基于Albert-TextCNN的网络安全文本多标签分类方法∗
2022-12-01刘江舟
刘江舟 段 立
(海军工程大学 武汉 430000)
1 引言
随着《“十四五”规划和2035年远景目标纲要》的发布,网络安全被列为未来中国重点发展建设的工作之一,也标志着我国的网络安全产业也进入了新时期。在网络安全日新月异的发展情况下,线上学习因为实时性和时效性,成为了多数网络安全从业者的学习手段,特别地,文本资源以技术文章和短讯等形式,成为了用户获取网络安全知识的重中之重。然而,互联网在提供了海量文本资源的同时,也存在着部分问题,现阶段以主题为标准的分类方式,虽然可以将文本资源进行了粗分类,但是分类的各个主题之间缺乏紧密联系,导致相关文本资源分布分散,缺乏传统课程学习的系统性和连续性,不利于用户快速准确获取目标文本包含的知识信息。
因此,本文提出基于Albert-TextCNN的网络安全领域文本分类模型,目的是在网络安全知识体系下,快速准确地提取文本中的知识点,从而实现按照知识点对网络安全文本进行分类,确保用户可以根据自己感兴趣的知识点来进行学习,达到用户按图索骥的目的。
2 相关研究
2.1 多标签分类方法
文本分类作为自然语言处理领域的重要课题[1],已经有了很多年的发展。多标签分类总体可以分为两种:一是传统的机器学习的方法;二是深度学习的方法。其中,机器学习方法又可以分为问题转化方法和算法自适应方法。问题转化方法是指把多标签分类问题转换为一个或者多个单标签分类问题,从而可以用现存的单标签分类算法来实现多标签分类的目的;算法自适应的方法是指直接根据问题本身,将修改现存的单标签分类算法进行调整,用来直接处理多标签学习问题。随着深度学习在计算机视觉和语音识别等领域取得的巨大进步,神经网络模型也逐渐被运用到了多标签文本分类问题上。Zhang等[2]和 Nam等[3]使用全连接神经网络来解决多标签文本分类问题,该方法虽然可以适用于大规模的文本分类问题,但却未充分考虑标签之间的关联关系,易导致反义标签共现的问题。文献[4]提出的TextCNN模型,首次将CNN结构引入到文本分类领域,用于句子级别的文本分类,取得了一定的效果。针对TextCNN忽略句子上下文的问题,文献[5]同时结合了RNN与CNN的优点,提出了TextRCNN模型。随着transformer和Bert的广泛应用,Sun[6]等将Bert用于解决文本分类问题,并介绍了Bert的微调方法,进一步让Bert适用于具体的多标签分类问题。
2.2 基于Bert模型的文本表示
在自然语言处理领域,由于计算机无法识别文本语言,因此,需要将文本语言转换为计算机语言,即解决文本表示问题[7]。其中,常见的有布尔表示和分布式表示。
