改进时间卷积网络和长短时记忆网络的泸水河流域月径流量预测模型
2022-12-05王万良胡明志张仁贡董建杭金雅文
王万良,胡明志,张仁贡,董建杭,金雅文
(1.浙江工业大学 计算机科学与技术学院,浙江 杭州 310023;2.浙江禹贡信息科技有限公司,浙江 杭州 310052)
0 引言
水资源是人类赖以生存的重要需求和人类社会经济与国民生活中不可替代资源。据国家水利部《2019年水资源公报》表明,我国目前存在的677座大型水库和3 628座中型水库年末蓄水总量较往年减少91.7亿m3,76个湖泊年末蓄水总量较往年减少28.9亿m3[1]。具体而言,快速变化的全球气候和高强度人类活动,一直影响着流域下垫面和产汇流过程,导致全球流域降水、径流等气象、水文要素更加难以琢磨,加深了水文预测中的不确定性和预报难度[2]。因此,当前最迫切需解决的问题是如何从一众径流预测技术中寻找突破,优选稳定性高且准确的水文模型,并应用于实际生产需要中。
传统水文预报方法可分为过程驱动模型方法和数据驱动模型方法两大类[3]。过程驱动模型是指以水文学概念为基础,利用数学模型方法对径流过程与河道演进进行模拟,从而模拟得到水文预报。例如赵人俊等[4]提出的概念性流域降雨径流模型——新安江模型,以流域蓄水容量曲线为核心,按泰森多边形法划分计算单元做汇流计算,再对出口以下的河道洪水进行单元出流过程相加,最后得到流量过程。王中根等[5]利用水土评估模型(Soil and Water Assessment Tool,SWAT)结合地理、水文数据模拟黑河流域复杂多变的径流过程。刘江涛等[6]开发了适用于半干旱高寒地区的降水输入模块,利用高程分带将降水组合成半网格半站点的降水输入数据驱动模型,并在拉萨河流域进行有效对比实验。李抗彬等[7]在TOP-MODEL模型中引入植被冠层截留蒸散发模型和Holtan超渗产流模型,采用马斯京根河道洪水演进模型,并对半湿润地区流域降雨径流过程进行模拟验证,结果表明改进模型模拟精度有很大的提高。然而,数据驱动模型通常依据水文站历年累积的大量水文资料,建立数学关系寻求预报对象与预报因子的最优描述关系,例如人工神经网络模型、回归分析模型等[8-9]人工智能模型。由于自然流域和降水过程在空间和时间上存在极大差异,而水文系统是一个多源耦合的系统,呈现多尺度,多特征,多规律的水文过程,存在参数难以统一以及水文模型可移植性差等问题[10]。基于人工智能的神经网络模型具有良好的非线性映射能力[11-12],在大数据处理和特征提取方面具有独特优势[13],不需要考虑水文过程的物理机制,能很好地适应复杂的时间序列数据,在解决水文预报以及多特征、多规律水文过程有独到的优势[14-15]。近年来,水文预报领域引入多种常见的人工智能模型,如人工神经网络(Artificial Neural Network,ANN)、随机森林(random forest)、循环神经网络(Recurrent Neural Network,RNN)、支持向量机(Support Vector Machine,SVM)等,并取得了可观的预测结果。如PARK等[16]利用混合ANN与遗传算法(Genetic Algorithm,GA)模型的实时径流预测模型,并以韩国Sumji流域为对象验证模型的可行性和精确性。冯钧等[17]将将长短时记忆网络(Long Short Term Memory,LSTM)与反馈(Back Propagation,BP)神经网络结合,成功地在子午河流域进行多次径流预报。张森等[15]构建了基于多种群遗传算法(Multiple Population Genetic Algorithm,MPGA)与LSTM混合模型,并用于晋江流域进行延时回归预测。李代华[18]提出基于Mittag-Leffler、Pareto、Cauchy 3种重尾分布改进的布谷鸟搜索算法(Cuckoo Search,CS)优化的支持向量机月径流预测模型,并验证了该模型的可行性。REDDY等[19]利用事件对抗神经网络(Event Adversarial Neural Network,EANN)混合模型在Kallada流域进行月径流量预测,并与常规前馈神经网络(Feed Forward Neural Network,FFNN)、多元自适应回归样条模型(Multivariate Adaptive Regression Splines model,MARS)进行性能分析,成功验证了人工智能模型的精确性和可行性。
