基于多尺度压缩卷积神经网络模型的表面缺陷快速检测
2022-12-05廉家伟何军红王天泽
廉家伟,何军红,牛 云,王天泽
(西北工业大学 航海学院,陕西 西安 710072)
0 引言
在工业生产过程中,对存在缺陷的工件或产品进行缺陷检测必不可少。缺陷检测即识别出是否有缺陷以及缺陷的类型,传统工业中对于工件的表面缺陷识别还停留在人工检测阶段,受到工人的个人因素影响,效率和质量都难以保障,传统的人工检测方法已经无法满足工业需求。在当前数据量与计算力日益剧增的时代背景下,深度学习迎来了发展的春天,新的学习算法层出不穷,广泛应用于计算机视觉[1-2]、语音识别[3-4]以及自然语言处理[5]等各个领域,并取得了巨大的成功。近年来,基于卷积神经网络(Convolutional Neural Network,CNN)的视觉检测方法已经越来越广泛地应用在表面缺陷检测中,其检测过程具有无接触无损伤等特点,而且在提高检测效率的同时也大大提高了检测精度。
如今,运用深度学习的方法进行表面缺陷检测已经成为主流趋势,很多学者对此进行了深入的研究。CHEN等[6]以从粗到细的方式级联了3个深度卷积神经网络检测阶段,设计了一个紧固件的缺陷检测系统,并通过实验证明了该系统能够在复杂的环境下达到较高的检测精度,以及良好的鲁棒性和适应性。TAO等[7]提出一种深度卷积神经网络级联结构,将缺陷检测转化为两级对象检测问题,通过这种方式定位并检测绝缘体的缺陷。YU等[8]提出一种可重复使用的两阶段深度学习的工业环境下的表面缺陷检测方法。FENG等[9]提出一种深度主动学习的系统,达到模型识别的最大化。ZHENG等[10]提出一种基于半监督深度学习的自动缺陷检测方法,能够充分利用大量的无标签数据。熊红林等[11]提出基于多尺度卷积神经网络的玻璃表面缺陷检测方法,能够达到较高的识别准确率。总之,深度学习卷积神经网络的应用越来越广泛。
随着对模型性能的要求不断提高,为了达到更好的预测效果,通常会采取两种方法:
(1)使用过参数化的大型深度神经网络,能够大幅提高模型的学习能力,为防止过拟合,通常也往往会加上正则化策略配合使用,于是出现了一系列性能更加优越的神经网络模型,如VggNet、GoogleNet以及ResNet等。
(2)使用集成策略,将很多相对较弱的模型集成起来,甚至是强强联合,往往能够达到更好的预测效果。然而,在这两种方案中网络性能的提升往往伴随着参数的增加以及复杂度的提升等问题,使得模型的部署困难,在实际应用中受限。如手机等便携式设备以及工业高实时性的检测设备等。因此,在保证模型精度和速度的同时,尽可能压缩网络成为当下亟待解决的问题。
HOWARD等[12]提出的MobileNet采用步长为2的卷积代替池化操作,同时放弃传统的标准卷积,采用深度可分离卷积(Depthwise Separable Convolution,DSC),可以大大减少参数量和模型计算量且不损失模型精度。HINTON等[13]提出通过知识蒸馏的方法让小模型和大模型的Softmax输出分布尽可能接近,从而达到尽可能相似的预测效果。WEN等[14]通过实验证明了庞大的深度卷积神经网络存在大量的冗余参数,可以通过网络修剪来优化模型。HU等[15]提出了网络修剪(Network Pruning),通过评估神经元的重要性并以其作为依据,裁减掉影响作用较小的部分来压缩网络。WU等[16]提出一种对权重参数使用k均值算法的方法,通过k个聚类中心和权重分配指数进行权值共享。COIFFIER等[17]提出一种ThriftyNets网络结构,定义了一个循环使用的卷积层,压缩了参数量并提高了参数利用效率。
近年来,各式各样的网络压缩优化算法被提出,模型的尺寸以及效率得到了大幅度的优化,但当前仍面临网络压缩尺度单一、压缩幅度有限以及精度损失大等问题,对于部分工业现场的部署应用还需要进一步改善。本文提出一种基于多尺度压缩卷积神经网络模型(Multi-scal Compression Convolution Neural Network,MC-CNN),从不同的尺度对网络进行压缩,在尽可能避免损失精度的情况下大幅降低模型复杂度,压缩模型尺寸且提高分类效率。并通过在NEU-CLS钢板表面缺陷数据集上的实验验证了该模型的可行性和有效性。
1 模型构建

