基于无监督学习的三维肺部CT图像配准方法研究
2022-12-01张红运杨志永张国彬
姜 杉,张红运,杨志永,张国彬
基于无监督学习的三维肺部CT图像配准方法研究
姜 杉,张红运,杨志永,张国彬
(天津大学机械工程学院,天津 300350)
三维肺部电子计算机断层扫描(computed tomography,CT)图像非刚性配准是医学图像配准领域中最重要的任务之一.但是,肺部组织受呼吸运动影响而产生的非线性形变与大尺度位移给三维肺部CT图像的非刚性配准带来巨大挑战.针对这一难题,设计开发了一种基于无监督学习端到端的配准方法.通过改进现有U-Net神经网络结构,在跳接之间引入Inception模块,充分融合多尺度深层特征生成高精度的稠密位移向量场.为保证位移向量场光滑,在损失函数中加入雅可比正则化项,以达到训练中显式惩罚位移向量场中奇点的目的.另外,为缓解现有公开数据资源有限导致的过拟合问题,提出了一种基于三维薄板样条(3D-thin plate spline,3D-TPS)变换的数据增强方法实现对训练数据的扩充,将具有60套三维肺部CT图像的训练数据集EMPIRE10扩充为6060套以满足卷积神经网络训练的需要.设计验证实验,通过与基于学习的Voxelmorph方法和两个包含传统方法配准工具包ANTs和Elastix进行比较.实验结果表明:在公开可用的DIR-Lab 4DCT数据集上,所提出的方法在目标配准误差(target registration error,TRE)上达到次优的2.09mm,平均Dice得分达到最优的0.987,同时所生成的扭曲图像中几乎不存在折叠体素.
非刚性配准;卷积神经网络;无监督学习;数据增强;雅可比正则化
三维肺部CT图像已广泛应用于图像引导下的放射治疗[1].肺作为典型的运动器官,在面向肺癌的放射治疗之前,为估计所需的精确剂量必须追踪肺呼吸运动[2].术中需要将不同呼吸状态的三维肺部CT图像与参考状态的三维肺部CT图像进行对齐,跟踪每个体素的剂量.三维肺部CT图像非刚性配准是准确跟踪肺部运动的一种可行方法.
非刚性配准是指在一对待配准图像间建立非线性稠密映射关系.现有的传统算法大多通过几何方法解决每个图像对的非刚性配准优化问题,如SyN (standard symmetric normalization)[3]和Diffeomorphic Demons[4].传统方法计算开销很大,每当配准一对新图像时,需重新迭代运算.近年来,越来越多的学者倾向于利用基于学习方法完成配准任务.训练后的卷积神经网络模型可以在几秒钟内完成一对三维医学图像的配准,且其精度足以媲美较成熟的传统方法.深度学习下的图像配准大致可分为两类:基于监督学习的配准方法和基于无监督学习的配准方法.
基于监督学习的配准方法在训练网络时,需要提供与训练样本相对应的标签(ground truth,GT).Fan等[5]使用传统方法对图像进行配准,将获取到位移向量场作为GT,然而此方法获得的GT与真实GT有所偏差.Hu等[6]提出用分割的解剖结构掩膜作为GT来训练卷积神经网络.在该方法中,卷积神经网络以固定和运动图像对作为输入,通过对解剖结构掩膜进行对齐达到配准图像的目的.Miao等[7]将原始图像作为浮动图像,将被模拟位移向量场扭曲的原始图像作为固定图像,将模拟位移向量场作为GT.尽管监督学习在图像配准领域有很大的潜力,但是通过传统的配准工具获取GT过程较为繁琐.
基于无监督学习的配准无需额外手工生成的GT,在训练过程中利用固定图像和扭曲图像之前的差异来指导网络参数的优化.VoxelMorph为一种典型的基于无监督学习的三维医学图像端到端配准方法,将配准中发生的扭曲变换定义为参数函数,并对其参数进行了优化[8].Zhao等[9]采用级联配准子网络预测位移向量场,取得了较好的效果.上述方法在脑、肝图像上取得了良好的效果,而神经网络在肺部CT图像配准中应用较少.相比较于脑、肝图像,不同时刻采集到的肺部图像往往会由于人体的呼吸运动产生大范围复杂非线性形变和位移,这将导致配准肺部图像较为困难.
