AIGC发展路径思考:大模型工具化普及迎来新机遇
2022-12-08□文翟尤李娟
□ 文 翟 尤 李 娟
0 引言
2022年8月,在美国科罗拉多州举办的新兴数字艺术家竞赛中,参赛者提交AIGC(AIGenerated Content,以下简称“AIGC“)绘画作品《太空歌剧院》,参赛者没有绘画基础但是却获得了此次比赛“数字艺术/数字修饰照片”类别一等奖,引发多方争议。一方面,批判者认为AI在“学习”了大量前人的作品之后,其创作没有任何情绪和灵魂,难以和人类的艺术创作相提并论。另一方面,支持者认为创作者在一遍遍修改文本内容后,才让AI创作出满意的作画,而且作品有很强的观赏性,AI的创作有其独特价值。AIGC的快速迭代演变,让大模型应用落地有了新领域,也带来对版权和通用人工智能到来的争论,因此有必要从产业发展的角度分析AIGC可能的发展路径,探寻问题解决方案,助力AIGC健康有序发展。
1 AIGC快速发展主要推动因素
AIGC是利用人工智能技术来生成内容。2021年之前,AIGC生成的内容主要以文字为主,而新一代模型可以处理的格式包括:文字、语音、代码、图像、视频、机器人动作等。AIGC被认为是继专业生产内容(PGC,professionalgenerated content)、用户生产内容(UGC,Usergenerated content)之后的新型内容创作方式,可以在创意、表现力、迭代、传播、个性化等方面,充分发挥技术优势。尤其是视觉信息,一直在网络中有较强的传播力且容易被大众感知,具有跨平台、跨领域、跨人群的优势,天然容易被人记忆和理解。同时视觉信息应用场景广泛,因此生成高质量的图像成为当前AI领域的一个现象级功能。
1.1 深度学习模型不断迭代为AIGC发展奠定了基础能力
2021年,OpenAI将跨模态深度学习模型CLIP(Contrastive Language-Image Pre-Training,以下简称“CLIP”)进行开源。CLIP模型能够将文字和图像进行关联。例如,将文字“狗”和狗的图像进行关联,并且关联的特征较为丰富,从而推动CLIP模型成为AIGC的重要组成部分。目前,CLIP模型具备两个优势,一方面能够同时进行自然语言理解和计算机视觉分析,实现图像和文本匹配。另一方面为了有足够多标记好的“文本-图像”进行训练,CLIP模型广泛利用互联网上的图片,这些图片一般带有相关文本描述,成为CLIP天然的训练样本。据不完全统计,CLIP模型搜集网络上超过40亿个“文本-图像”训练数据,为后续AIGC尤其是输入文本生成图像/视频应用的落地奠定了基础。

某AIGC绘图网站上输入Cyberpunk后,搜索到的AIGC生成绘画
在此之前,“对抗生成网络”GAN(Generative Adverserial Network, 以下简称“GAN”)虽然也是很多AIGC采用的主流框架之一,但GAN具有三个不足:一是对输出结果的控制力较弱,容易产生随机图像;二是生成的图像分别率较低;三是由于GAN需要用判别器来判断生产的图像是否与其他图像属于同一类别,导致生成的图像是对现有作品的模仿,创新性不足。因此依托GAN模型难以创作出新图像,也不能通过文字提示生成新图像。