布尔表示是根据囊括所有词的字典索引号,向量的维度是整个字典的长度,并且整个向量中只有一个维度取值为1,其余维度都是0,其中,取值为1的代表出现该词。布尔表示虽然拥有易于理解,便于生成的特点,但是仍然存在几个较为明显的缺点:一是向量维度爆炸。例如:当字典规模较大时,相应地向量维度也会十分庞大,但是有效数据却十分稀疏,不利于对向量的存储。二是无法体现词之间的关联。因为每个词向量之间都是正交关系,因此无法从数学角度体现词向量之间的关联关系,不符合实际工程需求。
分布式表示由Hinton于1986年提出,即后来广泛应用的词向量。分布式表示是通过训练将文本中的每个词用一个固定维度的向量表示,从而全部词向量共同组成一个向量空间,其中各个词向量相当于向量空间中的一个点,从而,使得词向量之间包含了词之间的语义关系。因此,我们可以用欧式距离,余弦相似度来计算词向量之间的语义相似度。
Bert模 型[8](Bidirectional Encoder Representa⁃tions from Transformer),由谷歌公司于2018年提出,因其在自然语言处理的各个领域均取得了不俗的成绩而被业界所熟知。根据Bert英文全称可以了解到该模型大量叠加使用transformer的编码模块,代替之前多数模型较为常用的Bi-LSTM[9],因此具有执行并行运算的能力,同时,transformer的编码器可以通过多头注意力机制及其前馈网络实现文本前后信息的交互,因此在处理文本信息方面具有极强的表征能力。其模型结构如图1所示,初始字向量E1,E2,…EN通过由多个 transformer组成的编码器,最后输出包含丰富语义信息的字向量T1,T2,…TN。
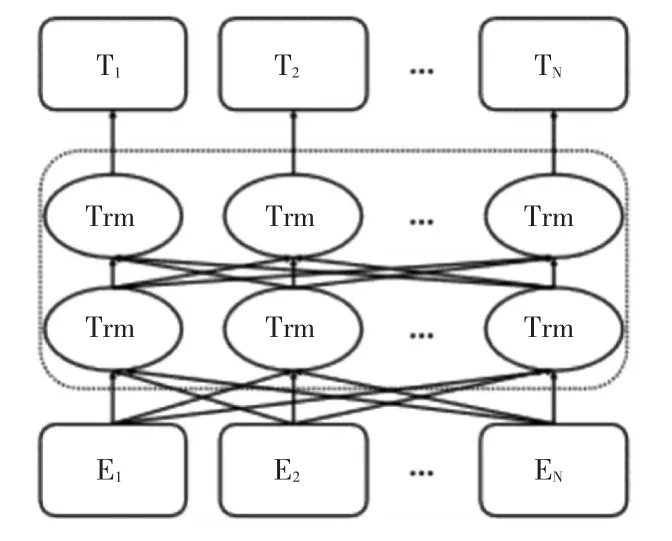
图1 Bert结构示意图
Bert最初的目标是利用大规模无标注语料训练,进而丰富语义信息的文本表示,即文本的语义表示。但是,由于Bert在大规模语料上训练所需的配置高,时间长,因此,Google公司提供了预训练模型,方便大众对Bert微调[10],进而完成相应的下游任务。
2.3 TextCNN模型的多标签分类
TextCNN的基本思想是利用CNN的结构进行分类,该模型将词向量组成的句子利用不同大小的窗口来捕捉句子的局部信息,提取相关特征,整体上比较适用于短文本任务。
从结构上讲,TextCNN分为输入层、卷积层和池化层,如图2。
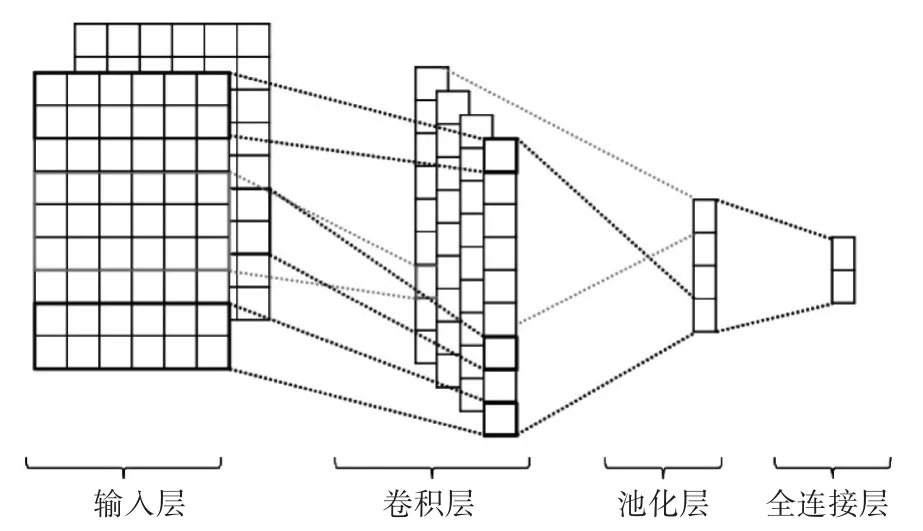
图2 TextCNN结构
TextCNN的输入层为一个文本的字向量组成的矩阵,由横向为每个字向量,同时为了保持字向量长度,还对原文本进行了补0操作。通常,TextCNN的输入向量来源于上游任务。
