基于滑动窗口和LSTM的PM2.5浓度预测模型
2022-11-23刘俊扬张仲荣祁楌捷
刘俊扬,张仲荣,祁楌捷
基于滑动窗口和LSTM的PM2.5浓度预测模型
刘俊扬1,张仲荣1,祁楌捷2
(1.兰州交通大学 数理学院,兰州 730070;2.甘肃荣泽源数据科技有限公司,兰州 730070)
:随着环境空气质量日趋重要,PM2.5浓度也逐渐受到重视。以北京市某空气质量监测站2010.1.1~2014.12.31的PM2.5浓度的小时数据以及对应的气象数据作为样本进行实验。首先对数据进行预处理,考虑到PM2.5前后关联性很强这一特点,将数据进行基于时间的滑动窗口处理以利用数据的时序性,然后对各气象因子进行皮尔逊相关分析,构建了5层长短期记忆(LSTM)网络模型,引入了学习率指数衰减方法,来预测1h后的PM2.5浓度,并将其与Lasso回归、支持向量回归(SVR)模型、XGBoost模型对比,发现构建的LSTM模型预测效果最好。
空气质量;PM2.5;滑动窗口处理;LSTM;指数衰减方法
人民的健康问题是我国的一项重要民生问题,衡量空气质量的一个重要指标就是PM2.5。研究分析PM2.5的浓度变化,并作出精准预测,能让公众更加了解PM2.5浓度的变化趋势,也为国家施行相关政策法规提供了方便。对于居民身体健康、出行安排、企事业单位发展、国家环境治理有着重要作用。
常见的空气质量预测方法可分为三类,潜势预测、统计预测、数值方法预测。由于空气质量数据本身的复杂性以及非线性等因素,一般的统计方法难以做出精准的预测。数据挖掘技术的不断成熟,使得越来越多的机器学习方法用于空气质量预测。
