考虑财务报告中文本风险信息的财务困境预测
2022-11-28朱晓谦李建平
孙 灏 ,朱晓谦 ,李建平
(1.中国科学院 科技战略咨询研究院,北京 100190;2.中国科学院大学 公共政策与管理学院,北京 100049;3.中国科学院大学 经济与管理学院,北京 100190)
近年来,国内外上市公司的财务困境事件频发,给市场投资者带来巨大的损失,使得财务困境的准确预测受到市场投资者、监管机构等的高度关注。Habib等[1]从4个方面总结了现有研究对财务困境的定义,分别为业务经营失败、无法偿还到期债务、申请破产保护以及发生贷款违约。为了更有效地预测公司是否陷入财务困境,现有研究对各种类型的数据信息进行分析,包括公司财务信息[2]、股票市场信息[3]以及公司披露的文本类信息[4]等。
早期的财务困境预测研究大多基于公司的财务和市场数据等定量信息。Altman[2]从公司的财务报表中提取了5个财务比率指标建立了Z-score模型,证明了财务比率指标能为财务困境预测提供有效信息。Shumway[3]基于股权价值波动率、股权超额收益率等市场信息构建了风险模型,发现市场信息够提升财务困境的预测效果。这些定量信息在之后的财务困境预测研究中也得到普遍应用[5-8]。然而,这些定量信息主要是对公司财务状况的高度凝练和总结,只能刻画公司部分的经营情况。
近年来,相关研究开始关注社交媒体及公司披露的文本信息在财务困境预测中的作用[9]。与定量信息直观地反映公司的经营和财务状况相比,文本信息则是对公司的经营情况进一步具体的解释与分析,能够对定量信息提供有效的补充。陈艺云等[10]采用百度新闻中公司的新闻报道文本进行财务困境预测。Mayew 等[4]基于公司财务报告中的管理层讨论与分析 (Management Discussion and Analysis,MD&A)构建财务困境预测模型。吕喜梅等[11]分析了公司在出现重大事件时披露的临时报告在财务困境预测中的作用。上述研究都发现各类文本类信息可以提升财务困境的预测效果。然而,媒体报道、MD&A 及临时报告等文本信息主要是对公司当前业务经营信息、财务报告数据等的解释和分析,对公司未来可能面临情况的内容较少[12]。
根据各国监管机构的要求,上市公司通常需要根据当前的经营情况预判未来潜在的重要风险,并以文本的形式在财务报告中披露[13]。例如,美国上市公司被证券交易委员会(Securities and Exchange Commission,SEC)强制要求在年度财务报告中的Item 1A 章节增加Risk Factor部分,披露使公司面临风险的重要因素,以帮助投资者更清楚地了解公司的风险情况[14]。相比于社交媒体及公司披露的MD&A 等文本内容,财务报告中的文本风险信息能够更加直接和前瞻地刻画公司未来的风险[13]。此外,现有研究发现,该部分内容在整个财务报告中的篇幅占比越来越高[15],并能够真实和有效地反映公司未来面临的风险情况[14]。然而,鲜有研究分析该信息在财务困境预测中的作用。
本文引入公司在年度财务报告中以文本形式披露的风险信息进行财务困境预测,并构建了能够刻画所披露的风险对公司产生影响的可能性的文本特征指标——风险可能性。该指标通过公司披露风险时语气的强弱实现量化,并结合常用的文本特征指标对文本风险信息进行特征提取,包括文本长度、情感、可读性以及样板性[16-18]。本文选取了5种主流的机器学习方法,对文本特征指标的财务困境预测能力进行评估,包括逻辑回归(Logistic Regression,LR)、支持向量机(Support Vector Machine,SVM)、神经网络(Neural Network,NN)、随机森林(Random Forest,RF)及XGBoost模型。为了检验本文提出的风险可能性相比常用的文本特征指标,是否更适用于处理文本风险信息,进一步对比分析了各个文本特征指标在财务困境预测中的重要程度。此外,对财务困境预测的时间窗口进行变化,分析文本风险信息的预测能力随预测时长增加时的变动情况。