本文所提MC-CNN压缩优化流程示意图如图1所示。首先,采用改进的轻量型网络MobileNet[12]作为基础的网络结构,采用深度可分离卷积代替常规卷积,并将浅层和深层中尺寸相等的两个FeatureMap进行拼接,得到一个更大的FeatureMap,能够增加特征的数量并保留一定的原始特征。然后,以改进的MobileNet作为学生网络通过知识蒸馏方法学习教学网络的知识,再通过网络修剪,剔除冗余参数,将得到的模型进行参数量化处理,最终得到能够在保证分类精度的同时,体积和运算速度大幅减小的模型MC-CNN。
2 模块介绍
2.1 网络结构
网络结构采用改进的MobileNet[12],该网络采用深度可分离卷积代替传统卷积结构。深度可分离卷积主要在网络结构上进行优化,由深度卷积(Depthwise Convolution,DWC)和逐点卷积(Pointwise Convolution,PWC)两个步骤组成。然后将浅层和深层中尺寸相等的两个FeatureMap进行拼接,如图2所示,得到一个更大的FeatureMap,能够有效增加特征的数量,将浅层原始特征与深层抽象特征相结合,能够避免特征抽象过程中丢失特征信息,使得有效的特征信息流继续向后传递,从而改善分类效果。

与常规卷积中一个卷积核同时操作所有的通道不同,在DWC中的卷积核不同于常规卷积的立体卷积核,而是二维平面的,一个卷积核只负责一个通道,不涉及其他通道信息,卷积核的个数等于输入通道的数目,逐通道进行卷积,只改变特征图的大小,不改变通道数,如图3所示。

PWC是将DWC的输出所有通道进行逐点卷积,糅合逐通道整理出来的各通道间的信息,只改变通道数,不改变特征图的大小,如图4所示。

同样的输入和输出情况下,常规卷积有O个k×k×I(其中:I为输入通道数,O为输出通道数,k×k为卷积核大小)大小的卷积核,参数量为k×k×I×O;而深度可分离卷积有I个k×k大小的卷积核和O个大小为I的卷积核,参数量为k×k×I+I×O,如图5所示。
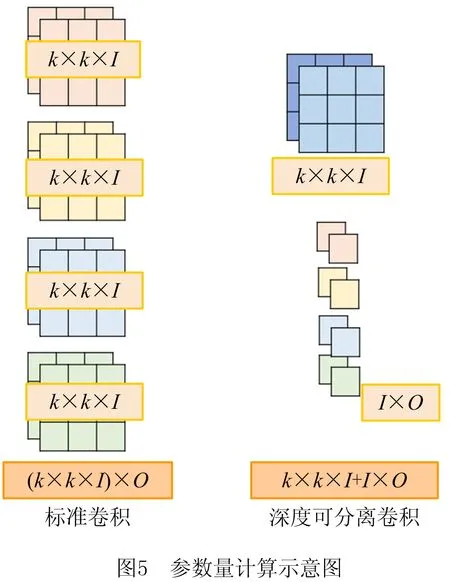
从而得到深度可分离卷积和常规卷积的参数量比值为:
(1)
通常输出通道数O的值远大于k,故O对于优化的参数量的作用较小,主要取决于卷积核的大小k,多数情况下,k=3,此时深度卷积神经网络参数量约缩小为常规卷积的1/9。因此,使用深度卷积神经网络能够大幅减少模型参数量,从而降低模型复杂度,提高模型识别效率。
2.2 知识蒸馏
将搭建好的轻量型网络与训练好的大型CNN网络进行知识蒸馏。知识蒸馏(knowledge distillation)的思想是将一个小规模的模型通过向训练好的大模型学习达到接近大模型的预测效果,即将一个强大的模型所包含的重要知识教给较小的模型。
首先训练一个较大的教学模型,然后再训练一个小的学生模型学习教学模型的行为,即Softmax输出,让教学模型和学生模型在给定输入情况下的Softmax输出分布匹配,即优化其Softmax分布的交叉熵,如图6所示。这样做的好处是可以充分利用Softmax分布所包含的信息。比如当识别手写体数字1的时候,标签只能告诉我们是1,不是7,也不是9,而经过训练的Softmax可以告诉我们0.7的概率是1,0.2的概率是7,0.1的概率是9。

