基于特征选择和GWO-KELM的鸟声识别算法
2022-12-05李大鹏周晓彦徐华南
李大鹏,周晓彦,叶 如,夏 煜,徐华南
(南京信息工程大学电子与信息工程学院,江苏 南京 210044)
0 引言
鸟类作为生态系统的重要组成部分,对鸟类活动和分布的监测,为了解一个地区的生物多样性变化和气候变化提供了重要的依据[1-2],因此对鸟类的监测与分类识别具有重要意义。鸟鸣声和形态特征是区分鸟类的重要特征,也是目前鸟类物种识别普遍采用的方式,在实际监测中鸟鸣声相较于形态特征更加便于监测。虽然目前国内外对于鸟声识别的研究并不多,但也取得了一定的成果。通过调查研究发现,目前国内的鸟声识别技术主要通过改进鸟声特征提取算法,提取各种鸟声特征然后使用机器学习算法构建分类器进行识别[3]。
目前,鸟声识别的分类方法可以分为3种:(1)基于模板匹配的分类方法。最常见的是动态时间规整(Dynamic Time Warping,DTW)算法,如徐淑正使用基于音长、梅尔倒谱系数(Mel-Frequency Ceps-tral Coefficients,MFCC)、线性预测系数(Linear Prediction Coefficient,LPCC)系数和时频域纹理特征的动态时间规整算法可以达到90%的准确率[4]。(2)通过人工算法提取特征,选择合适的分类模型。孙悦华等提取了4种鸟类鸣声的MFCC,然后使用高斯混合模型对其进行分类识别,正确率可以达到89.1%~92.5%[5]。陈莎莎等为了降低环境噪声对鸟声识别的干扰,使用灰度共生法提取纹理特征,然后利用随机森林(Random Forest,RF)模型对20种鸟声进行识别,平均正确率可以达到95.35%[6]。钱坤等首次使用OpenSmile提取大规模声学特征,使用ReliefF算法降低特征维度,极限学习机(Extreme Learning Machine,ELM)作为分类器实现鸟声的分类识别,该方法在10种、30种和54种鸟类的识别正确率分别为94.71%、89.56%和86.57%[7]。张赛花等提取了一种梅尔子带参数化特征,使用支持向量机(Support Vector Machine,SVM)对野外11种鸟鸣声进行分类识别,结果表明该方法对11类鸟声查全率、查准率和F1-score均高于89%[8]。(3)基于深度学习的方法。EmreCakir等基于提出了卷积递归神经网络(Convolutional Recurrent Neural Networks,CRNN)的方法实现鸣声的高维特征及短时帧间的相关性特征提取,对Freesoung数据库中的鸟鸣声进行分类实验,正确率达到88.5%[9]。冯郁茜提出了基于双模态特征融合的鸟类物种分类算法,融合卷积网络提取的语图特征和长短时记忆结构提取的鸣声时序序列特征,自适应完成基于鸣叫或者鸣唱的物种识别[10]。Bold等利用卷积神经网络(Convolutional Neural Networks,CNN)提取语图特征并且提出跨模态结合特征,提高了分类识别的性能[11]。
由于文献[5-7]所提取的鸟声特征较为单一,分类参数采用网格搜索的方式容易错过最优值,无法达到分类器的最好性能。本文受文献[7]的启发,将广泛应用于语音情感识别的ComParE特征集[12]应用于鸟声识别领域,同时为了降低特征冗余度,采用适合高维样本的特征排序结合浮动搜索策略的混合特征选择方法,以核极限学习机(Kernel Extreme Learning Machine,KELM)[13]十折交叉验证的正确率来评判特征的优劣,进行特征选择,得到适用于鸟声的特征子集,最后通过灰狼算法[14]对KELM参数进行寻优,得到最优参数提高模型识别正确率。
1 基于特征选择和GWO-KELM的鸟声识别算法
本文所提出的鸟声识别系统总体框架如图1所示主要分成两个部分:
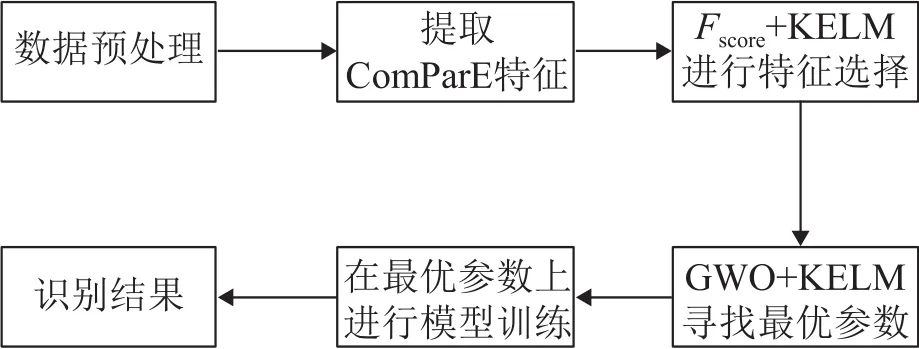
图1 鸟声识别系统框图Fig.1 Block diagram of bird sound recognition system
(1)基于KELM和Fscore的混合特征选择
首先对获取的鸟声进行预处理,并通过OpenS-mile提取ComParE特征集,然后计算每个特征的Fscore,对特征的区分能力进行评价并排序。最后以KELM十折交叉验证正确率作为特征选择的标准,采用广义顺序向前浮动搜索(Generalized Sequential Forward Floating Search,GSFFS)[15]作为搜索策略进行特征选择得到最终适用于鸟声识别的特征子集。
(2)基于GWO的KELM识别算法
为了提高KELM模型在鸟声分类识别上的效果及稳定性,将特征子集在KELM模型上十折交叉验证的正确率,作为灰狼优化算法的适应度,迭代寻找最优的正则化参数c和核函数参数σ。最后在该参数上对KELM模型进行训练,得到识别结果。
1.1 核极限学习机
极限学习机[16]由黄广斌在2006年提出,是一种只有一个隐藏层的神经网络结构,它的隐藏层节点参数w和b通过随机生成的方式产生,与训练集无关[17],其输出函数为

