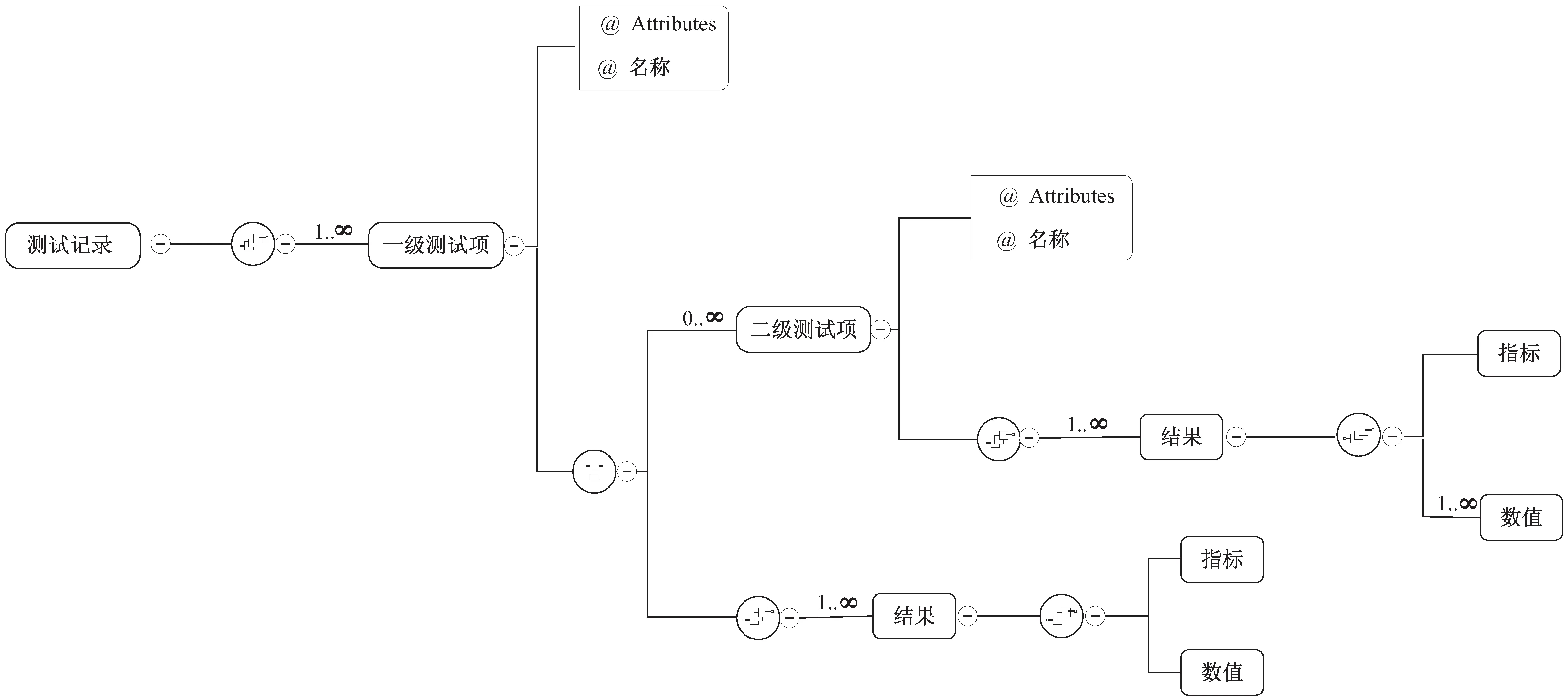
图7 测试知识本体的局部结构
eXist数据库的基本概念包括文档集(collection)、资源(resource)和文档(document)。eXist通过collection将一系列数据文件聚集起来,存储所有文件的元数据以及多个resource。resource中以命名空间为单位存储多条XML数据(document)。在该文的系统中,每一类测试项目c对应一个collection,其中包含各个pc的resource以及存放Kp的测试数据document。有了测试知识库,便可以着手生成测试文档了。
4 测试文档自动生成
对于所有的测试项目,测试文档均为符合标准的规范形式,这种形式一般用模板来表达。但是一般使用的静态报告模板存在以下几个问题。首先,难以处理动态变化的数据,例如对空的测试项进行去除,或对重复的测试项增加动态分节;其次,难以根据测试数据的特点按需展示内容,例如对于表格形式的数据,难以提供选择以最适合的图表(chart)形式来呈现;再有,人们习惯了纸质的测试文档,而作为电子形式的测试文档理应有更丰富的交互方式,例如通过插件或智能标签来裁剪或定位报告中的特定内容,或对测试结果进行查询统计。
为支持文档的动态生成能力,采用局部模板,以自底向上的方式来生成测试文档。为测试文档的各个部分设计了局部的模板ti,每个ti可能有多个候选{ti1,ti2,…},根据数据的呈现要求来选用,全部ti组成测试文档的模板集合T,
ti∈T,0 ReportGeneration(Kp,T) i=1; whilei<=N { for eachti∈T { 定位Kp的位置,得到数据d; 按d的特点和呈现要求选择ti中的候选模板tij,tij∈ti; 用d填充tij,生成测试文档的第i部分; } } if需要动态查询等扩展功能 { 构造基于XQuery查询程序; 生成查询插件或智能标签; } 项目要求将测试文档保存成为Microsoft Word文档形式,为降低对Microsoft Office产品的依赖,没有采用Office SDK,而基于OOXML的开源接口POI[19]来开发模板。