常用的机器学习方法有支持向量机、人工神经网络、XGBoost等。Chelani[1]采用支持向量机模型来预测日最大O3浓度,并在模型中引入了气象参数,用2002~2004印度德里某地观测到的日最大O3浓度以及气象值作为数据对模型训练,最后发现预测误差要小于神经网络模型的预测误差;Ortiz-Garcia等[2]使用了SVMr的改良算法来预测马德里城区小时O3浓度,这种算法是对SVMr超参数搜索空间的一种降维处理。该算法兼容性强,也能将城市变量、交通变量纳入其中,以提高预测精度;白胜楠[3]利用北京市2010年至2017年大气数据和气象数据,使用灰色关联度分析对影响PM2.5的多个属性进行关联强度分析,构建LSTM模型对PM2.5日浓度进行预测,结果表现良好;Pan[4]根据天津市空气质量检测数据,使用XGBoost算法对天津市PM2.5小时浓度进行预测,并将结果分别与随机森林、多元线性回归、决策树和支持向量回归得到的结果做比较,发现XGBoost算法的表现要优于上述4种模型。
由此,本文把4种统计预测模型Lasso, SVR, XGBoost, LSTM分别用于空气质量数据的训练测试和预测,最后将4种模型得到的预测结果进行对比分析。
1 研究数据
1.1 研究区域和数据来源
本文选取了北京市2010年1月1日至2014年12月31日共43824条PM2.5浓度的小时数据以及对应的北京首都国际机场的气象数据。其中PM2.5浓度的小时数据由美国驻北京大使馆采集获取。
1.2 数据预处理
1.2.1 去除趋势和季节性
为了控制PM2.5浓度小时数据的质量,剔除了原数据中小时PM2.5浓度小于0的值和大于800μg/m3的异常值。并对当天PM2.5浓度小时数据缺失大于4小时的数据予以整天剔除。若当天缺失数据少于4小时,则用Pandas库中的前项填充的方法填充该缺失值。图1展示了2010年1月1日至2014年12月31日PM2.5浓度的小时数据变化。