其中:h(x)为隐藏层的特征映射,隐藏层输出权重β根据广义逆矩阵原理和最小二乘法计算得到:

其中:H是隐藏层的输出矩阵,T是目标矩阵。
Huang等[13]通过对比极限学习机与SVM的原理,结合核函数方法用核映射代替ELM中的随机映射,提出了核极限学习机(KELM),利用Mercer构造核矩阵ΩELM取代广义逆矩阵中的HHT。
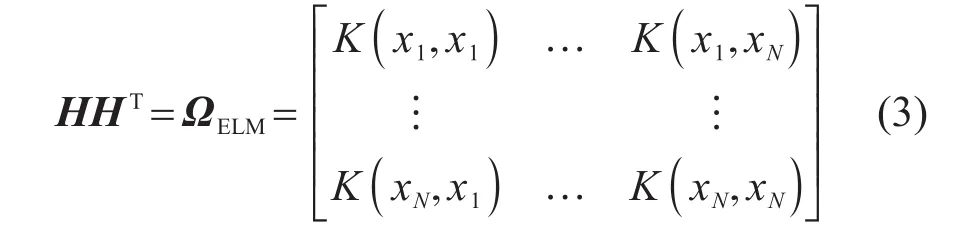
所以由式(2)、式(3)可得隐藏层输出权重:

为了提高KELM的稳定性与泛化能力,引入正则化参数1/c添加在对角矩阵HHT对角线上。则输出权重表示为
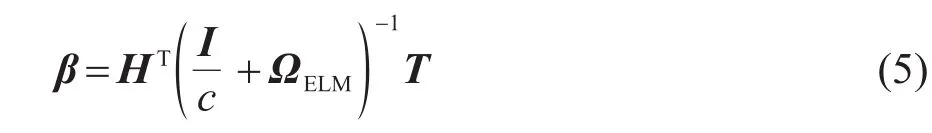
其中:I为单位矩阵,由式(3)、(4)可得当特征映射h(x)未知时KELM的输出函数可以表示为