本文提出一种基于无监督学习的卷积神经网络方法用于三维肺部CT图像非刚性配准.在现有U-Net神经网络结构上进行改进,将Inception模块引入至跳接之间以提升网络的特征检测能力,充分融合多尺度深层特征生成高精度的稠密位移向量场.为了抑制不可逆变形,对稠密位移向量场中的具有负雅可比行列式值的变换进行惩罚.实验表明,在变形后的图像中几乎没有折叠体素.训练后的卷积神经网络模型,可实现端到端的三维肺部CT图像非刚性配准,同时具有较强的泛化能力.
1 方 法
图1 基于无监督学习的三维肺部CT图像配准流程
Fig.1 Flow chart of 3D lung CT image registration based on unsupervised learning
1.1 卷积网络结构
如图2所示,使用的卷积网络是基于U-Net的改进.通常情况下,为生成高精度的稠密位移向量场,可在U-Net上堆叠卷积层加深网络来实现.但是随着网络深度的增加,可能会出现梯度消失现象,进而导致模型过拟合.另外,不同个体的肺部CT图像中信息位置存在较大差异,因此选取合适尺寸的卷积核变得十分困难.针对上述问题,本文不再通过盲目加深U-Net来优化网络性能,而是通过引入Inception模块加宽网络,在保证U-Net网络一定深度的基础上,通过Inception模块所特有的多尺度卷积操作,促进网络捕捉并学习更加丰富的多尺度特征.配合U-Net中跳跃连接所融合的上、下文信息,以达到生成高精度稠密位移向量场的目的.

图2 3D卷积网络模型结构
1.2 损失函数
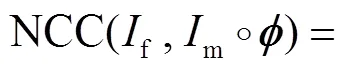
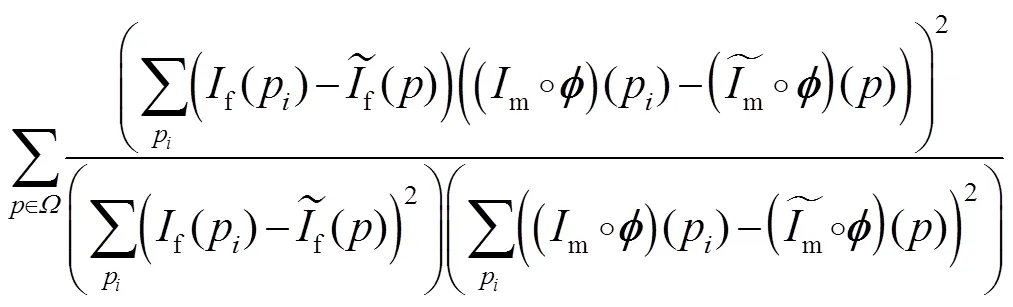
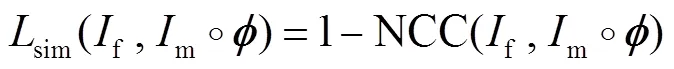
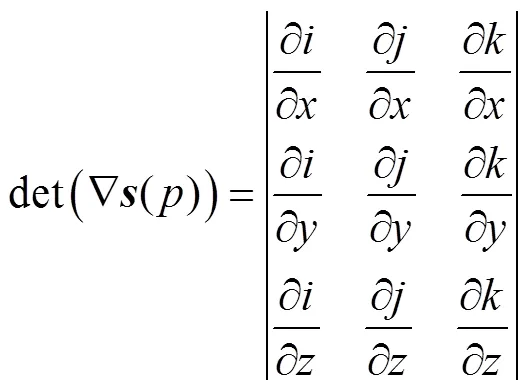
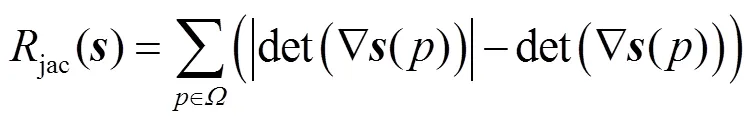
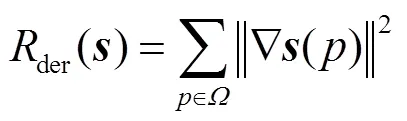
损失函数整体可以表示为

2 实 验
2.1 数据集
本文使用3个包含同一病人不同时刻的三维肺部图像数据集:EMPIRE10[12]、DIR-Lab 4DCT[13]和POPI[14].DIR-Lab 4DCT数据集包含10个四维肺部CT图像,每个四维肺部CT图像中包含一个完整呼吸周期中的10个呼吸相位.选择具有最大相对变形的两个阶段数据:呼气末时刻和吸气末时刻,两阶段分别标注有300个地标点.EMPIRE10数据集由30对三维肺部CT组成.POPI数据集由6个四维肺部CT图像组成,使用最大相对变形的两个阶段:呼气末时刻和吸气末时刻,两阶段分别标注有100个地标点.