Diffusion扩散化模型出现较晚,但真正实现让文本生成图像的AIGC应用为大众所熟知,也是2022年下半年Stable Diffusion应用的重要推手。Diffusion模型有两个特点,一方面,给图像增加高斯噪声,通过破坏训练数据来学习,然后找出如何逆转这种噪声过程以恢复原始图像,经过训练,该模型可以从随机输入中合成新的数据。另一方面,Stable Diffusion把模型的计算空间从像素空间经过数学变换,降维到可能性空间(Latent Space)的低维空间里,这一转化大幅降低了计算量和计算时间,使得模型训练效率快速提高。Diffusion算法模型的创新与应用推动了AIGC技术的突破性进展。

AIGC相关深度学习模型汇总表
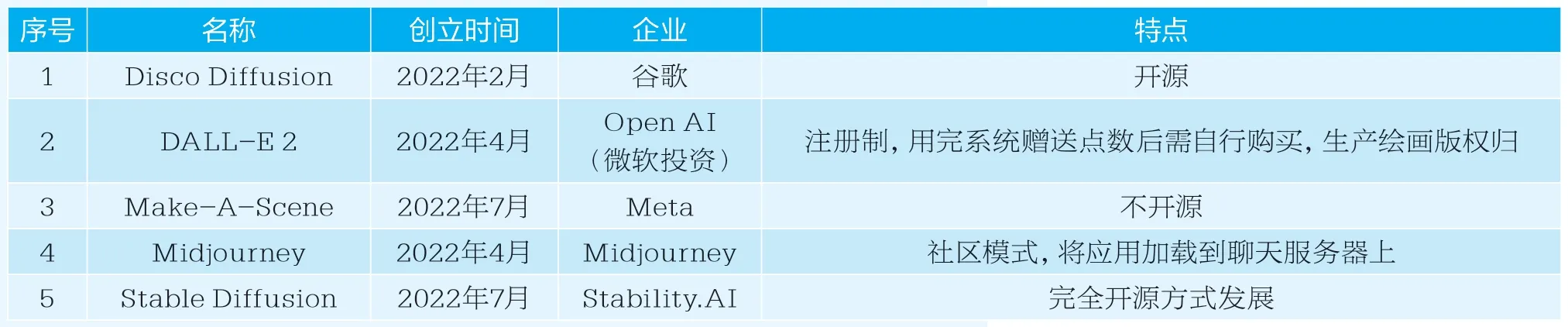
AIGC绘画应用系统汇总表
总的来看,AIGC在2022年实现快速迭代,主要是在深度学习模型方面有了长足进步。首先CLIP模型基于海量互联网图片进行训练,推动AI绘画模型进行组合创新。其次Diffusion扩散化模型实现算法创新。最后使用潜空间降维的方法来降低Diffusion模型在内存和时间消耗较大的问题。因此,AIGC绘画之所以能够帮助用户进行辅助创作,背后离不开大量深度学习模型的不断完善推动和基础作用。
1.2 开源策略成为应用开发普及的“必选项”
在算法模型方面,AIGC的发展离不开开源模式的推动。以深度学习模型CLIP为例,开源模式加速CLIP模型的广泛应用,使之成为当前最为先进的图像分类人工智能,并让更多机器学习从业人员将CLIP模型嫁接到其他AI应用。同时,当前AIGC绘画最热门的应用Stable Diffusion已经正式开源(包括模型权重和代码),通过视觉、语言等多源知识指引扩散模型学习,强化扩散模型对于语义的精确理解,以提升生成图像的可控性和语义的一致性。Stable Diffusion的开源直接引发2022年下半年AIGC引发广泛关注,短短几个月时间内出现大量二次开发,从模型优化到应用拓展,大幅降低用户使用AIGC进行创作的门槛,提升创作效率,并长期位居GitHub热榜第一名。
在训练数据集方面,机器学习离不开大量数据学习。LAION作为全球非盈利机器学习研究机构,在2022年3月开放了当前规模最大的开源跨模态数据库LAION-5B,使得近60亿个“文本-图像”可以用来训练,从而进一步加快AI图像生成模型的成熟,帮助研究人员加快推动从文字到图像的生成模型。基于CLIP和LAION的开源模式构建起当前AI图像生成应用的核心。未来,随着模型稳定,开源将成为AIGC成熟的催化剂,源模式有望让相关模型成为海量应用、网络和服务的基础,应用层面的创造力有望迎来拐点。
2 AIGC为创作领域带来的效率与模式的创新
创造力曾被认为是少数幸运儿拥有的天赋,但随着深度学习的爆发,协助创作者提升创作效率成为可能。目前来看,AIGC在工业设计、动漫设计、摄影艺术、游戏制作等场景,能够激发设计者创作灵感,提升内容生产效率。
2.1 应用效率提升是当前AIGC落地关键
在捕捉灵感方面,AIGC协助有经验的创作者捕捉灵感,构建新的创新互动形式。例如在游戏行业,制作人灵感往往难以用文字准确表达,与美术工作人员经常由于沟通产生理解误差。通过AIGC系统可以在设计初期,生成大量草图,在此基础上制作人与美术人员可以更好的理解并确认彼此的需求。同时,创作灵感难以琢磨,可以提前通过AIGC来寻找“感觉”,进一步降低美术创作者大量前期工作和项目成本。例如,制作人可先构建完整的背景故事,之后由AIGC生成系列画作,再由专业的美术人员进行筛选、处理、整合,并将整个故事和画面进一步完善提升。
