基于句法和语义的英汉翻译记忆系统设计研究
2022-12-02董菊霞
董菊霞
(平顶山学院,河南 平顶山 467000)
1 引言
互联网技术的快速发展,促进了机器翻译系统开发,借助互联网平台,实现系统数据库信息实时更新,为用户提供网络访问连接[1]。该系统支持多种语言的相互转换,能够为用户交流提供便利条件。目前,机器翻译系统主要分为两种类型,分别是语料库翻译、语法分析翻译[2]。相比之下,语料库翻译技术发展较好。由于自然语言历经多年发展形成,人们针对相同的语言理解存在一定差异,因而降低了机器翻译的准确性。面对重复率较高的文件翻译工作,耗费时间较多[3]。翻译记忆技术的提出,打破了传统机器翻译模式,能够缩减重复语句的翻译时间[4,5]。由于翻译记忆技术研发时间比较短,尚未形成完善的英汉翻译记忆系统。本文尝试将语义和句法作为译文指标,开发一套英汉翻译记忆系统。
2 英汉翻译记忆
2.1 英汉翻译记忆方法
翻译记忆指的是将以往翻译任务获取的经验作为信息基础,开展下一次翻译任务,在此期间使用的系统,是翻译记忆系统[6]。本文提出的英汉翻译记忆,是以英语和汉语作为翻译相互转换的两种语言,运用翻译记忆系统,在记忆库中搜索相似资源,作为译文参考依据。用户在使用该系统过程中,以系统提供的资源作为辅助翻译工具,根据自己的理解,调整最终翻译结果,以此提高翻译效率。当系统处理新的翻译任务时,将此任务与数据库中资料进行匹配,生成相似译文,作为翻译参考依据,用户根据译文情况,选择接受此翻译结果,或者在此基础上做出更改[7]。当本次翻译结束后,相关翻译信息将被存储至记忆库中。随着使用时间不断积累,记忆库中的资源就会逐渐增加,有助于翻译效率的提升[8]。
2.2 英汉翻译记忆作业流程
英汉翻译记忆方法涉及的主要技术有相似度计算、记忆库技术、译文构造技术[9]。运用这3项技术,对数据进行检索、资源匹配、人工校对等处理,从而生成翻译结果。本文提出的英汉翻译记忆系统,从记忆库中检索相关数据,与原文数据进行对比,完成英语和汉语之间的转换处理。如图1所示为英汉翻译记忆作业流程。