目前,很少有学者将近年新提出的深度学习方法应用于水文领域进行实验探索,极度缺乏新模型对于复杂且耦合度高的多源水文、气象时空数据的应用经验。例如,2018年由BAI等[20]提出的一维时间卷积网络将卷积神经网络思想引入处理时序数据中,使用多层网络来学习较长时间跨度的信息,其网络结构如图1所示。相较于门控循环网络(Gated Recurrent Unit,GRU)、RNN等标准递归网络,时间卷积网络(Temporal Convolutional Network,TCN)在时间序列问题上能得到更精确的输出,并能保持更简单清晰的网络结构,但是少有人将其应用于处理多源水文、气象数据,缺乏相关实验报告。LSTM[21]作为一种由循环神经网络发展而来的具备特殊门结构的模型,因其较RNN能更好地处理时序数据、实现长期记忆,而被广泛应用于时间序列预测领域。近年许多学者、专家都对其进行模型改进,并取得了相应的成果。例如,KRATZERT等[22]利用LSTM直接学习各流域内通用水文模型参数,在更少的参数迭代情况下,构建更优的水文模型,并通过实验证明了该模型的可行性;SHI等[23]通过引入卷积替代LSTM矩阵乘法操作,建立了更精确的时空序列预测模型;宋亚等[24]整合自编码神经网络与双向LSTM,优化数据依赖特征提取精度,有效解决了时序数据维度高、样本量大的问题。
水文预报所依赖的数据因其领域特殊性,存在一定的多源性、趋势性、不确定性[25],以及随机规律特征,让目前单一水文预报模型无法全面提取多源流域水文特征,在提高径流预测精度上还存在较大的提升空间。李福兴等[26]采用经验模态分解(Empirical Mode Decomposition,EMD)提取多尺度径流序列特征,混合差分整合移动平均自回归模型(Auto-Regressive Integrated Moving Average,ARIMA)与广义回归神经网络(General Regression Neural Network,GRNN)模型对不同尺度固有模式分量(Intrinsic Mode Functions,IMF)进行过程模拟,并有效地提高了预测精度;梁浩等[27]提出融合大气环流异常因子后的基于小波分解(Wavelet Decomposition,WD)的SVM水文预报模型,并在渭河流域取得了满意的试验结果;包苑村等[28]提出基于变分模态分解(Variational Mode Decomposition,VMD),卷积—长短期记忆网络的渭河流域月径流量预测模型,提高了月径流预测精度。以上研究表明了多模型组合应用在提高径流预测精度上的可行性。
基于上述分析,本文构建一种能有效利用多源水文和气象数据,基于改进TCN和LSTM耦合的泸水河流域月径流量预测模型TCN_LSTM,主要改进包括:
(1)TCN_LSTM通过构造多卷积核并行网,进行多源时序特征卷积提取,并使提取的时序特征仍具有因果特性。
(2)TCN_LSTM引入扩张卷积在数据输入阶段进行高阶水文特征浓缩,达到了多尺度特征提取和扩大感受野,避免多源水文数据因数据量纲、值域不同而导致LSTM记忆单元冗杂问题,并提高记忆单元处理效率的目的。
(3)引入残差链接至TCN_LSTM模型,直接跨层传输底层特征,从而简化整体数据特征学习过程,增强梯度传播能力。
1 理论方法
1.1 时序卷积网络
BAI等[20]提出的(TCN)是一种具有特殊结构的卷积神经网络模型,是以传统一维卷积神经网络为基础,同时结合因果卷积、扩张卷积与残差链接而得到的新型网络模型[29-31],目前,该模型在机器翻译、音频合成和自然语言处理等任务上取得了优异的结果。TCN为进一步分层捕获时空数据特征提供了新思路[32],其核心特点是:①相较于普通卷积,该模型能够灵活接受任意尺寸的感受野,即使牺牲一定网络深度也能以较大的感受野抽取数据特征[33];②TCN网络结构可以获取任意长度的时序数据,并将其映射到相同长度输出序列[34]。TCN利用一维卷积核扫入当前时间节点及该节点之前的历史时序数据,沿网络层进行数据处理[35]。其模型结构如图1所示。TCN模型具有如下特征:
(1)TCN采用因果卷积,保证模型不能颠倒序列顺序,防止信息“泄露”,即该时刻的输出仅与上一层中该时刻对应输入及更早时刻输入进行卷积,与未来时刻无关。如图1所示,此时卷积核尺寸k取值为3,即每一层的该时刻输出都是由前一层对应的位置及前两个位置的输入共同计算得到,并随着隐藏层层数的增加,一个输出所对应的输入越多,所需要考虑的时间序列数据时刻越久[36]。
