基于静态随机存取存储器的存内计算研究进展
2022-11-29蔺智挺童忠瑱吴秀龙汪方铭彭春雨卢文娟陈军宁
蔺智挺 徐 田 童忠瑱 吴秀龙 汪方铭 彭春雨卢文娟 赵 强 陈军宁
(安徽大学电子信息工程学院 合肥 230601)
1 引言
人工智能(Artificial Intelligence, AI)在各个领域得到了特别的关注和广泛的应用,同时也促使着“算力时代”的到来。与AI相关的算法,如深度神经网络(Deep Neural Networks, DNN)、卷积神经网络(Convolutional Neural Networks, CNN)等需要进行大量的数据处理。然而,大多数现代计算系统是以传统的冯·诺依曼结构为基础建立的,物理结构上包括独立的计算单元和存储单元,其在执行各种计算任务的过程中,需要在存储单元和计算单元之间反复传输大量的数据,这将导致巨大的延迟和能量损耗[1–3],从而限制了数据处理的效率。处理器和存储设备长期非均衡的发展,使得存储器和处理器之间的速度差距越来越大,这种差距称为“内存墙”,由此产生众所周知的冯·诺依曼瓶颈。只有解决冯·诺依曼瓶颈,才能将人工智能应用到能量预算和效率有严格限制的设备中(如物联网、可移动设备、可穿戴设备等)实现“人工智能无处不在”。
为了克服传统冯·诺依曼结构带来的计算限制,存内计算(Computing In Memory, CIM)的概念被提出,其不需要将数据从存储器传输到处理器,直接将运算部分整合到存储阵列内部执行计算,这不仅减少了中间数据的传输,还减轻了处理器的运算量。由于总线的带宽不再是吞吐量的限制因素,从而显著地提高了吞吐量和能效[4–7]。存内计算的另一个显著的优势是能够实现多行读取,从而减少了存储访问的次数,增加了数据吞吐量。
随着有效缓解冯·诺依曼瓶颈的存内计算成为一个热门的研究领域,越来越多的学者开始从事这方面的研究,乘法计算、加减法运算以及逻辑运算已通过存内计算实现,相关的研究在国际等级的期刊、会议陆续出现。随着学者对存内计算技术研究的深入,一些学者发现在各种存储器中实现存内计算具有可行性,由于静态随机存取存储器(Static Random-Access Memory, SRAM)单元稳定性高,读取速度快而且在最先进的处理器中普遍存在,这使得在芯片上集成计算能力具有可行性。基于SRAM的存内计算也受到国内外学者的关注。在SRAM阵列中实现存内计算技术包括数字信号[8–10]、模拟信号[11–14]和混合信号方法,基于SRAM存内计算技术的具体实现将在之后的章节概述。
本文其余部分的组织结构如下,第2节主要介绍SRAM存内计算的应用背景,例如卷积神经网络、机器学习分类器、编码、存内加解密算法等;第3节阐述基于SRAM存内计算的逻辑运算、乘法累加操作(Multiply ACcumulation, MAC)等运算功能的实现。第4节介绍以模数转换器为核心的量化技术和不同数模转换器的特点;第5节分析存内计算架构中存在的一些挑战与问题;第6节从不同研究方向展望存内计算技术。
2 存内计算技术应用背景
现有存内计算能实现的计算原语已经广泛应用于各个AI领域之中,从要求大量数据访问的图像语音识别到确保数据安全性的加解密算法。在本节中,介绍了存内计算技术的应用背景,并且分析了SRAM阵列如何与这些应用相结合。
2.1 应用于机器学习
2.1.1 卷积神经网络
CNN作为DNN的延续和发展,主要应用于图像处理。如图1所示,其中展示的是CNN中的卷积层。卷积层提取了输入的不同特征,全连接层组合这些特征映射到最终的输出。对于每一个卷积层都包含一系列卷积核(Weight, W)、输入特征映射(Input Feature MaP, IFMP)、输出特征映射(Output Feature MaP, OFMP)。输出特征映射是由卷积核与输入相卷积得到,其中主要的运算就是MAC。所以很多研究者致力于实现存内的MAC运算,而且SRAM单元互补对称的结构很利于应用于MAC。通常把权重存储到SRAM单元内部,输入可通过外围电路应用于字线上或者通过数字辅助电路应用于阵列之中。为了进一步减小功耗和硬件开销使存内运算更好地满足SRAM阵列,文献[15,16]实现了存内的二值化神经网络(Binary Neural Networks,BNN),其输入和权重都是二值为“+1”或者“–1”,其精度相较于传统的CNN算法相差不大。Chih等人[17]提出基于6T SRAM的全数字存内计算用于实现CNN中的乘法累加操作,具有较高的能量效率和吞吐率。SRAM阵列具体如何实现这些乘累加操作,后面的章节会具体介绍。