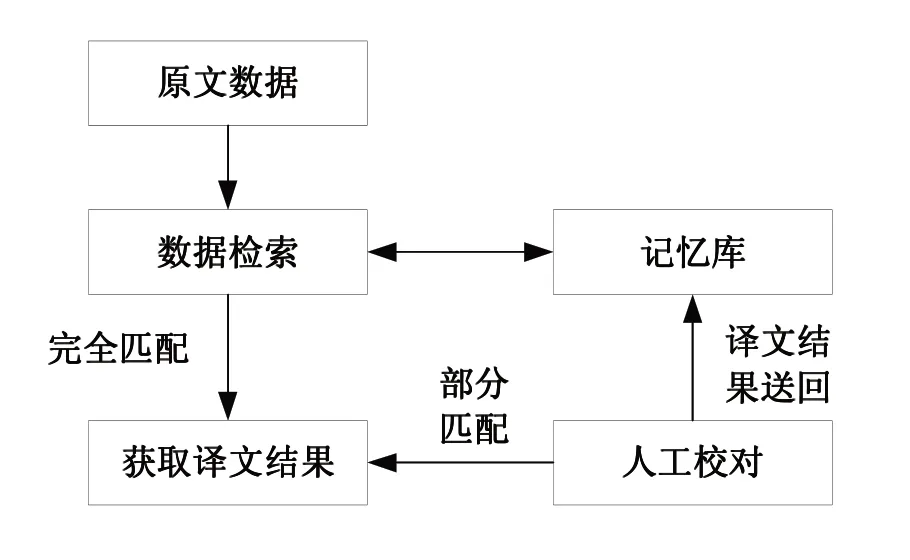
图1 英汉翻译记忆作业流程
首先,根据原文数据,调用记忆库中的信息,经过数据检索,寻找与之匹配的译文资源。接着,对比检索译文资源与原文数据是否完全匹配,如果完全匹配,则生成译文结果。反之,采用人工校对的方式,对本次译文结果进行校对,同时将校对相关信息存储至记忆库中,以此丰富记忆库中的译文资源,同时优化译文标准。
3 基于句法和语义的英汉翻译相似度算法
翻译相似度算法作为翻译记忆系统开发的核心工具,以语义和句法作为翻译相似度判断指标,分析英语句子和汉语句子的译文是否匹配。一般情况下,相似度范围[0,1],数值越接近1,则认为翻译语句与原句越相似,从语义、句法两个方面来看都是满足翻译意思标准的[10]。另外,单词排序同样符合译文要求。如果相似度数值接近0,则认为两个语句之间不存在联系,语义和句法几乎都不同[11]。本算法中,利用[0,1]范围内数据表示译文句子之间的相似程度。
关于相似度算法的开发,首先利用Link Grammar Parser软件计算需要翻译的句子,获取该语句的句法结构[12]。其次,判断生成的句法结构与原句的句法结构是否相同,如果完全相同,运用算法继续计算获取语义,并判断生成的语义与原句的语义是否相似。其中,句义相似度的判定,以句子中的各个组成部分作为判定对象,分别对各个部分的语义相似度进行判断,得到综合判断结果,从而避免译文句子与原句之间实际相似度与计算结果产生偏差。例如,句子s1:TIFF IFD entry value has wrong size.句子s2:TIFF IFD entry has invalid value.对这两个句子的相似度的计算,首先进行拆分,而后分别计算各个对应词组的相似度。词组1:(TIFF IFD entry),(TIFF IFD entry value);词组2:(has),(has);词组3:(invalid value),(wrong value)。这种相似度方法,与传统方法中计算宾语value方法不同,给出的主要成分entry和value更加贴近实际语义。假设句子成分数量为n,利用句子成分字符串计算得到n数值,并采用公式(1)计算句子相似度:
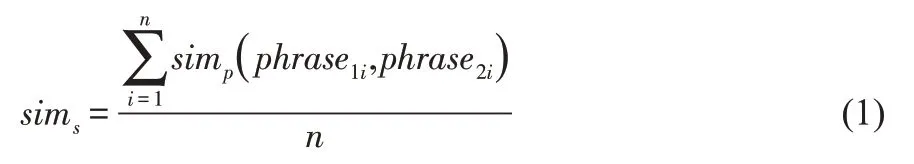
假如抽取句子单词的期间,发现单词抽取后句子的成分为空,那么该句子中的被过滤单词判定为代词,句子中的各个成分相似度利用公式(2)计算。
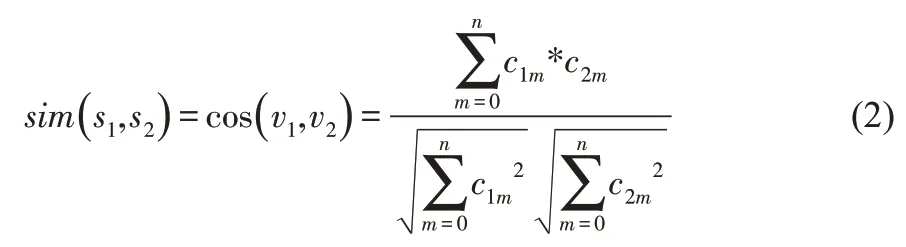
公式(2)中,v1和v2代表向量,c1m和c2m均为字符。
例如句子They like singing.和句子He likes reading.之间的相似度计算,句子成分分为3个词组。词组1:{(they)(he)};词组2:{(like)(like)};词组3:{(sing)(read)}。利用公式(3)计算。通常情况下,采用wup计算的数据值范围是(0,1),在Synset之间LCS深度不可能是0的情况下,可以使用公式(3)进行计算分析,但是如果输入的Synsets相同,数据值就是1。
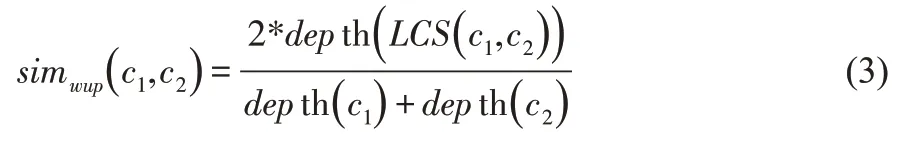
公式(3)中,wup方法得到的计算结果范围为(0,1);LCS代表公共包容最小值;depth代表深度。
基于上述原理,利用C语言进行编程,如下:

4 基于句法和语义的英汉翻译记忆系统设计
4.1 系统总体架构设计
本系统架构主要分为3个模块,分别是索引生成模块、相似度计算模块、译文处理模块。其中,相似度计算模块又分为句法处理模块、语义计算模块。如图2所示为系统总体架构。
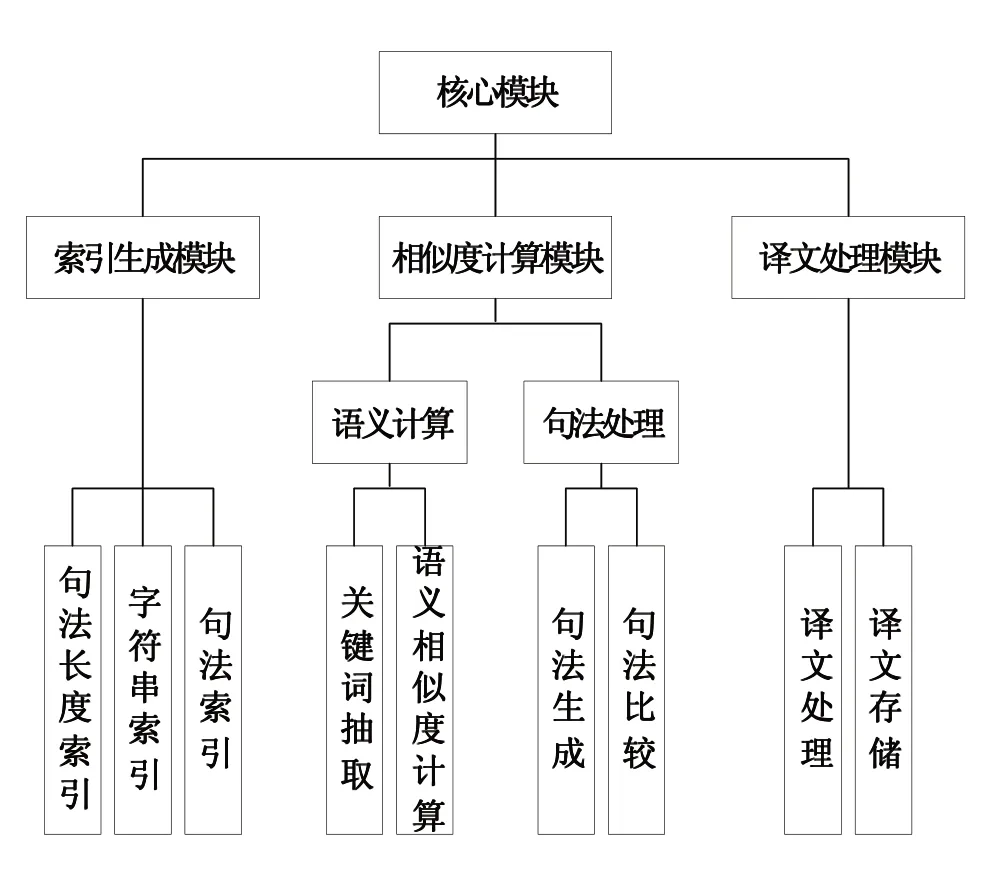
图2 系统总体架构
该架构中,索引生成模块包括句子长度索引、字符串索引、句法索引3项功能;译文处理模块包括译文处理、译文存储2项功能;句法处理模块包括句法生成、句法比较2项功能;语义计算模块包括关键词抽取、语义相似度计算2项功能。
