基于改进YOLOv5的纸病检测方法
2022-11-24张开生关凯凯
张开生 关凯凯
(陕西科技大学电气与控制工程学院,陕西西安,710021)
在造纸过程中,受造纸工艺流程、纤维原料、人工操作、设备状态等因素的影响,纸张会出现褶皱、孔洞、划痕等表面缺陷问题,这些缺陷不仅影响纸张外观,还会降低印刷的成品率和经济效益。因此,纸张缺陷检测是造纸过程尤为重要的一环。
传统的纸张缺陷检测是依靠人工完成,存在检测效率低下、漏检率高、人力成本昂贵等问题。随着计算机技术的不断提高,人工检测已经逐渐被基于机器视觉的检测方法所替代[1]。张学兰等人[2]利用纸张图像的形态特征、灰度级统计、纹理特征、形态学、模糊逻辑及神经网络对纸病图像进行分割和识别,但是由于该算法过于复杂,所以实时检测速度难以满足造纸工厂对于纸病检测的要求。高乐乐等人[3]利用卷积神经网络(Convolutional Neural Network,CNN)自动提取纸病图像的深层次特征,解决了纸病特征难确定的问题,最后结合Softmax实现对纸病的辨识。曲蕴慧等人[4]使用Gabor及Gaussian滤波器去除纸张纹理干扰,然后使用Laplasian算法进行边缘检测,最后使用形态学闭运算得到纸病边缘图像,提高了纸病检测算法的抗干扰性。亢洁等人[5]利用鲁棒主成分分析法,将纸病图像对应的矩阵分解为稀疏矩阵和低秩矩阵,进而在检测过程中只需选择稀疏矩阵对应的图像进行检测,提高了检测效率。王思琦等人[6]通过主成分分析(PCA)纸病特征提取算法来构建纸病的特征空间,降低了纸病原特征的维数,改善了对相似纸病的检测精度。赵晓等人[7]利用纸病区域为简单连通图像的特点,对纸病区域进行连通区域标记和形状特征值提取,提高了纸病检测的准确率和效率。针对传统纸病识别方法大多采用分类算法,且特征提取困难、对光源依赖较高和实时性差等问题,本课题提出一种基于改进YOLOv5的纸病检测方法,通过在批量归一化模块(Batch Normalization,BN)的首尾部分添加居中和缩放校准以增强纸张缺陷的有效特征,并在骨干网络中引入坐标注意力机制(Coordinate Attention,CA)提升模型的特征提取能力,最后选用CIoU_loss作为边框回归的损失函数,以实现更高精度的定位。
1 YOLOv5网络模型