图1 SRAM阵列应用于卷积神经网络
2.1.2 机器学习分类器
在机器学习中,分类器对所需处理的数据进行分类,用于判断一个新的观察样本所属的类别。然而,由于分类器算法的高数据访问速率及高度不规则的数据访问模式,实现低开销的分类器算法具有挑战性。所以,学者开始关注存内实现分类器,并且其中较多的工作是基于SRAM阵列实现分类器。
文献[18, 19]提出了一种机器学习分类器,其中计算是在标准6T SRAM阵列中执行的。外围电路通过SRAM列来实现混合信号的弱分类器,通过组合多个列来克服电路的非理想性,实现强分类器。其中输入是以字线电压体现,而权重是固定存储在阵列单元内部。此设计在采用标准训练算法时将能耗降低了113倍。Kang等人[20]介绍了一种随机森林机器学习分类算法的存内实现。同样地,该设计也是基于6T SRAM阵列,支持大规模的并行处理,从而最大限度地减少了数据与存储器之间往返的次数。在存内实现高数据访问量算法将会是未来的趋势。
2.2 应用于编码
数据传输差错控制编码中一个重要的算法就是汉明距离。汉明距离是比较两个相同长度字节中有多少位不同的算法,其在信号处理和模式识别中都有广泛应用。
Kang等人[21]提出了一种基于6T SRAM阵列的存内汉明距离计算。该设计中一个数据存储在单元内部,而另外一个数据是应用于字线上,最后的汉明距离计算结果以两个位线电压差得到。由于结果是以位线电压体现,所以该设计的计算方式只能按列进行,这就与SRAM按行存储模式有所冲突,降低了计算效率。为了解决此类问题, Ali等人[22]提出了一种9T SRAM单元用于汉明距离计算,该计算方式是按行进行的。其中输入向量应用于两根读位线即上读位线(Read Bit Line, RBL)、读位线非 (Read Bit Line Bar, RBLB),另一个数据也是存储在单元内,异或(eXclusive OR, XOR)结果最终在按行连接的电源线(Source Line, SL)。为了打破汉明距离算法在存内空间上的限制,接下来的研究方向可以着眼于可同时按行、按列进行汉明距离计算。
2.3 应用于存内加解密算法
在大数据时代对数据加密尤为重要,但是通过数字域实现一套加密算法,例如高级加密标准(Advanced Encryption Standard, AES),其功耗和延时会限制系统整体性能,而存内实现AES就是很好的选择。
如图2所示,为AES加解密算法的全流程,其中包括字节替换、行移位、列混合、轮密钥加这4个步骤。Wang等人[23,24]实现了存内全流程AES。Agrawal等人[2]基于8T SRAM提出了“读算存”策略,其中将运算得到的XOR结果通过每一列尾部的数据选择器存储到另外一行,可以实现AES中迭代式XOR部分操作,但是这样的策略同时也增加了存储阵列的面积开销,需要额外空出一行来存储运算结果。Huang等人[25]修改了带有双字线的6T SRAM位单元,以在不牺牲并行计算效率的情况下实现 XOR 加密,这可以保护 CIM中的DNN模型数据不被泄露。
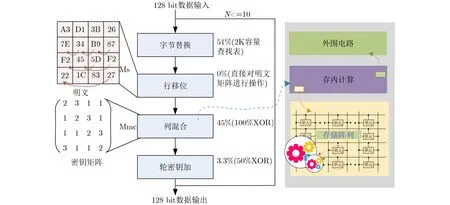
图2 AES流程图
3 SRAM存内计算实现的运算功能
基于SRAM的存内计算设计既可以实现SRAM的基本读写功能,也可以通过设置位线电压,改变单元结构以及修改外围电路来实现计算功能。目前一些存内设计主要实现的功能有布尔运算、内容可寻址存储器(Content Addressable Memory,CAM)、乘法累计以及减法运算。
3.1 布尔运算