在卷积层中,不同于计算机视觉中的CNN正方形卷积核可以在图片矩阵上进行纵向和横向两个方向的移动;TextCNN的卷积核与词向量的宽度相同,仅需要在纵向进行移动。由于卷积核需要词向量的宽度一致,作为滑动窗口的卷积核,不同的卷积核大小,会使窗口内包含的语义信息也会不同,根据实际工程需求可以选择不同卷积核。
TextCNN的池化层采用了最大池化,即从滑动窗口中产生的特征向量中筛选出最大特征,进一步将特征向量进行拼接,从而得到一个固定长度的向量表示。
3 基于Albert-TextCNN的多标签分类模型
3.1 提出目的
常见的网络安全领域文本的分类是按照其主题进行分类,但是此类标准的分类主题之间缺乏彼此的联系,不利于用户选择适合自己兴趣的文本。在网络安全领域,一个文本资源通常会包含多个网络安全知识点,因此,本文提出以知识点为标准,将文本资源按照知识点进行分类。同时,通过整理所得的知识体系,帮助用户了解知识点之间的包含与被包含关系,通过知识点关联文本资源,从而有利于用户根据自身知识水平进行网络安全领域文本资源的选择。
3.2 模型结构
图3 为模型结构,本文采用 Albert[11]预训练模型对文本进行向量提取,从而作为多标签文本分类的输入。
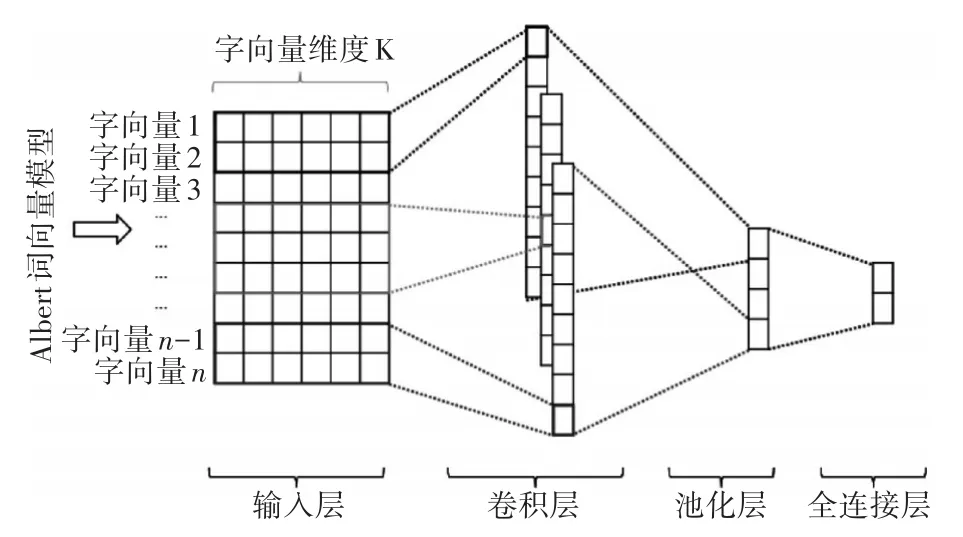
图3 Albert-TextCNN的多标签分类模型
基于模型更加轻量化,效果更好,训练更快的目的,Albert(a lite bert,精简版Bert)预训练模型,在Bert的基础上,Albert有以下三个改进点:
一是对嵌入参数进行因式分解。将词嵌入层映射到低维空间进行降维,再映射到隐藏层;
二是采用跨层参数共享的策略,避免参数量随着网络深度的增加而增多;
三是解决了Bert下句预测(Next Sentence Pre⁃dict,NSP)损失抵消的问题,改用语序预测(Sen⁃tence-Order Prediction,SOP)来代替NSP作为训练任务。
综合以上三个特点,Albert模型参数量仅为Bert的1/18,训练速度却为Bert的17倍,在显著减少了参数量的同时仍保持了较高的模型效果。因此,比较适合小规模的文本分类任务。本文采用的Albert_small_zh预训练模型在包括多个百科、新闻、互动社区多种语境的约30G中文语料上进行训练,累计学习训练超过100亿汉字,同时,语料中包含部分中文语料中的常用英文。因此,结合Albert模型本身的三个特点,该模型适用于任务规模相对较小,同时实时性要求高的包含少量英文的分类任务。因此,本文采用的Albert_small_zh包含4个隐藏层,12头注意力机制,总计4M的参数量。