YOLOv5为单阶段目标检测网络,在学习了以前版本及其他网络的优点后,对之前YOLO系列[8-11]目标检测算法检测速度快但准确率不高的问题进行了改善,既能满足实时图像检测的需要,又具有较小的结构。因此,本课题使用YOLOv5作为检测模型,其网络模型如图1所示,分为输入端、骨干网络、颈部网络和输出端4个部分。
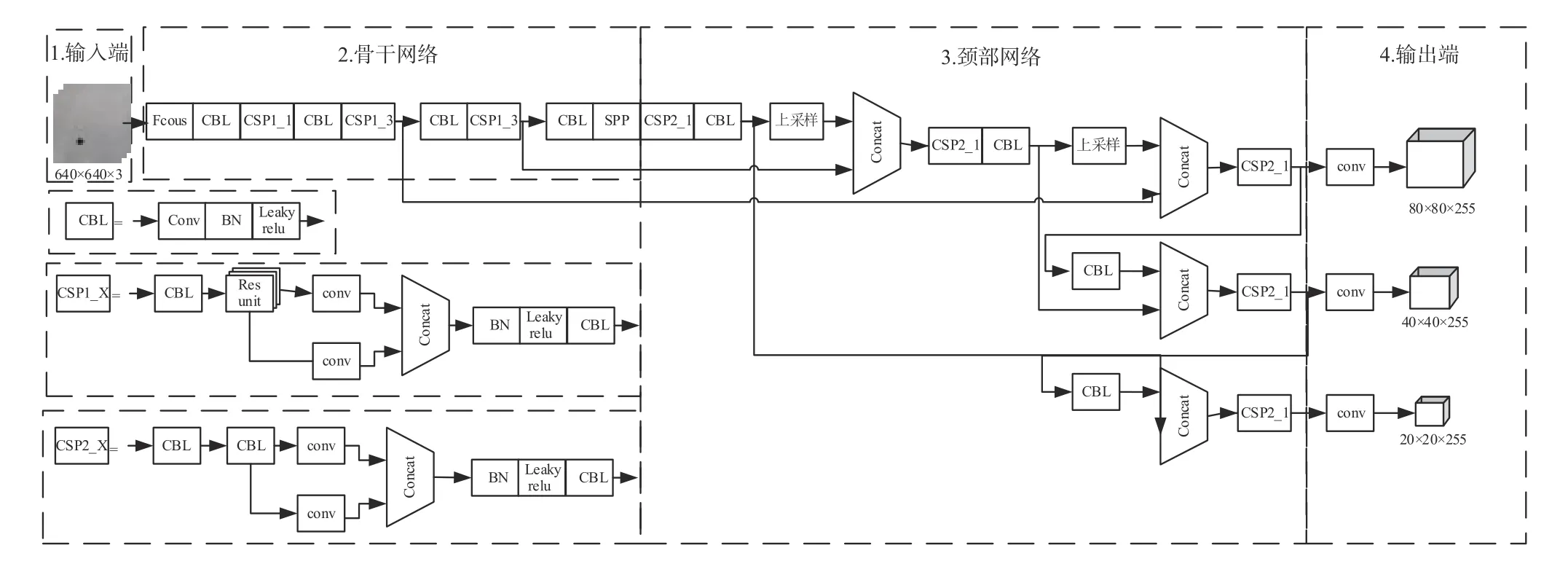
图1 YOLOv5网络模型Fig.1 YOLOv5 network model
1.1 输入端
YOLOv5的输入端采用Mosaic数据增强、自适应锚框计算和图片尺寸处理等方式。Mosaic数据增强是对4张图片按照随机缩放、随机裁剪、随机排布的方式进行拼接,丰富了数据集样本,使网络具有更好的鲁棒性。YOLOv5的初始锚框参数为[116,90,156,198,373,326][30,61,62,45,59119][10,13,16,30,33,23],自适应锚框计算是在初始锚框的基础上,将输出预测框与真实框做差值,再通过不断地迭代,获取最佳的锚框值。图片尺寸处理采用自适应缩放图片将图片缩放到统一尺寸。
1.2 骨干网络
YOLOv5的骨干网络即特征提取网络,主要包括切片结构(Focus)、卷积模块(CBL)、瓶颈层(CSP)以及SPP[12]4种模块。Focus模块流程如图2所示,640×640×3的图像经过切片得到320×320×12的特征图,再经过包含36个卷积核的卷积操作得到了320×320×36的特征图。一个基本的CBL模块由Conv2d+Batch Normalization+Leaky relu共同组成。CSP[13]的残差结构能优化梯度信息,可以减少网络优化过程中的梯度信息重复,加快推理的速度。SPP模块采用3个多尺度的最大池化进行多尺度融合,提高了模型的感受野,同时解决了锚框与特征层的对齐问题。
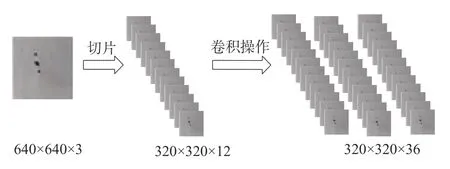
图2 Fcous模块流程图Fig.2 Focus module flow chart
1.3 颈部网络
YOLOv5继承了YOLOv4的优点,在颈部网络采用FPN[14]+PAN[15]结构,区别于YOLOv4的普通卷积操作,YOLOv5采用的CSP结构,进一步提高了网络特征融合的能力。