本文的创新和贡献主要体现在两个方面:①引入公司在年报中披露的文本风险信息进行财务困境预测,拓展了现有研究预测财务困境时所使用的数据类型。现有研究在财务困境预测中采用的文本数据类型主要包括MD&A[4]、企业临时报告[11]和社交媒体[10]等,主要是对公司当前财务信息、经营情况等方面的解释和分析[12]。相比之下,本文引入的公司在财务报告中披露的文本风险信息能够更加直接和前瞻地描述公司未来可能面临的风险[13]。②构建了适用于文本风险信息的特征指标——风险可能性,实现了对所披露风险对公司产生影响的可能性的刻画。现有研究在分析金融文本数据的特征时,主要从情感、可读性及样板性等维度进行考虑[16,19],然而,这些特征指标不适用于从文本风险信息中提取风险对公司产生影响情况的特征信息。本文提出的风险可能性指标,能够定量地刻画出公司受到所披露风险影响的可能性大小,从而帮助预测公司是否陷入财务困境。
1 文献综述
除结构化的定量信息外,以非结构化形式存在的文本类数据在各类数据中的比重不断上升,并在财务困境预测领域得到广泛应用[4,9,11,17]。根据信息的来源,这些文本可以划分为社交媒体信息和公司披露信息两种类别[19]。
现有研究常见的社交媒体类文本数据主要包括新闻报道、微博、Twitter和股票论坛等,这类社交媒体信息具有发布时间间隔短的优势,可以帮助投资者及时地了解公司的动态信息[20-21]。陈艺云等[10]通过爬虫技术从百度新闻中收集了公司的新闻报道文本内容,分析发现,公司的负面报道比例越高,出现财务困境的可能性就越大。Lu等[22]基于《华尔街日报》发布的新闻报道信息构建了公司信用违约预测模型,结果表明,在定量指标基础上预测效果得到显著提升。何贤杰等[20]基于中国上市公司在新浪微博上发布的信息,研究发现,公司治理水平越高的公司更倾向于开设微博账号,并发布公司的相关信息。Jung等[23]分析了公司在Twitter平台发布的季度收益公告文本信息,发现经营情况较差的公司会选择性地在Twitter上发布更少的信息。Zhao等[24]分析市场投资者在股票论坛中发布的评论文本信息,发现投资者对公司的财务及经营情况表现出更消极的态度时,公司出现财务困境的可能性越大。
公司披露的各类文本数据也受到了较为广泛的关注,主要包括公司财务报告中的MD&A 部分、财务报告的附注部分以及公司发生重要事件时披露的临时报告等。这类公司披露信息是以文本的形式对公司经营情况的说明和分析,可以作为公司定量财务信息的有效补充,帮助投资者更为全面地了解公司的经营情况[25]。Mayew 等[4]通过分析上市公司在年报中披露的MD&A 内容,发现财务困境公司的管理者在披露时倾向于使用更多的负面情感词汇。陈艺云[17]基于中国上市公司披露的MD&A文本,研究结果验证了MD&A 文本信息能有效帮助预测公司财务困境。Zhao等[24]基于财务报告附注、MD&A 等文本信息构建财务困境预测模型,发现在财务指标基础上融合文本信息能够显著提升预测效果。Gandhi等[26]对银行业公司在年度财务报告中披露的文本内容进行分析,发现负面情感词汇的数量越多时,公司发生财务困境的可能性越大。吕喜梅等[11]通过采用公司披露的临时报告文件信息,构建了中国新三板企业财务困境预测模型,发现提取的公司权益变动、资金管理等主题信息能够显著提升预测效果。
除了上述公司披露的文本数据类型,各国的监管机构通常还要求公司在财务报告中披露可能对公司未来发展战略和经营目标的实现产生不利影响的风险因素。例如,美国证券交易委员会于2005年颁布的公司信息披露法规中,美国上市公司应当在其年度报告Form 10-K 文件中的Item 1A 章节新增Risk Factor部分,详细、规范地披露公司未来可能面临的重要风险因素[27]。这类文本风险信息是公司的管理层基于公司实际的经营情况分析得出的风险信息,相比于公司披露的其他类型文本信息,能够更为直观地反映公司所面临的风险情况[12,28]。此外,监管机构对公司披露的文本风险信息内容的真实性及有效性进行了严格监督,且已有研究发现,文本风险信息对公司未来所面临的财务风险、法律诉讼风险等有一定的预见能力[14]。因此,文本风险信息的优势在于直接和前瞻地反映了公司的潜在风险,能够作为公司定量信息的有益补充。然而,现有研究很少关注这类文本风险信息在财务困境预测中的作用,故引入文本风险信息构建财务困境预测模型,分析其能否提升财务困境预测效果。