假设经Albert_small_zh预训练模型处理后的第i个文本中共有n个词,则在TextCNN输入层中的初始输入E可以表示为

在卷积层中,利用卷积核进行卷积操作,进而提取窗口内文本的局部信息:
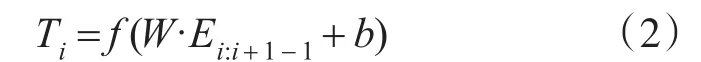
其中,W 为权值矩阵,b为偏置项,f(∙)为激活函数。
在最大池化层中可以得到,全局特征向量:

最后,进入全连接层进行分类。
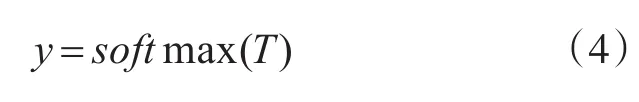
4 实验结果分析
4.1 实验环境
实验硬件:CPU为i5-8400,显卡为RTX2060,显存8G;实验软件:操作系统为Windows10 64位,Python版本为3.8,TensorFlow版本为1.15。
4.2 实验数据
本实验使用的数据集共6771条,每条包含文本资源的标题及关键词,文本资源从安全客、Free⁃buf等网络安全网站爬取得到。按照8:2的比例分为训练集和验证集。同时,根据看雪论坛等多个网络安全权威网站整理得到网络安全领域相关知识共216个,即以上文本资源覆盖216个知识点标签,如图4为部分知识点。

图4 网络安全知识点标签(部分)
对于常规的文本分类任务,该数据集属于小型语料库,同时由于样本本身存在类别较多,类别不平衡等现象,会对模型的分类效果产生较大影响。因此按照文献[12]提出的EDA方法通过同义词替换法(Synonyms Replace,SR)、随机插入法(Ran⁃domly Insert,RI)、随机交换法(Randomly Swap,RS)和随机删除法(Randomly Delete,RD)对文本数据进行增强,减小类别不平衡对模型效果的影响。
4.3 评价标准
本实验模型与对比模型通过以下5个实验指标进行评估:准确率(Accuracy)、精确率(Preci⁃sion)、召回率(Recall)、F1值和Hamming Loss对分类结果进行分析。
精确率(Precision,P)表示在预测为正的样本中,被正确预测所占样本比例,该指标体现了模型的查准率。召回率(Recall,R)表示在预测正确的样本中,正样本所占样本比例,该指标可以体现模型的查全率。F1值则是由精确率和召回率的加权调和平均计算得来,是对精确率和召回率的综合考察。准确率(Accuracy,A)表示在分类正确的标签数量占标签总量的比例。在多标签分类任务中,由于标签众多不能关注每一个标签的指标,因此,使用Macro-precision、Macro-recall和 Macro-F1来进行度量,同理,其值越大,代表模型的性能越好。

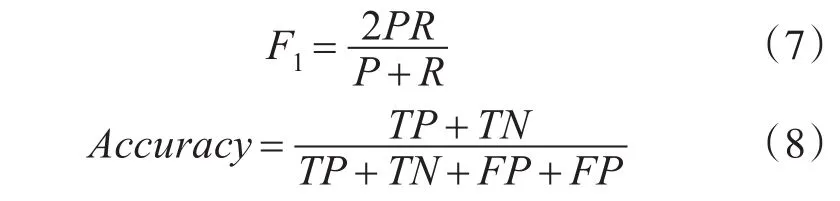