(2)TCN采用扩张卷积,通过增加卷积核的大小及扩张系数值,使得数据的感受野增大,形成更长时的卷积“记忆”,使得当模型进行多维数据并行输入时能保持高效的计算效率[37]。其结构可参考图1所示,该图隐藏层最下层扩张系数大小为d=1,表示输入时每个时间点都进行采样,下一层d=2表示每两个时间点作为一个输入,当隐藏层d=8时,时刻t感受野大小为最下层时刻t-17~t时刻数据,而此时隐藏层仅3层结构,这样随着层数加深,有效窗口的大小呈指数增长,则能以更少的层数获取更大的感受野以及更低的网络复杂度[38]。

(3)TCN引入残差网络,其核心思想是“连接”相隔一层或多层的网络层,以有效解决复杂模型中的梯度消失问题[39]。随着网络模型隐藏层层数的增加与复杂化,其能提取到的不同特征就会越丰富,但时间卷积网络中感受野大小的设置限度取决于网络深度和扩张系数大小,这势必会导致网络结构更加复杂,网络稳定性变差,造成梯度消失、梯度爆炸等问题[37],而引入残差块则能有效提高模型表现,保证模型良好性能。
1.2 长短时记忆网络
长短时记忆网络是基于循环神经网络的衍生网络,较原始RNN的基础上引入门控机制,以解决整体网络模型因复杂网络层造成的梯度消失、梯度爆炸和无法处理长期依赖的问题[40]。在面对长期依赖问题时,LSTM模型为解决传统RNN模型单隐藏层状态传递方式导致的权重更新缓慢情况,引入细胞状态传递方式,使得在反向传播更新权重过程与网络层特征传递过程中两者状态变化得以保持稳定,网络权重参数更新与长时记忆能力保持高效率,故LSTM模型常被用于长短期风电、水利、疾病预测及自然语言处理等领域,并取得广泛应用[41-42]。LSTM与其他神经网络相似,具备输入层、隐含层、输出层,其隐含层中的神经元能通过上一时刻与当前时刻输入的依赖信息控制当前记忆单元状态,广泛应用于处理时间序列数据[43]。RNN与LSTM网络整体结构如图2和图3所示。
如图2所示,相较于标准RNN结构具有简单重复模块,LSTM网络通过设置3个控制单元来让依赖信息有选择地影响循环神经网络每个时刻的状态[44-45]。首先由遗忘门的Sigmoid层决定当前时刻与上一时刻相应水文预测数据中需要舍弃的信息,其次再由输入门的Sigmoid层决定记忆单元中需要更新的依赖信息,最后根据当前记忆单元状态,经由输出门将存储的依赖信息传输到下一神经元,并循环此步骤[46-48]。LSTM网络结构如图3所示。
图4为LSTM网络中记忆单元结构示意图,其利用遗忘门和更新门选择必要依赖信息,并与当前细胞状态一起传递到下一刻,从而实现时序数据特征提取[49]。假设此时模型处于t时刻,记忆单元已经存储前t-1时刻的水文信息Ct-1,LSTM具体处理流程为:
(1)根据当前时刻输入xt和上一时刻输出结果ht-1,由遗忘门ft决定从之前存储的信息Ct-1中进行“舍弃”,利用遗忘系数与存储信息Ct-1按位相乘,而向量ft值越接近0的依赖信息越会率先遗忘,而取值接近1的信息得到保留,其遗忘门计算公式为:
ft=σ(Wf·[ht-1,xt]+bf)。
(1)
式中:Wf、bf为遗忘门的可调向量参数;σ为Sigmoid激活函数,
(2)
式中e为自然对数。


(2)经由上一步遗忘了部分信息之后,输入门it会根据当前时刻输入信息xt和上一时刻输出xt-1来更新信息加入Ct-1中,其输入门计算公式为:
it=σ(Wi·[ht-1,xt]+bi)。
(3)
式中Wi、bi为输入门的可调向量参数。
输入层Sigmoid层决定了需要更新的值之后,由tanh层构造依赖信息Ct,后续将结合这两步骤进行更新记忆单元状态值。新依赖信息计算公式为:
(4)
式中WC、bC为依赖信息的可调向量参数;tanh为双曲正切函数,
(5)

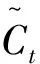
(6)

(3)由输出门根据记忆单元状态和输入依赖信息决定最终输出信息,其计算公式为:
(7)
式中Wo、bo为输出门的可调向量参数。
2 改进TCN_LSTM径流预测模型
水文预测中,径流的形成过程机理复杂,考虑多源水文因素以及高纬度水文特征的提取对于提高水文径流预测精度具有十分重要的影响。若只分析低维的水文实测数据,模型的拟合度往往不尽如人意[50-51]。基于此,本方法将改进的TCN和LSTM相结合,构建了TCN_LSTM月径流量预测模型,可以用来提高水文预测的准确度和计算效率,其网络结构如图5所示,其中隐含层数量不仅限于图中的两层,箭头按时刻从左向右进行隐含层状态的传递。
