学生在线学习行为分类融合方法的研究与应用
2022-12-02李菲曹阳顾问
李菲 曹阳 顾问
(三江学院计算机科学与工程学院,江苏 南京 210012)
1 引言
学生学习成绩预测一直是教育界研究的热点,尤其在当前疫情期间,居家学习和在线教学成为常态,如何有效利用信息技术,加强学生学习效果识别和预测,是教育领域的难点和重点。学生成绩预测帮助老师及时调整教学方法、监督和提醒学生,从而提高学生的最终学习成绩。
在线教学借助中国大学慕课MOOC、超星、腾讯课堂等平台,使用腾讯会议、QQ教室等工具,相比传统教学,形式更灵活、学生学习行为更多样化,这对教师的教学方法提出更高要求。刘茜萍等[1]在疫情期间,根据课程特点,综合应用多种不同的教学平台设计互动教学方案,提高教学质量。陈逸菲等[2]利用SPOC课程教学的学习行为数据,从中找到对成绩影响最大的学习行为,实现数据驱动的混合式教学方式。除了改进教学方法外,机器学习方法、神经网络技术也应用在线教学数据分析中,帮助预测学习成绩,提升学习效果。邓天平等[3]采用聚类技术,结合慕课堂线上学习数据和线下考试成绩,对学生进行聚类并分析各学习行为和成绩之间的相关性。郎波等[4]根据学习平台上的日常学习数据,选取影响因子,采用BP神经网络和遗传算法,对学生成绩进行预测。曹洪江等[5]分析学生历史成绩的时序性,结合学习过程的遗忘特点,引入LSTM网络进行建模,成绩预测取得了较好的准确性。另外,考虑学生对课程的主观情感因素,叶俊民等[6]针对学习社区的短文本情感特征,训练深度学习模型。以上研究方法大多采用单一的神经网络模型,即输入学生的知识结构和学习情感,没有从线上教学实际出发,考虑学生学习行为的多样性,因此本文分析学生在线学习的行为特点,提出融合LSTM网络和感知机MLP的预测模型:
(1)根据学生在线学习的周期特点,将学习特征分为每周学习特征和整学期学习特征两大类;
(2)对每周学习特征,使用长短期记忆神经网络建模,模拟学生周期性学习过程,对整学期学习特征,采用MLP网络建模;
(3)将LSTM网络和MLP网络融合,完成学生成绩预测。
2 融合模型
学生学习成绩预测,通常使用学习过程中学生的若干行为特征,构建合适的学习模型。学习成绩预测模型可以用数学符号表示如下:
(1)学生课程成绩按照5个等级记录,分别为优秀、良好、一般、及格和较差,记为y∈[0,1,2,3,4],y(i)=3表示第i个学生的成绩及格。
(2)学生每周学习行为,记为Pikj∈Rq,k∈{1,…,k},k代表一个学期的学习周数,q代表每周的学生行为数据的维度[7],例如学生Si在k周(共16周)产生的学习行为特征序列为Pi=[Pi1,Pi2,…,Pik]。学生的每周学习行为有明显时序特点,可通过长短期记忆时间网络LSTM训练。
(3)学生学期学习行为,记为E=[ec,ez,eg,ep],ec为单元测验成绩、ez为单元作业成绩、eg为结课成绩、ep为课程评价。