现有研究在分析金融文本的特征时大多从情感、可读性及样板性等维度进行考虑,有关结论也验证了这些文本特征的确能够从文本中挖掘得到有效信息[16,19]。姚加权等[29]针对中文金融文本分别构建了适用于年度财务报告和社交媒体的情感词典,并发现基于情感词典得到的情感特征指标能够有效预测公司股票收益率、成交量及波动率等市场因素。Loughran等[30]同样构建了适用于英文金融文本的情感词典,并发现该词典相比于一般性的词典能够更好地刻画金融文本中的情感特征。Li[31]对公司年度财务报告中披露的文本内容进行可读性分析,发现盈余收入越差的公司的财务报告可读性越差,这是因为公司为了降低股票市场波动而故意模糊信息[32]。样板性也称为文本相似性,在金融文本领域主要用于刻画不同公司之间披露文本的相似程度,以及同一公司在不同时期披露文本的相似程度[19]。
不同于一般类型的金融文本,本文引入的文本风险信息的主要内容是公司未来可能面临的潜在风险。该风险信息是各公司基于自身的经营情况,对未来潜在的重要风险的预判,因而不同公司之间所披露的风险存在一定程度的差异[13],且不同的风险对公司的经营情况产生的影响也不同[14]。本文通过分析各个公司所披露的风险信息对该公司产生的影响情况,从而帮助预测公司是否陷入财务困境。然而,现有研究常用的文本特征指标难以刻画出文本风险信息对公司产生的影响情况,因此,本文提出新的文本特征指标,该指标能够定量地刻画公司受到所披露风险影响的可能性大小,从而用于财务困境预测。
综上所述,现有研究对财务困境预测问题已经进行了较为丰富的研究,但是在采用的文本数据类型、文本特征的分析方法两个方面还存在一定不足。首先,现有研究在财务困境预测中采用的文本信息主要包括MD&A[4]、企业临时报告[11]和社交媒体[10]等类型,这些文本信息主要是对公司当前财务信息、经营情况等方面的解释和分析,对公司未来经营情况的前瞻性描述较少[12];其次,现有研究在分析金融文本数据特征时主要从情感[29]、可读性[31]及样板性[19]等维度进行考虑,由于这些文本特征指标主要用于分析常见的文本信息,不适用于特定类型的文本,故本文引入直接和前瞻地披露公司未来风险情况的文本风险信息,并针对该文本的特征提出了风险可能性指标,用于刻画公司受到所披露风险影响的可能性大小。
2 研究设计
2.1 公司财务报告中的文本风险信息
本文基于上市公司年度财务报告中披露的文本风险信息进行财务困境预测。考虑到美国上市公司在年报中披露的风险信息相比于其他国家更为详细和规范[13],本文选择美国上市公司披露的文本风险信息进行分析。美国证券交易委员会在2005年颁布的Regulation S-K 法规要求,上市公司应当在年度财务报告Form10-K中Item1A章节新增“Risk Factor”部分,详细披露公司认为对未来发展战略和经营目标可能产生不利影响的风险因素。在以HTML格式存储的Form 10-K 报告中,各章节通过不同的HTML标签进行标记,因此,可以采用正则表达式匹配识别Item 1A 章节,从而提取出“Risk Factor”这一章节的文本风险信息。
公司通常以一个标题加一段详细解释的方式来披露每一个风险因素,标题基本可以清晰地概括各个风险因素,平均每份财务报告大约包含21 个标题[33]。每个标题通常讨论一类风险因素,Bao等[33]通过构建无监督的主题模型方法,从2006~2010年间所有美国上市公司披露的文本风险信息中,识别出所有行业中公司面临的25种风险因素,包括“人力资源”“股价波动”“竞争”“信用风险”和“国际风险”等。表1为4个风险标题的示例,通过这些标题分别总结出“产品服务”“税收波动”“信息系统安全”及“法律监管”4个风险因素可能影响公司未来的经营和收益。因此,美国上市公司在年度财务报告中披露的文本风险信息能够清晰地刻画出公司经营过程中面临的风险情况,可以作为财务困境预测的有效补充信息。

