基于BERTScore 指导的文本摘要技术
2022-12-01刘高军王一如王昊
刘高军,王一如,王昊
(1.北方工业大学信息学院,北京 100144;2.CNONIX 国家标准应用与推广实验室,北京 100144)
从文本的大量内容中提取出核心摘要具有重要意义[1],根据提取方式的不同,其主要分为生成式文本摘要和抽取式文本摘要[2]。对于生成式文本摘要,很多非神经系统通过使用选择并压缩的方法[3]提高摘要结果的事实准确性[4],通过使用序列到序列模型生成最终摘要,以上方法得到的结果可能存在语法错误[5],甚至出现与原文相悖的内容[6]。对于抽取式文本摘要,通过对整篇文章进行句子抽取并排序得到最终摘要[3],利用分类器决定是否抽取出文本中的某个句子[7],以上提到的抽取方法会出现过度抽取的情况,并且通常词级别的抽取式文本摘要得到的结果可读性较差[8]。
为解决上述问题,文中使用了基于BERTScore反馈的强化学习模型将两种摘要方法相融合。首先为降低文本中干扰信息的影响,利用卷积模型以及Bihop 注意力机制抽取出文本的重要信息,其抽取结果在生成摘要阶段结合注意力机制进行压缩,在训练过程中计算压缩结果与参考摘要的BERTScore 值,该值作为反馈指导模型更新策略梯度参数和当前状态,进而指导下一步抽取行为,以此不断提升模型在抽取阶段的性能。使用BERTScore 能够处理其他基于N-gram 的评估指标对表示相同含义的不同词汇评分低的问题,进而保证了摘要结果的多样性并增强了整个模型的健壮性和对语义的重视程度。同时,文中的模型中加入了Gumbel-Softmax 可微再参数化技术,改善了模型不可微的情况。
1 模型设计
文中先用抽取式模型过滤原文本中的干扰信息,然后用生成式方法对抽取出的内容压缩,得到精简摘要,完整模型如图1 所示。模型使用基于策略梯度的强化学习将两种摘要方式相融合,并利用BERTScore 作为强化学习的反馈调整策略梯度参数和当前状态,该状态将作为下一步抽取行为的依据。BERTScore 更关注文本内容,得到的摘要结果也更为准确,因此文中的模型在提升了筛选重要信息能力的同时,得到了与原文内容更相符的摘要结果。Gumbel-Softmax 可微再参数化技术的加入用于解决抽取式模型不可微的情况。

图1 完整模型图
1.1 句子的表示与抽取
首先利用时序卷积模型得到文本中每个句子的表示,再由BERT 预训练的词向量矩阵Wemb得到每个词的分布向量表示,并经过一维单层卷积过滤器获得词与前后内容的依赖关系。使用由LSTM-RNN 训练的指针网络从已得到句子矩阵表示的文本内容中筛选出重要句子,如式(1)所示:

整个网络中结合了Bi-hop 注意力机制,其中第一层注意力机制用于确定包含重要信息的句子,第二层用于计算每个句子被抽取的概率,以上步骤如图2 所示。

图2 句子的表示及抽取过程
1.2 摘要的生成
由于在抽取阶段已过滤文本中的干扰信息,生成摘要阶段是对上一阶段抽取出的包含重要内容的句子进行分析与压缩,因此该部分使用结合注意力机制的seq2seq 模型就可得到准确且精简的摘要结果。文中模型加入了结合双线性乘法注意力机制的编码器-解码器结构,如式(2)所示。针对生成式文本摘要会出现的OOV(Out-of-Vocabulary)问题,模型中使用了copy 机制。