由于阵列单元结构的重复性,所以在存内较易实现简单重复的布尔逻辑运算。现阶段大多数布尔运算是通过激活相邻的两个或多个单元的字线,用灵敏放大器(Sensa Amplifier, SA)感测位线电压所实现[25–28]。然而对于使用传统的6T阵列执行存内操作,同时开启多行会带来一些挑战,例如读干扰问题。因此电路设计者采用读写分离的SRAM单元[6,26,29]或降低字线(Word Line, WL)电压的方法来缓解这些挑战。Agrawal等人[2]则提出了8T SRAM和8+T SRAM单元结构实现布尔逻辑运算,提高了吞吐率和计算速度。这里主要介绍其或非(Not OR,NOR)和与非(Not AND , NAND)逻辑运算。8T SRAM单元结构如图3(a)所示,通过控制一列中两个位单元的读操作,在RBL上实现布尔逻辑运算。如图3(b)所示,为了实现NOR逻辑运算,首先将RBL预充到VDD,同时激活一列中相邻两个单元的字线,当单元1和单元2中存储的数据都为0时,两个单元的放电路径同时截止,RBL保持预充高电平,经过两个反相器(INVerter, INV)后,NOR输出为1,其余输出为0。
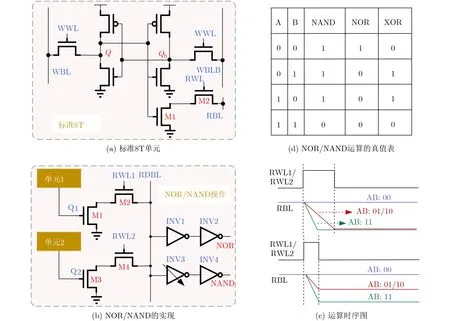
图3 布尔运算
NAND逻辑运算通过准确控制两条读字线(Read Word Line, RWL)的脉冲宽度实现,只有当单元1和单元2中存储的数据都为1时,两个单元中的M1, M3同时导通放电(此时放电速度最快),单元1和单元2其中一个为1时,只有一个放电路径使得RBL放电不完全。如图3(c)所示,这两种情况下RBL上的电压会有所不同。通过选择INV3的跳变点,使得它仅在“11”情况下输出高电平,此时INV4输出NAND操作。两种运算的真值表如图3(d)所示,此单元具有解耦的读写路径,同时激活两条读字线不会带来读干扰问题。另一种设计是将8T SRAM结构改进为8T+SRAM结构,其使用非对称SA检测两条读位线上的电压差实现布尔逻辑运算,因为此单元结构允许差分读取检测,所以与8T单元结构相比具有更高的鲁棒性。
表1比较了5种现有的存内计算实现布尔运算的技术,结果表明,大多数方案是通过修改标准单元实现各种布尔运算。文献[30,31]提出创新的策略使用6T SRAM 单元执行布尔运算,避免了读写干扰的风险。其将两个被访问的单元连接到不同的局部位线,最终在全局位线连接的SA端输出运算结果。类似于上述策略的大多数存内设计在单个周期只能实现两个输入的布尔运算,若要实现复合布尔逻辑运算至少需要两个周期。文献[32]提出新的12T双端口双互锁存储单元在单个周期内同时实现两对数据集的布尔运算。安徽大学的Lin团队[33]充分利用传统8T的双字线和3个读端口实现多输入布尔运算,有效地突破了现有方案的瓶颈。这些工作则解决了多输入布尔逻辑需要两周期的问题,能做到在1个周期内就可完成复合布尔逻辑运算。
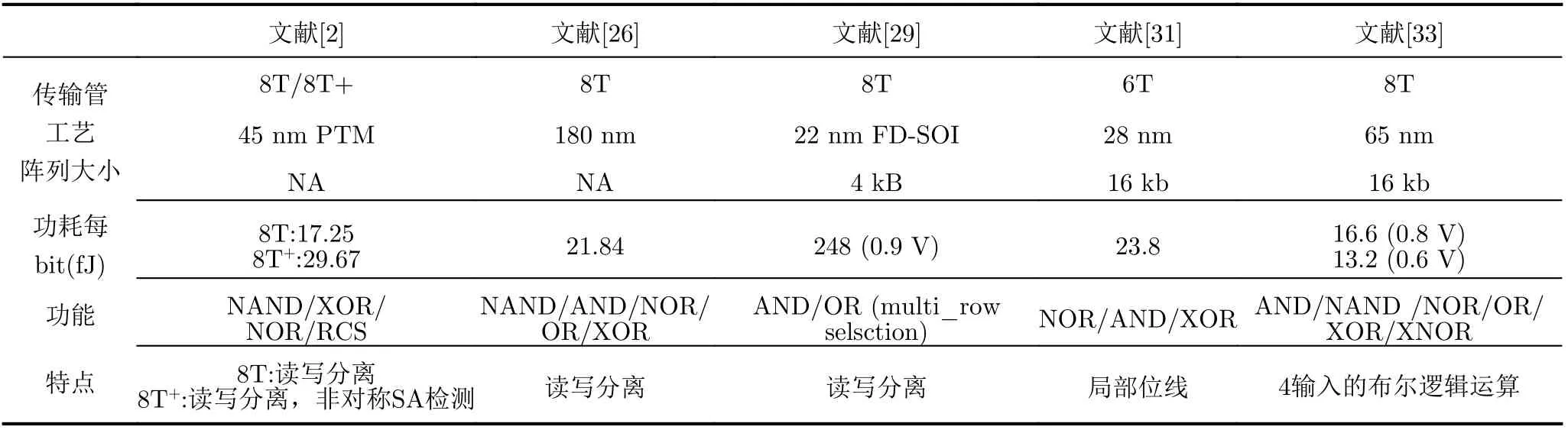
表1 CIM实现布尔运算的相关设计参数以及性能指标
3.2 乘法及累加
DNN的关键算法是矩阵向量乘法(Matrix-Vector Multiply, MVM),包括乘法和累加计算。然而,算法频繁的访问存储被限制了能效和速度,为了解决这个问题,学者提出BNN将权重和神经元激活二值化[34–36],MVM被简化成按位XNOR运算。Agrawal等人[14]实现了XNOR运算通过模拟累加方式把结果累加到SL之上,原理如图4所示。
其中操作分为两步:预备阶段如图4(a)所示,在执行运算之前2维向量输入A1和K1被存储在存储阵列之中,RBL/RBLB预充到VDD。接着,A1相应行的字线RWL打开,RBL/RBLB根据相应存储阵列存储的值进行放电,然后,所对应行的SL接地。例如,存储阵列存储的数值为“1”(Q=VDD,QB=0 V),则RBL通过M2, M1放电到0 V。运算阶段如图4(c)所示,首先,对K1进行操作,K1值的大小是存储阵列存储值设定的。如果Q=0,则K1=0;如果Q=1,则K1=1。然后K1所在行的SL上寄生电容存储了初始电压,并且其对应行的RWL开启。最后SL上积累XNOR计算结果。例如,A1=0,K1=0,则SL电压“上拉”;A1=0,K1=1,则SL电压“下拉”。通过上面两步实现了A1*K1,也就是XNOR运算。对应的真值表可由图4(b)看出。完成了单次XNOR运算后,运算的累加结果体现在SL电压上。
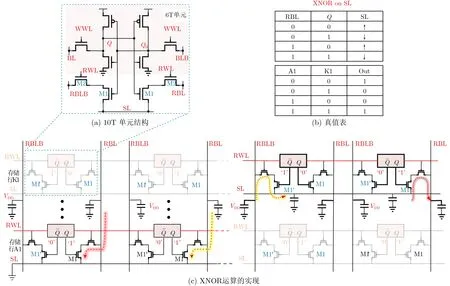
图4 乘法运算