为了让两个模型的Softmax输出的分布充分接近,不能直接使用一般的Softmax,因为在一般的Softmax函数中,先用指数拉大logits(the inputs to the final Softmax)[13]间的差距,然后归一化,最终输出的是一个接近one-hot的向量,大大局限了知识的体现。
有两种方法可以避免该问题:
(1)直接比较logits,对于每条数据,大模型和小模型产生的logits分别为vi和zi,将式(2)最小化即可。
(2)
(2)更通用的做法即是使用一种广义的Softmax函数将小模型中的logitzi,转化为属于各个类别的概率qi,如式(3)所示:
(3)
式中T是引用统计力学中玻尔兹曼分布中的概念,指的是温度,通常设为1。由式(3)可知,当T的值很小时,Softmax的输出接近one-hot向量;当T变大时,Softmax输出的属于各个类别的概率分布会变软,即各元素数值差距相对较小,因此在训练模型时调大两个模型的超参数T(两个模型的T值相等)使得输出足够软,然后优化其交叉熵损失C:
(4)
使两个模型足够接近。训练结束后,仍然使用T=1即常规Softmax进行预测。
交叉熵损失C对于小模型中的zi的梯度为:
(5)
其中:vi为大模型的logit,pi为大模型的Softmax输出。
当T相对于logits足够大时,式(5)可以化为:
(6)
如果所有的logits对于每个样本都是零均值化,即∑jzj=∑jvj=0,则式(6)可转化为:
(7)
当T过大,且logits对于每条数据都是零均值化的,则知识蒸馏等价于最小化logits的平方差(见式(2));当T过小时,输出偏硬,不利于信息的表达。实验表明,应选取适当的T,软化Softmax输出分布有助于提高模型表现。