其中,TP表示将正样本预测为正,FP表示将负样本预测为正,FP表示将正样本预测为负,TN表示将负样本预测为负。
Hamming Loss(HL)表示标签被误分类的个数,该值越小表示模型的性能越好。
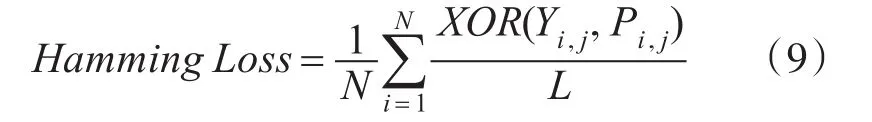
其中,N表示样本的数量,L是标签的总数,Yi,j表示第i个样本真实标签集中的第j个标签,Pi,j表示第i个样本预测标签集中的第j个标签,XOR表示异或运算。
4.4 对比实验
本采用以下两个模型进行对比实验:
1)Albert文本分类模型:模型以Albert模型作为词向量模型,把词向量直接接入全连接层进行分类。
2)Albert+Dense文本分类模型:模型以Albert模型作为词向量模型,但是把多标签分类问题当作多个判断是否属于该类标签的二分类问题。
4.5 结果与分析
为防止实验中偶然因素的干扰,实验结果均运行10次求均值,从而得到表1中的结果。

表1 实验结果对比
由表中结果可知,本文采用的在网络安全知识体系下的Albert+TextCNN可以有效提升模型效果,在准确率、精确率、召回率和F1值上均可取得最大值,与表现最好的对比模型Albert+Dense相比分别在Precision、reccall、F1和accuracy指标上高出0.21、0.36、0.32和0.20,且Hamming Loss最小。
同时,由图5和图6可知,在网络安全数据集上,Albert+TextCNN模型与其他两个模型对比,ac⁃curacy曲线最早达到稳定,在10K step附近达到稳定,并且曲线明显高于其他两个模型。同时,Al⁃bert+TextCNN模型loss曲线下潜深度更深,loss更小,而且曲线整体稳步收敛。
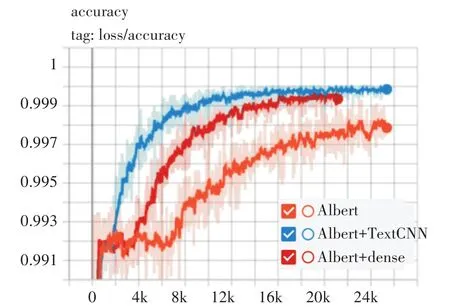
图5 模型accuracy曲线对比
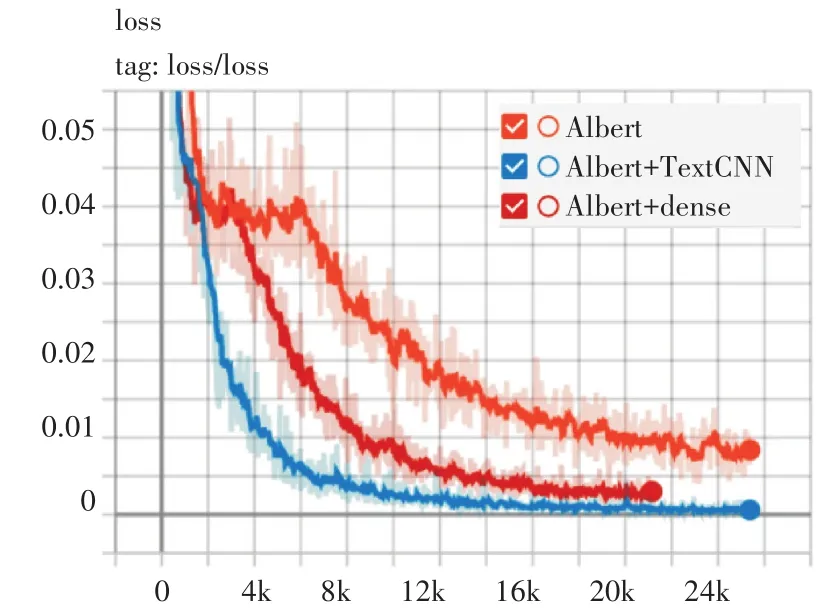
图6 模型loss曲线对比
综合以上两点,实验验证了Albert+TextCNN模型的有效性,本文提出的模型能够很好地利用Al⁃bert对文本强大的表示学习能力,再通过TextCNN的卷积核进一步提取文本的语义信息,同时辅助以网络安全知识体系下标签之间的先验知识,增强了模型在文本多标签分类任务中的识别能力在与对比实验模型的比较中具有一定的优势。
5 结语
本文提出了在网络安全知识体系下,基于Al⁃bert-TextCNN的网络安全领域文本分类模型。经过实验对比,该模型优于同类型的多标签分类模型,可以有效地抽取文本知识点,实现对文本按照知识点标签的快速分类。
下一步,本文将进一步将模型结合推荐算法,从知识点角度出发,为精准有效地推荐相关的文本资源,实现智能导学的目标。