表1 美国上市公司年度财务报告Form 10-K 中披露的风险信息示例
2.2 文本风险信息特征指标
2.2.1风险可能性指标 相比于以往研究常用的金融类文本数据,财务报告中的文本风险信息披露的主要是公司未来可能面临的风险因素。通过对公司在年报中披露的大量文本风险信息的分析发现,公司在披露风险信息时语气的强弱存在差异,表现为使用情态动词的不同。如表1所示,公司在披露“产品服务”风险因素时使用的情态动词为must,语气较强,表示该风险对公司产生影响的可能性较高;在披露“税收波动”“信息系统安全”及“法律监管”3个风险因素时,使用的情态动词分别为could、may及could,语气较弱,表示这3个风险对公司产生影响的可能性较低。由上述分析可以看出,公司披露风险信息时的语气强弱能够反映出该公司受到风险影响的可能性的差异。因此,本文在利用文本风险信息进行财务困境预测时,从语气强弱的角度分析公司披露的风险对公司产生影响的可能性。然而,文本长度、情感分析、可读性分析等常用的金融类文本特征分析方法,难以反映文本中的语气强弱并刻画出公司披露的风险对公司的影响情况。
为了刻画一个公司受到未来可能面临的风险影响的可能性大小,本文提出了风险可能性指标,通过分析公司披露文本风险信息时的语气强弱实现量化。由于情态动词的语气强弱能够反映表达者对其描述内容的信息程度高低[30],故通过分析文本风险信息中情态动词的语气强弱以构建风险可能性指标。首先从公司披露的各个风险因素的标题及详细解释中识别出情态动词,然后对情态动词的强弱程度进行区分以分析每个风险因素的语气强弱,最后对各个风险因素的语气强弱进行综合,从而得到能够反映公司披露的文本风险信息整体语气强弱的“风险可能性”指标。与以往研究常用的金融文本分析方法相比,该指标的优势在于可以更为直观地刻画出公司披露的风险信息对公司产生影响的可能性。
假设一个公司在其年度财务报告Form 10-K的Risk Factor部分共披露了N个风险因素,表示为(r1,r2,…,rN)。为了分析各个风险因素中情态动词的语气强弱,引入Loughran等[30]研究得出的情态动词语气强弱词典。如表2 所示,Loughran等[30]根据语气强弱将情态动词划分为两类,包括18个强语气情态动词及27个弱语气情态动词。基于该词典,从第i个风险因素ri的标题及详细解释中识别出现的所有情态动词,并根据语气强弱进行划分,从而得到强语气及弱语气情态动词的数量,分别记为重复该步骤,可得N个风险因素(r1,r2,…,rN)中强语气及弱语气情态动词的数量,分别记为为了综合评估N个风险因素的语气强弱的整体情况,进一步分析了N个风险因素中强语气情态动词在所有情态动词中的数量比重的均值,从而得到N个风险因素对公司产生影响的可能性的综合情况,即风险可能性指标,如下式所示:

表2 Loughran和McDonald的情态动词语气强弱词典
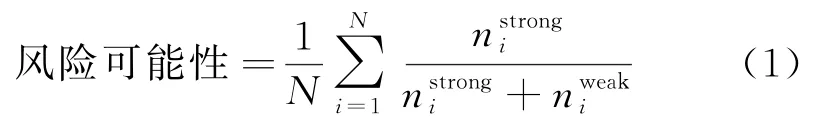
该指标的数值大小区间为[0,1],数值越大,表示公司披露的风险对公司产生影响的可能性越大。综上可知,本文提出的风险可能性指标能够刻画出财务报告中披露的文本风险信息对公司产生影响的可能性的综合情况,从而有利于公司的财务困境预测。
2.2.2常用文本特征指标 在分析金融类的文本时,现有研究通常利用情感、可读性、长度及样板性等特征指标从文本中提取有效信息[4,18,16],因此,除了采用本文构建的风险可能性指标,也利用这些文本特征指标对公司在年度财务报告中披露的文本风险信息进行分析和效果对比。
文本长度指标是现有研究中较为常用的刻画文本特征的指标,主要通过文本中词语的数量的Log值进行刻画[14],如下式所示:

文本情感指标的常用刻画方法为词袋法[17],主要基于Loughran等[30]针对金融文本构建的情感词典。利用该词典可以对文本中正面和负面情感词语进行识别并统计,分别得到正面及负面情感词语的数量,从而构建了情感指标,如下式所示:

文本的可读性主要用于刻画文本内容被读者理解的难易程度,通常采用雾指数实现量化[16]。雾指数表示读者在第一遍阅读一篇文章时,需要多少年的教育水平才能读懂。例如一篇文章的雾指数为5,表示读者在第一遍读该文章时需要5年的教育才能读懂。该指标主要通过句子理解难度(句子中包含词语数量越多则越难)和词语难度(词语音节越多则越难)两个方面实现度量[32],如下式所示:

文本的样板性刻画了特定文本内容和其他文本内容之间的相似程度,可用于分析不同公司之间披露的文本内容的相似程度[19]。Dyer等[18]将样板性定义为公司披露的文本中存在样板性的句子的词语数量占全文词语数量的比重,如下式所示。其中,句子存在样板性通过该句子和同会计年度中其他公司(至少75%)披露的文本是否有相同的短语(词语数量至少为4)刻画,

2.3 财务困境预测模型及评价方法
基于文本风险信息的特征指标,本文选用了5种主流的机器学习方法进行财务困境预测,包括逻辑回归、支持向量机、神经网络、随机森林以及XGBoost[4,9,26]。逻辑回归在线性回归的基础上增加了Sigmoid函数进行非线性映射,以处理分类问题,并通过L1正则化防止过拟合[11]。支持向量机通过在特征空间中寻找最优超平面,以最大化数据样本中支持向量与超平面之间的间隔距离,并利用非线性核函数处理数据的线性不可分问题[34]。标准神经网络构建以神经元和激活函数为基础的多层神经网络,并通过后向传播方法进行参数优化以训练模型[35]。随机森林和XGBoost是基于多个决策树方法的集成模型,并分别通过Bagging等[36]策略方法进行集成学习。
本文选用了4个常用的评估指标对模型的预测效果进行度量[11,36-37],包括总准确率、一型、二型准确率和AUC(Area under the Receiver Operating Characteristic),分别表示模型将所有样本、财务困境样本和非财务困境样本正确分类的百分比。具体定义如下所示:
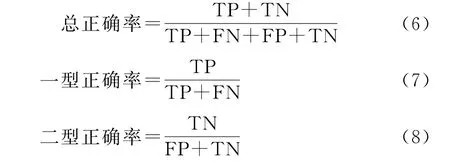
式中:TP(True Positive)为财务困境样本被正确预测为财务困境的数量;FN (False Negative)为财务困境样本被错误预测为非财务困境的数量;TN(True Negative)为非财务困境样本被正确预测为非财务困境的数量;FP(False Positive)为非财务困境公司被错误预测为财务困境的数量。AUC指标刻画了模型对财务困境样本及非财务困境样本的综合预测能力,通过ROC(Receiver Operating Characteristic)曲线下面积计算得到,其取值范围在0 和1 之间,AUC越接近1,模型的预测效果越好。
3 实证研究
本节采用美国上市公司在年度财务报告中披露的文本风险信息进行实证研究,检验在定量指标基础上融入文本风险信息能否提升财务困境的预测效果,并分析了本研究提出的风险可能性指标相比于常用文本特征指标的重要度。
3.1 实证数据
实证研究基于美国上市公司在年度财务报告Form 10-K 中的“Risk Factor”部分披露的文本风险信息数据。由于美国证券交易委员会从2005年开始要求美国上市公司在财务报告中披露 “Risk Factor”部分,美国的上市公司在2006的年度财务报告中开始披露文本风险信息,故样本数据的时间区间确定为2006~2020年。从美国证券交易委员会的EDGAR 数据库中收集公司的Form-10K 报表,并对“Risk Factor”部分的文本风险信息数据进行提取和清洗,共得到8 071 家美国上市公司的81 167个年度文本风险信息数据。
为了分析引入文本风险信息后对公司财务困境预测的提升效果,综合参考Altman[2]、陈艺云[17]及Mayew 等[4]研究中使用的定量指标,共选取了8个常用的财务和市场指标作为比较基准,包括营运资本/总资产、留存收益/总资产、息税前利润/总资产、权益市值/债务面值、销售收入/总资产、波动率、超额收益率和相对规模。剔除存在缺失值的公司样本,得到35 058个年度样本。