如果需要生成HTML形式的测试文档,可使用XSLT构造测试文档的转换式样单,此处不作赘述。这种在不同介质上按需生成文档的能力,体现了复合出版的思想。图8是该文生成的测试文档部分内容。 图8 生成的测试文档(部分) 运用数据到文本的生成理论,提出了一种基于知识提取的测试文档生成方法。该方法首先对原始的测试记录数据进行分析和理解,重点进行电子表格的表头识别和单元格关联关系识别,抽取出XML形式的表格逻辑关系分析结果;其次按照预先设计的、标准化的测试本体,将表格逻辑关系分析结果转换成规范的知识表达,存放在XML数据库中,形成测试知识库;最后依次用知识库中的数据填充文档局部模板,逐步获得整体的测试文档。该方法体现了如下的创新性: 较好的通用性和“低代码”,可以支持多类测试和多个测试项目。在不同的测试类型之间切换时,只需要自动识别新的电子表格测试记录,并替换第3节中的Tp即可。另外,如果测试项目对测试文档的展现形式有特殊的要求,可以定制模板和脚本,此外无需更多的编程,避免了重复开发工作。 通过对测试数据的知识提取,避免了原始测试记录的不稳定性,利于测试结果有效利用。虽然在测试过程中受各种因素影响,难以保证测试人员自始至终采用一致的电子表格记录数据,但是只要表格的逻辑结构不变,总能从中得到正确的知识表示。另外规范化的知识表示可以用于后续对测试结果的各种查询、统计和分析。 在填充局部模板的基础上生成整体测试文档,避免了传统静态模板带来的缺点,能够较好地处理动态的数据,并按需展示数据内容,同时可以扩充交互式的数据访问能力。 系统有较好的跨平台能力,采用开放的标准和开源软件进行开发,不依赖于特定的商业软件。 取得的成果已经通过验收,成功应用于中国电子技术标准化研究院的产品测试部门,从浩繁的测试数据中生成一份测试文档只需要几分钟的时间,在近期大负荷的信创产品测试任务中发挥了重要作用。 在未来可以继续改进的方面有: (1)考虑将RDF等知识表示语法用于测试知识的表示,以期更高效地实现对测试结果的语义检索; (2)构建更为灵活的文档模板集合,配合智能化的作文规则,进一步提高测试文档的可读性; (3)将成果推广到其他领域的文档编制,针对敏捷开发和DevOps等开发模式特点,探讨从不同来源的原始数据生成完整的、规范的产品文档的可能性。
5 结束语