整个存内乘法技术的关键是如何累加XNOR计算结果。一些存内计算设计[11,37,38]以模拟的方式在SRAM阵列中实现乘法累加,以加速人工智能算法。表2总结了部分存内设计实现乘法运算的参数以及性能指标。虽然有些方法可以显著提高能量效率和执行效率,但也存在一些不足,例如使用ADC/DAC会产生额外的面积开销或者受到模拟非理想性的影响降低了推理的准确性。针对这些问题一些学者做了分析研究,例如文献[37]提出了奇偶双通道策略增加了运算吞吐量和整体系统的能耗效率。文献[39]研究了模拟运算的非理想性对基于6T SRAM单元实现点乘运算的影响,并提出有效的缓解方案。文献[40]将基于6T SRAM的内存运算与数字近内存计算多位积和运算相结合,以提高读取精度并减少面积开销。
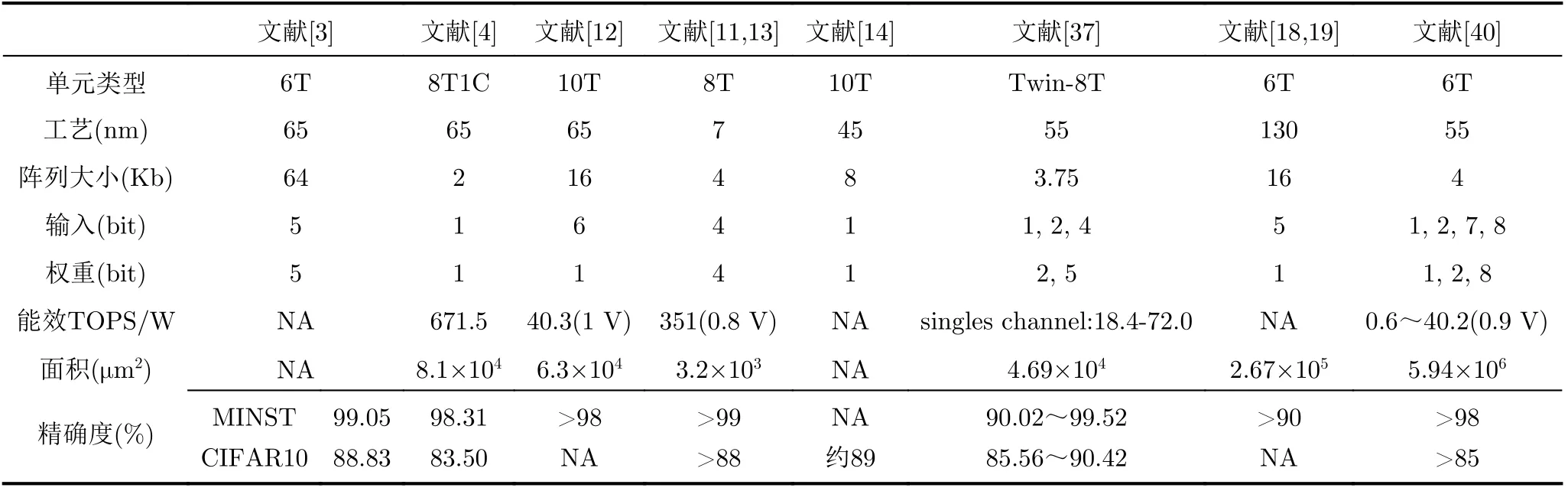
表2 存内实现乘法运算的参数以及性能指标
3.3 减法
减法运算是广泛使用的匹配模式算法,根据脉宽调制技术研究者提出基于SRAM的减法运算。减法运算实现如图5所示,将减数以4位二进制的形式输入到字线脉冲产生电路,脉冲产生电路根据输入的特征值选择开启一条字线(输入为1时开启WL,反之开启WLB),4条字线开启的时间根据输入特征值的权重高低分别为8T, 4T, 2T, 1T。被减数以4位二进制形式存储在一列相邻的4个存储单元。如果局部位线(Local Bit Line, LBL)和局部位线非(Local Bit Line Bar, LBLB)与存储节点“0”连接则使其放电,与节点“1”相连则保持预充电压。之后通过比较两条局部位线的电压差获得减法的计算结果,这种多行开启的方式实现减法运算极大地提高了吞吐量。
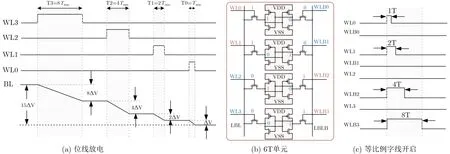
图5 减法运算原理图
3.4 内容可寻址
CAM主要分为二进制内容可寻址(Binary Content Addressable Memory, BCAM)和三进制内容可寻址(Ternary Content Addressable Memory,TCAM)。通过对需要检索的数据与存储器内的数据进行比较匹配得到存储位置,这样操作可以极大程度地减少待检索数据的搬移。
3.4.1 二进制内容可寻址
文献[9]使用如图6(a)所示的push-rule 6T SRAM单元构成的阵列,BCAM操作时,搜索数据和待查找数据都是由4位二进制组成的,搜索数据以电压的形式加载到字线,待查找数据存储在一列相邻的4个单元。每列的匹配结果通过位线BL与BLB接的SA和与门体现。文献[41]提出了基于SRAM 6T的可重配置CAM/SRAM结构,如图6(b)所示,该结构可通过CAM_MODE在CAM模式和SRAM模式下进行切换,提高了单元利用率。在CAM模式下执行并行数据搜索,并通过单端灵敏放大器输出结果表示寻址是否匹配。但是此设计以面积和功耗为代价实现并行数据搜索。利用CAM搜索数据的功能,文献[42]提出CAM辅助电路技术,该技术通过提高写速度来提高能量效率。文献[43]则利用3D-CAM设计一种新颖的存内数模转换器。
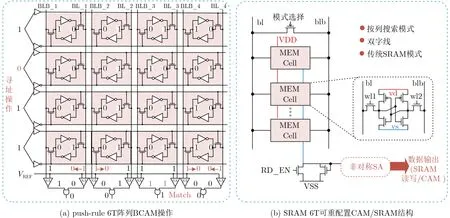
图6 二进制内容可寻址
3.4.2 三进制内容可寻址
另外一种寻址模式为TCAM三进制寻址。由于TACM在存内中可以有无关态,因此其可以匹配多个搜索字符串。表3比较了多种现有的内容可寻址方案,如图7(a)所示为TCAM阵列[33],其中TCAM的3种状态:0/1/X(X为无关态),分别由00/11/10表示。搜索的数据存储在SRAM阵列同一行相邻的两列中,目标数据由RWL和WLL的电平表示。文献[44]同样使用读写分离的8T单元实现TCAM功能,如图7(b)所示,通过控制其RWL和搜索字线USL和LSL的开关实现寻址。此单元不仅可配置为TCAM,还可以执行左移、右移功能。
图7 三进制内容可寻址
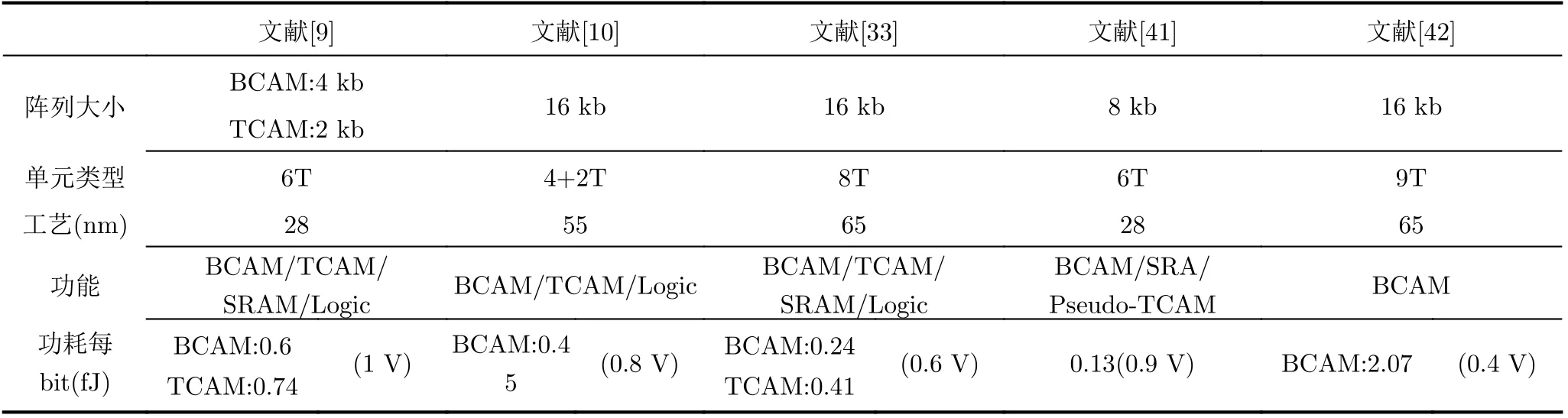
表3 存内CAM芯片参数以及性能指标总结