参考以往研究定义财务困境的方式[26],根据公司的退市代码,将证券交易所强制退市(退市代码在300~599之间)的公司作为财务困境样本[26],其他公司作为非财务困境样本。最终得到648个财务困境公司样本,34 410个非财务困境样本。公司的退市代码和定量指标都来自沃顿商学院数据库(Wharton Research Data Services,WRDS)。
基于2.2节中的方法度量公司财务报告中文本风险信息的文本特征,包括本文提出的风险可能性指标以及常见的情感、可读性、长度和样板性指标。表3所示为财务困境公司和非财务困境公司样本的5 种文本特征指标的均值、中位数和标准差。为了验证各文本特征指标在两类公司样本之间是否存在显著差异,采用独立样本T检验分别对各文本特征指标进行显著性检验,并根据检验结果T值的正负号分析文本特征指标和公司财务困境之间的关系。

表3 文本特征指标的统计检验结果
由表3可见,各文本特征指标的T检验结果都显著,表明5个文本特征指标在财务困境及非财务困境样本之间的均值存在显著差异。本文提出的风险可能性指标的T检验结果显著为正,表明公司披露的文本风险信息的风险可能性指标越高,更可能发生财务困境。初步验证了公司在披露文本风险信息时使用更高比重的强语气情态动词,即认为风险对公司产生影响的可能性更大时,出现财务困境可能性更大。
由常用的文本特征指标可以发现,长度和情感指标的T检验结果显著为正,表明公司在披露的文本风险信息中内容越多或情感越积极时,发生财务困境的可能性越高;而可读性及样板性指标的T检验结果显著为负,表明公司披露的文本风险信息更难以被读者理解,或与其他公司披露的文本风险信息的相似程度越低时,发生财务困境的可能性越高。与以往研究基于MD&A 文本验证的情感越消极的公司更可能出现财务困境的结果相比[4,17],本文发现,情感越积极的公司反而更可能发生财务困境,分析造成此差异的主要原因是,文本风险信息与MD&A 文本所披露的内容在情感特征方面存在不同[27]。
3.2 基于文本风险信息的财务困境预测
为了验证本文引入文本风险信息对公司财务困境预测的提升效果,将现有研究[2,4,17]中常用的定量指标(包括财务指标和市场指标,具体见3.1节)作为财务困境预测效果的比较基准。如2.3节所示,采用常见的逻辑回归、支持向量机、标准神经网络、随机森林和XGBoost[4,9]5种模型,进行财务困境预测。
由于上市公司的年度财务报告通常在会计年度结束后的4个月内编制完成,可能导致公司t年陷入财务困境时t-1年的财务报告还未公布,故参考陈艺云[17]的方法,基于公司t-2年的数据建立模型预测其是否在t年陷入财务困境。在模型构建过程中,逻辑回归的正则化参数为5,支持向量机的核函数为高斯核函数、正则化参数为5,标准神经网络共4层、隐藏层维度为10,随机森林及XGBoost中基决策树数量为100。模型的训练采用现有研究中常用的训练集80%、测试集20%样本数据划分方式[9]得到28 046个训练样本及7 012个测试样本。考虑各模型需要调整超参数以最优化模型性能,从训练集中划分出20%的样本作为验证集,并采用网格搜索方法对各模型的超参数进行寻优。由于财务困境预测问题中财务困境样本的数量通常显著少于非财务困境样本,具有样本不均衡的特点,故采用代价敏感学习方法[38],对不同类别样本的分类错误赋以不同的惩罚权重,提高模型对财务困境类样本的重视程度,并通过网格搜索方法确定最优的惩罚权重。采用5折交叉验证将各模型重复训练5次,在测试集上得到的准确率的平均值作为最终的预测结果。
表4所示为基于定量指标以及引入文本风险信息特征指标后的财务困境预测结果。基于常见的定量指标的财务困境预测结果中,XGBoost模型的AUC 值最高,为88.63%,对应的总准确率为81.49%,一型准确率为81.46%,二型准确率为81.50%。Mai等[9]基于美国上市公司定量指标的AUC值为80.70%,吕喜梅等[11]基于中国上市公司定量指标的AUC值为85.80%。对比发现,本文基于定量指标的AUC值较高,验证了定量指标选取的合理性。

表4 引入文本指标的财务困境预测结果对比 %