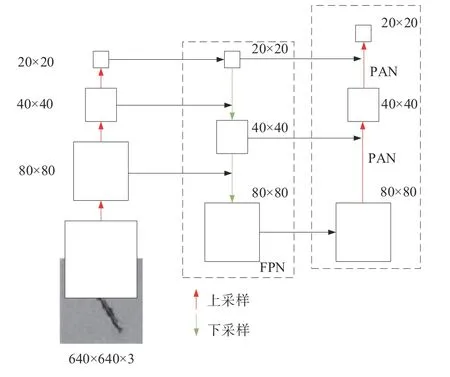
图3 颈部网络结构Fig.3 Neck network structure
1.4 输出端
输出端以GIoU_loss作为目标边界框回归的损失函数,采用非极大值抑制(Non Maximum Suppression,NMS)提高对多目标框重叠现象的检测能力,并输出1个包含预测图像中的缺陷位置和分类信息向量。
2 改进的YOLOv5算法
2.1 改进BN
BN已经成为神经网络训练过程的常见组件,在BN中,居中和缩放操作及均值和方差统计用于批量维度上的特征归一化,使神经网络有着更稳定的训练过程和更优秀的性能。然而BN不可避免地忽略了不同实例之间的差异,为了在BN中进行特征校正[16],本课题分别在BN的原始归一化层的开头和结尾添加居中和缩放校准。给定输入特征X∈RN×C×H×W,式中N、C、H、W分别表示批次大小、输入特征的通道数、高度、宽度,特征的居中校准如式(1)所示。
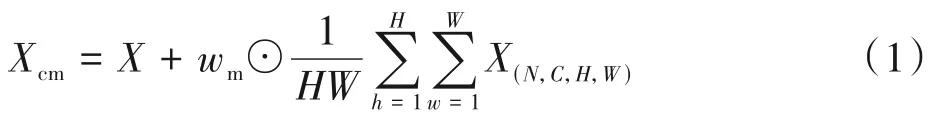
式中,wm∈R1×C×1×1是可学习的权重向量,其值随网络层数的变化如图4(a)所示。大多层的值接近于零,但是随着网络层数的不断叠加,其绝对值也不断增加,网络有了更多特定于实例的功能。Xcm表示特征的居中校准,⊙表示对特征的点乘操作,经过居中校准的居中特征如式(2)所示。

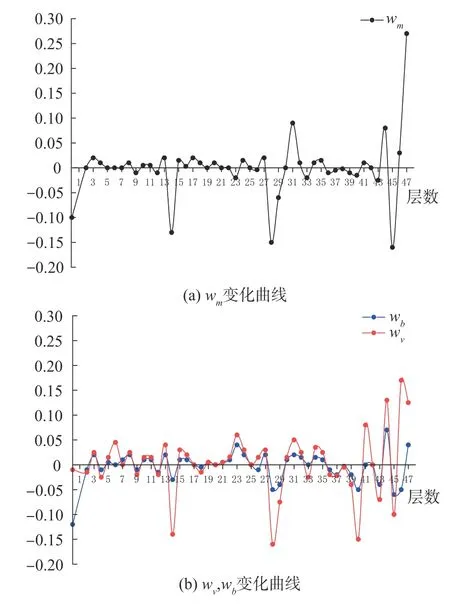
图4 可学习权重变量的折线图Fig.4 Line chart of learnable weight variables
式中,E(Xcm)表示Xcm的平均值,通过像BN一样缩放Xm,能够推得式(3)。

式中,Var(Xcm)为Xcm的方差,ε用来避免出现零方差,再通过缩放校准操作到原来的缩放操作,可得式(4)。
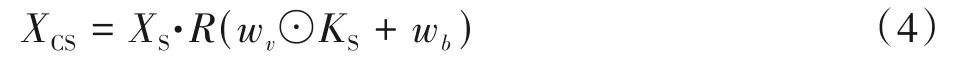
其中wv,wb∈R1×C×1×1是可学习的权重向量,随网络层数的变化如图4(b)所示。本课题选用Tanh函数作为R()的限制函数来抑制极值。Ks表示实例特征XS的统计量,能够设置为多个值。式(4)中的限制函数R()与wv、wb能够抑制分布外的特征使整个分布更加稳定。最终,训练的可学习比例因子γ和偏差因子β进行线性变换以获得最终具有代表性的批量归一化结果Y,如式(5)所示。