2.2 数据增强
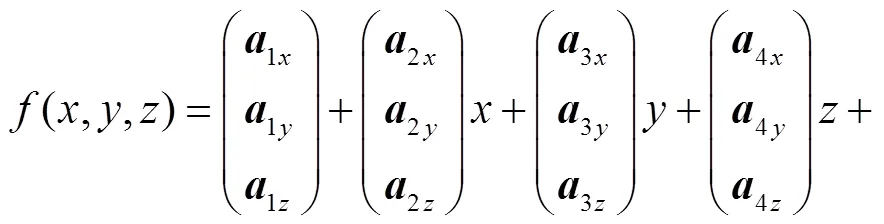
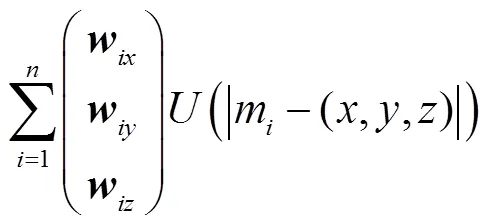
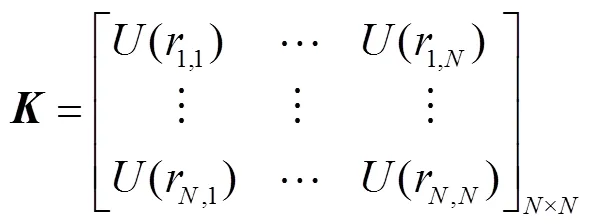
3D-TPS插值函数的参数能够通过求解下面线性方程组得出.
(9)
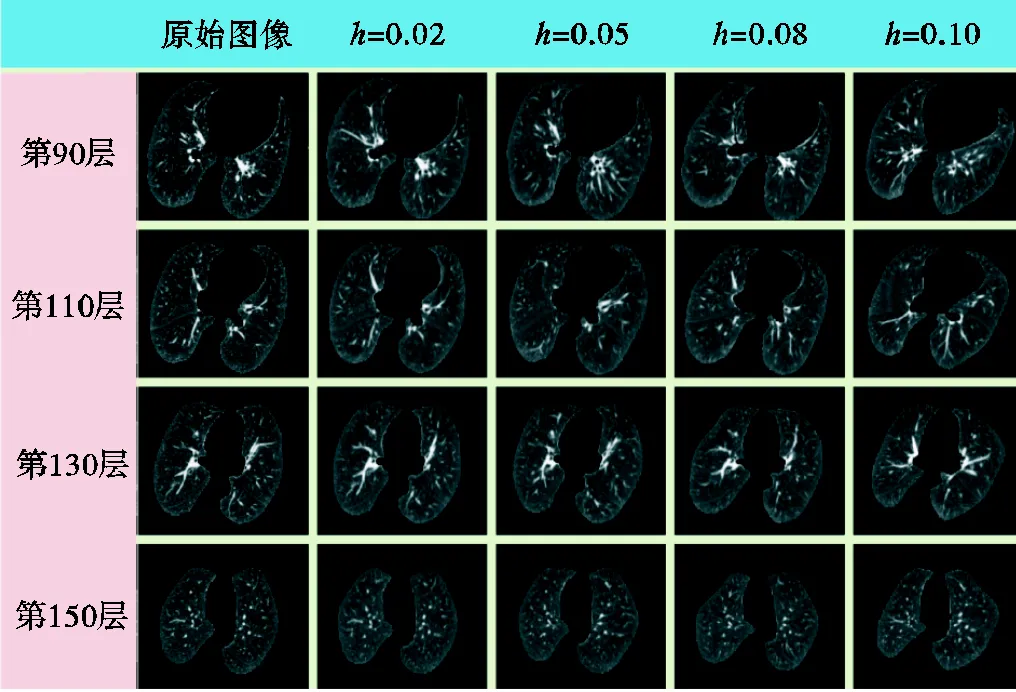
图3 3D-TPS生成图像示例
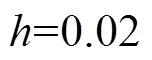
2.3 评价指标
由于CT图像中肺实质区域往往会占据大量的体素,因此使用地标点间的TRE来评估肺内部的配准质量.