首先,利用改进的TCN模型,在保持因果卷积特性下,有效结合多源水文数据,从多源角度分析水文径流预测。其次,引入扩张卷积至标准LSTM中,利用其高效的特征提取,实现从水文数据中提取更高阶水文特征并过滤无用信息,提高LSTM隐藏层记忆单元处理效率。最后,通过加入残差链接,优化预测模型整体网络结构,直接跨层传输特征,简化整体数据特征学习过程,增强梯度传播能力。具体流程如下:
(1)初始化TCN模型结构及参数 在水文预测领域,由于复杂的自然气候原因,径流预测需要考虑多源水文因素的影响。输入通常为多维度水文数据,包括集水流域降雨量、上游径流量、流域蒸发量、损失量、气温等水文数据。鉴于标准TCN模型只有一维的卷积核,只能处理一维输入数据,故本文思路是将多个一维扩张卷积在多维度上进行并行操作,构造一组多个可分离一维卷积核并行网,以提取各维度上隐含特征信息,并进行特征融合,充分保留了不同维度上水文数据之间的关联性,并能大大提升模型运算效率。
一层多个一维扩张卷积流程示意图如图6所示。在图6中,输入数据I是一个由n种数据,总时间跨度为m的时间序列数据构成的n×m的矩阵,经过卷积层中大小为d×1,扩张因子D为2的卷积滤波Fn作用之后,输出T为n个特征图,其中第n个特征图由输入In与卷积滤波Fn进行扩张卷积运算,其计算公式为:
Tn=Fn×In。
(8)
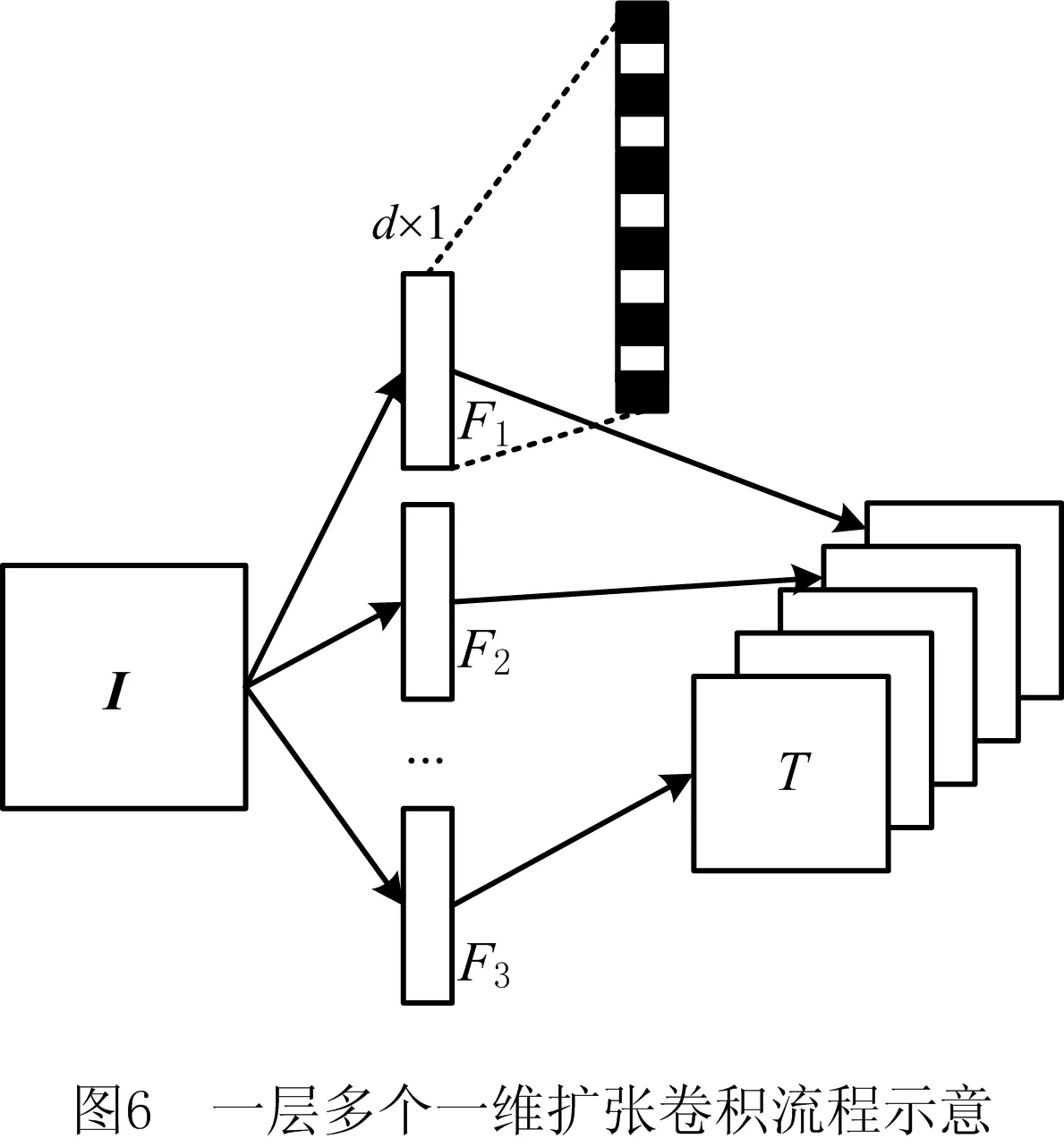
对于图6中演示的一层多维卷积操作,其感受野大小计算公式为式(9),即该层卷积核感受野为7×7=49。
rn+1=(2D+2-1)×(2D+2-1)。
(9)
针对TCN_LSTM中多层多维卷积网,感受野大小计算递推公式为:
(10)
式中:Si表示第i层步长,Kn表示第n层卷积核尺寸。卷积核尺寸计算公式为:
(11)
式中P表示网络模型中padding值。输入数据经过此类多次卷积操作后,其水文数据中包含的抽象特征被有效提取,且仍可保持各种类数据的内联性,经过多层卷积操作后通过TCN中全卷积层获得与输入维度相同的输出矩阵。
改进的TCN模型在保留原有扩张卷积与因果卷积特性前提下,从原来的单维水文数据覆盖至全种类数据维度输入,充分保证其能有效处理长历史水文数据,以及加快网络模型的训练速度,具有更良好的实时反馈感。
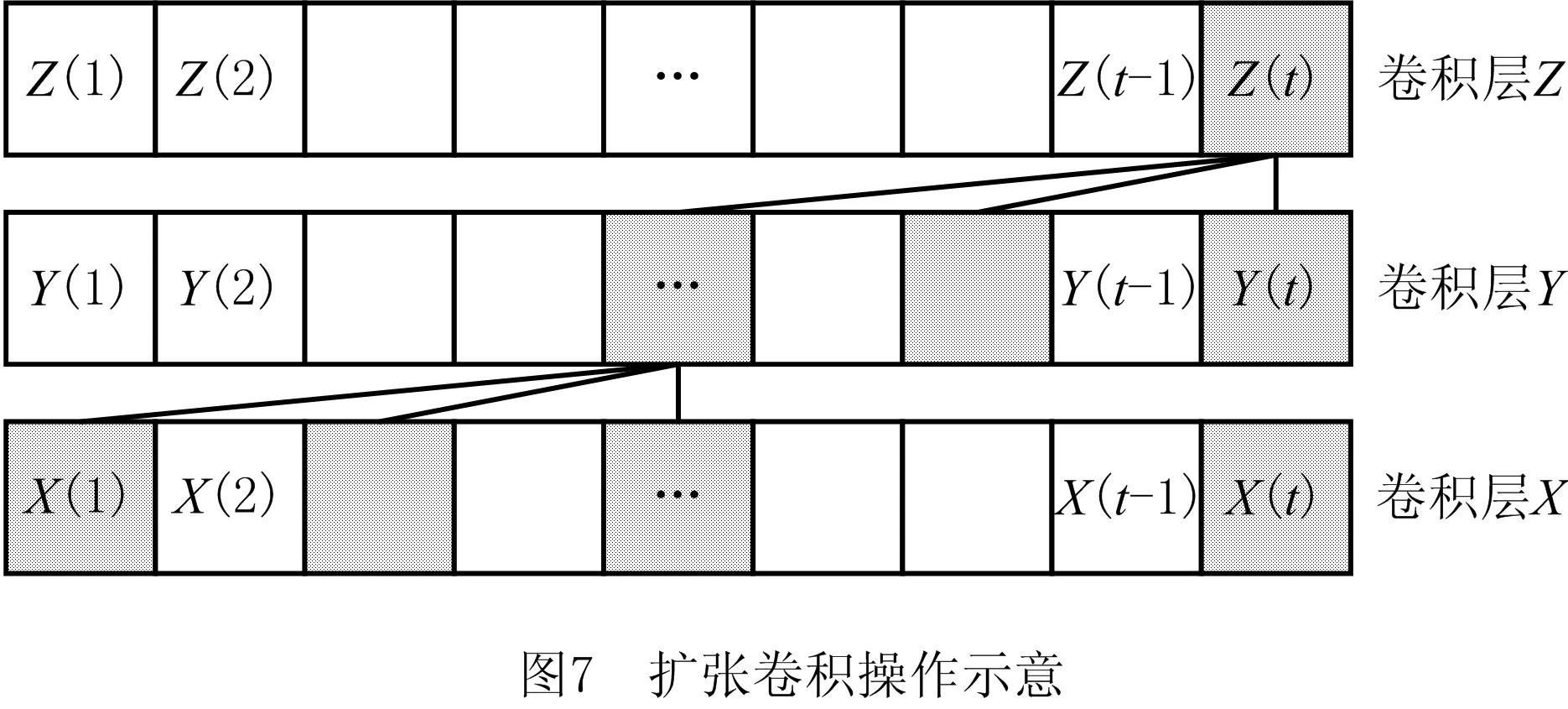
(2)初始化LSTM模型结构及参数 较标准LSTM模型在处理长期记忆上,因长历史、多种类数据优化存储能力不足而导致的预测精度下降、预测反馈延迟问题。本文通过在LSTM网络循环层之前加入扩张卷积操作来提取当前时刻t蕴含的依赖信息量,使得对于相同尺寸的输入数据,网络所含的感受野越大,提取所有数据所需的网络层数越少,显著简化了网络结构,优化了网络处理速度与预测精度。
扩张卷积操作示意如图7所示。图7中卷积核大小设置为3,扩张率为1,在t时刻卷积层Z所蕴含的有效信息是从卷积层X在时刻1~时刻t所蕴含信息中抽取的更高阶特征,能极大效率地过滤长时数据中包含的无用信息,同时能保留原有多维度水文信息之间关联性,减少后续处理的数据量,提升整体处理效率。
在水文数据经过卷积层处理操作之后,多维水文序列高阶特征经由全连接层进入循环层得到输出结果,然后将预测的结果与历史水文实测数据进行比较,利用输出层计算所得误差进行梯度反向传播更新循环层各参数配置,当达到最大迭代次数时,选取损失函数值最小的水文模型。
(3)为整体模型引入残差链接 考虑到改进TCN_LSTM径流预测模型需要学习长时间跨度下多维度水文数据,网络卷积层仍然具有非常庞大的数量,且经过多层卷积、压缩操作,依赖信息较原始信息仍有一定差别与丢失,故在网络模型中引入残差链接方式,使得网络能够跨层传输底层依赖信息,最大限度让输出层融合高阶特征与详细的底层特征,提升径流预测精确度。
一个残差块b包括直接映射部分与残差部分,其表达公式为:
(12)
式中:Xn表示第n层卷积层蕴含的依赖信息;C表示扩张卷积操作,即直接映射部分;F为不同层之间进行残差映射操作。本文模型中的卷积层由多卷积核并行构成,以进行深层次特征提取,同时设计并组合多个通用残差块来进行源数据多维度特征提取。在每一层残差块中包含两层扩张因果卷积和激活函数ReLU,并应用权重归一化到卷积核,此外在每次扩张因果卷积后添加dropout进行正则化以减轻源特征过拟合的发生。其结构图如图8所示,针对K层并行残差块,源数据输入各层残差函数中,为解决不同的输入输出宽度,额外利用一层扩张卷积确保得到相同形状的张量。