与上述不同的是,文献[45]提出的10T SRAM提高存内计算的稳定性,通过重新配置数据线、读出放大器和读端口可实现内容可寻址,由于其单元结构的对称性可提供按行或列的数据搜索。考虑到三进制内容可寻址存储器受到单元面积大、高搜索功率以及匹配线上搜索速度和信号余量的折中等限制,Xue等人[46]采用分离控制14T TCAM单元和一种3倍裕量电压检测放大器缓解上述问题,同时降低了搜索延迟和搜索能量。
4 SRAM存内计算量化技术
在SRAM阵列中执行乘法累加运算的本质是模拟运算,其将权重存储在单元阵列中,输入激活应用到字线,运算结果以模拟电压的形式体现,那么如何量化该模拟电压以及提高量化精度显得尤为重要。
4.1 Flash ADC应用于存内计算
常见的ADC结构有积分型ADC[12,14,47]、逐次逼近型ADC[3,48–50](Successive Approximation Register Analog-to -Digital Converter, SAR-ADC)以及Flash ADC [11,13,51,52],其中Flash ADC由多个比较器构成,是目前转换速率最快的一种结构。文献[4, 5]在外围电路中嵌入11级Flash ADC,将代表每列MAC结果的模拟电压进行数字化处理。每个ADC由10个基于采样的自校准单端比较器组成,其操作分为两个步骤,首先,在每列MAC计算期间,将代表运算结果的MBL通过传输门连接到比较器的电容Vcap,同时RSTB=1产生负反馈。之后,将电容的输入节点切换到参考电压VREF,并且关闭负反馈路径。VREF和VMBL之间的电压差将导致电容的充放电,使反相器被驱动为高电平或低电平,之后通过增益反相器链放大输出数字值。文献[53]使用strong-arm比较器构成的11级Flash ADC进行数字化,并且通过多路复用器在64列之间共享ADC,减少了面积开销。与非线性量化相比,其采用受限线性量化方案,由于更宽的参考电压间隔将CIFAR-10的精度提高到88.8%。与上述不同的是文献[13]在功耗、性能和面积之间权衡选择了4 bit Flash ADC,此ADC使用SA代替模拟比较器以节省面积降低功耗。
4.2 应用于存内计算中的逐次逼近型ADC
与Flash ADC相比,SAR-ADC的结构相对简单,广泛用于处理存内计算中产生的模拟运算结果。考虑到CIM中的ADC面积和能量开销,文献[49]采用SAR架构的ADC提供8位输出,用于后续数字计算。文献[3]使用SAR-ADC将多位乘法运算累加的模拟电压转换为数字输出,由于采用SA作为比较器和电容阵列的DAC,从而降低了SAR-ADC的静态功耗。文献[37]利用了电容阵列经过多周期操作生成了不同的参考电压用于处理位线的模拟电压,并且利用了电容阵列对位线电压进行了高低位合并,也就是进行了加权。在此ADC中是将不同数值的电容通过开关依次接到SA两端中的一端,也就是通过多个操作阶段进行逐次比较,从而对位线的模拟电压进行量化。尽管此逐次逼近型ADC相较于Flash ADC在量化速度上有所不足,但是使用多周期可以节省大量的面积开销。
4.3 数字电路辅助型ADC
如何将低精度ADC应用于存内计算之中一直是关键技术。下面的工作就是利用了数字电路进行辅助,使得低精度ADC在量化模拟电压时也能提高量化结果。
文献[14]提出基于电荷共享方法来执行XNOR和近似popcount运算。最终的结果以模拟电压的形式体现在源极SL上,为了检测该模拟电压,他们提出了一种低开销、低精度电荷共享的串行积分型ADC。由于低精度的ADC很难检测准确地模拟电压。所以该方案还采用双字线和双级ADC技术来最小化脉冲计数输出的误差。双字线技术存储器阵列每行的前1/2单元连接到RWL1,另1/2连接到RWL2。以确保一次只有1/2的单元参与电荷共享,从而减少待检测的SL上电压状态的数量。双级ADC如图8(a)所示。在ADC检测的第1阶段,ADC控制模块产生信号VREFN, VREFP以及使能信号SAE,并将其馈送到两个SA,以确定SL上模拟电压的子类。其他的控制信号用于ADC检测的第2阶段对虚拟单元进行操作,虚拟单元根据子类在每个周期向SL注入或从SL泵出电荷,同时数字电路计数器在产生ADC输出的最后3位期间对周期数进行计数。