(1)句子长度索引:以“句子长度”为对象,在记忆库中创建索引关系;
(2)字符串索引:以“字符串”为对象,在记忆库中创建索引关系;
(3)句法索引:以“句法”为对象,在记忆库中创建索引关系;
(4)句法比较:采用相似度计算方法,对原句和译文结果中的句法进行比较;
(5)句法生成:通过相似度计算,生成句法相似度计算结果;
(6)关键词抽取:从原句中抽取关键词,作为译文比对重点对象;
(7)语义相似度计算:采用相似度计算方法,对原句和译文结果中的语义进行比较。
4.2 系统总体作业流程
按照如图2所示的总体框架结构,设计系统总体作业流程:
第一步:向系统中输入需要翻译的语句;
第二步:根据英汉语言转换需求,确定翻译语句的语言类型;
第三步:分析句子字符串、长度,调用系统记忆库,从库中找到相似的译文资源;
第四步:对比译文资源的句子与原文的语义是否相符,如果相符,则输出译文,反之,执行下一步;
第五步:将句法作为资源搜索条件,从记忆库中搜寻与原文的句法相似的例句;
第六步:计算记忆库生成句子与原句的句法相似度;
第七步:从生成的例句中,挑选出句法相似度最高的例句,作为译文结果;
第八步:根据用户对译文结果的满意程度,决定是否对译文进行更改。如果对译文满意,则直接输出译文结果,反之,对译文采取修正处理,并将相关信息存储至系统记忆库中。
4.3 翻译记忆库设计
翻译记忆库分为3个级别,包括词汇级、句子级、更深层级。其中,采用词汇级设计的记忆库优点为:译文生成过程比较简单,记忆库作业简单;缺点为:加工程序较为繁琐,降低了翻译效率。采用句子级设计的记忆库优点为:加工程序比较简单,容易扩充,句子翻译较为清晰,容易比对;缺点为:译文生成计算难度较高,对双语资料的加工处理要求偏高。采用更深层级设计的记忆库优点为:译文生成的信息偏多,包括句子结构、词类等,译文资源较多;缺点为:加工程序颇深,加大了译文信息例句扩充难度。