(4)径流预测 利用历史水文数据预训练得到最优模型,将测试样本输入模型中计算,最后得到径流预测数据,并与实际测试集进行比较,得到模型预测结果。
混合模型整体流程示意图如图9所示。整体模型在初始化模型结构、超参数以及对多源数据进行预处理筛选剔除错误数据,如0值、空值等情况,并利用相邻水文站数据进行补齐。随后,将多源数据进行多维矩阵构造,并作为数据输入,在卷积层对数据进行空洞卷积提取高维特征,该步骤可以有效减少高维网络层权值系数数量,也能大幅减少整体模型的时空复杂度。经由全连接层将卷积后的高维特征输入循环层进行计算,同时利用残差链接跨层将底层未经卷积层处理的数据传输至循环层,以防止复杂网络层多次循环导致的数据丢失与失真情况。随后记录每次迭代模型的损失值,记录每迭代一轮的最优模型,当达到最大迭代次数时,比较最优结果,输出损失值小的模型。将该最优模型作为最终结果,利用测试集进行测试,得到TCN_LSTM模型预测结果。

3 实例应用
3.1 研究区域概况
赣江位于长江流域南部,是长江南部第七大分支,属于鄱阳湖盆地水系统,面积为83 500平方公里,涵盖南昌、伊春、新余、九安,占鄱阳湖盆地总面积51.5%。赣江二级支流泸水河(安福县境内)从武功山南麓伊始,从属赣江2级支流,全长总共约120 000 m,并于吉安县城西汇入赣江的1级支流河水[52]。本文以沪水河流域为例,安福县沪水河流域水资源开发和利用已经处于相对较成熟阶段,到2009年底全县共修建116座电站(含在建10座),装机容量达6.83万千瓦时(可投产装机6.667万千瓦),丰水期小水电年发电量近2.0亿千瓦时[53-54]。
社上水文站于1957年设站,有1958~1961年的水文、气象观测资料,1962年1月撤消,改为社上水库站,1976年开始在坝上设立水尺观测水库水位,同时观测降雨量,保存有1976~2015年水位、降雨观测资料。
东谷水文站位于江西省安福县横龙镇东谷村,1979年4月由吉安地区水电处为东谷水库设立的专用水文站,现属江西省水文局领导。2005年停止测流,保有有1979年5月~2004年的水位、流量、降水量资料。东谷水库建成后设立东谷水库站进行监测水库水位、降雨量,保有有2010~2015年的水位、降雨量观测资料[55-56]。
因此,以泸水河流域径流序列数据提取变化特征,构建合理的径流预测模型,为该流域内水电站及水情环境研究提供了科学支持,对当地合理运用水资源,改善生态环境,开展水资源规划,推进当地生态文明建设和可持续发展有巨大作用。
3.2 模型输入输出确定
为了验证改进后TCN_LSTM耦合水文模型在目标流域月径流预测能力,本文研究就水文站月径流量建立TCN_LSTM预报模型。模型输出层输出为径流的回归结果,即该水文站当月径流量,模型的输入为水文站历史观测水文、气象及时间数据,包括该站点降雨量、当地气温、区域内径流蒸发量、径流渗透量、实测径流量、平均风速以及时间节点,共10项影响因子。由于影响水域径流量的物理成因预测方法结果更优[56],且为避免各因子之间高相关性造成的预报有误,本模型在输入层处理时运用主成分分析方法[57]对初定的影响因子进行数据降维,降低数据之间的相关性。输入层数据长度m根据历史观测数据长度进行计算,构建成一个10×m维度的矩阵,输入网络模型进行计算。
3.3 评价指标选取
为评估预测结果的精确性和有效性,本实验采用均方根误差(RMSE)、平均绝对误差(MAE)及纳什系数(NSE)评价指标来进行预测精度的评价,具体计算公式如下:
(13)
(14)
(15)

RMSE为均方根误差的算术平方根,取值范围为0到正无穷,其取值越小表明模型拟合越优,越具有更高的精确度;MAE是平均绝对误差,是绝对误差的平均值,能很好地反映预测值误差的实际情况,其取值范围为0到正无穷,值越小表明模型误差越小;纳什系数NSE用于评价模型精度,一般用于验证水文模型模拟结果好坏,其范围为负无穷到1,数值越接近1,代表模型精确度越高,若NSE数值为负数则表明模型无法正常完成模拟。
3.4 模型参数实验及分析
改进TCN_LSTM模型由前文介绍及式(9)和式(10)可得,隐藏层层数nTCN、扩张因子DTCN及卷积核大小K对于TCN模型性能有关键作用。同时,由经验法推论可得,扩张因子DLSTM及隐藏层层数nLSTM对于LSTM模型的“输入层”特征提取和预测性能有重要影响,故本文采取相应对照实验来分析隐藏层层数、神经元个数、扩张因子及卷积核大小对于改进TCN_LSTM模型的整体影响。