如图8(b)所示,文献[40]提出了自参考多级读出器(Self-Reference Multi Level Reader, SRMLR)用于量化两个位线的模拟电压值。SRMLR是由电压型SA、数据线预充选择器、输出锁存器和编码器所组成的。无论是Flash ADC、逐次逼近型ADC还是数字电路辅助型ADC都是对位线运算结果进行量化,并在面积、功耗、精度之间的折中。
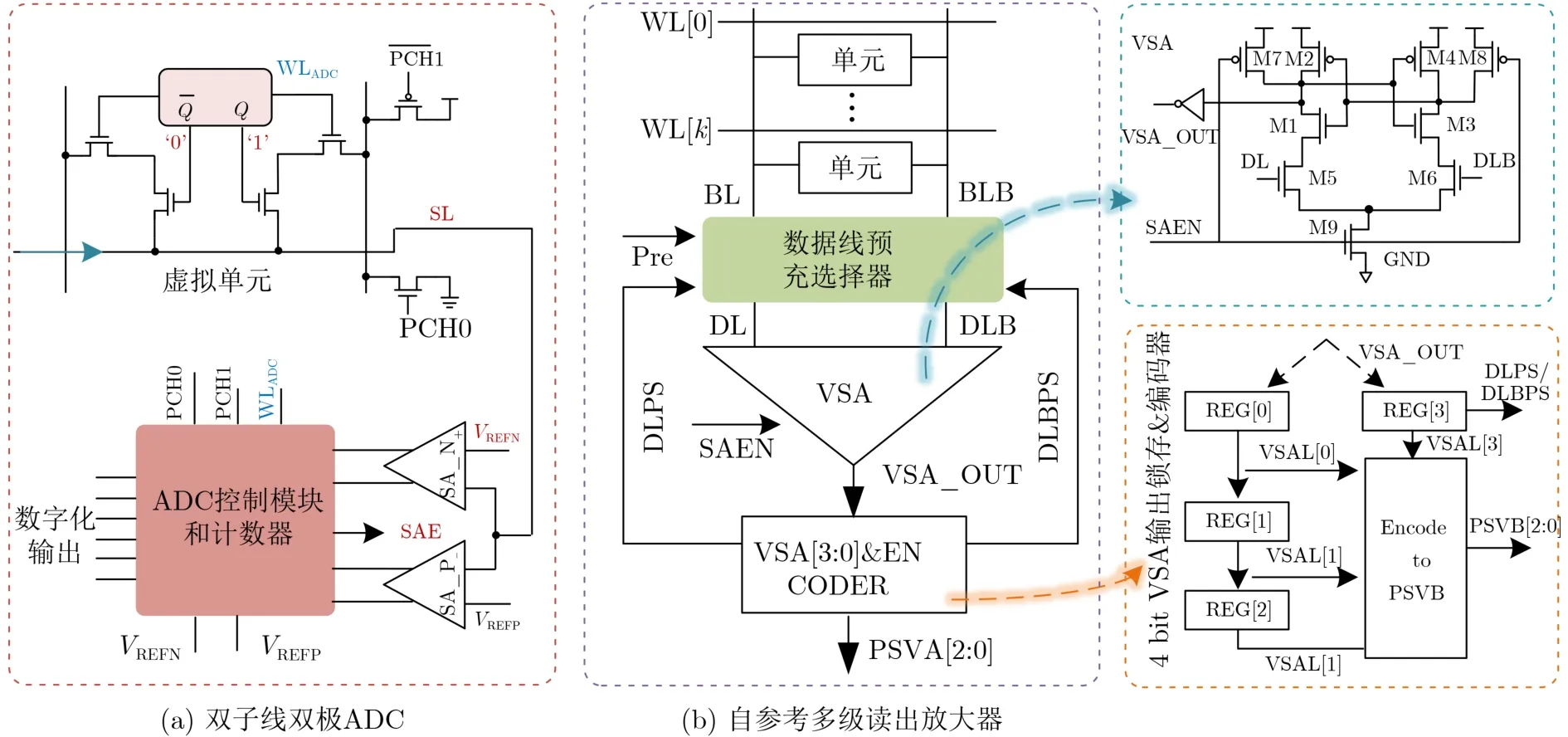
图8 数字辅助型ADC
5 存算架构面临的挑战及解决策略
为了实现存内计算中的特定功能,国内外学者对单元结构的重构或外围电路的增添方面进行了大量的研究。各种存算策略的出现同时也带来很多架构问题,下面针对存算架构中几个关键问题进行分析。
5.1 存算加权技术分析
5.1.1 晶体管尺寸加权技术
在实现多比特乘法中,晶体管的宽长比经常被用来作为加权。如图9(a)所示,8T阵列中通过调整不同列的读取访问管尺寸大小作为数据的权值[1],在此8T阵列中第1列的M1和M2的宽长比等于8,以此类推第2列、第3列、第4列的M1, M2的宽长比分别为4, 2, 1,因此可以实现多位乘1位的点积和运算。此工作合并4列的位线放电电流,最后通过运算放大器将电流值转化成电压值进行量化。相同地,文献[37]基于传统8T提出了twin-8T结构,将其中一组读取晶体管宽长比调至另外一组的2倍,实现了两比特输入加权。
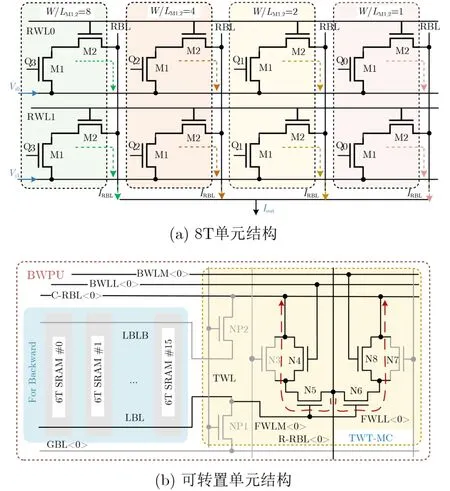
图9 晶体管尺寸加权
如图9(b)所示,文献[38,54]提出一种可转置运算单元结构,其内部也是利用晶体管的宽长比进行加权。此策略是基于传统6T单元增加额外的晶体管,可以实现水平方向和垂直方向的乘法运算。上述的研究均是利用了位线放电电流与晶体管宽长比成正比的特点,所以可以通过调节其尺寸得到多位乘法运算。但是由于需要调大管子的尺寸,所以在芯片之中所需要的面积开销也很大。如果想要实现更高位的运算,那么面积开销是需要呈指数倍增长,文献[37,38,54]利用宽长比方法只做了两位加权。宽长比对运算进行加权的实质是对电流进行等比例扩大,之后研究的方向可致力于寻找另一种等比例扩大电流的策略来代替宽长比加权,减少面积开销带来的挑战。
5.1.2 电容阵列加权技术
电容阵列在实现运算结果的高低位合并是一项常用的技术,也就是通过电容阵列提高运算的位数[11,13]。如图10(a)所示,RBL[3]-RBL[0]每一列上的电容总值都为9CU,然而每根位线上分享的电容数值比例为8:4:2:1,因此可通过打开S0和S1分别在N3-N0得到8 /9∆v, 4 /9∆v, 2 /9∆v, 1 /9∆v。文献[55, 56]通过比例为16:1的电容阵列,完成了低4位运算同高4位运算的合并,基本操作与上述类似。上述的研究都是通过电容的数值完成加权操作的,此技术与晶体管尺寸技术加权同样有较大的面积消耗。另外一种做法是通过多周期多运算结果进行分享[57]得到与电容加权相同的结果,如图10(b)所示,如果需要1/8加权,位线在第1个周期连接到端口2,电压降低到1/4。第2个周期,位线连接到端口1,电荷再平分,所以现在的电荷变成原来的1/8。为了获得其他权重,可以在类似于上述操作的多周期操作中完成,此技术比上述电容数值加权技术增加了计算周期,但是减小了面积开销 。
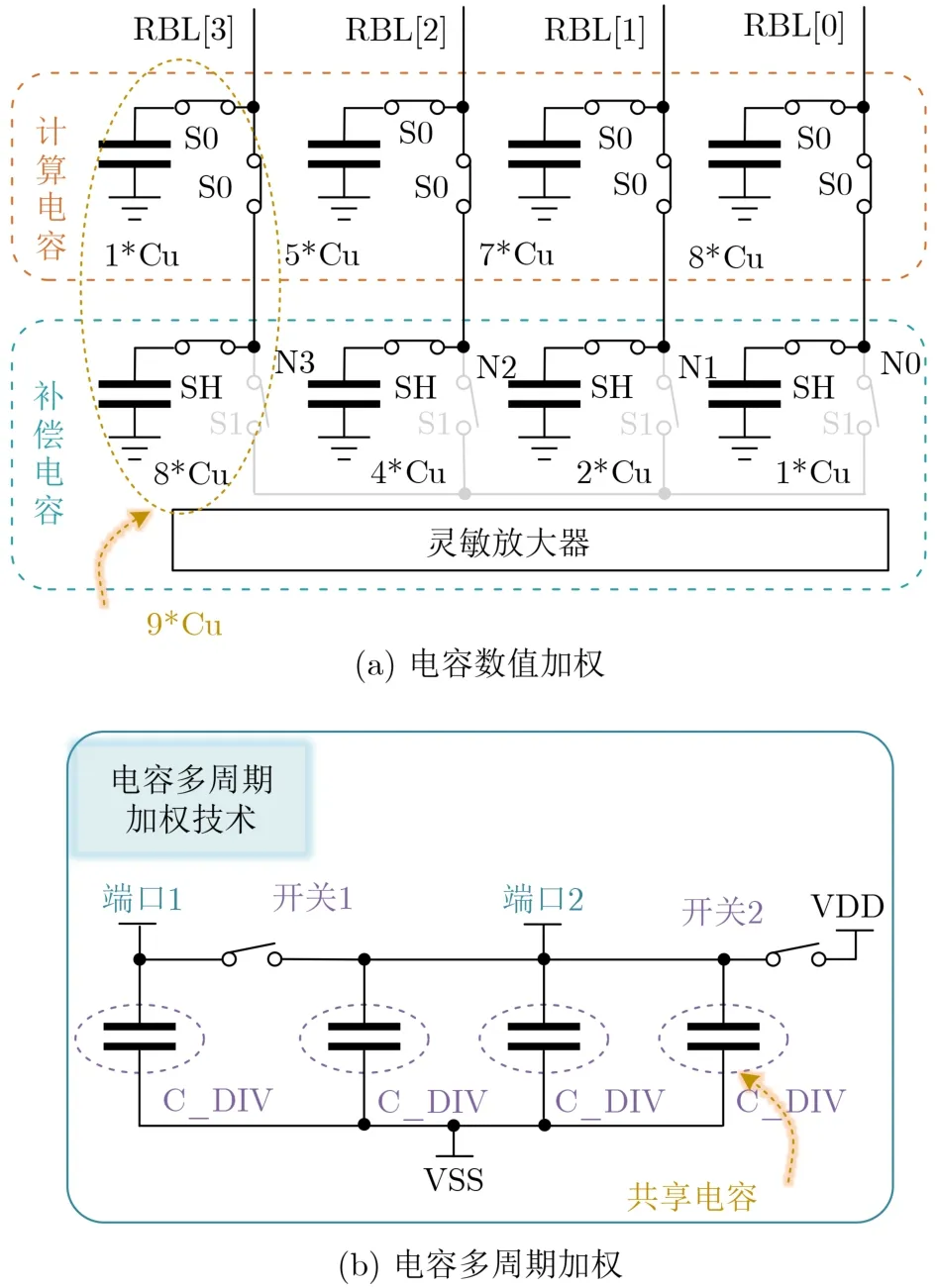
图10 电容加权技术
通过电容阵列,无论是电容数值加权还是多周期分享,都是在面积开销和速度开销之间的折中。而且,电容分享在通过开关共享时也会有损耗,影响计算结果的精度。过大的电容虽然可以增加计算结果的线性度,但是也会给电路带来额外的功耗。
5.1.3 脉冲个数/高度/宽度加权技术
Sinangil 等人[13]提出的用于机器学习的CIM芯片采用了脉冲个数调制电路,如图11(a)所示,利用字线 RWL 上不同的脉冲数目代表不同的权重。这些脉冲是由计数器根据输入数据的数值所产生的,再应用到字线开启单元,从而实现多比特输入。脉冲高度加权可以由如图11(b)所示电路产生,字线DAC电路由二进制权值电流源和复制单元所组成[19],此电路可根据输入数据不同生成不同比例的电流,电流再通过二极管连接的MA,R产生应用于字线的电压,输出电压根据数字量0000-1111一一对应,从而实现了不同权重的输入。除了脉冲个数与脉冲高度加权技术,还有另外一种控制访问管放电时间的脉宽加权。如图11(c)所示,文献[55,56]提出了一种功能性读技术对存储的权重进行4位加权。该策略的实现是基于脉宽调制,而且在位线电压保持在一定的范围内,位线放电电压与字线开启时间成正比,所以可以通过调整WL0-WL3开启时间为8:4:2:1实现4位加权运算。