在定量指标的基础上引入文本风险信息的5个文本特征指标,对公司财务困境的预测结果显示,各模型的预测效果都得到明显提升,仍然是XGBoost模型的AUC 值最高,达到91.84%,对应的总准确率为84.22%,一型准确率为84.15%,二型准确率为84.22%,在仅使用定量指标的基础上分别提升了3.21%、2.73%、2.69%和3.22%。由实证结果可见,公司在年度财务报告中披露的文本风险信息可以作为常用的定量指标的有效补充,采用风险可能性、长度、情感、可读性及样板性文本特征指标能够从文本中提取有效信息,并提高定量指标对财务困境的预测能力。
3.3 文本特征指标的重要度分析
为了检验相比于常用的文本特征指标,本文构建的风险可能性指标是否更适用于分析文本风险信息,本节对各个文本特征指标在预测财务困境时的重要度进行分析。在本文选用的5种机器学习模型中,随机森林和XGBoost是基于决策树的集成模型,不仅能够预测公司是否陷入财务困境,而且能够评估预测时各个特征指标的重要性[39]。现有研究通常通过基尼重要度指标来度量此类集成模型中特征指标的重要性[39]。具体而言,在集成模型中的决策树构建过程中,需要根据特征变量对目标变量的区分能力强弱选择强特征作为树节点,区分能力的强弱则通过加入特征变量前后基尼系数的变化程度来刻画,即基尼重要指数。当特征指标的基尼重要指数越大,则表示该特征的重要度越大,在模型预测过程中所提供的信息量越多。因此,本文通过度量随机森林和XGBoost模型中特征变量的基尼重要度,分析各类文本特征指标在财务困境预测中的重要度。
图1 所示为本文构建的风险可能性指标以及4种金融文本中常用的情感、可读性、样板性、长度和样板性指标的基尼重要度大小及其排序结果。由图1可见,无论在随机森林还是XGBoost模型中,风险可能性指标的基尼重要度都显著高于4种常用的文本特征指标。该结果表明,对于公司在年度财务报告中披露的文本风险信息,本文根据该文本特点构建的风险可能性指标更适用于提取该文本中包含的重要信息。在实际中,利用公司披露的文本风险信息评估财务困境时,应当充分关注公司在描述文本内容时的语气强弱。当文本中情态动词的语气越强,说明披露的风险对公司产生影响的可能性越大,该公司陷入财务困境的概率越大。
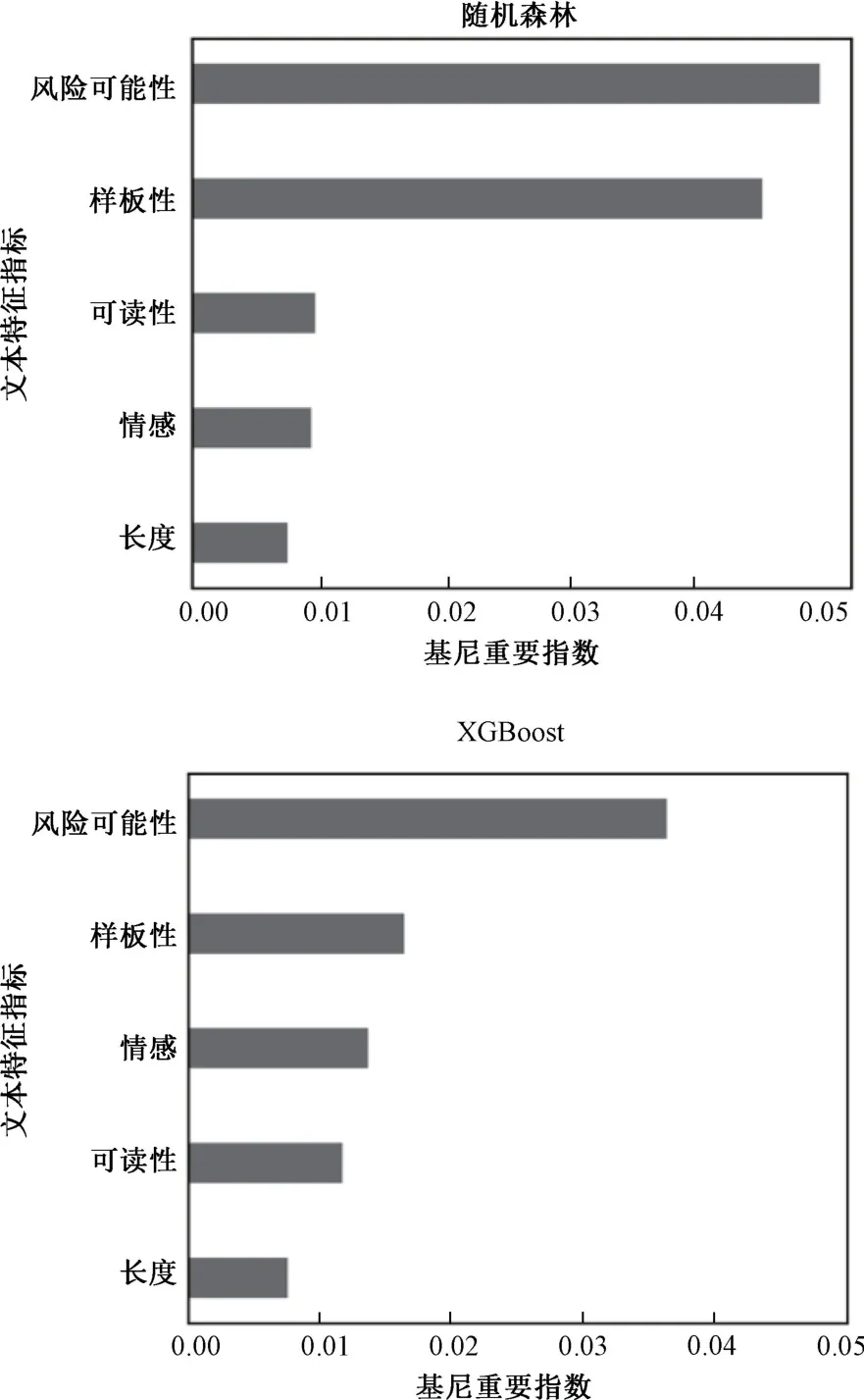
图1 文本特征指标的基尼重要指数大小排序
3.4 财务困境预测的时间窗口变化分析
对公司财务困境的预警越早,越有利于市场投资者及时避免财务困境造成的风险损失。因此,本节通过分析随着财务困境预测的时间窗口的提前,模型效果的变化情况,探究公司在年报中披露的文本风险信息能否提供更早的财务困境预警信号。在3.2节使用公司t-2年的信息预测t年是否陷入财务困境的基础上,分别使用公司t-3、t-4年的信息预测t年是否陷入财务困境。为了确保不同预测时长下结果的可对比性,各模型的构建及训练过程与3.2节保持一致。
图2所示为不同预测时长下,仅使用定量指标及引入刻画财务报告中文本风险信息的文本特征指标后,运用各类模型进行财务困境预测得到的AUC值。由图2各子图中实线(左边坐标轴)可见,随着预测时长从提前2年增加至提前4年,无论是仅使用定量指标,还是引入文本特征指标后,各类模型预测效果的AUC 值都有所降低。此结果与Mayew等[4]和Mai等[9]基于MD&A 文本进行不同时长的财务困境预测的研究结论一致,在预测公司未来更远的财务困境时,仅使用定量指标或引入文本信息后所能提供的有效信息量会减少。值得注意的是,在定量指标基础上引入文本特征指标后,各类机器学习方法的预测效果AUC值的下降趋势更为缓慢。
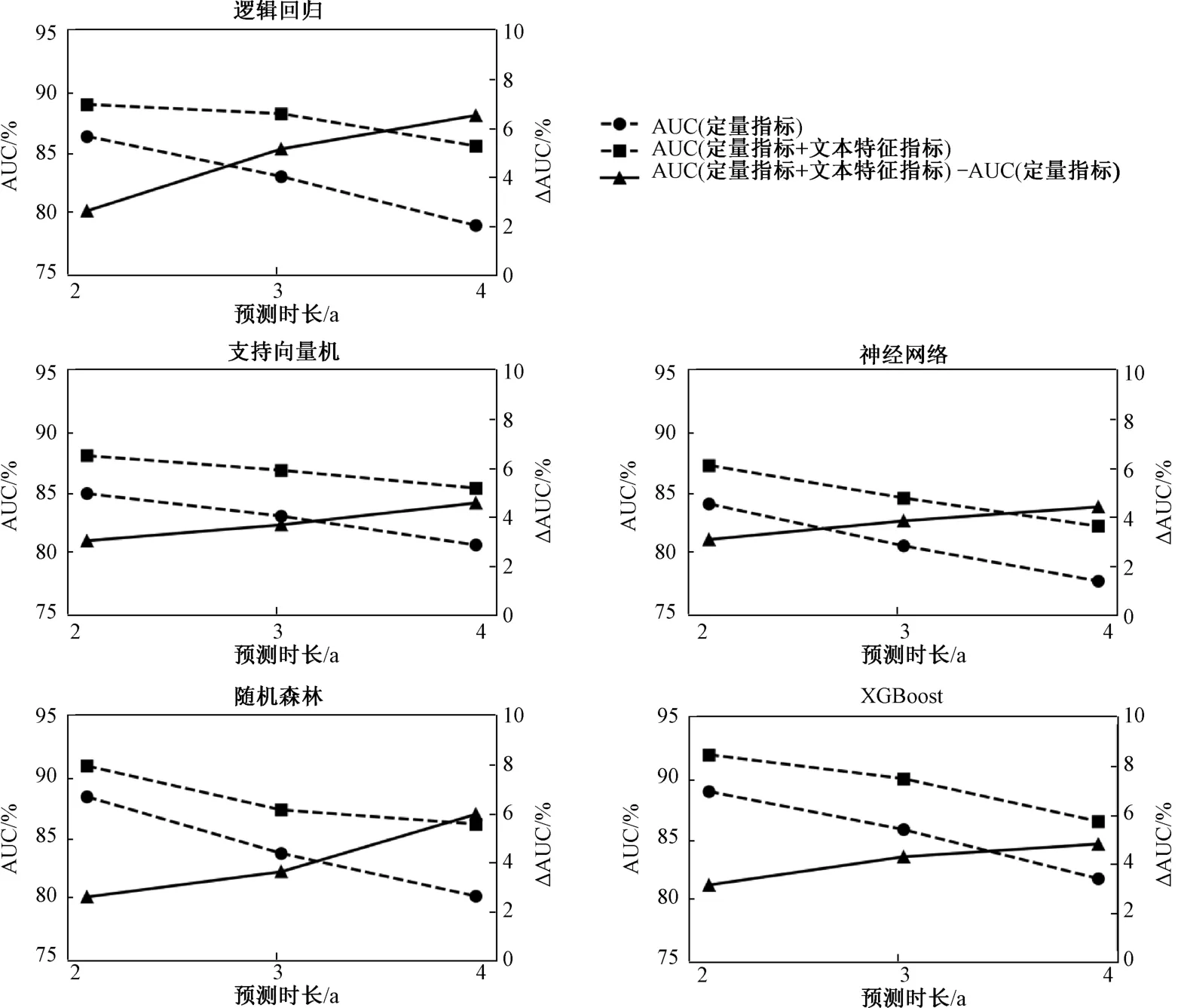
图2 不同预测时长下各类模型的财务困境预测效果