为了形成更稳定的纸病有效特征分布,本课题在BN的原始归一化层的开头和结尾添加居中和缩放校准。优化结果如图5所示,经过居中和缩放校准的中间特征图比未校准之前的中间特征图形成的特征分布更稳定。

图5 居中和缩放校准效果图Fig.5 Centering and scaling calibration renderings
2.2 引入CA
在纸病图像当中,亮斑、褶皱等类型纸病所占像素少且容易受到背景因素影响,原有算法在深层卷积采样时容易丢失上述两类纸病的特征信息,故本课题在骨干特征提取网络当中引入了CA[17]来进一步提高模型的特征提取能力,CA模块的流程如图6所示。输入给定的任意中间张量X=[x1,x2,…,xn]∈RC×H×W,都能输出一个增强表示能力的有相同尺寸的输出Y=[y1,y2,…,yn],式中C为通道数,H和W分别为输入图像的高和宽。
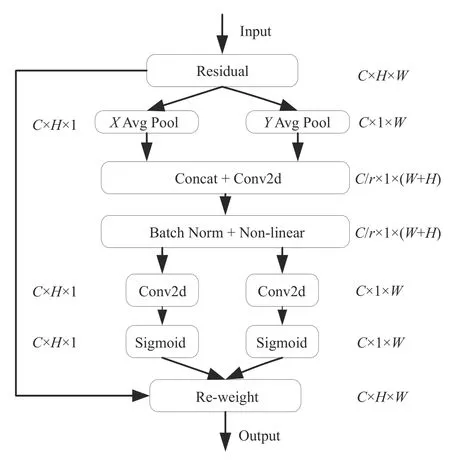
图6 CA模块结构图Fig.6 CA module structure
输入端给定一个特征图,其维度为C×H×W,首先通过全局平均池化沿水平方向和垂直方向对每个通道c进行编码,得到2个一维特征编码向量如式(6)和式(7)所示。

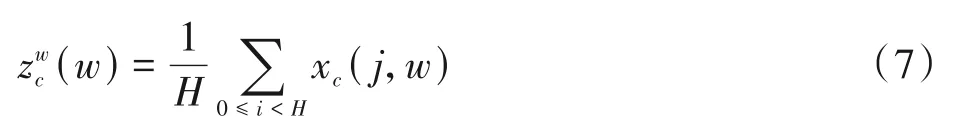
为了利用上述操作产生的信息特征,再使用Concat级联之前生成的特征图zw、zh,然后使用卷积核大小为1的卷积变换函数F1进行变换操作,如式(8)所示。

式中,δ表示非线性激活函数;f表示在水平方向和垂直方向的的空间信息进行编码时的中间特征映射。沿空间维度可将f分解为f h∈RC/r×H和f w∈RC/r×W,其中r表示下采样比例。利用两个卷积核大小为1的卷积运算Fh和Fw对f h和f w进行变换,得到具有相同通道数的张量,变换方式如式(9)和式(10)所示。

式中,σ表示Sigmoid激活函数,为降低计算开销,通常使用恰当的缩减比r来减少f的通道数。最后再对gh和gw进行扩展,分别作为注意力权重,可得最终式(11)。