Dice虽然不能很好地评价肺实质区域的配准质量,但可用于评估肺边界的对齐程度.Dice分数表达式为
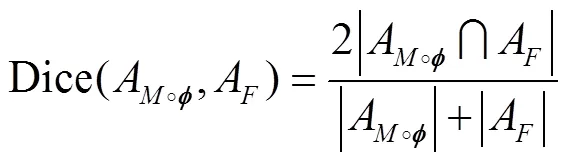
此外,图像折叠在解剖学上是不合理的.第1.2节中提到的折叠体素的数量也作为算法的评价指标之一.
2.4 对比实验
首先,将所提出的算法与ANTs[15]配准工具包中提供的SyN算法进行了比较.实验表明,使用SyN默认参数对肺部CT图像进行配准,达不到最佳配准性能.通过在多个数据上开展大量实验,可得到更优参数设置:SyN步长为0.25,高斯参数为(3,0),在4种尺度下,每一种最多进行219次迭代.同时,将本文算法与基于Elastix[16]工具包中提供的B样条(B-Spline)配准方法进行了比较.使用归一化交叉相关作为相似性度量,进行了5个分辨率的1000次迭代.另外,还与基于学习的VoxelMorph算法进行了比较.VoxelMorph提出了两种以U-Net为网络框架的Vm1和Vm2网络结构,本文分别在Vm1和Vm2上进行了对比实验.最初的VoxelMorph算法被应用于脑组织配准,为保证公平对比,在EMPIRE10数据集上重新对VoxelMorph进行了训练.最后,为验证Inception模块的有效性,笔者将本文方法与未添加Inception模块的U-Net进行了对比实验.
2.5 实现细节
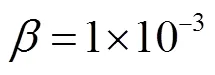
3 实验结果
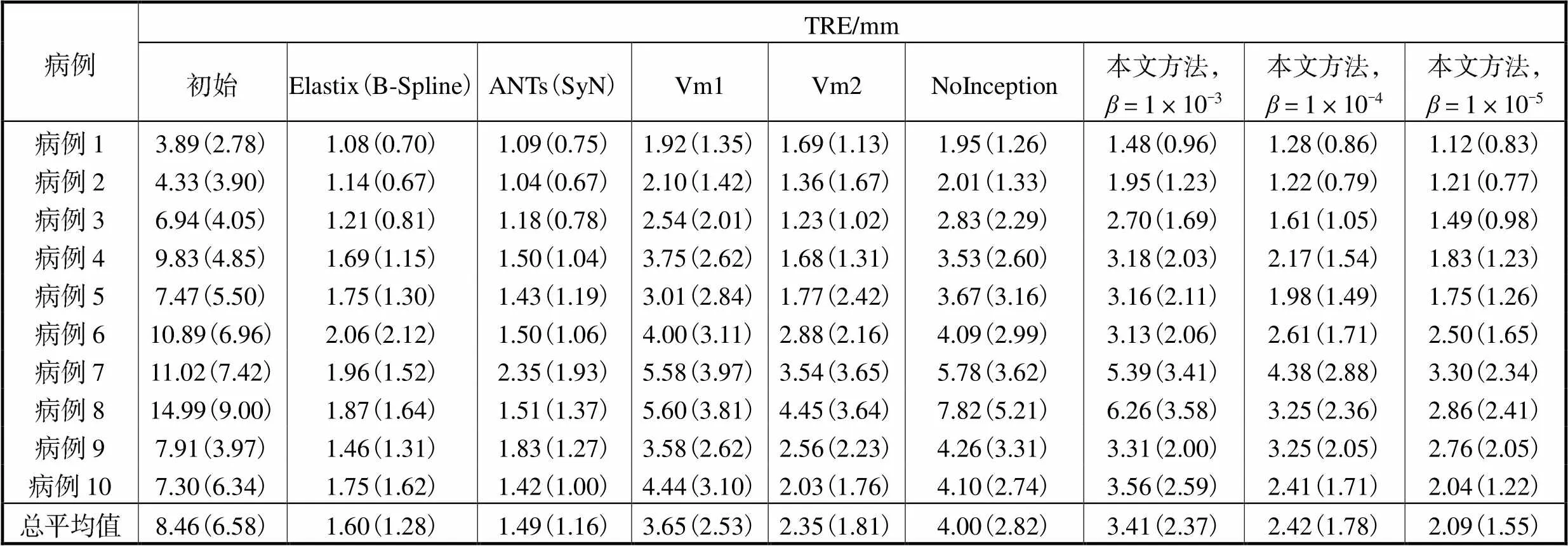
通过使用测试数据集中包含的3000对地标点计算TRE.TRE结果如表1所示,括号中为标准偏差.本文提出的方法取得的平均配准误差为2.09mm,标准偏差为1.55mm,取得了次优结果.