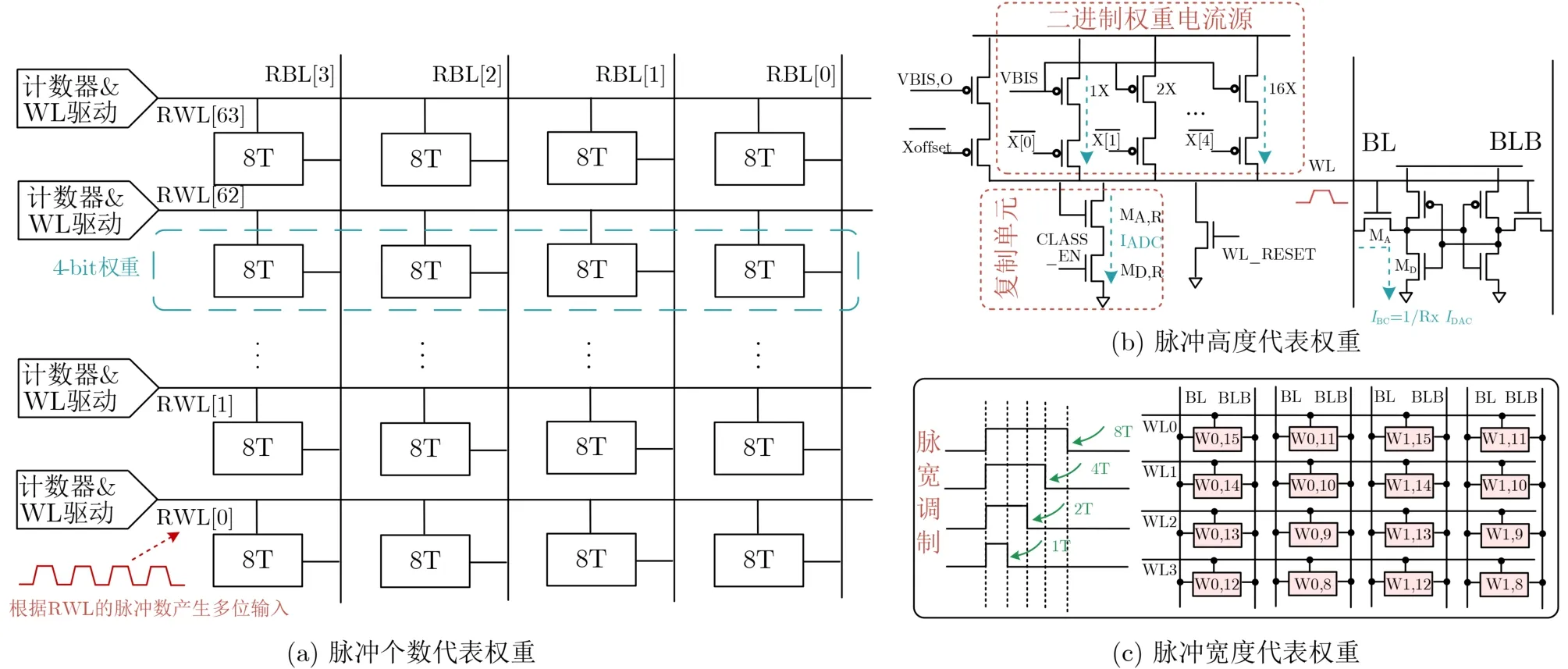
图11 脉冲加权
3种技术的核心问题在位线上等效电阻与寄生电容不是恒定的,在整个计算过程中位线电压是动态变化的,因此会使整个系统计算精度下降。而且整个阵列中字线长度较长,所以应用于字线的电压会随着寄生电容不同发生畸变,导致相同的计算数值在不同列产生不同的放电电压,产生计算结果有不一致性。
为了保障存内计算中的一致性以及提高线性度,文献[58]提出了一种共源共栅电流镜(Cascade Current Mirror, CCM)用于钳制位线电压,如图12(a)所示,每条位线上增加4个晶体管,钳制位线电压并按比例镜像读取电流,从而提高计算的线性度。时序如图12(b)所示,在预充电过程中,BL充电至VDD/2左右,Vout接地,VCM/VG连接至VDD;然后CCM进入预读取阶段,VG连接到 BL,为了确保晶体管在饱和区工作,VCM的偏置电压被设置为VDD/2左右,CCM需要很短的预读取时间,以使BL 的电压在 WLR脉冲到达之前保持稳定。最后多行读取开始,多行字线被激活,M1和M3按比例镜像多行读取时位线上的总电流IBL,并且通过电容收集镜像的电流形成输出电压Vout表示计算结果。由于此电路采用双字线6T单元结构,减少了字线上的脉冲宽度延迟,从而保证电路计算的一致性。仿真结果显示,在0.8 V电压下,CCM电路可将非线性降低70%,在0.9 V电压下,计算一致性提高54.85%。此研究不仅探索了非线性和不一致性产生的原因,还提出相应的解决方案是当前技术的一个突破。Kim等人[59]提出了全数字位串行计算架构,基于其新颖的可重构位串行结构,输入和权重精度可从1 bit配置到6 bit,此设计不受上述模拟计算的非理想性影响,但是提供的面积优势是以降低吞吐率为代价。
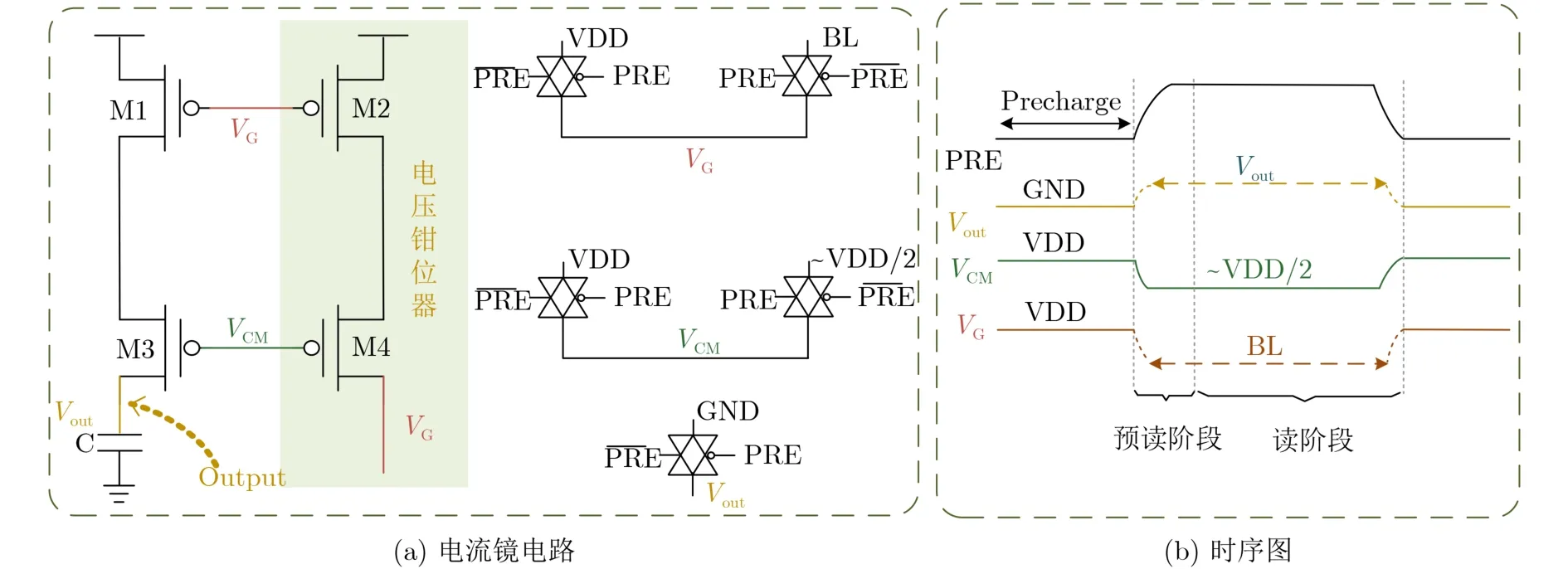
图12 共源共栅电流镜
5.2 外围电路占比过大
存内计算的架构为了执行额外的计算功能需要大量的外围辅助电路来完成。例如,在实现数字功能中的逻辑运算时,每一列位线上需要两个SA来区别不同输入;在执行模拟运算中的乘累加时,就需要外围辅助电路量化这些电压值。典型的做法是引用ADC进行量化,这都会增加外围电路的占比。此外,多比特输入生成也会占据很大部分的面积。
外围电路占比过大是研究者在设计电路过程中需要去解决的问题,为了减少外围电路的开销,Yin等人[53]通过64列共用一个ADC,分64次对位线电压进行量化。Biswas等人[12]实现了存内基于脉宽的6 bit输入,传统的做法是通过外围电路生成64种不同脉宽,再根据输入将对应的脉宽作用到阵列之上,这样策略的外围电路面积开销过大。此工作中提出了GBL_DAC(Global Bit Line Digital-to-Analog Converter)电路,该电路使用了3个2:1多路复用器(MUltipleXing, MUX)和一个8:1MUX实现了64:1MUX的功能,通过组合8种不同的脉宽就可生成64种与输入对应的脉宽,大大减少面积开销。在存内计算系统级设计时也不能一味为了实现更复杂的运算增加外围电路而忽视了辅助电路的复杂性。
5.3 读破坏问题
在存内计算中经常需要同时开启多行进行操作,增加数据处理的吞吐量。但是,同时开启多行会导致存储节点与位线直接相连接,读取过程中很容易造成数据被翻转,导致最后的计算结果发生错误。如图13(a)所示,在一列中相邻4个单元中存储的数据为“0111”,相对应的4根字线WL0-WL3被激活,其开启时间分别为8T0, 4T0, 2T0, T0。BLB电流根据单元内部存储的数据从M3, M2, M1流向存储“0”数据单元的M0。传统SRAM基本单元为左右对称互补结构,所以BL上电流正好与BLB相反,并且BL可以通过3个路径放电,会使位线电压快速降低。如果位线电压降得过低,会影响3个存储“1”的单元,使内部数据容易发生翻转,这样会导致存内计算中读取鲁棒性降低。最坏的情况会发生在放电为8T0时,此时位线放电量最大。