其中,hi是结合了上下文内容的句子向量,zj是抽取出的句子,Wattn是注意力权重矩阵。
1.3 结合BERTScore的强化学习模型
1.3.1 BERTScore计算
当前的文本摘要研究任务中常根据评估指标Rouge 的情况微调模型,该指标在评估摘要结果时只考虑句子表层词汇的匹配情况,并未考虑句子内容,导致摘要结果的事实准确性不可控。文献[8]提出的从文本内容的角度评估翻译结果精确性的方法可改善翻译任务中与上述问题相似的情况,因此文中的模型加入了结合BERTScore 的强化学习模型,将抽取式文本摘要与生成式文本摘要相融合,即利用actor-critic 策略梯度将句子级别的BERTScore 评估结果作为反馈指导抽取行为,并学习句子的显著性特征。模型的整个过程与马尔可夫决策过程(MDP)相似:抽取器作为强化学习的agent,在每一步(t)抽取之前先观察当前状态,并将上一步(t-1)的摘要评估结果作为反馈,指导当前的抽取行为。
模型中计算预测摘要与参考摘要匹配情况的BERTScore 更加注重语言的多样性,能够关注到表示相同语义的相似词汇。文献[10]的研究表明,此评估方式的结果与人工判断有很高的一致性。BERTScore包括的Recall(RBERT)、Precision(PBERT)和F1(FBERT)均通过计算文本向量的余弦相似度得到:
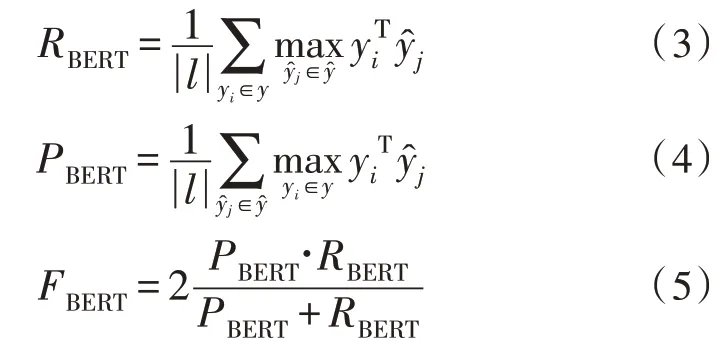
1.3.2 反馈值的计算
模型中首先直接用BERTScore 评估预测摘要与参考摘要的内容匹配情况,并将该值作为强化学习模型的反馈指导抽取行为,同时考虑到基于N-gram的评估指标Rouge 常用于评估文本摘要的词汇匹配度,故文中尝试将两种评估方式相结合,从词汇匹配情况以及内容匹配角度共同评估预测摘要的效果,从而更全面地考量模型的性能,并更好地指导抽取行为,联合反馈值计算公式如下:其中,λ是BERTScore 和Rouge 的调和参数。

2 可微再参数化技术
针对模型抽取器部分不可微的情况,文中使用了Gumbel-Softmax 函数替换计算抽取概率的Softmax函数,公式如下:

式中,x表示抽取出的句子,θ是训练参数。Gumbel-Softmax 函数是为解决模型不可微问题的可微再参数化技术,它允许通过转化Gumbel 分布的样本选择变量值,该函数可表示为:

3 训练和实验
针对CNN/DailyMail 的验证集,对实验中的参数均进行了调整,文中使用了32 个样本的小批量数据进行所有的训练,Adam 优化器的学习率在机器学习阶段为0.001,在强化学习阶段为0.000 1。文中首先训练抽取器和生成器直到二者均收敛于极大似然函数的目标,然后使用强化学习训练上述训练好的子模块。在用到LSTM-RNNs 的部分均使用了256 个隐藏单元,对于模型中的极大似然训练模型,文中使用BERT 预训练语言模型取代由Word2vec[11-12]初始化的词向量矩阵,并且该词向量矩阵将根据训练情况更新。
3.1 实验数据
文中使用的数据集是包含了美国有线新闻网(CNN)以及每日邮报(Daily Mail)共约一百万条新闻语料的CNN/Daily Mail。实验中使用的是该数据集的未匿名版本,并对该数据进行适当的处理,其中包含了训练文本、验证文本和测试文本。
3.2 评价指标
结合文本摘要任务通用的评价指标[13],文中使用Rouge-1(R-1)、Rouge-2(R-2)、Rouge-L(R-L)评估预测结果的质量。考虑到文中将BERTScore 评估函数加入到模型中,因此为体现该评估函数对模型效果的影响,将FBERT作为评价指标评估摘要内容质量。
3.3 实验结果及分析
3.3.1 模型总实验
为了验证文中模型在文本摘要任务的优良性,将其与不同摘要方法进行对比,表1 为各不同模型的实验结果对比情况。