此时,f(x)的表达式为
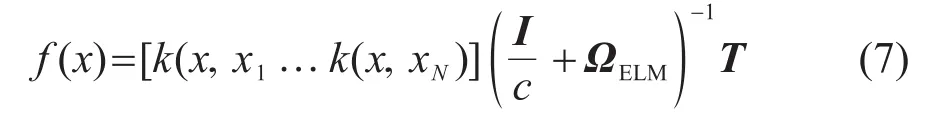
1.2 基于KELM和Fscore的混合特征选择算法
由于ComParE特征集是为人类语音情感识别而设计,其中部分特征并不能反映鸟声的特点,为了更好地实现对鸟声的识别,降低特征冗余度,本文使用特征选择算法寻找合适的特征子集。
特征选择算法按照是否独立于分类器,可以分为Filter型和Wrapper型[18],Filter算法根据特定的准则评价特征重要性,独立于分类器,速度快,但特征分类能力较弱;Wrapper算法以分类器性能为评价标准,特征子集分类效果好,但算法速度慢,特征泛化能力较差[19]。本文将这两种方式混合,把Fscore作为特征区分能力评价标准结合KELM分类器,以广义顺序向前浮动搜索(GSFFS)[15]为搜索策略寻找最佳特征子集。
1.2.1 Fscore特征区分能力评价标准
传统的Fscore只能用来计算两类特征的区分能力,谢娟英等[20]及杨勇[21]对其进行了扩展,提出了改进的Fscore,可以衡量多类特征的区分能力。为了满足对于多种鸟声识别的需求,选择改进的Fscore作为鸟声特征区分能力评价标准对于提取到的鸟声特征 样 本,第i个特征的Fscore计算公式为
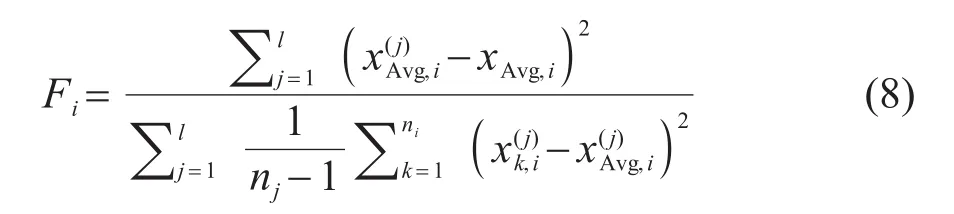
1.2.2 混合特征选择
为了提高搜索效率,本文首先对计算得到鸟声特征的Fscore按照大小进行降序排序,选择前20%特征作为初始特征集,删除得分最低的20%特征,剩下60%特征作为预选特征集。然后,依次不断加入预选特征集中Fscore得分最高的特征,以KELM十折交叉验证正确率为特征区分能力评价标准,如果正确率没有提高就从特征子集中删除该特征,继续依次搜索剩下的预选特征集。为了解决严格地按照正确率上升作为特征选择标准造成特征子集无法更新的问题,引入惩罚参数λ,即KELM正确率下降不超过λ就不会删除该特征,混合特征选择算法步骤如下:
(1)计算每个鸟声特征的Fscore,并降序排序;
(2)选择前20%特征作为初始特征集,20%~80%特征作为预选特征集,个数为n,初始化i=0,RAcc=0;
(3)令i=i+1,将第i个特征加入特征子集;
(4)计算特征子集的KELM十折交叉验证正确率为RAcc1;
(5)若RAcc1+λ>Acc,更新特征子集和正确率令RAcc=RAcc1,否则从特征子集中删除该特征;
(6)若i<n返回步骤(3),否则输出被选特征子集。
1.3 基于GWO优化的KELM分类模型
对于分类模型参数的选取,传统的方法一般使用网格搜索的方式进行,但该方法在较大范围使用小步长进行搜索时,需要较高的计算资源和较长的时间,而使用较大步长搜索往往可能错过全局最优值。因此本文采用随机搜索的方式寻找KELM模型参数的全局最优值。
1.3.1 灰狼算法
灰狼优化(Grey Wolf Optimizer,GWO)算法是由澳大利亚学者Mirjalili等人在2014年提出的一种元启发式群体智能优化算法,该算法通过模拟自然界中灰狼的社会等级制度和狩猎机制,将灰狼按照等级从高到低分为α狼、β狼、δ狼和ω狼四种狼,实现对于猎物的寻找、包围和攻击[14]。在GWO算法中,群体适应度最优的三个解依次对应为α狼、β狼、δ狼,其余的解为ω狼,通过α狼、β狼、δ狼引导ω狼包围、攻击猎物,从而获得最优值。
GWO算法数学模型为
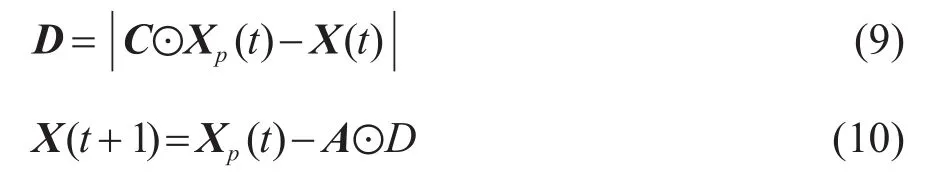
其中:D表示灰狼个体与猎物间的距离,X(t+1)表示灰狼更新后的位置,公式中⊙均为矩阵的哈达玛积,为取矩阵中元素的绝对值。t表示当前迭代次数,Xp和X分别表示猎物和灰狼的位置向量。A和C为系数向量,计算公式为