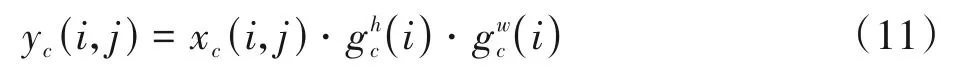
CA是一种较为新颖的注意力机制,可以在不给网络模型带来计算负担的情况下提升模型的检测精度。本课题将其放置在骨干网络当中用以提升骨干网络的特征提取能力,检测结果对比如图7所示。图7(a)中存在一个漏检黑斑,而图7(b)正确检测出所有的黑斑,可见加入CA能够在一定程度上提高网络的检测能力。
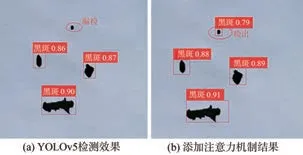
图7 添加注意力机制效果图Fig.7 CA renderings
2.3 改进损失函数
YOLOv5的损失函数Loss,由置信度损失lobj、分类损失lcls及目标框和预测框的位置损失lbox3部分所组成,如式(12)所示。

其中目标置信度误差lobj定义如式(13)所示。
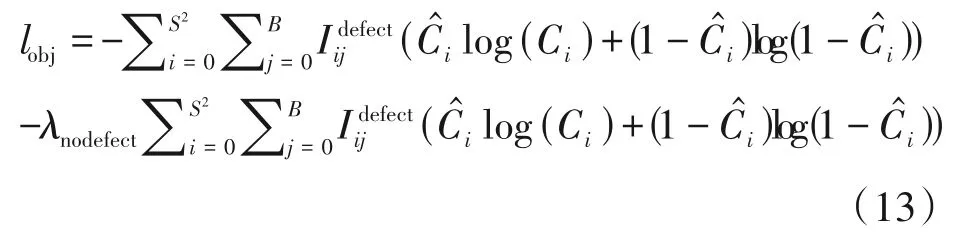
目标分类误差损失lcls如式(14)所示。
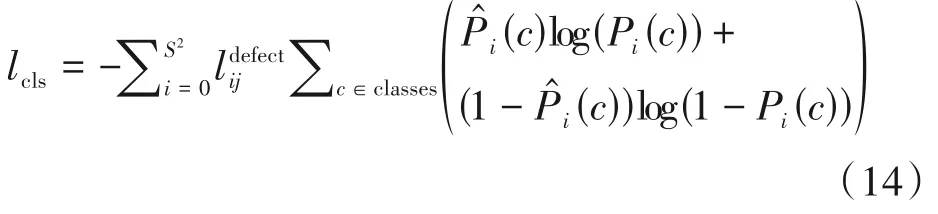
目标框位置误差损失lbox如式(15)所示。
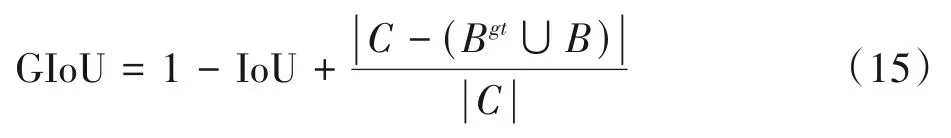
YOLOv5网络模型的原始边界框损失函数为GIoU_loss。其中,B={x,y,w,h}为预测框的大小,Bgt={xgt,ygt,wgt,hgt}为真实框大小,C为B和Bgt的最小面积(真实框与预测框之间的距离越远,C值越大并趋近于1)。
尽管GIoU_loss解决当预测框和目标框不相交,即IoU为0时,损失函数不可导的问题,但GIoU_loss并不稳定而且收敛的速度较慢,所以本课题选择使用CIoU_loss作为边界框的损失函数,CIoU_loss如式(16)所示。
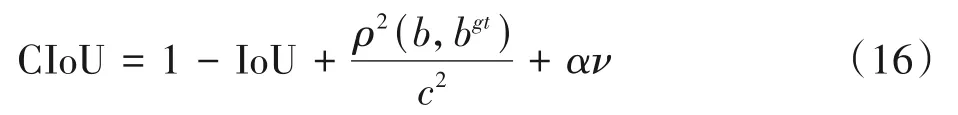
其中,ρ表示预测框与真实框2个中心点之间的欧式距离;c表示相交的预测框与目标框之间所构成外界最小矩形的对角线距离;b和bgt表示B和Bgt的中心点;α表示权重参数;ѵ表示代表长宽比一致性的参数。α和ѵ的计算如式(17)~式(18)所示。
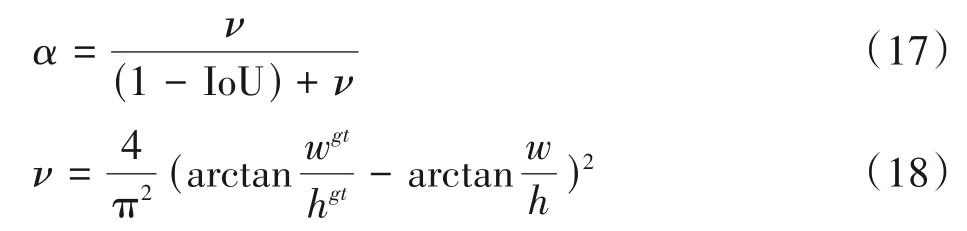