2.3 网络修剪
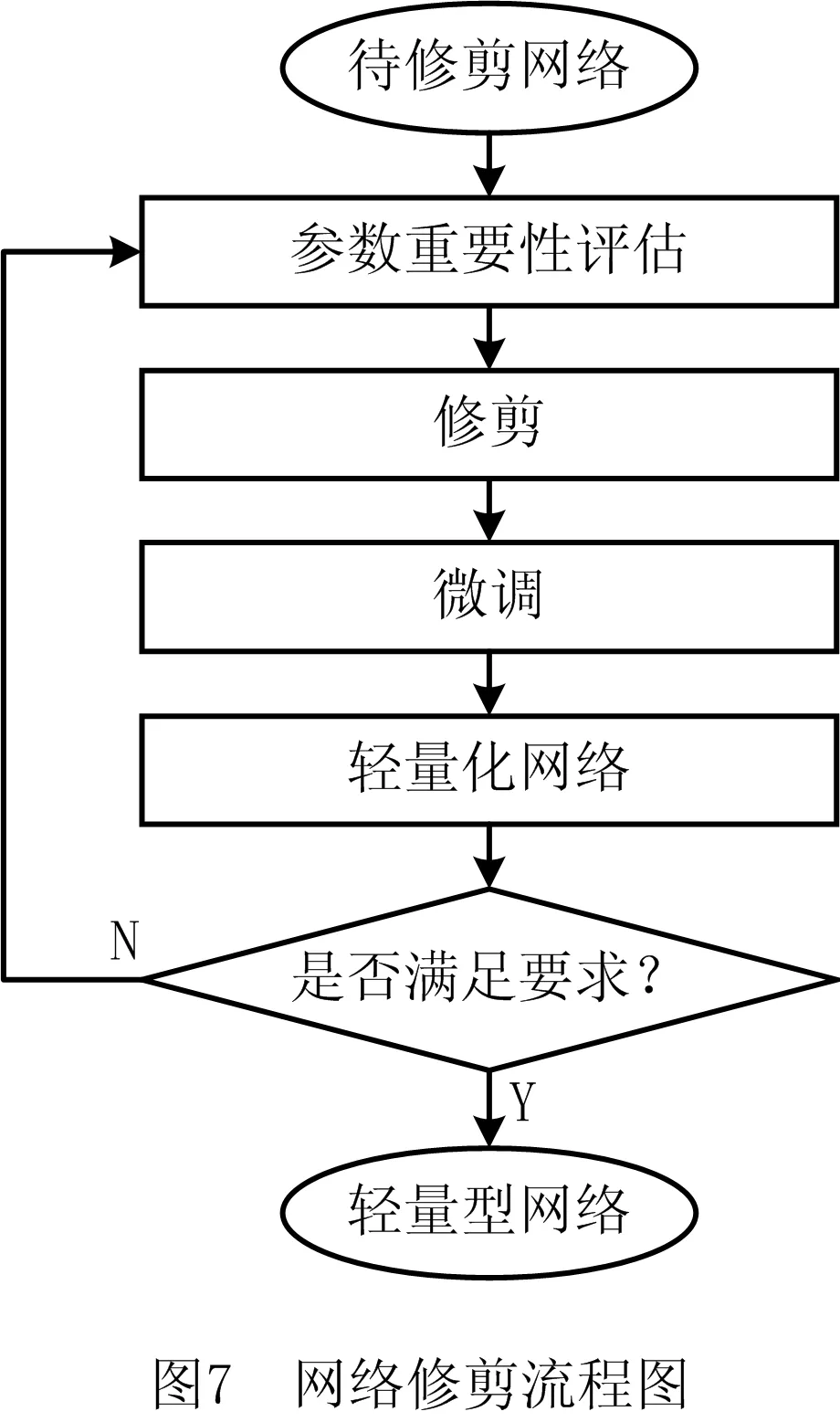
经过知识蒸馏学习的模型还存在着一定量冗余的参数,接下来对该模型进行网络修剪。简单来说,网络修剪(network pruning)就是对一个已经训练过的模型中影响较小的参数进行修剪,使模型变得更加精简。主要流程如图7所示。
首先训练一个待修剪的网络模型,然后选出影响作用小的部分并去除,这时模型效果会有所下降,需要再通过训练来更新参数使模型精度得到一定的恢复,重复裁剪和更新的过程直到得到满足要求的模型。
网络修剪包括权重修剪和神经元修剪两种方式。其中权重修剪是剔除影响较小的值,为方便矩阵运算,将空缺的连接权重补0,因此实质上并未提高运算效率,据实验[14]表明,在修剪掉大量参数后,只有很小的精度损失。虽然计算效率并没有提高,但是表明了网络裁剪的可行性与巨大的裁剪空间。通常采用的是神经元修剪的方式,神经元修剪相当于移除了权重矩阵中的列,参数减少,运算速度提升。本文实验中采用神经元修剪的方式。
修剪神经元之前要先评判神经元的重要程度。Pytorch中提供的Batchnorm计算如式(8)所示:
(8)
需要计算每个mini-batch中数据各个维度的均值和标准差,其中γ和β是尺寸和输入数据一致的学习系数矩阵,是可训练的参数,γ是权重系数,β是偏移系数。神经元的作用越小,相应的γ因子的值就越小。故可以通过Batchnorm layer的γ因子评判神经元的重要程度,从而修剪掉影响作用较小的神经元。实验表明,修剪参数过多将对精度产生较大影响,参数修剪量百分比Quantity与精度下降△Acc(重复5次实验取平均值)如表1所示,故取参数修剪量为3%为宜。