在提升效率方面,AIGC的出现将会让创作者拥有一个更加高效的智能创作工具,在内容创作环节进行优化,而非成为竞争对手。例如在极短的项目筹备时间内,AIGC可以大幅提升效率,验证了AI投入到工业化使用的可行性。尤其是对于艺术、影视、广告、游戏、编程等创意行业的从业者来说,可以辅助从业者进行日常工作,并有望创造出更多惊艳的作品。同时,还可以进一步降低成本和效率,为规模化生产构建市场增量。
2.2 创意与实现步骤分解实现进一步细化分工
在创意构思阶段,AIGC构建了新的创意完善通路,传统的创作过程中消化、理解以及重复性工作将有望交由AIGC来完成,最终创意过程将变为“创意-AI-创意”的模式。
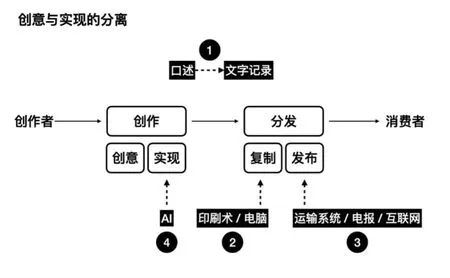
图片来源:《AI时代的巫师与咒语》
在创意实现阶段,创作者和AIGC的关系类似于摄影师和照相机。摄影师构建拍摄思路并进行规划,对相机进行参数配置,但不用了解相机的工作原理与机制,一键生成高质量的内容。同样,创作者构思并进行规划,对AI模型进行参数配置,不需要了解模型的原理,直接点击输出内容即可。创意和实现呈现出分离状态,实现过程变为一种可重复劳动,可以由AIGC来完成,并逐步将成本推向趋近于零。
3 推动AIGC良性发展的意见和建议
Gartner预计,到2025年,生成式人工智能将占所有生成数据的10%。根据《Generative AI :A Creative New World》的分析,AIGC有潜力产生数万亿美元的经济价值。AIGC在引发全球关注的同时,知识产权、技术伦理将面临诸多挑战和风险,同时AIGC距离通用人工智能还有较大的差距。
3.1 从“大模型”到“广应用”,探索可行商业模式
基于深度学习算法数据越多,模型鲁棒性越强的特点,当前的大模型规模只增不减,比拼规模已经成为标配。例如,Open AI推出的GPT-3参数已经超过1750亿个。但“数据投喂”并非一种技术路径上的创新,更多的是在工程领域的微调。需要指出的是,模型规模越大,其实越难以在现实场景中落地部署。同时“海量数据”并不等同于“海量高质量数据”,有可能会导致反向效果产生。
AIGC的发展离不开预训练大模型的不断精进。大模型虽然在很多领域都表现出良好的使用效果,但是这些效果作为展示甚至噱头之后,很难形成良性的商业价值,与大模型的训练成本、基础设施投入更是相差甚远。如何推动“大模型”向“大应用”来转变,正在成为关键的考验。AIGC的破圈以及引发的关注,可以看到大模型商业化的潜力正在清晰化,一方面大模型企业可以根据C端用户实际“按需提供服务”和商业转化。另一方面带动对云计算、云存储的使用量上升。将AIGC从“尝鲜试试看”变成大众频繁使用的需求,再到与具体行业和领域深度结合,依托我国丰富的产业需求和应用场景,有望为大模型商业化和长期价值探索一条新路径。
3.2 注重知识产权保护,尝试探索新价值创新
AIGC的飞速发展和商业化应用,对大量依靠版权为主要营收的企业带来冲击。具体来看:一方面,AIGC难以被称为“作者”。根据我国《著作权法》的规定,作者只能是自然人、法人或非法人组织,很显然AIGC不是被法律所认可的权利主体,因此不能成为著作权的主体。另一方面,AIGC产生的“作品”尚存争议。根据我国《著作权法》和《著作权法实施条例》的规定,作品是指文学、艺术和科学领域内具有独创性并能以某种有形形式复制的智力成果。AIGC的作品具有较强的随机性和算法主导性,能够准确证明AIGC作品侵权的可能性较低。同时,AIGC是否具有独创性目前难以一概而论,个案差异较大。