通过CIoU_loss解决了原始模型中预测框与目标框在不同位置时损失值一样的问题,使预测框的回归更加精准,提升网络模型的检测性能。
2.4 算法描述
以YOLOv5网络模型作为基准网络,通过在BN的原始归一化层的开头和结尾添加居中和缩放校准,形成更稳定的特征分布,再在骨干网络添加CA模块提升网络的特征提取能力,最后用CIoU_loss最为边界框回归的损失函数使得模型定位更加精准,进而实现纸张缺陷检测。
改进后的算法具体步骤如下,算法流程图如图8所示。
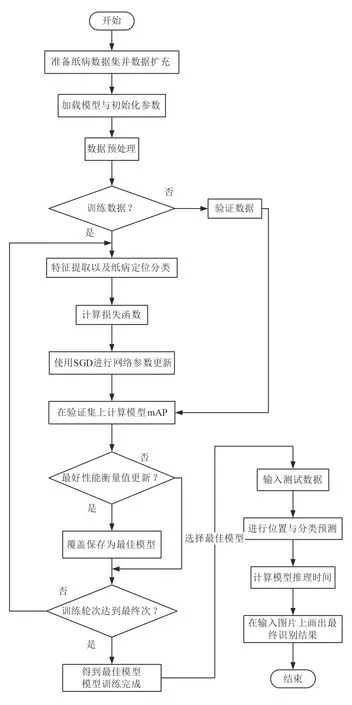
图8 算法流程图Fig.8 Flow chart of the algorithm
(1)准备纸病图像数据,采用增强亮度、翻转、随机裁剪、随机位移、随机添加Gaussian噪声等操作进行数据扩充。
(2)将扩充后的数据随机划分为训练集和验证集。
(3)加载模型配置文件以及初始化参数,对输入数据预处理。
(4)加载网络模型,对输入图片进行特征提取与物体定位分类。
(5)训练时使用SGD网络参数的更新迭代。
(6)在验证集上计算模型的mAP,并在每轮训练结束后判断模型是否为最佳,最佳则进行保存。
(7)训练轮次完成后,保存训练过程当中的最佳模型及最后一次训练模型。
3 实验与分析
3.1 实验数据准备
实验通过在LabelImage软件上进行标注与分类实际纸病图像数据集来验证本课题算法的可行性。实验选择的各类纸病及其数量如表1所示。

表1 实验选择的纸病类别及其数量Table 1 Type and quantity of paper defects selected in the experiment
该数据集样本较少,在模型训练过程中容易过拟合。为了克服该问题,本课题采用增强亮度、随机翻转、随机裁剪、随机位移、添加Gaussian噪声等手段对数据样本进行增强。增强后的训练集和验证集按照9∶1的比例分为训练集(6920张图像)和验证集(769张图像)。
3.2 模型评估
在本实验中,选择的模型评估指标是:查准率(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,AP)、mAP(mean Average Precision)。
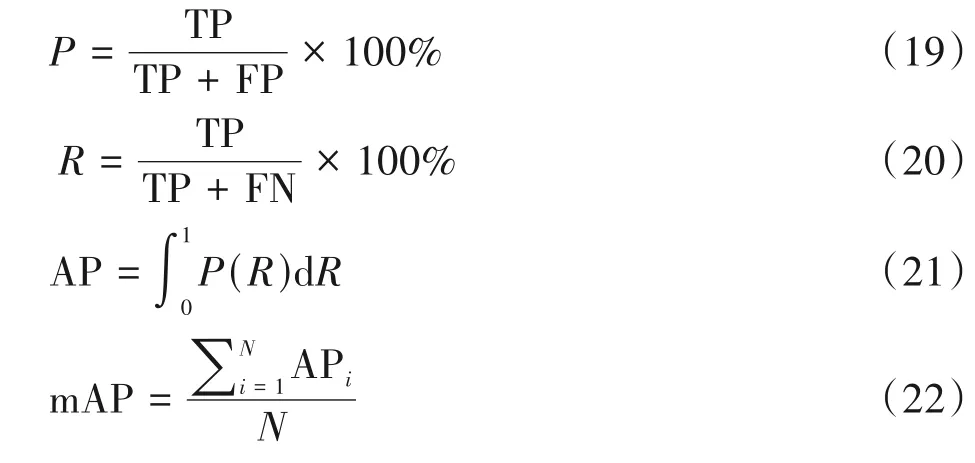