表1 各模型在CNN/DailyMail的实验结果
1)抽取式文本摘要
表1 中第一部分是抽取式文本摘要实验结果对比,其中Lead-3 算法得到的摘要是文本的前三句。SUMO[14]是以树归纳的角度得到的抽取式文本摘要,证明了文档结构对抽取式文本摘要有重要作用。
2)生成式文本摘要
表1 中第二部分是生成式文本摘要实验对比结果,MASS[15]提出了基于文本摘要源句中单词的中心度为指导的复制机制,因此更关注源句中的单词。BERTSUMABS[16]证明了篇章级编码对任务的重要性并且没有使用其他机制就得到了较好的实验结果。
3)抽取式与生成式相结合
表1 中第三部分是将抽取式文本摘要与生成式文本摘要相结合的实验结果对比,并且对比的模型均是使用强化学习优化整个模型,差别在于使用的反馈不同,ext+abs+RL(learned)[17]使用损失函数计算反馈值,由于计算反馈值的过程不是基于N-gram 的方式,且此实验结果受Rouge 评估方式影响,因此得到的Rouge 结果不理想。使用Rouge 作为反馈的ext+abs+RL[3]模型得到了相比上述模型更好的结果,而使用文中提出的以BERTScore 作为反馈的模型得到的摘要结果,相比于Rouge 作为反馈的模型,其基于N-gram 评估的角度分值较低,这是由于生成式文本摘要根据对句子的理解生成新的句子,该句子中可能包括原句中没有的词汇。文中以BERTScore 作为反馈考量的是文本内容的匹配情况,而并非只考量句子表层词汇的匹配情况,因此文中模型在评价指标FBERT角度得到的分值要高于上述模型,这也与人工总结文本的结果更相似。以BERTScore 和Rouge 共同作为反馈的模型(λ=0.5)既考虑了句子表层的词汇匹配情况,又考虑了文本内容的匹配情况,因此得到的摘要结果在Rouge 方面有一定的提升(与ext+abs+RL(Rouge))相比,在评估指标Rouge 角度提升效果为R-1:+0.46;R-2:-0.02;R-L:+0.63,与ext+abs+RL(BERTScore)相比,在评估指标Rouge 角度提升效果为R-1:+0.53;R-2:+0.11;R-L:+1.96。在评估指标FBERT方面,与ext+abs+RL(Rouge)相比,提高了2.35,由此可见,将Rouge与FBERT联合作为强化学习的反馈能够优化整个模型,并得到与参考摘要更相近的结果。
3.3.2 对比实验
为了验证文中模型使用结合BERTScore 的强化学习模型的有效性,针对上文提到的调和参数λ值设置对比实验,评估指标avg 由R-1、R-2、R-L和FBERT三者计算均值得到,对比实验中λ分别取值为0、0.25、0.5、0.75、1,与各取值相对应的实验结果如图3所示。

图3 参数对比实验
其中,λ为式(6)中BERTScore 和Rouge 的调和参数,avg 为评估指标R-1、R-2、R-L和FBERT的均值。
由图3 中对比实验结果可看出,当λ=0.5 即均衡考虑词汇匹配情况和内容匹配情况时,生成的摘要效果最好,因此,当模型使用BERTScore 和Rouge 共同作为强化学习的反馈进行实验时,取λ=0.5。
4 结束语
文中在利用强化学习将抽取式与生成式两种摘要方法相融合的基础上,使用BERTScore 评价指标作为模型的反馈,避免了使用Rouge 评价指标忽略不同词汇表示相同语义的情况,并且文中尝试将BERTScore 和Rouge 联合作为反馈,以最大化理解文本内容的同时权衡词汇匹配度,得到了与人工总结尽可能相似的文本摘要。文中使用Gumbel-Softmax可微再参数化技术优化了模型中抽取器不可微的问题。未来,仍需要继续探索文本摘要的评价方法以及加强对文本内容的重视,以得到效果更好的文本摘要。