对学生学习效果进行预测,整个过程由采集学生学习数据、提取学习行为特征、构建学习模型和模型效果评价。(1)从中国大学MOOC平台、腾讯会议收集学生在线学习数据;(2)提取每周学习行为和学期整体学习行为,并进行数据优化和清理;(3)对每周学习行为建立LSTM模型,并融合学期整体学习特征,构建学习效果预测模型;(4)通过常见的性能评价指标对预测模型进行评价。预测模型框架及处理流程如图1所示。

图1 预测模型框架
2.1 数据源信息采集
课题数据来源于三江学院计算机学院软件工程专业和计算机科学技术450名学生在软件测试课程的学习数据,每个学生数据分别从中国大学慕课MOOC在线开放课程、慕课堂、腾讯会议记录中获取,并结合线下学习情况:(1)在线开放课程记录包括单元测验、单元作业、结课成绩、讨论区发言个数、获赞数、课程评价;(2)慕课堂记录包括考勤、点名、随堂练习成绩、讨论次数、优秀发言次数、视频观看次数、视频观看个数、视频观看时长;(3)腾讯会议学习记录包括入会情况、课堂表现,课堂表现可认为是线上课程的学习积极性,在实际教学中设置为“网课活跃度”行为特征,以量化学生线上学习参与程度。授课教师采用腾讯会议的投票功能,投票主题为知识点问题,学生对各选项进行投票选择,实践表明线上教学中学生不会主动参与话题讨论,但大部分学生能积极投票,因此网课活跃度反映学生的参与程度,学生每参与一次投票活动,增加一个网课活跃度;(4)线下学习主要数据为期末考试成绩和实验成绩,期末考试成绩作为预测目标数据。
利用这些学习记录,从线上线下多个维度综合体现学生的学习情况,反应学生的主动学习态度和实际知识掌握程度,是学习成绩预测的主要依据。
2.2 数据处理及归类
学生学习数据采集后需要进行分析,处理学习记录中缺失、重复的异常情况,对学生的课程评价完成情感分析,具体操作如下:
(1)部分学生的学习记录有缺失。个别学生没有加入学校在线开放课程,单元测验和单元考试学习记录为空,只有慕课堂记录和线下成绩。对这部分学生的缺失数据以0计算。
(2)部分学生的学习记录有重复。有部分学生使用多个账号登录学习,产生多组学习数据,例如学生使用微信扫码登录慕课堂,使用认证账号登录在线开放课程,因此有两组数据,需要教师手工合并为同一组数据。
(3)学生课程评价情感分析。学生对课程评价属于主观感受,且非实名评论,因此对这部分数据要进行处理:首先学生评价时采用昵称,教师从后台数据库关联学生学号姓名;其次,并非所有学生都给出评价,参与评价的学生约占总人数的2/3;另外还存在一些无效评价、重复评价;最后,有的学生评价比较隐晦,没有明确表达自己对课程的情感。综上,我们在删除重复和无效评价基础上,采用自然语言处理技术,对学生评价短文本处理,获取学生的课程情感,设定为中立、消极、积极三个等级。