目前已经有业内人士尝试探索将创作者的“创意”进行量化,甚至定价,有助于打造AIGC的商业模式。这其中“注意力机制”将成为AIGC潜在的量化载体。例如国内有机构专家提出,可以通过计算输入文本中关键词影响的绘画面积和强度,我们就可以量化各个关键词的贡献度。之后根据一次生成费用与艺术家贡献比例,就可以得到创作者生成的价值。最后在与平台按比例分成,就是创作者理论上因贡献创意产生的收益。
例如某AIGC平台一周内生成数十万张作品,涉及这位创作者关键词的作品有30000张,平均每张贡献度为0.3,每张AIGC绘画成本为0.5元,平台分成30%,那么这位创作者本周在该平台的收益为:30000*0.3*0.5*(1-30%)=3150元的收益,未来参与建立AI数据集将有望成为艺术家的新增收益渠道。
3.3 距离通用人工智能还有较大差距
当前热门的AIGC系统虽然能够快速生成图像,但是这些系统是否能够真正理解绘画的含义,从而能够根据这些含义进行推理并决策,仍是未知数。一方面,AIGC系统对输入的文本和产生的图像不能完全关联起来。例如,用户对AIGC系统进行测试,输入“骑着马的宇航员”和“骑着宇航员的马”内容时,相关AIGC系统难以准确生成对应的图像。因此,当前的AIGC系统还并没有深刻理解输入文本和输出图像之间的关系。另一方面,AIGC系统难以了解生成图像背后的世界。了解图像背后的世界,是判断AIGC是否具备通用人工智能的关键。目前来看,AIGC系统还难以达到相关的要求。比如,在Stable Diffusion 输入“画一个人,并把拿东西的部分变成紫色”,在接下来的九次测试过程中,只有一次成功完成,但准确性还不高。显然,Stable Diffusion并不理解人的双手是什么。
知名AI专家发出的调查也印证了同样的观点,有86.1%的人认为当前的AIGC系统对世界理解的并不多,持相同观点的人还包括Stable Diffusion的首席执行官。
3.4注重创作伦理引发安全风险
部分开源的AIGC项目,对生成的图像监管程度较低。一方面,部分数据集系统利用私人用户照片进行AI训练,侵权人像图片进行训练的现象屡禁不止,这些数据集正是AIGC等图片生成模型的训练集之一。例如,部分数据集在网络上抓取了大量病人就医照片进行训练,且没有做任何打码模糊处理,对用户隐私保护堪忧。另一方面,一些用户利用AIGC生成虚假名人照片等违禁图片,甚至会制作出暴力和性有关的画作,LAION-5B数据库包含色情、种族、恶意等内容,目前海外已经出现基于Stable Diffusion模型的色情图片生成网站。
由于AI本身还不具备价值判断能力,为此一些平台已经开始进行伦理方面的限制和干预。例如DALL·E2已经开始加强干预,减少性别偏见的产生、防止训练模型生成逼真的个人面孔等,但相关法律法规的空白和AIGC应用研发者本身的不重视将引发对AI创作伦理的担忧。
4 结束语
2022年AIGC发展速度惊人,年初还处于技艺生疏阶段,几个月之后就达到专业级别,足以以假乱真。这让花费毕生所学进行创作的从业人员倍感焦虑和紧张。同时,AIGC的迭代速度呈现指数级爆发,这其中深度学习模型不断完善、开源模式的推动、大模型探索商业化的可能,成为AIGC发展的“加速度”。新技术会淘汰适应性差的人,但是那些拥抱变革、适应力强的人,最终往往能驾驭新技术、发现新机遇,从此获得新收益。新的生产方式会被替代,新的工作岗位、新产业甚至新的艺术表现形式,会从变革中诞生。