为了解决上述讨论的读破坏问题,Kang等人[60]则通过降低字线WL的开启电压来减缓位线的速度,并且调节每个T0的时间使其放电的线性度最优。如图13(b)所示,有研究者通过重构传统SRAM单元提出了7T, 8T, 9T, 10T等一系列读写分离结构[6,14,44,52],这样把读、写操作分开,被隔离的位线不会影响到内部节点,也就不会出现读破坏的现象。为了不影响存储密度,其他研究者选择将基本6T单元结构的存储阵列分割成较小的部分[30,31],如图13(c)所示,其将两部分被访问的小阵列模块连接到不同的局部位线,最终在全局位线连接的SA端输出运算结果,从而降低了读破坏的风险。
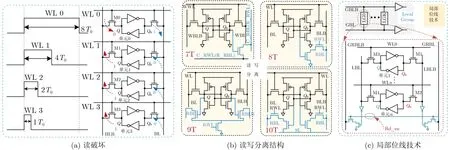
图13 多行读取的读破坏
6 展望
6.1 多模式下模块电路的建模
以应用为导向的存内计算系统是需要考虑存储器密度、计算精度、功耗等因素的。想要进行敏捷的CIM系统设计,研究者可以针对电路单元库的不同层次,研究多模式下电路的自动建模,快速获得各层次电路模块的参数以支撑芯片综合算法。
电路执行不同任务,在性能、功耗等方面显示出不同的需求,这使得最终的电路的设计和结构会有所不同。这一点在存内计算场景下将变得更加突出,因此,如图14所示,需要建立一个高能效的电路单元库,可以满足尽可能多的任务场景。已有的电路模块中,相同功能的不同电路模块往往具有不同的电路接口,这不利于在电路迭代时进行敏捷设计。因此为了实现CIM芯片的敏捷设计,可以应当构建具有相同接口的模块电路库。当硬件参数、需求改变时,通过迭代关键路径关键模块可以提升目标性能,以此缩短存内计算芯片迭代时间,提升电路设计的敏捷性。
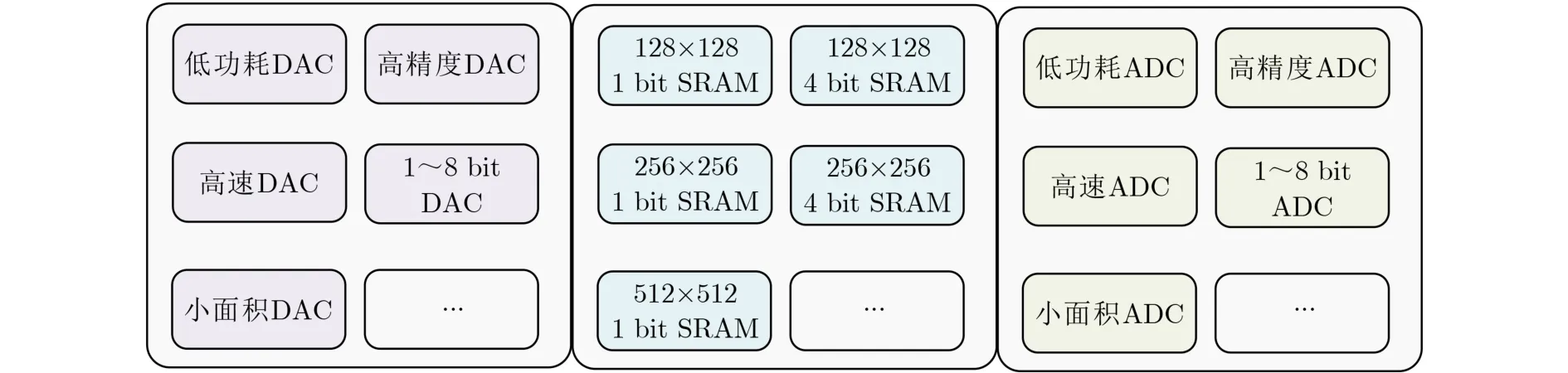
图14 电路单元库模型实例
6.2 面向多种AI算法的CIM资源规划与调度
CIM的最大优势在于减少数据的搬移,而不在于复杂计算。若某种算法其数据并不需要频繁搬移或者改变,同时运算却较为复杂,那么“存内”并不合适。因此,如图15所示,研究者应当首先分析SRAM特点、CIM的限制以及主流人工智能算法的需求。之后需要提炼算法共性基本算子、提炼算法位数、容量需求。根据所提炼的共性基本算子、各种需求,规划电路模块功能接口、规划精度位数可调范围、规划共享的层次数目、每个层次的计算资源共享模式。之后再设计计算资源调度策略,实现计算资源调度器。调度器需考虑SRAM的状态以及计算资源的状态,根据请求进行调度选择合适的计算资源,避免冲突。

图15 计算资源调度方式研究方案
6.3 面向CIM的异构多处理器系统关键技术
想要充分发挥CIM的优势,可以将其看成系统的一部分而不仅是一个割裂的辅助加速器。在CIM系统中,并不是所有的数据都适合在存内处理,部分数据在处理器中计算,部分数据在CIM中计算。程序在CIM中执行的部分必须与在处理器中继续执行的部分保持一致。但是由于一致性消息消耗了大量的片外通信,CIM体系结构无法使用传统的方法来实现缓存一致性,对于许多数据密集型应用程序来说,这可能会抵消CIM执行的好处。研究思路如图16所示,未来研究方向可能是在传统粒度一致性的基础上,通过准预测的思想,减少CIM提交来减少冲突发生回滚的开销。这样不仅避免了大量不必要的数据刷新所造成的功耗,还保障了数据的一致性。

图16 面向CIM的异构多处理器系统关键技术的研究思路
7 结论
存内计算技术作为“算力时代”中的前沿技术之一,其具有划时代意义。SRAM存内计算是克服传统冯·诺依曼架构中存在的“存储墙”问题的有效策略,可以高能效地实现AI算法,为未来的智慧生活奠定了基础。本文概述了SRAM存内计算的应用背景,并且讨论了现有SRAM架构所能实现的运算功能。用于复杂的应用时电路需具有要高精度的量化能力,为此我们还研究了SRAM存内计算架构中各种量化技术。并且探讨了SRAM存内计算技术中存在的一系列问题和面临的挑战。存内计算架构的竞争力体现在芯片的整体性能,而整体性能本质是各种问题之间的折中,基于存内计算架构的芯片在未来定会广泛地应用于各个领域。