进一步分别计算在2年、3年及4年的预测时长下,引入文本特征指标前后AUC 值的变化。由图2各子图中虚线(右边坐标轴)可见,在5类机器学习方法下,随着预测时长的增加,从文本风险信息中提取的文本特征对预测效果AUC 值的提升值变得更大。该结果表明,定量指标的预测能力随时间窗口的提前逐渐下降;与此相反,本文引入的公司在财务报告中披露的文本风险信息的预测能力并没有下降,反而随着预测时间的提前能够提供更多的信息。本文分析主要原因是,相比于刻画公司当前经营情况的财务及市场定量指标,财务报告中的文本风险信息更为前瞻地披露了公司未来可能面临的风险情况[27],从而能够提供更早的预警信息。因此,运用财务报告中披露的文本风险信息来辅助财务困境预测是必要且有效的。
3.5 稳健性检验
在3.2节中是采用训练集80%、测试集20%的方式随机划分的数据集,除此之外,按年份时间节点划分数据集也是一类常用的方式[17,28]。为了检验3.2节的结论是否受到数据集划分方式的影响,将2006~2015年、2016~2020年间的公司样本分别作为训练集和测试集,重复3.2节中模型的训练及测试得到财务困境预测结果。由表5可见,在定量指标的基础上,引入公司在财务报告中披露的文本风险信息后,各类模型的效果依然有显著的提升,XGBoost模型的AUC 值最高,为88.87%,共提升了3.55%。此结果表明,在不同的数据集划分方式下,在定量指标基础上融入文本风险信息依然能够显著提升财务困境的预测效果,验证了3.2节结论的稳健性。
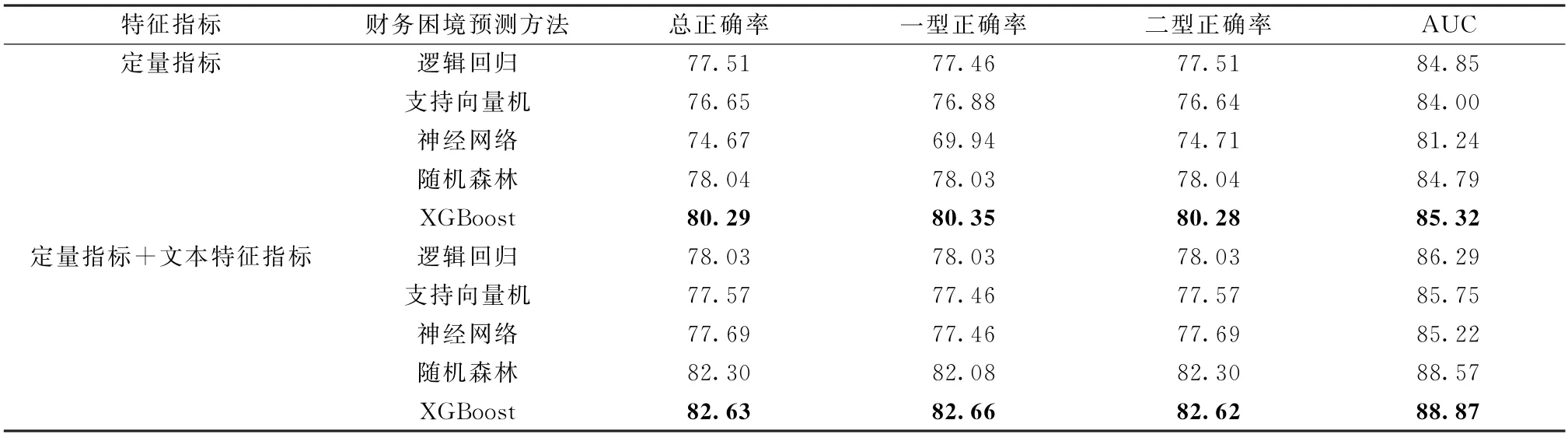
表5 按时间划分样本数据集的结果 %
财务困境预测问题一般存在着显著的样本不均衡问题,由于财务困境样本的数量通常显著小于非财务困境样本,模型会倾向于将未知公司样本预测为非财务困境类,从而导致模型难以正确预测财务困境样本。在3.2 节中,采用了代价敏感学习方法[38]增加了损失函数中财务困境类样本的权重,以处理样本不均衡问题。除此之外,在数据预处理阶段,对训练样本进行重新采样也是一类常见的样本不均衡处理方法[40],如过采样方法生成额外的少数类样本,或下采样方法去除部分多数类样本,从而使训练样本中的各类样本达到均衡。为了检验3.2节的结论是否会受到样本不均衡处理方法的影响,分别引入常用的SMOTE(Synthetic Minority Oversampling Technique)过采样方法及随机下采样方法[40],对原始样本进行处理,采样结果如表6所示。
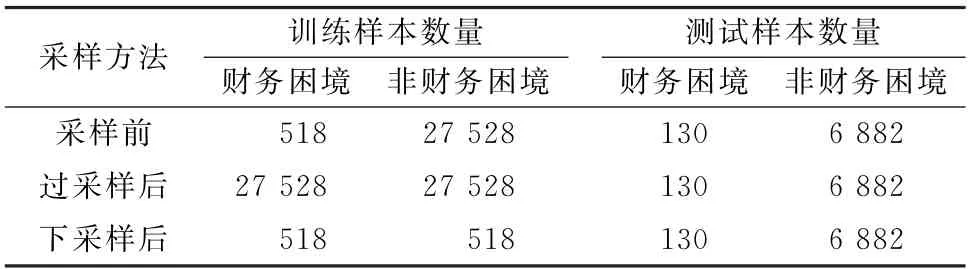
表6 不均衡财务困境样本重新采样后的样本分布
基于两类重新采样后的样本得出的财务困境预测结果如图3 所示。与3.2 节中的结论一致,不论采用过采样还是下采样方法,在定量指标的基础上引入文本风险信息后,各类模型的预测效果AUC值都有显著提升,证明了研究结论的有效性和稳健型。
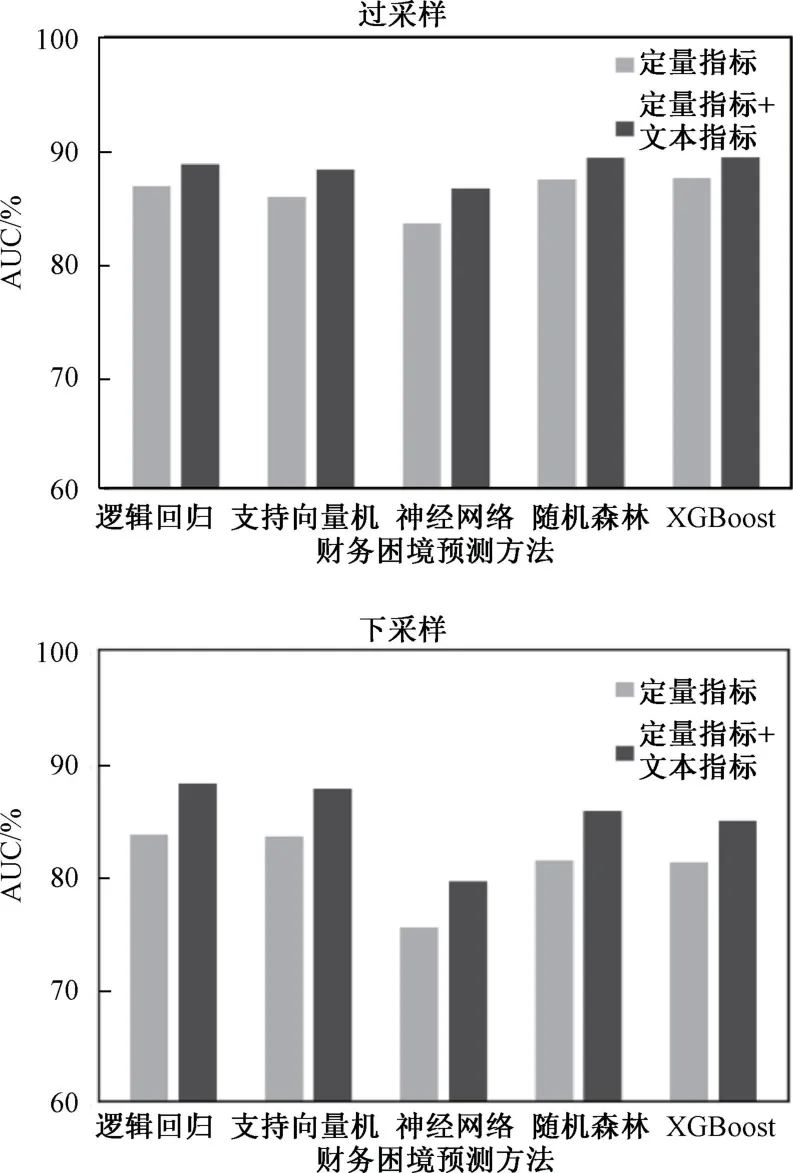
图3 基于过采样和下采样样本不均衡处理方法的预测效果
4 结论
本文引入公司在财务报告中以文本形式披露的风险信息进行财务困境预测,并构建了能刻画所披露风险对公司产生影响的可能性大小的文本特征指标,与其他常用文本特征指标作为机器学习方法的预测变量,以进行财务困境的预测。基于2006~2020年美国35 706个上市公司年度样本进行实证研究,主要结论包括:
(1) 在常用的财务及市场各类定量指标的基础上,引入公司披露的文本风险信息可以显著提升财务困境预测的准确率。
(2) 与情感、可读性、样板性等常见的文本特征指标相比,本文构建的风险可能性指标更适用于分析财务报告中的风险信息,且该指标越大,即公司受所披露风险影响的可能性越大时,公司越有可能出现财务困境。
(3) 随着财务困境预测时间窗口的提前,引入的文本风险信息能够更为显著地提升预测效果,即文本风险信息能够为财务困境提供较早的预警信息。
研究结果可以为市场参与者、监管机构在分析公司的财务困境风险时提供新的数据视角,除了分析公司的财务、市场等各类定量数据,还应当重点关注公司在财务报告中以文本形式披露的信息。未来研究可以考虑来自监管机构的问询函、公司披露的关联交易公告等多种类型的文本信息,从更多的角度分析公司的经营和财务状况,以帮助预测公司是否会陷入财务困境。