表1 不同算法在DIR-Lab4DCT数据集上的TRE
Tab.1 TRE of different algorithms on the DIR-Lab 4DCT dataset
注:括号内为标准偏差,无量纲.
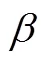
如图5所示,通过计算测试数据集上固定图像掩膜与扭曲图像掩膜间的平均Dice得分,相比于VoxelMorph、SyN和B-Spline,本文所提出的方法可实现最优的配准性能(平均Dice=0.987).
能够进行主观性评价的实验结果如图6所示.稠密位移向量场以RGB图像表示,3个通道对应位移场的3个维度,越亮位置表示该位置发生的变形越大.图中也给出被稠密位移向量场扭曲的形变网格图像.值得注意的是,本文提出的方法与VoxelMorph使用的采样方法相同,与ANTs和Elastix的采样方式不同.
在稠密位移向量场的雅可比行列式图像中,比0大的位置映射为蓝色,而小于等于0的位置映射为红色,即红色标记了出现奇点的位置.在雅可比图像行列式图像中,本文方法并未显现出折叠体素.在RGB图像中和网格图像中,能够看出本文方法获得了更加丰富的变形.
表2总结了所有的配准实验结果,并给出了所有方法在GPU和CPU上的运行时间对比.到目前为止,还没有针对ANTs和Elastix的GPU实现.结果表明,本文所提方法的配准速度相比传统方法(SyN和BSpline)有着指数级提升,与VoxelMorph相近.值得注意的是,本文方法在获得高配准精度的同时几乎不产生折叠体素.另外,表2中的差异和是绝对差异图像中所有体素值的总和,配准效果越好则差异和越小.实验结果表明本文方法在差异图像的定量评价上取得了最优.