式中,TP(True positives)表示正确分配的正样本;FP(False positives)表示错误分配的正样本;TN(True Negatives)表示正确分配的负样本;FN(False Negatives)表示漏检目标个数;AP表示Precision-Recall曲线下面的面积;mAP表示该图片每一类的平均精度求均值。
3.3 实验条件
实验环境使用Windows 10操作系统,16 GB内存,NVIDIA GeForce RTX 3070显卡,Intel Core i5 10600KF 4.1 Ghz处理器,在pytorch 1.10.0和cuda11.5软件中实现模型的搭建及训练工作。
3.4 测试与分析
对模型进行训练时,通过在COCO数据集上的预训练模型权重进行初始化,采用SGD优化器来进行参数更新,详细参数设置如表2所示。

表2 参数设置Table 2 Parameter settings
图9为模型性能评估结果。由图9(a)可以看出训练过程的损失变化情况,即前期的损失值下降较快,但随着训练轮次的增加,Loss曲线逐渐降低并趋于平稳;可根据图9(b)训练结果中的训练数据信息进行可视化绘图,即平均精度均值(mAP@0.5)、查准率(P)、召回率(R)。
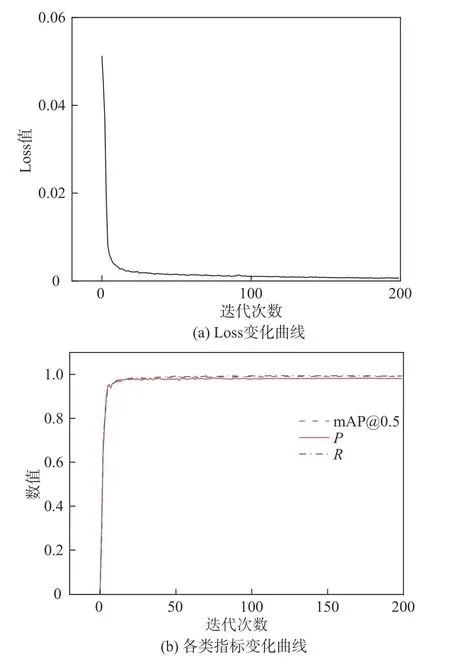
图9 模型性能评估Fig.9 Model performance evaluation
为了方便比较,本课题设计消融实验以验证改进效果,结果如表3所示。由表3可知,改进BN单元、添加CA和修改损失函数都提高了检测性能。改进后的BN模块能够保留目标更多的浅层特征信息,形成更稳定的特征分布,使模型在原基础上mAP提升1.2%,传输帧数有较大提升;通过加入CA,使得模型将空间信息嵌入到通道注意力当中,模型有了更好的检测性能;最后将CIoU_loss作为目标边界框回归的损失函数,解决原损失函数目标框与预测框重合时GIoU退化为IoU的问题,使得模型的定位更加精准。结合3种改进方式改进后的模型mAP为99.0%,相较于原YOLOv5的mAP提升了1.5%,检测速度提高了2.12帧/s。
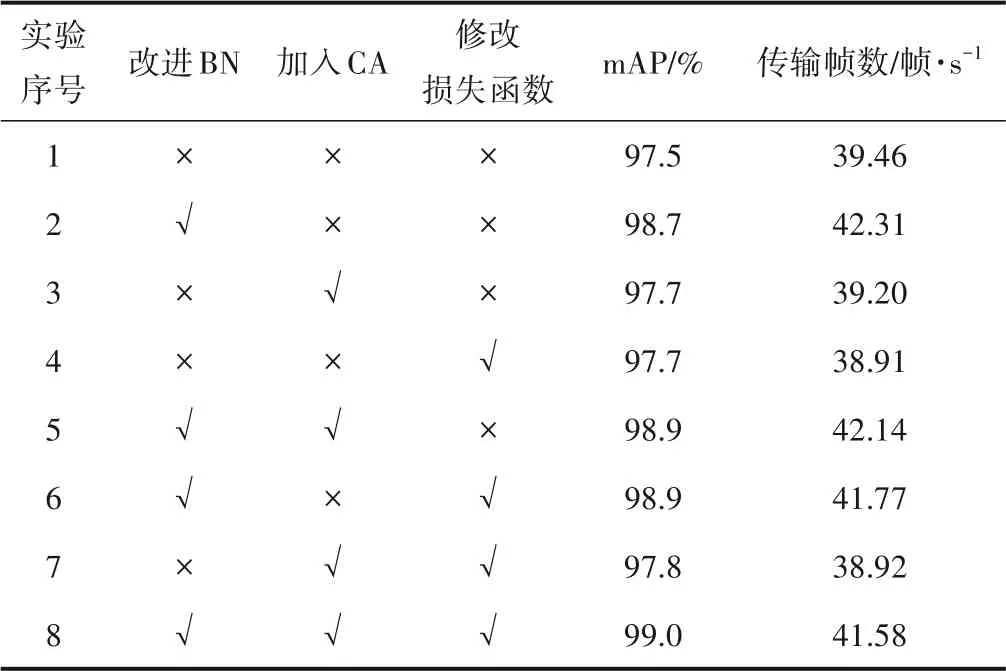