通过对比上述3个层级的实例库的优点和缺点可知,如果前期译文工作量较少,后期记忆库的加工程度就会更大,反之前期工作量过重,后期可以降低加工程度,但是增加了管理工作量。对于英语句子的翻译,是将句子拆分为多个简单的句子,每个句子又分为主语、谓语、宾语。因此,本系统设计记忆库时,以简单句子为单位,根据句子成分展开翻译,以此降低译文难度,使得记忆库开发比较容易实现。
本系统设计的记忆库,兼顾系统管理与译文检索效率,以句子的句法、语义作为检索要点,设计如表1所示的记忆库结构。
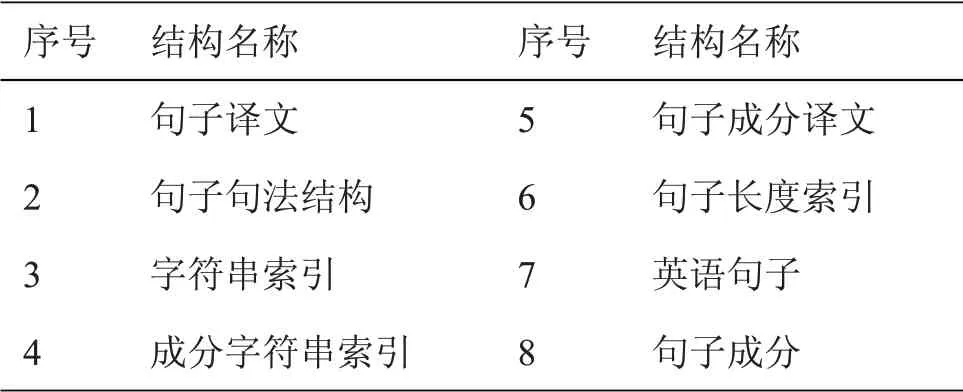
表1 记忆库结构
按照表1所示的记忆库结构,存储译文资源,如果译文结果未能得到用户认可,则存储用户更改过的译文信息,作为下一次相同句子翻译参考依据。
关于记忆库的创建,利用SQL Sever软件开发3个数据信息表,表中的信息按照表1中的结构编辑。以下为3个数据信息表的设计方案:
(1)Component表:用于存储句子的各个译文内容和句子结构。
(2)Structure表:用于存储与句子相关的信息,例如:译文的句法结构等。
(3)Sentence表:用于显示译文结果,包括英语句子信息、汉语句子信息,两部分信息相对应。
4.4 相似度计算
本系统采用相似度算法,对原句、译文句子的相似度进行判断,该判断结果将作为系统翻译处理依据。如果相似度达到100%,则输出译文结果,如果相似度不足,则继续遍历译文结果,经过对比计算相似度参数数值,如果仍未达到100%,则与之前遍历的译文相似度数值进行对比,取最大值。而后判断当前是否仍然存在未计算相似度对应的译文例句,如果存在,继续遍历译文并计算相似度,与之前最大值进行对比,直至所有译文例句的相似度数值计算结束,从中选取相似度数值最大的译文语句作为译文结果,输出译文结果后,等待用户审核,判断是否对此译文结果满意,如果不满意,更改译文结果。如图3所示为相似度计算流程。
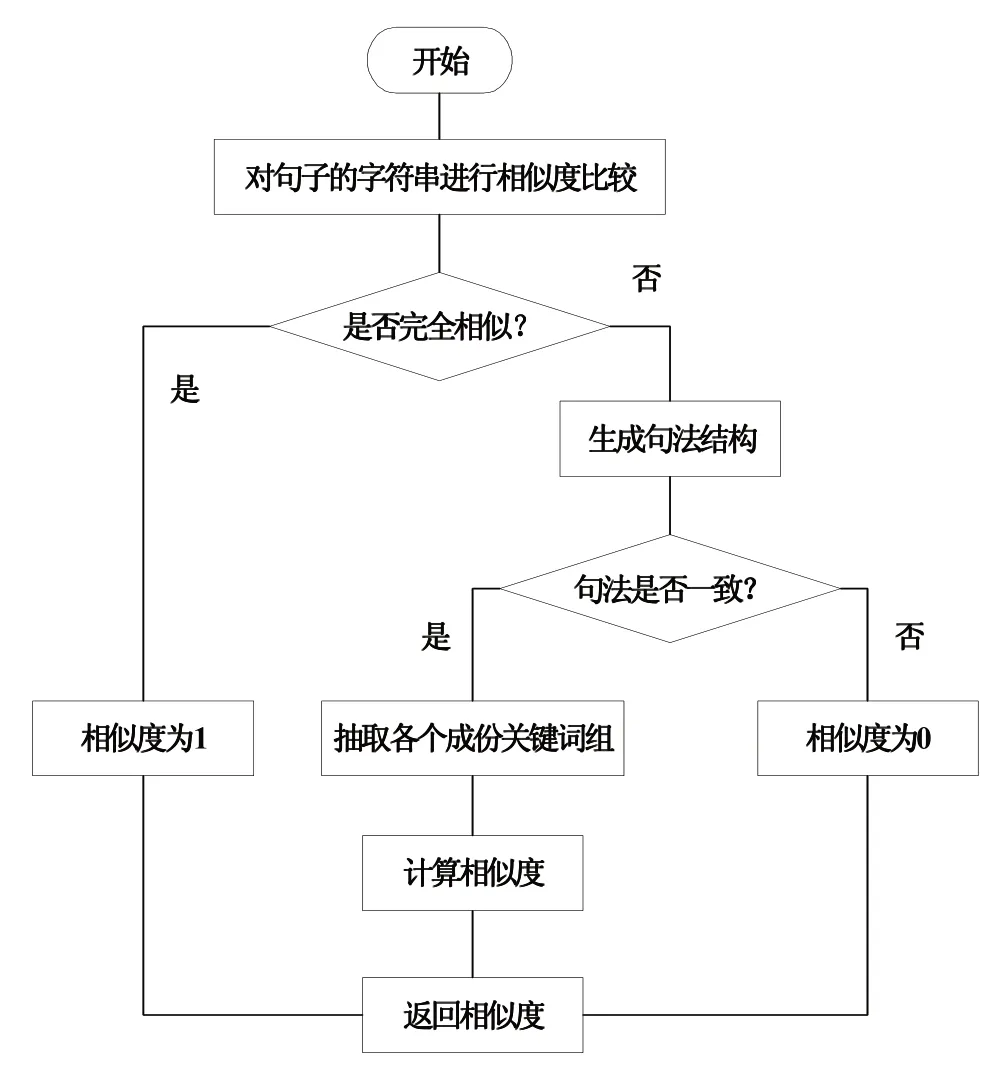
图3 相似度计算流程