本实验中扩张因子D分别取4、8、16,卷积核大小K分别取3、5,隐藏层层数nTCN、nLSTM分别取4、8和64、128,共组成36个实验,如表1所示。其中,卷积核数量固定为32,采取训练次数为800,学习率为0.01,损失系数为0.4,其他参数保持不变。最终分别通过对比各实验组训练集和测试集在NSE系数上的表现来选择最佳参数组。

表1 TCN_LSTM模型参数选取对照实验
通过选取不同参数进行模型训练集和测试集验证,得到各个组别实验的最终实验结果如图10所示。
通过对照观察组别1、2、3、4及5、6、7、8可得出当保持nLSTM不变,增加一定扩张因子、隐藏层层数nTCN、卷积核大小后对于整体模型的精度提升较高,其中扩张因子对于精度的影响更为明显。
通过对比1、2、3、4及20、21、22、23、24组别,训练集和测试集的精度差异随着模型参数及网络层参数量的增加而逐渐产生较大差异,可发现随着nLSTM、nTCN、D等参数增大,模型的过拟合现象逐渐明显,对于模型精度影响较大,由经验分析法可得出在当前数据规模及权值学习迭代次数下,模型复杂度已无法支持继续加深。

结合图10NSE系数结果对比分析5、6、7、8、9及13、14、15、16、17组别可得出,在模型可承受范围内,逐步增加nLSTM、nTCN、D等参数可得到正反馈结果,模型精度在训练集与测试集上得到正向提升。
通过对比组别13、14、17、18、19、20可得出,扩张因子的增大对于输入层特征抽取有正向作用,但随着隐藏层层数的增加,在提高模型复杂度的同时起到负向作用,反而加大了模型过拟合现象的产生,表现为在训练集上有更高的精确度,却在测试集上表现不佳,如组别19、20所示。
由上述分析可得,本文改进TCN_LSTM模型选取参数组合为扩张因子D=8,隐藏层大小分别为nTCN=4、nLSTM=128,卷积核大小为K=5。此时,本文模型有着更优的预测精确度,后续对比实验中均采用此参数。
3.5 对比实验及分析
本文针对社上、东谷水文站的历史水文、气象数据进行模型与实验,数据分配情况如表2。

表2 水文站数据训练及测试分配情况
《水文情报预报规范》中规定预见期超过流域最大汇流时间,且在三天以上一年以内的水文径流预报允许误差范围为变幅的20%内,其中相对误差计算公式如式(16):
(16)
式中:xt表示t时刻径流实测值,yt表示t时刻径流预测值。
本文分别选取东谷水文站2002年和社上水文站2013年场次数据为例进行水文预报合格率检查,具体数据如表3。
分析表3中实验结果可知,改进TCN_LSTM模型得出的预测值在相对误差值上是完全符合水文情报规范中要求的中长期径流预测要求的。

表3 水文站径流量数据抽样实验结果
为更好地展现本文提出的混合模型在月径流预测中的精确性,同时选用日前径流预测领域技术选型较多的BP模型[58]、SVM模型[59]、GRU模型[60]、RNN模型[61]、TCN模型[20]、ANN模型[62]、LSTM模型[63]以及本文TCN_LSTM模型对数据样本进行拟合实验,进一步对比8种模型在水文径流变化趋势中的差异。考虑到各模型间不同超参数设置会对预测结果有一定影响,本文在原模型的基础上经过交叉验证、多次试错以及以往经验参考得出针对本文数据集的最佳参数。各模型主要设置如下:
(1)BP神经网络选用单隐藏层结构的三层模型。考虑到输入层及输出层节点数分别为9、1,通过经验公式计算可得隐藏层节点数最佳为8,误差控制率为0.001,学习系数为0.01,隐含层传递函数为poslin,输出层传递函数为purelin,学习函数采用trainlm。
(2)SVM模型在顾哲衍等[59]工作的基础上,经过多重交叉试错后,确定最佳惩罚系数为500,ε值为1.5,γ值为0.001。
(3)GRU采用单层模型,其中神经元节点数为32,隐藏层层数为3,丢失系数为0.3,学习系数为0.01,优化器采用Adam,激活函数采用softmax。
(4)RNN与LSTM采用单层模型,隐藏层节点数为32。
(5)ANN模型隐藏层节点数为32,隐藏层层数为3,学习率为0.01,激活函数为ReLu,损失系数为0.3,学习率为0.01。
(6)TCN模型每层扩张系数为[1,2,4,8,16],每层卷积核大小设置为5×5,卷积核个数为32。
本文实验结果如表4和表5所示。