表3 消融实验结果Table 3 Ablation experiment results
3.4.1 不同方法结果对比
为了更好地验证本课题所提出的改进算法的检测性能,采用检测准确率与检测时间2项指标,将本课题的算法同现有基于CNN的纸病分类算法以其余主流目标检测网络模型Faster R-CNN、SSD、YOLOv4、YOLOv5在自建数据集上的训练结果进行评估与对比,对比实验的结果如表4所示。可以看出本课题所提出的改进算法相较于基于CNN的纸病类算法的检测精度更高,检测速度快了31.18帧/s,相较于双阶段目标检测网络模型Faster R-CNN,检测准确率提高了4.9%,检测速度提高了28.5帧/s。对于单阶段目标检测网络模型的SSD、YOLOv4、YOLOv5来说,本课题提出的改进算法在检测准确率和检测时间上都有所提高。
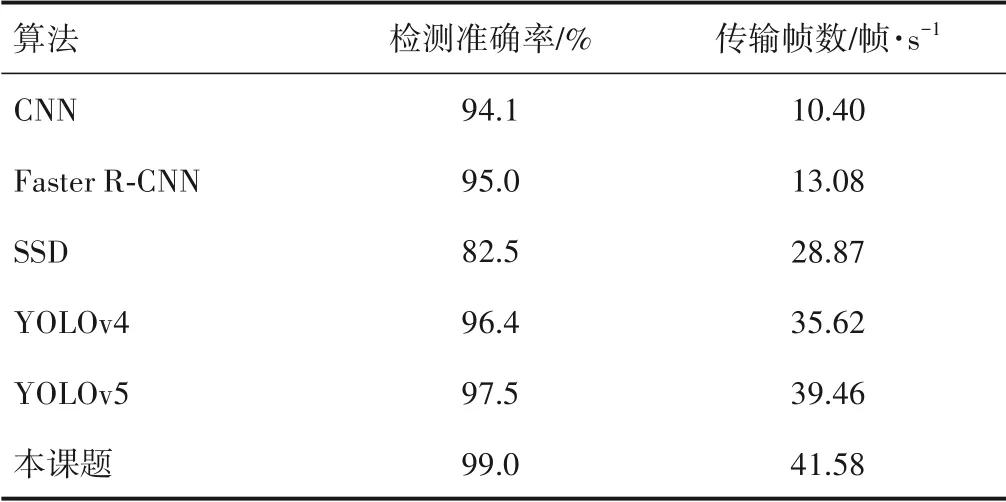
表4 与传统算法检测性能对比Table 4 Compared with traditional algorithm detection performance
图10展示了本课题提出的改进算法应用于常见的各类纸病的检测效果,能够看到本课题提出的改进算法在光照强度不充足,图像具有噪声时仍然能对各类纸病保持较高的检测精度及精准的定位。
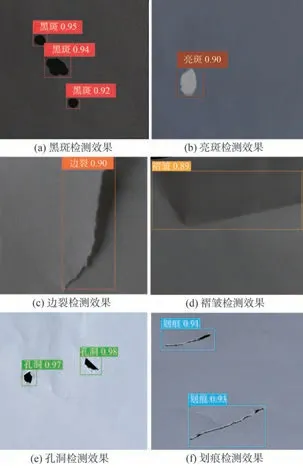
图10 各类纸病检测效果图Fig.10 Various paper disease detection renderings
4 结 语
针对传统纸病检测算法中纸病特征提取困难、实时性差的问题,本课题提出了一种基于改进YOLOv5的纸病检测方法。该方法以YOLOv5网络模型作为基准网络,通过修改批量归一化模块单元使模型形成更稳定的特征分布,再添加注意力机制提升模型的特征提取能力,最后以CIoU_loss作为目标边界框回归的损失函数以实现更高精度的定位。本课题提出的改进算法的平均精度在验证集上达到了99.0%,传输帧数达到了41.58帧/s,检测时间相较于现有的基于CNN的纸病分类算法得到大幅减少,相较于其余主流目标检测网络模型,在检测准确率和检测时间上都有所提升。改进后的算法对于光源的依赖程度更低,并且具有较好的鲁棒性与模型泛化能力。