学生课程评价,采用SnowNLP进行情感分析。Snow NLP是使用Python编写的开源情感分析程序,其本质是贝叶斯分类[8],通过pip3 install snownlp安装,该库计算语句情感sentiments,分值范围为0~1,分值越高表示其越正向,我们设定sentiments>0.5为积极,=0.5为中立,<0.5为消极。
SnowNLP来源于电商评价,泛化能力存在一定局限性,因此我们结合结巴分词,使用textrank关键词提取,强化分词,以提高情感评价准确性[9]。例如有学生评价:“虽然我学的不是软件专业,但是这门课还是教会了我很多东西”。SnowNLP评价sentiments值为0.61,判断为积极情感,但通过结巴分词textrank后,sentiments为0.73,进一步加强了情感导向。
学生原始数据处理后,根据学习数据特点,将这些数据按时间维度分为每周学习记录、学期整体记录两大类,如慕课堂中每周签到、随堂练习记录归为周数据,一学期软件测试课程教学周期为16周,因此每个学生有16次周数据。分类后的学生学习行为特征如下:
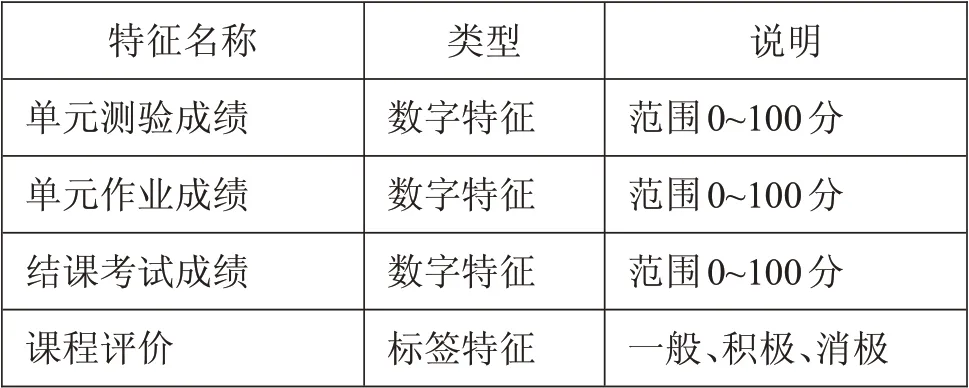
表1 学期整体学习行为特征
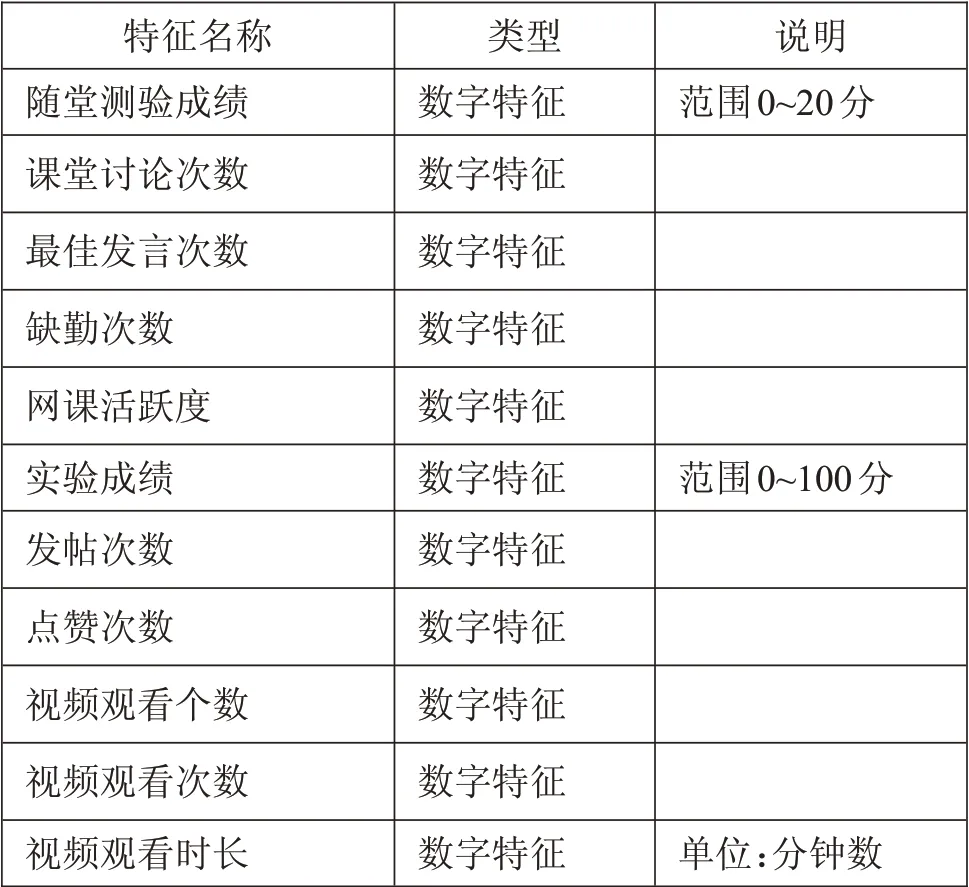
表2 每周学习行为特征
学生数据经过清洗处理后,还需要根据特征类型进行优化处理,针对标签类型的学习特征,采用one-hot编码,将标签分类转换为哑变量(Dummy Variable);针对数字类型的学习特征,采用归一化处理,通过最小-最大标准化映射到[0,1]区间,公式如下:

2.3 建模
当前在学生学习领域的研究,往往使用独立输入的神经网络模型[5,6,10],即网络只有一个输入和一个输出,而且网络是层的线性堆叠。学生学习成绩预测问题,包含多维度学习行为特征,网络模型需要多模态输入,使用不同类型的神经层处理不同类型的数据。虽然可以训练多个独立的模型,对预测值做加权平均,但因为模型提取的信息存在冗余,因此针对本课题的实际情况,构建一个具有多输入分支的网络模型,学生周学习数据采用LSTM网络,学生学期学习数据采用MLP网络,用一个可以组合多个张量的层将这两个不同的输入分支合并。整个模型的结构如图2所示。
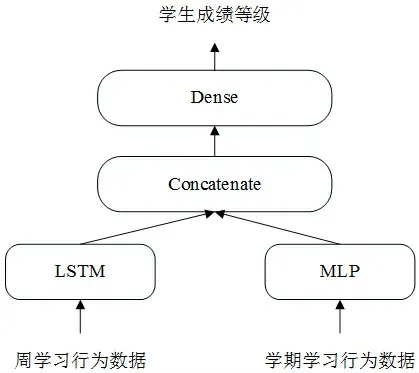
图2 学生学习成绩预测融合模型结构
(1)学生每周学习情况具有时序特点,每周学习情况动态反映了学生的学习效果,对后续学习产生影响。LSTM能够学习长期依赖关系,建立远距离因果联系,因此适合学生周期学习特征,输入学生的时序数据,输出具有代表性的行为特征,体现学生在不同时刻的学习状态。
在LSTM网络中,用门的开关程度来决定对哪些信息进行读写或清除,有遗忘门、更新门、输入门。LSTM通过遗忘门的Sigmoid激活函数实现遗忘不重要的信息,例如学生第一周的部分学习内容对第二周的学习帮助不大,因此学生在第二周的学习会丢弃这部分内容。遗忘门公式为:

LSTM通过输入门将有用的新信息加入到记忆单元,计算公式为:
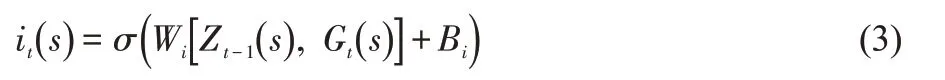
LSTM的输出门,从当前状态中选择重要的信息作为输出,输出门ot(s)得到当前时间步的学生学习状态,即输出ht(s),计算公式为:

以上公式中W是权值矩阵,B是偏置,⊗表示点积。
(2)学生的学期学习特征,由单元测验成绩、单元作业成绩、开放课程结课考试成绩、学生课程评价情感4个特征组成,代表学生在该学期中的整体表现,设定为MLP网络,作为学生评价模型的另一个输入,和每周学习的LSTM模型实现融合。
把学期整体情况的输出端和每周学习情况的输出端合并起来,采用keras自带的concatenate函数,形成融合模型的输入,再接上一个全连接层,完成整个模型构建。全连接层采用激活函数ReLu,模型优化器为rmsprop,损失函数为categorical_crossentropy,迭代次数Epoch为500轮,输出层采用softmax预测学生最终成绩等级。
3 实验结果与分析
实验数据集为2.2节处理后的学生课程数据,评估指标采用精确率(Precision)、召回率(Recall)、F值(F1-Score)进行模型分类预测性度量。精确率是模型正确分类的正例样本数与总的正例样本总数的比值;召回率是模型正确分类的正例样本数与分类正确的样本总数的比值;F1值是准确率与召回率的调和平均,综合体现精确率和召回率,F1值越高,分类效果越好。

其中,TP表示学生标签为正例,被分类为正例;FN表示学生标签为正例,被分类为反例;FP表示学生标签为反例,被分类为正例;TN表示学生标签为反例,被分类为反例。
为了展示本文模型的整体性能,将本文提出的融合网络和支持向量机SVM、逻辑回归LR、多层感知机MLP进行对比实验。实验结果如表3所示。
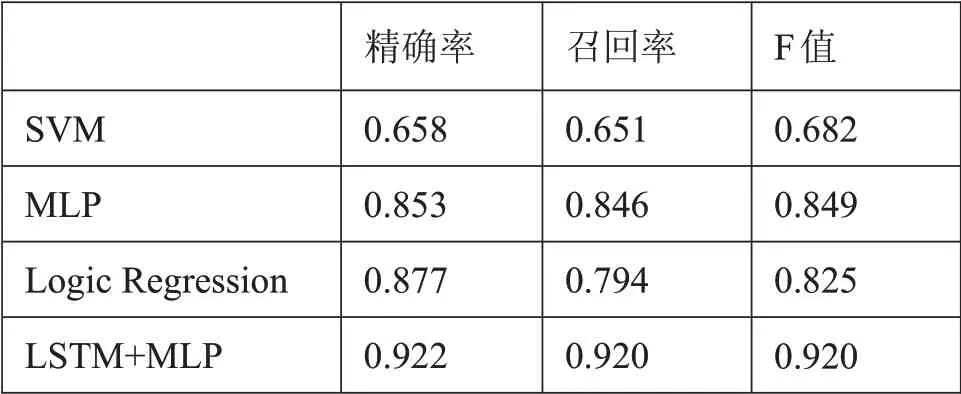
表3 实验对比结果
从表3的实验结果可见,LSTM+MLP融合的网络模型,在精确率、召回率和F值上取得最优值。对比实验中其他算法预测准确率不高的原因,分析可能对所有的特征信息进行随机分类训练,在训练时没有区别性对待各属性特征对学生成绩的重要程度,LSTM捕获了学生的序列信息,考虑每周的行为信息,加强了重要属性特征提取,结合学期学习行为,大大提高了模型的预测分类效果。
4 结语
本文针对在线教学现状,提出了一种LSTM和MLP融合的学生成绩预测方法,将学生学习数据分为周期性和整学期两种类型,周学习数据采用LSTM网络建模,学期数据采用MLP建模,这两种模型融合使得预测能力更强,有效提高学生成绩分类的准确性。在本校软件测试课程上进行实验,实验结果表明,本文提出的融合模型取得较好的预测效果。未来的工作主要对学生学习行为之间的关系、学习行为与最终课程成绩之间的关系采用更先进的神经网络表达,着重分析各类关系及关系权重,提高预测结果,准确反应学生的主动学习态度和实际知识掌握程度。