表1 Params和△Acc对照关系
2.4 参数量化
最后,将经过修剪的网络模型进行参数量化处理。实验中采用两种方式对参数进行量化,如图8所示。
(1)缩减参数的存储位数,本次实验使用Pytorch深度学习框架,默认的参数类型是32位浮点型,可以将32位浮点型数据转换为16位浮点型数据,该方法虽然简单,但效果却非常直观,实验表明,模型体积会缩小一半且精度几乎没有损失。

(2)采用K-Means聚类算法对参数进行聚类。K-Means算法的思想很简单,将给定的样本集按照样本之间距离的大小划分为K个簇,并使簇内点之间的距离尽可能的近,簇与簇之间的距离尽可能的远。
给定数据集D={x1,x2, …,xm},划分为k个簇(C1,C2, …,Ck),则最小化目标函数平方误差E:
(9)
式中ui是簇Ci的均值向量,即质心,
(10)
参数聚类后将模型中属于该类别的参数用该类别中所有参数的中位数或均值表示即可。聚类数目通常为2的整数次方,比如参数分为16类,则只需4个bit存储类别编号即可。实验表明,参数聚类的颗粒度大小对模型的精度会产生不同的影响,参数类别数目k和精度的下降百分比△Acc(重复5次实验取平均值)如表2所示,故k值取32为宜。

表2 k和△Acc对照关系
3 实验分析
本文提出基于多尺度压缩卷积神经网络模型MC-CNN。采用深度可分离卷积和特征图拼接结构作为基础网络模型,然后通过知识蒸馏的方法学习已经训练好的CNN模型的知识,再对学习过的模型进行网络修剪并微调模型参数以恢复网络修剪造成的精度损失,最后对模型参数进行量化得到最终的模型,能够实现较好的快速分类效果,且大幅度压缩模型的体积。
3.1 实验数据
实验数据采用的是NEU-CLS表面缺陷公开数据集,其中收集了热轧钢带轧制氧化皮(RS),斑块(Pa),开裂(Cr),点蚀表面(PS),内含物(In)和划痕(Sc)6种典型的表面缺陷,如图9所示。每一类缺陷包含300个样本数据,共有1 800个样本数据,由于样本数据量较少,对样本数据进行扩增处理,通过旋转90度,180度以及镜像等方式扩增数据集,扩增后每一类缺陷包含1 200个样本数据,共有7 200个样本数据。训练集、验证集以及测试集的比例为5:3:2,使用CrossEntropy损失函数,Adam算法进行优化,epoch设为60,batch_size设为64,学习率为0.001。各个模型中上述参数均保持一致。
原始图片数据分辨率为200×200,经边缘扩充及中心裁剪后分辨率为224×224,训练样本输入矢量为(224,224,3)的图片数据,首先在卷积池化层进行特征提取,接着在全连接层分类,经Softmax输出为(1,6)的矢量,代表属于各类别的概率,其中最大的概率值就是模型分类的最终结果,为便于模型训练,分别使用0,1,2,3,4,5代表缺陷类型轧制氧化皮(RS),斑块(Pa),开裂(Cr),点蚀表面(PS),内含物(In)和划痕(Sc)。