首先,以句子的字符串作为对比对象,开展相似度对比。如果句子中的字符串完全相似,则生成相似度结果为“1”,反之,生成原句的句法结构,将其作为下一步相似度对比对象。接下来,对比原句的句法与译文的句法是否一致,如果达成一致,则从译文中抽取各个成分关键词组,计算相似度,并生成相似度结果,数值范围[0,1]。如果句法未能达成一致,则生成相似度结果为“0”。最后,返回相似度计算初端,开启下一次句子相似度计算。
4.5 译文生成
本系统针对英汉语句的翻译,采用相似度算法进行计算,所得计算结果范围[0,1]。按照相似度取值情况,将译文匹配类别划分为3种:(1)“完全不匹配”,对应相似度数值为0,此情况需要修改译文才可以使用,译文生成的流程为“wrong size”→“invalid value”→“非法值”→修改大小错误→生成译文结果。(2)“模糊匹配”,对应相似度数值为(0,1),此情况需要采用人工翻译生成的译文才可以使用,译文生成的流程为“has”→“has”→“有错误”→调整部分译文结果→生成译文结果。(3)“完全匹配”,对应相似度数值为1,直接复用译文即可,译文生成的流程为“TIFF IFD array entry”→“TIFF IFD array entry”→“TIFF图像的IFD数组项”→复用“TIFF图像的IFD数组项”→生成译文结果。
5 系统测试与分析
5.1 测试内容与方法
(1)英汉翻译系统的索引生成和关键词的提取
索引生成测试:记忆库中,创建主索引和次索引。其中,主索引创建建立在英语句子字符串基础上,次索引创建建立在句子长度基础上,根据索引关系在记忆库中快速完成句子的检索,从而找到与待译句子相近的例句。
关键词的提取测试:主要测试系统提取出的关键词是否为待译句子的核心和主要词汇。
(2)英汉翻译系统相似度测试
本次测试以传统机器翻译系统作为对照组,以本文设计的英汉翻译系统作为实验组,分别对两种系统的英汉语句翻译中译文结果相似度进行测试。测试中,分为两种情况,其中一种情况为不含有重复句子(全为新句),另外一种情况为含有重复句子(部分为新句)。每种情况设定英语句子的数量分别为200个、400个、800个。