表4为各预测模型结果评价指标对比。由表4可知,通过与其他常用于时间序列的神经网络算法对比,TCN_LSTM模型在RMSE、MAE及NSE等评价指标上具有更优秀的表现,结果也更加准确。本文TCN_LSTM模型预测结果相较于单一TCN、LSTM模型在实验结果上的差距远远小于传统RNN、ANN等常用模型。NSE作为一项常用来评估水文模型好坏的指标,由表4可知,TCN_LSTM模型NSE值在东谷和社上水文站分别为0.98和0.96,结果均比LSTM、RNN、TCN等模型有提高,表明TCN_LSTM模型在进一步结合多源数据特征,提取对预测结果正相关的特征上具有更加优良的效果,从而证明了该方法提高径流预测精度的可行性。

表4 水文站径流量在不同模型下标准差对比
表5为各模型之间计算效率的对比实验。通过各阶段模型训练轮次中最优平均绝对误差值(L1_loss)和均方误差值(L2_loss)的比较可知,TCN_LSTM、LSTM、TCN、GRU能较RNN、ANN模型更快拟合水文数据,获得更优的径流预测模型,其中RNN、LSTM、GRU模型因其自身时间连接特性导致计算时数据量随着循环层迭代、特征积累,其需要更大的显存空间,故在训练时间上需耗费更多时间,GPU计算速度较CPU优化效率不高,甚至存在下降趋势。GRU较LSTM在网络结构上进行优化,极大减少了训练所需参数量,提升了模型拟合速度,但是最终在训练轮次达到1 000轮以上时,GRU模型损失值难以收敛,精度提升上限不及LSTM。BP模型通过不断对数据样本进行训练,达到网络权值与阈值修正,实验采用的单隐藏层BP模型通过各隐藏节点来逼近需求中的“非线性函数”,虽然训练速度极快,但是模型结构限制导致收敛速度很慢,收敛最终效果欠佳。ANN模型实质是将输入时序数据到输出结果的非线性函数变换,网络结构较其他模型更为简单,训练速度较其他模型更快,虽然在GPU上能适应并行计算,且速度较CPU有一定优化,但变化较小,损失值较高。TCN模型内核是基于卷积操作,对于“记忆”数据提取与计算具有更优效率,且易于进行并行化操作,因此在模型迭代计算上能较快获得更优收敛性,同时在GPU平台上能进行更高效计算。由表5损失值随训练轮次变化可得,ANN模型在整体训练阶段损失值变化一直处于较高的水平,随着轮次进行,损失值难以降低,模型难收敛。同比RNN模型、GRU模型与LSTM模型需保持较多的训练轮次才能得到较优模型,如LSTM在300轮以上能达到较优收敛性,GRU在300轮训练时模型已形成收敛趋势且训练所需时间更短,RNN则需1 000轮之后才能达到较低收敛值。模型拟合需大量的时间与数据进行计算,而数据特征的堆叠易于造成特征量计算爆炸,影响计算效率。反观本文提出的TCN_LSTM,基于循环层基础上利用卷积抽取‘时序’特征并行进行计算,提升模型计算效率,使得整体模型能以更少的训练轮次、更短的训练时间获取更高拟合度的径流预测模型,证明了本文方法通过引入卷积操作、残差链接,加快数据特征抽取与传输速度,提高模型计算效率的可行性。

表5 不同模型计算效率对比
图11为东谷水文站2012年至2015年径流量各模型的预测结果对比图,图12为社上水文站2001年至2004年径流量的拟合曲线对比图。从图中可以看出该段数据集波动频率较高,振幅较大,对于模型的精确性检验具有一定参考性。分析结果如下:
(1)观察图11a~图11c和图12a~图12c发现,本文提出TCN_LSTM模型相较于单一TCN与LSTM模型在预测整体趋势上具有更高的耦合性与周期内更低的振荡性,整体预测精度更加准确。从图10c和图11c可发现,TCN模型在整体趋势上依然具有较优的精确度,在数据密集时间段能保持良好的预测稳定性,但是随着时间跨度加大以及数据源因不同地区而表现不同时空特征时,模型预测趋势波动较大,精确度变化幅度呈不稳定趋势,模型的普适性低于LSTM模型。从图10d和图11d可发现,LSTM模型在面对不同区域及长时间跨度下时空特征数据具有优于TCN的稳定性,但是也不难看出,在部分数据密度较大时间段内,模型预测趋势波动也较大,分析原因是LSTM模型门控结构虽然能支持低维度下更长时间跨度的数据记忆,但是不具备类似因果卷积与扩张卷积在数据特征上的强泛化能力。从图10a和图11a可发现,面对复杂多变情况下,本文提出的TCN_LSTM模型在数据特征泛化能力、长跨度下数据记忆能力与不同区域下预测模型稳定性都优于单一的TCN与LSTM模型,由图中可看出在东谷水文站及社上水文站预测曲线一定程度上能近似地耦合真实径流曲线变化趋势,较单一的TCN与LSTM模型预测曲线精度有明显提升,基本能对高频率、大振幅、复杂地域下的数据集有更加友好的预测表现。