3.2 对比分析
为验证提出的MC-CNN模型的有效性,将该模型与CNN(网络结构参数如表3所示)、MobileNetV2以及ShuffleNetV2等模型进行比较。
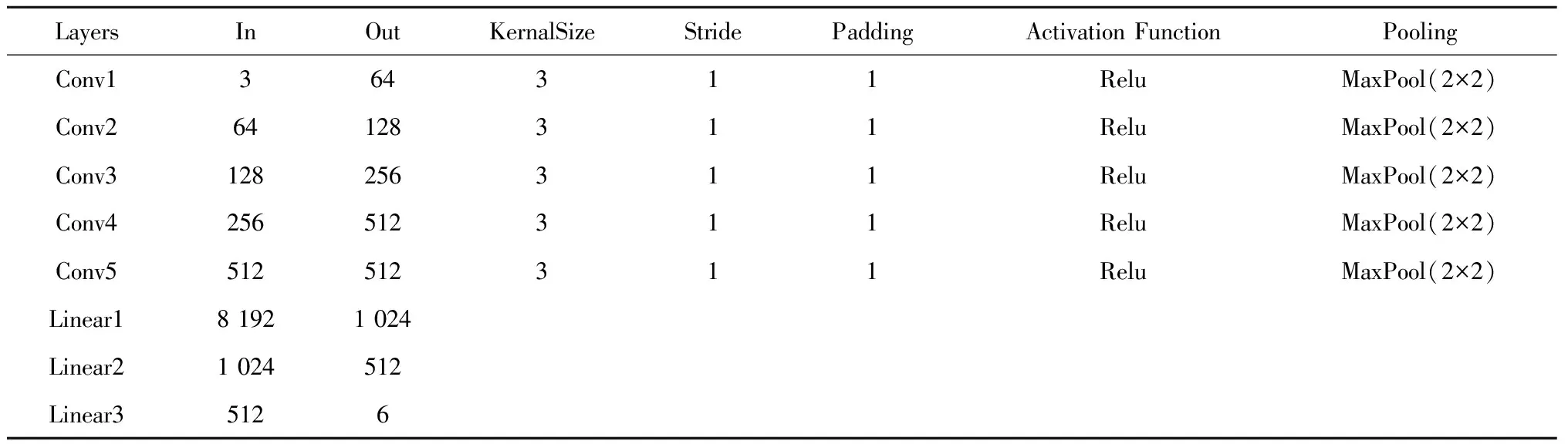
表3 CNN结构参数
为测试所提出模型的综合性能,除了模型的准确率(Acc)之外,还要将模型的复杂度作为评价指标进行对比分析。时间复杂度决定了模型的训练和预测时间,过高则会导致模型训练和预测耗费大量时间,既无法快速验证和改善模型,也无法进行快速的预测。空间复杂度由模型的参数数量决定,模型的参数越多,训练模型所需的数据量就越大,而且还需要更多的存储资源。计算量指模型的运算次数,从另一方面反映了模型的复杂程度。
通过运算时间(Time)、模型大小(Size)以及浮点运算量(FLOPs)作为时间、空间和计算量3个维度的复杂度评价指标,其中Time为各个模型在测试集上的运算时间,由于不同硬件设备的差异,该参数只在表4中模型间的比较具有意义。其中CNN模型大小为48.94 MB,浮点运算量为1123.62百万次,运算时间为5.577 s;MobileNetV2模型大小为0.99 MB,浮点运算量为98.37百万次,运算时间为2.781 s;ShuffleNetV2模型大小为1.94 MB,浮点运算量为132.21百万次,运算时间为3.253 s;MC-CNN模型大小为0.46 MB,浮点运算量为43.82百万次,运算时间为1.483 s。MC-CNN的复杂度远小于CNN的复杂度,且大幅低于MobileNetV2和ShuffleNetV2的复杂度。
各模型训练精度随迭代次数的变化如图10所示。CNN的学习能力相对较强,Acc曲线上升较快,精度也较高。轻量型网络MC-CNN通过知识蒸馏向CNN学习以及网络修剪和参数量化也可以达到较高精度且能够降低模型复杂度。从图中可以看出MC-CNN的收敛速度和精度要优于其他两个主流轻量型网络。


各模型损失值随迭代次数的变化如图11所示。同样,CNN强大的学习能力使Loss在前几次迭代中大幅下降,随后MC-CNN基本与其持平,而且优于MobileNetV2和ShuffleNetV2。
3.3 实验结果
实验结果如表4所示,由表可知MC-CNN模型相比于CNN体积缩小了99.06%,效率提高了273.96%,浮点运算量降低了96.10%;相比于MobileNetV2体积缩小了53.54%,效率提高了87.53%,浮点运算量降低了55.45%;相比于ShuffleNetV2体积缩小了76.29%,效率提高了119.35%,浮点运算量降低了66.86%,更易于在实时性要求高,存储资源以及计算资源有限的环境下部署,而且相较于其他两个主流轻量型网络有效避免了精度的损失。

表4 各模型性能对比
4 结束语
本文提出一种基于多尺度压缩卷积神经网络模型MC-CNN。首先使用深度可分离卷积和特征图拼接作为基础网络结构,然后通过知识蒸馏对模型进行训练,接着对训练好的模型进行网络修剪,去除冗余参数,最后对模型进行参数量化,最终得到MC-CNN模型,能够实现在大幅提高检测效率并压缩模型体积的同时达到较高精度的分类。
使用神经网络等深度学习技术进行表面缺陷检测已然是大势所趋,能够避免传统图像检测方法中繁琐的图像预处理、特征提取以及分析等步骤,但是复杂的网络模型应用部署存在一定困难,因此对模型进行压缩并保留检测精度具有十分重要的现实意义。当前网络压缩技术还在发展当中,下一步,在压缩网络的同时还应尽可能提高检测精度;另一方面,模型的结构以及超参数的配置有限,应研究更加合理的配置压缩模型方法来应对更加复杂的任务。