其中:a随迭代次数t线性递减,r1、r2为[0,-1]的随机向量。C是系数向量,用于增加(C>1)或减少(C<1)灰狼与猎物之间的距离,提高全局搜索能力。
假设狼α、β、δ知道猎物潜在位置,则灰狼更新公式为

其中:Dα、Dβ、Dδ分别表示狼α、β、δ与其他个体的距离,Xα、Xβ、Xδ表示狼α、β、δ的当前位置。
1.3.2 GWO-KELM算法
常用的KELM核函数有高斯核函数,多项式核函数,拉普拉斯核函数和sigmoid核函数等[13],实验中KELM核函数选取高斯核函数,其计算公式为

由式(7)、式(15)可知,KELM性能与正则化参数c和核函数参数σ密切相关,为了提高KELM模型分类识别效果及稳定性,本文通过灰狼算法优化KELM的参数c和σ,把KELM模型十折交叉验证正确率作为灰狼优化算法的适应度。GWO优化KELM分类识别算法步骤如下:
(1)初始化GWO算法参数:狼群数量、最大迭代次数t、参数c和σ上下界;
(2)随机初始化狼群位置,位置维度为2;
(3)根据狼群位置即c和σ,计算KELM交叉验证正确率作为灰狼个体适应度;
(4)选择适应度最好的三个狼,记录其位置为Xα、Xβ、Xδ;
(5)根据式(13)、式(14)更新狼ω位置;
(6)根据式(11)、式(12)参数A和C;
(7)计算位置更新后的适应度,并与上次迭代的最优适应度对比,更新狼α、β、δ适应度和位置;
(8)若迭代次数超过最大次数,输出全局最优适应度及其对应位置Xα,否则执行步骤(5)。
2 实验
2.1 鸟声数据库及预处理
为了验证算法的有效性,本文采用国内国外两种数据库进行实验。一是德国柏林自然科学博物馆数据库,该数据库由专业的鸟类学家在自然野外环境中采集的鸟鸣声数据组成。为了保证足够的训练、测试数据,实验中删除数据库中鸟声音频文件数少于25个的鸟类,采用了60种鸟类、共计4 468个鸟鸣声音频文件,最短时长约为0.3 s,最长为36 s。同时将这4 468个长度不等的鸟声数据统一为单声道、采样率44.1 kHz、32 bit的WAV格式音频。二是由北京百鸟数据科技有限责任公司发布的中国常见20种鸟类鸣声合集,包含灰雁、大天鹅、绿头鸭、绿翅鸭、灰山鹑、西鹌鹑、雉鸡、红喉潜鸟、苍鹭、普通鸬鹚、苍鹰、欧亚鵟、西方秧鸡、骨顶鸡、黑翅长脚鹬、凤头麦鸡、白腰草鹬、红脚鹬、林鹬、麻雀,共14 311个长度均为2 s的WAV格式音频。
2.2 特征提取
使用在语音情感识别中广泛使用的开源工具OpenSmile提取ComParE特征集。该特征集在2013年InterSpeech中被提出,包含了大量手工设计的低水平特征LLDs和在LLDs基础上统计得到的高级统计特征HSFs,共包含6 373维度特征,包括MFCC、时间信号的过零率(Zero-Crossing Rate,ZCR)、帧能量均方根(Root Mean Square,RMS)、基音频率(F0)等特征,具体信息可参见文献[12]。
2.3 分类模型评价标准
混淆矩阵是一种直观地评价分类模型结果的指标,如图2所示是二分类结果混淆矩阵。
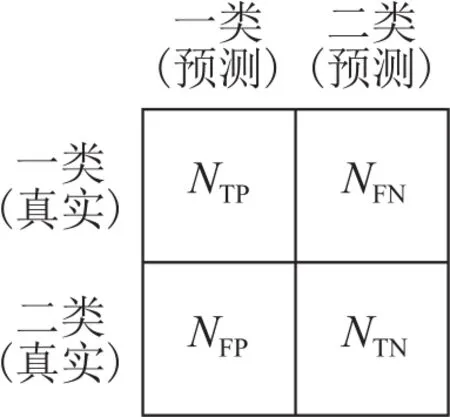
图2 二分类结果混淆矩阵Fig.2 The confusion matrix of dichotomy results
图2中,NTP为样本的真实类别是正例且模型预测的结果也是正例的样本个数;NTN为真实类别是负例,且预测成为负例的样本个数;NFP为真实类别是负例,但预测成为正例的样本个数;NFN为真实类别是正例,但预测成为负例的样本个数。
对混淆矩阵的数据进行简单计算,可以延伸得到查准率、查全率、正确率和F1-score等常用评价指标。对于每种鸟类其计算公式如下:

本文选择正确率和兼顾查准率和查全率的F1-score作为分类模型评价指标。
2.4 实验与分析
为了验证本文算法的有效性,实验共分为三个部分,其中前两部分实验均在德国柏林自然科学博物馆数据库上实现。首先对比原始ComParE特征集在不同分类器上的表现;其次对比选择后的特征子集与原始ComParE特征集在不同分类器上的识别精度,并对比采用网格搜索方式和GWO随机搜索方式所得参数识别结果;最后对比了近年来相关论文所提算法和主流的深度学习算法。实验的特征提取部分,通过基于python的OpenSmile3.0工具包实现提取鸟声音频的ComParE特征,每个音频文件可以得到6 373×1维特征向量,循环遍历数据库中的所有音频提取其特征并保存为CSV文件。然后以Matlab 2018b软件为算法实验平台,采用十折交叉验证方式作为实验协议即将数据集分成十份,轮流将其中9份作为训练数据、1份作为测试数据,进行试验。
2.4.1 ComParE特征集在不同分类器上的表现
该实验在德国柏林自然科学博物馆数据库上进行,并随机选取了其中10类,30类和全部60类数据进行实验。对比了原始ComParE特征集在RF、SVM、ELM和KELM分类器上的表现结果如表1所示。实验设置如下,除RF模型以外在将特征向量输入分类器之前,首先对特征进行归一化处理,其中RF模型采用默认设置决策树数量为500,特征数量为79;由于特征参数维度很高,因此SVM模型采用线性核函数,正则化参数设置为1;ELM模型隐藏层数量通过循环搜索的方式遍历[1 000 2 000… 30 000]最终在10类,30类和60类实验中对应的设置为10 000、16 000、20 000;KELM模型核函数选择为高斯核函数,采用网格搜索的方式,高斯核函数参数σ∈[2-52-4...215]和正则化参数c∈[2-52-4...215]最终σ和c设置为4 096和2 048。
从表1中可以看到KELM分类器在10类、30类和60类鸟声识别十折交叉验证正确率为96.67%、93.77%和93.23%,相对于其他分类器均具有更高的正确率。结果表明KELM算法相较于其他算法在高维度鸟声特征分类识别中更具优势,体现了KELM分类器的优越性。
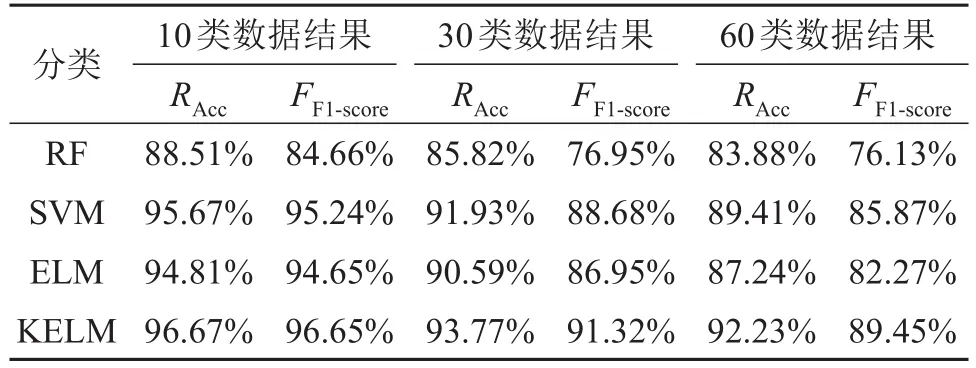
表1 ComParE特征集在分类器上的表现Table 1 The performance of the ComParE feature set on the classifier
2.4.2 基于特征选择和GWO-KELM算法实验
为了进一步提高鸟声识别的效果,本文对提取到的6 373维特征集采用Fscore+KELM的方法在德国柏林自然科学博物馆全部60类数据库进行特征选择,减少冗余特征,实验惩罚参数λ设置为0.001。为了更好地体现特征对于分类器性能的影响,将KELM参数σ和c固定为4 096和2 048,最终选择出2 710维特征。
GWO算法初始设置为初始化狼群数量为10,最大迭代次数为100,参数c和σ的上下界设置为10 000和0.000 1,初始狼群位置在上下界范围内随机生成。如图3所示GWO-KELM在选择后的特征集上的迭代结果,最终选择的最优参数c和σ分别为316、6 112。其他分类器的参数设置与2.4.1节相同。