(2)观察图11a、图11c~图11e和图12a、图12c~图12e,可以看出改进后的预测模型比常用的RNN模型、LSTM模型、GRU模型精确度更高。观察图11d和图12d可发现RNN模型在波动频率较为密集的周期内拟合效果较差,分析其原因为RNN循环单元按链式链接,序列输出为多层递归的结果,前部序列信息在传递到后部时,信息权重下降,信息丢失,造成RNN预测结果在后续阶段波动变化大,结果不准确。GRU模型为LSTM模型的变种,故可同时观察研究图11c、图11d和图12c、图12d由图中可发现LSTM模型拟合度较GRU表现更好,对比两者结构与常用场景可发现GRU为达到简化模型目的,将忘记门与输入门合成为单一更新门使得参数量较LSTM减少至少三分之一,大大地加快了训练,也导致模型收敛更快,训练过程中对于时空特征精细化抽取较LSTM难以提升效率,表现为在数据震荡密集复杂的时间段精确度有明显下降,即牺牲精度换取速度。面对本文复杂多变的时空特征情况,GRU模型拟合度不如LSTM。
(3)观察图11a、图11f和图12 a、图12f,SVM模型实验结果表明,单SVM模型对于模型拟合程度欠佳,分析原因为当样本量、样本特征维度提高,SVM模型自身结构限制了计算效率与计算准确度,也表明了随着现实情况复杂度上升,纯数学模型或机器学习算法作为主要支撑的预测模型难以满足现实需求。
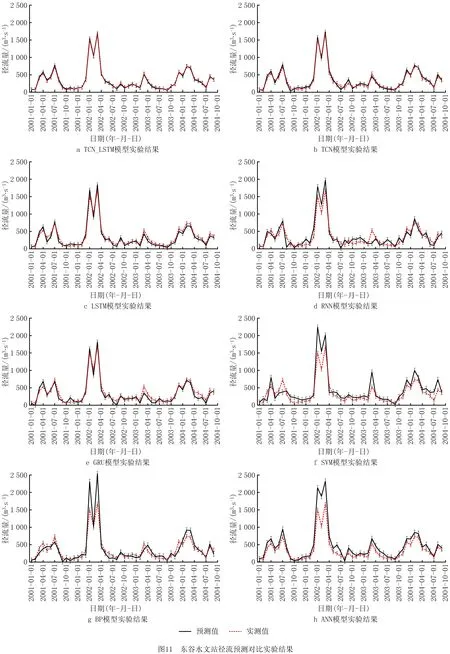

(4)观察图11a、图11g、图11h和图12a、图12g、图12h,人工神经网络与BP神经网络相较于实验中其他常用时间序列处理的对比模型结构上更为简单,计算时间响应上也更为快速,但从图中对比可发现,同等数据量下,ANN模型与BP模型在结果集上精确度较低。观察图11g和图12g可发现,ANN模型整体趋势上与实测曲线大体拟合,但对于精度值存在误差较大,究其原因是模型学习体量需求巨大,现有数据集无法满足该模型学习能力,并且现有模型结构导致其无法有效降低本文数据集存在的噪声影响,仍需花费未可估计的时间与精力去评估与测试ANN模型超参数集与模型结构,整体来说不适用于本文情况。观察图11h和图12h可发现,本文选取的单隐藏层结构BP神经网络表现拟合度欠佳,与实测曲线相差较大,分析原因为其结构体量相较于其他模型过于简单,对于多维时空数据特征处理能力较弱。模型本身对于超参数与结构的调整上限较其他模型更低,预测稳定性也处于较低状态,且与ANN模型同样需要耗费更多的精力与时间来进行模型调整。反观图11a和图12a曲线大致拟合情况与表3中标准差的实验结果相符合,说明改进TCN_LSTM模型能够充分利用时间卷积网络与长短时记忆网络的各个优点,针对长时数据有更加有效的处理,以及更优良的多源数据高阶特征提取操作,充分优化整体模型网络结构,避免梯度爆炸、消失造成的结果失真,整体模型优于改进前的单个模型效果,更加符合流域实际的产汇流情况,满足实际生产应用需要。
4 结束语
本文基于改进TCN和LSTM模型建立了月径流量水文预测模型TCN_LSTM,支持多源水文、气象数据输入,并以赣江二级支流泸水河上社上水文站与东谷水文站作为研究区域进行改进模型的径流预测效果研究,为该流域水文径流模拟提供了一种有效的研究思路,具有理论意义与实用价值。本文研究得出如下结论:
(1)本文改进后的耦合水文径流预测模型在均方根误差、平均绝对值误差及纳什系数上平均值分别为32.88、26.63和0.97,精度相较于常用单一神经网络模型如RNN、LSTM、TCN、ANN模型都有显著提高,且有更低的损失值。表明该模型在该流域的产汇流拟合情况极佳,能很好适应该支流的水文预测情况。
(2)改进后的耦合水文模型在水文数据变化频率快、振幅大上的表现相较于其他模型更优,从实验结果中可看出,改进模型能有效利用更长时间跨度的多源水文数据,同时提取高阶特征与利用低阶特征进行预测,预测结果基本符合水文预报规范规定,也更加拟合实测数据集。
本研究仍存在可深入研究空间,未来可从如下方面进一步开展:
(1)本文研究对象的局限性问题 考虑到泸水河流域相关气候研究较成熟,径流过程季节性趋势较明显,水文数据完备,故以此为分析对象,导致研究场景未覆盖其他具备不同径流过程和气候特性的流域。在未来研究中可以此为方向进行本文模型的鲁棒性验证,扩展模型所能处理的流域类型范围,推动模型的完善。
(2)研究场景的可深入挖掘性 无法否定的是径流过程是一个综合各方面因素的复杂形成过程,随着自然环境中人为因素的影响加深,未来不能仅仅从历史显性水文影响因子上进行研究,更应该深入分析挖掘隐性因素,探寻整体径流过程中的内在规律,提升预测精度。