表2 各算法在DIR-Lab4DCT数据集上的实验结果
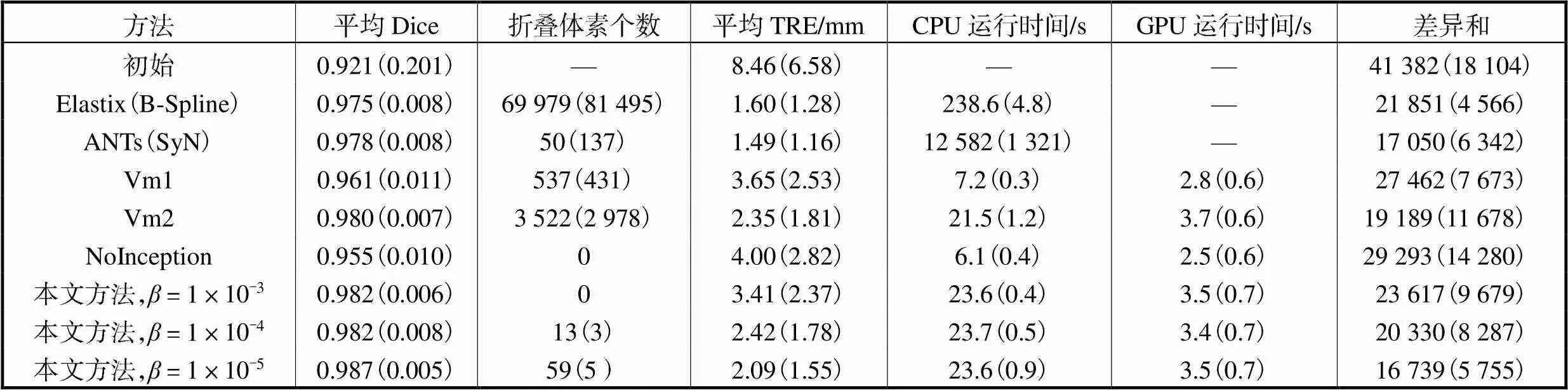
Tab.2 Experimental results of different algorithms on the DIR-Lab 4DCT dataset
注:括号内为各变量的标准偏差,无量纲.
4 讨 论
本文提出了一种基于无监督的三维肺部CT图像配准方法.利用浮动图像和固定图像对之间的NCC来优化卷积神经网络参数,而不需要额外GT.在损失函数中引入雅可比正则项,有效地减少了扭曲图像的折叠体素数量.采用基于3D-TPS变换的数据增强方法人工生成大规模训练数据,满足了卷积神经网络模型的训练需求.实验结果表明,该方法取得TRE值为2.09mm,平均Dice得分为0.987,且扭曲图像中仅包含极少量的折叠体素.测试集上的实验结果也表明该方法在三维肺部CT图像配准中具有良好的鲁棒性.
5 结 语
本文提出了一种基于无监督学习的卷积神经网络方法实现三维肺部CT图像的非刚性配准.基于3D-TPS变换的数据增强能够解决数据资源有限导致的过拟合问题.在跳接之间引入Inception模块,充分融合多尺度深层特征生成高精度的位移向量场,以获得更佳配准效果.实验结果表明,相较于传统方法,本文算法可实现可靠的配准性能,且配准效率得到了指数级提升.
[1]Kaus M R,Brock K K,Pekar V,et al. Assessment of a model-based deformable image registration approach for radiation therapy planning[J]. International Journal of Radiation Oncology Biology Physics,2007,68(2):572-580.
[2]Yu Z H,Lin S H,Balter P,et al. A comparison of tumor motion characteristics between early stage and locally advanced stage lung cancers[J]. Radiotherapy & Oncology,2012,104(1):33-38.
[3]Avants B B,Epstein C L,Grossman M,et al. Symmetric diffeomorphic image registration with cross-correlation:Evaluating automated labeling of elderly and neurodegenerative brain[J]. Medical Image Analysis,2008,12(1):26-41.
[4]Thirion J P. Image matching as diffusion process:An analogy with Maxwell’s demons[J]. Medical Image Analysis,1998,2(3):243-260.
[5]Fan J,Cao X,Yap P T,et al. BIRNet:Brain image registration using dual-supervised fully convolutional networks[J]. Medical Image Analysis,2018,54(1):193-206.
[6]Hu Yipeng ,Marc M,Eli G,et al. Label-driven weakly-supervised learning for multimodal deformable image registration[EB/OL]. https://arxiv.org/abs/1711. 01666v2,2017-11-05.
[7]Miao S,Wang Z J,Liao R. A CNN regression approach for real-time 2D/3D registration[J]. IEEE Transactions on Medical Imaging,2016,35(5):1352-1363.