图3 GWO-KELM迭代结果Fig.3 GWO-KELM iteration results
表2所示为选择后的特征子集与原始ComParE特征集在不同分类器和GWO-KELM算法的识别结果。从表2中可以看出选择后的特征子集在四个分类器上的识别正确率和F1-score均高于原始特征集,提升幅度约2%~5%。结果表明,基于Fscore和KELM特征选择算法减少了冗余特征,所选特征集具有良好的分类能力,能够更好地反映鸟鸣声的特点。在GWO-KELM模型(c=316,σ=6112)上识别正确率为94.45%,相比采用网格搜索的方式KELM算法提高0.5%左右。与传统的网格搜索方式相比,GWO搜索方式更容易找到全局最优值,证明了GWO-KELM模型的有效性。

表2 不同分类器对60类鸟声特征选择前后的特征集的识别结果Table 2 Identification results of different classifiers for the feature sets before and after the selection of the 60-class bird acoustic features
2.4.3 与其他论文方案的比较
由于德国柏林数据库语音长短差距较大,无法直接作为CNN模型的输入,所以为了与目前主流的深度学习模型进行对比,实验增加了北京百鸟数据库的实验。该部分实验主要与以下4种方法进行对比:
(1)ComParE+SVM:使用OpenSmile工具包提取ComParE特征集,通过经典的SVM算法进行识别。
(2)09IS+ELM[7]:通过p-centre方法实现对鸟鸣声的音节检测,然后使用OpenSmile工具包提取09IS特征集,并通过ReliefF算法减少特征维数,最后采用ELM进行识别。
(3)Logmel+CNN[11]:通过librosa提取鸟鸣声的梅尔谱图,输入CNN进行识别。
(4)Logmel+CRNN[9]:通过librosa提取鸟鸣声的梅尔谱图,输入CNN和两层循环神经网络(Recurrent Neural Network,RNN)进行识别。
(注:09IS+ELM模型采用原文在德国柏林数据库上的实验结果,Logmel+CNN和Logmel+CRNN模型实验结果通过python 3.7和基于TensorFlow的kreas 2.3框架,采用原文参数复现所得)。
实验结果如表3所示,从表中可以看出相较于手工特征加分类器的方式,端到端的深度学习模型在识别率上更具备优势,本文所提的基于特征选择和GWO-KELM的鸟声识别算法,在传统手工特征方法中具备明显优势,可以达到与目前常见的卷积神经网络(CNN)近似相同的正确率,与CNN加RNN的方式仍有一定差距。但深度学习网络往往需要更高的计算量和更多数据样本。同时本文的方法不受音频长短的影响,在音频长短一致的北京百鸟数据库和音频长短不一的德国柏林数据库都可以实现较好的分类效果。而深度学习网络需要固定的语音长度或者通过补0等方法实现特征补齐,对于语音长短差距较大数据库处理较为困难。因此本文方法对于数据要求更低,具有更好的适应性。

表3 与其他论文方案的对比Table 3 Comparison with other paper schemes
3 结论
为了提高种类较多的鸟声识别正确率,解决目前鸟声识别算法中特征单一的问题,本文提出了一种基于混合特征选择和灰狼算法优化核极限学习机的鸟声识别算法。该算法将Fscore特征区分能力标准与KELM分类器相结合对提取的ComParE特征集进行特征选择,然后通过GWO算法优化KELM进行分类识别。通过对比实验可以看出,相较于原始ComParE特征集,选择后的特征子集在不同分类器上的识别正确率均有提高,表明了基于KELM和Fscore的混合特征选择算法所选特征子集具有良好的分类能力。该方法在德国柏林数据库和北京百鸟数据库的分类识别正确率分别可以达到94.45%和91.16%。虽识别正确率略低于目前计算量更大的深度学习模型,但由于深度学习模型需要更多的数据样本,本文所提方法在小样本鸟声数据的识别上仍具有一定优势。