(3)英汉翻译系统耗时测试:该项测试内容以不同情况下的系统作业耗时作为主要测试指标,两种情况及英语句子数量设置同测试内容(2)。
5.2 测试结果分析
对本系统的索引生成和关键词的提取功能进行测试,结果如表2所示。
表2中测试结果显示,本系统能够有效创建待译句与数据库中例句之间的索引关系,并且提取句子关键词的可靠性较高,有助于系统英汉翻译准确性的提升。

表2 系统索引生成和关键词提取功能测试结果
另外,按照系统测试内容与方法,分别对传统机器翻译系统、本翻译系统的译文相似度、耗时情况进行测试,结果如表3、表4所示。
表3中,与传统机器翻译系统相比,本文设计的翻译系统生成的译文相似度更高,仅有英语句子增加至800个时,存在2个句子译文相似度未能达到标准,而传统机器翻译系统的译文相似度不达标数量达到了37个。针对重复语句情况,本翻译系统的译文相似度效果更佳,仅有1个句子译文未能达到标准,而传统机器翻译系统的译文相似度出现了下降变化趋势。因此,本翻译系统在英汉句子翻译中的精确度更具优势。
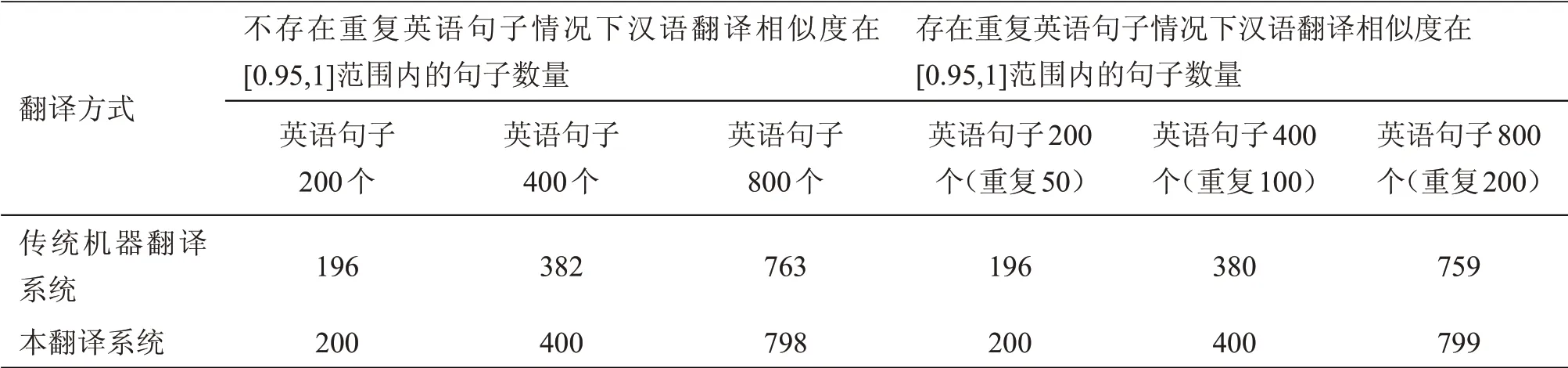
表3 英汉翻译系统的译文相似度测试结果
表4中,与传统机器翻译系统译文耗时情况相比,本翻译系统在不同情况下的译文耗时更短一些,随着句子数量的增加,单个句子译文耗时明显下降。另外,英语句子中存在重复语句情况下,传统机器翻译系统的耗时几乎保持不变,而本翻译系统的耗时出现了明显下降的变化特点。因此,本翻译系统在英汉句子翻译中的耗时更具优势。

表4 英汉翻译系统的耗时测试结果
6 结语
本文采用翻译记忆技术,以语义、句法作为翻译处理指标,设计一套英汉翻译记忆系统。该系统通过构建记忆库,将两种语言的翻译资源存储至其中,而后按照原文中的语义、句法,提取记忆库中的资源,与原文进行匹配,取相似度最高的译文作为翻译结果,经过人工修正生成译文。系统测试结果表明,本系统能够更为精准地翻译句子,且作业效率较高。