[8]Balakrishnan G,Zhao A,Sabuncu M R,et al. VoxelMorph:A learning framework for deformable medical image registration[J]. IEEE Transactions on Medical Imaging,2019,38(8):1788-1800.
[9]Zhao S,Dong Y,Chang E,et al. Recursive cascaded networks for unsupervised medical image registration[C]// IEEE/CVF International Conference on Computer Vision. Seoul,Korea,2019:10599-10609.
[10] Max J,Karen S,Andrew Z,et al. Spatial transformer networks[EB/OL]. https://arxiv.org/abs/1506.02025,2016-02-04.
[11] Balakrishnan G,Zhao A,Sabuncu M R,et al. An unsupervised learning model for deformable medical image registration[C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:9252-9260.
[12] Murphy K,van Ginneken B,Reinhardt J M,et al. Evaluation of registration methods on thoracic CT:The EMPIRE10 challenge[J]. IEEE Transactions on Medical Imaging,2011,30(11):1901-1920.
[13] Castillo E,Castillo R,Martinez J,et al. Four-dimensional deformable image registration using trajectory modeling[J]. Physics in Medicine and Biology,2010,55(1):305-327.
[14] Vandemeulebroucke J,Rit S,Kybic J,et al. Spatiotemporal motion estimation for respiratory-correlated imaging of the lungs:Spatiotemporal motion estimation for 4D CT[J]. Medical Physics,2010,38(1):166-178.
[15] Avants B B,Tustison N J,Song G,et al. A reproducible evaluation of ANTs similarity metric performance in brain image registration[J]. NeuroImage,2011,54(3):2033-2044.
[16] Klein S,Staring M,Murphy K,et al. Elastix:A toolbox for intensity-based medical image registration[J]. IEEE Transactions on Medical Imaging,2010,29(1):196-205.
Research on a 3D Lung Computed Tomography Image Registration Method Based on Unsupervised Learning
Jiang Shan,Zhang Hongyun,Yang Zhiyong,Zhang Guobin
(School of Mechanical Engineering,Tianjin University,Tianjin 300350,China)
Deformable registration of 3D lung CT images is crucial in medical image registration. However,nonlinear deformation and large-scale displacement of lung tissues caused by respiratory motion pose great challenges in the deformable registration of 3D lung CT images. Thus,we present a fast end-to-end registration method based on unsupervised learning. We optimized the classic U-Net model and added Inception modules between skip connections. The Inception module aims to capture and merge information at different spatial scales for generating a high-precision dense displacement vector field. To ensure a smooth displacement vector field,we introduced the Jacobian regularization term into the loss function to directly penalize the singularity of the displacement field during training. The existing publicly available datasets cannot implement model training. To address over-fitting caused by limited data resources and to expand the training data,we proposed a data augmentation method based on a 3D thin plate spline transform. Moreover,6060 CT scans will be generated based on the EMPIRE10 dataset,which contains 60 original CT scans to meet the requirement of convolution neural network training. Regarding the DIR-Lab 4DCT dataset,we achieved a target registration error of 2.09mm,an optimal Dice score of 0.987,and almost no folding voxels in comparison with the experimental results obtained using the deep learning method Voxelmorph and registration packages,such as advanced normalization tools (ANTs) and Elastix.
deformable registration;convolution neural network;unsupervised learning;data augmentation;Jacobian regularization
TP242
A
0493-2137(2022)03-0247-08
10.11784/tdxbz202010040
2020-10-21;
2020-12-10.
姜 杉(1973— ),女,博士,教授.
姜 杉,shanjmri@tju.edu.cn.
国家自然科学基金资助项目(51775368,81871457,51811530310);天津市科技资助项目(18YFZCSY01300);天津市津南区科技计划资助项目(20200110).
Supported by the National Natural Science Foundation of China(No.51775368,No.81871457,No.51811530310),Tianjin Science and Tech-nology Project(No.18YFZCSY01300),Tianjin Jinnan District Science and Technology Planning Project(No. 20200110).
(责任编辑:王晓燕)