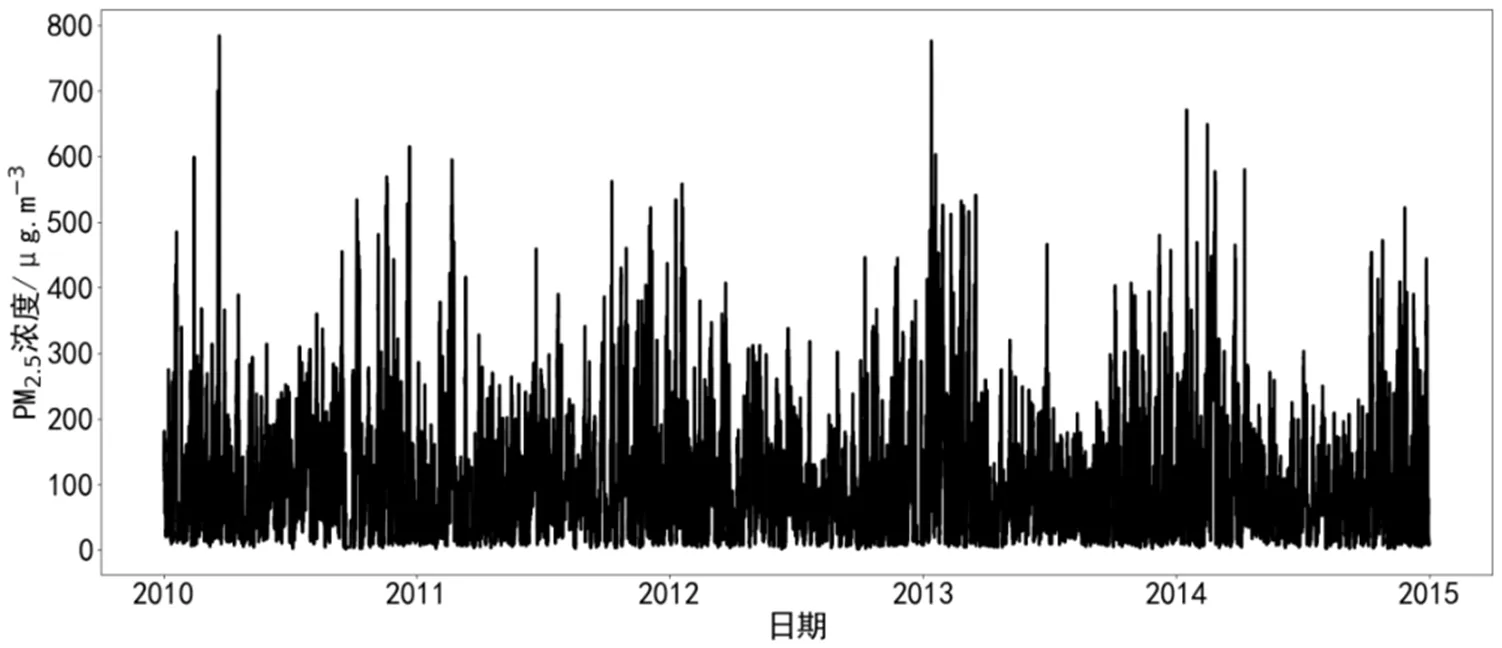
图1 PM2.5小时浓度变化图
由于PM2.5浓度的小时数据存在较强的趋势和季节性,故采用移动平均法剔除了原数据中的趋势和季节性。如图2所示,首先将数据归一化处理,发现均值在-1到2之间,标准差在1附近。再减去12期加权移动平均值,发现均值在-1到1之间,标准差在1附近。此处遂改用一次差异化对归一化后的PM2.5浓度的小时数据进行处理,最终发现均值在0附近,标准差在0.6到1之间。
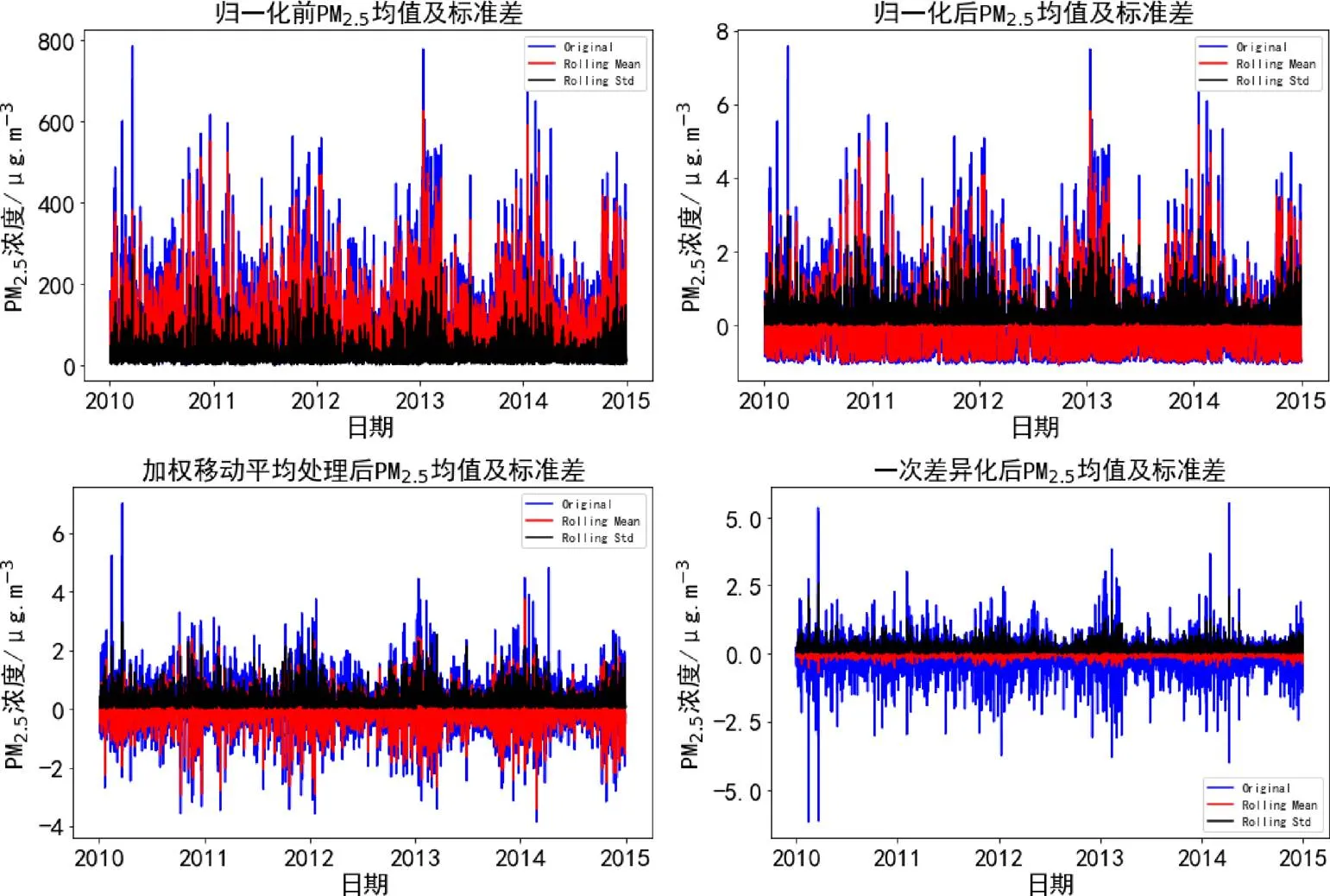
图2 PM2.5小时浓度的均值和方差图
1.2.2 滑动窗口处理
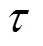
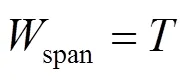
而连续时间内的基本窗口序列可以组建成一个滑动窗口,表示为
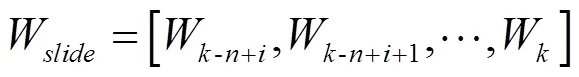
式中,W为第个基本窗口抵达后的时间窗口;为滑动窗口可容纳的基本窗口数量。时间窗口的跨度可表示为[5]
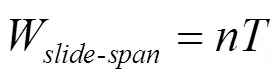
基于时间的滑动窗口处理模型如图3所示,基本窗口的滑动形成了滑动窗口。
考虑到PM2.5浓度数据具有时序性,前后关联较强,因此对数据进行基于时间的滑动窗口处理。将过去每5天的PM2.5浓度的小时数据以及对应的气象数据共120条进行整合封装,看作一个窗口的数据,作为模型的一个输入,然后把当前00:00时刻的PM2.5浓度的小时数据设为模型的输出。即利用前5天的气象数据及PM2.5浓度小时数据预测1小时后的PM2.5浓度。
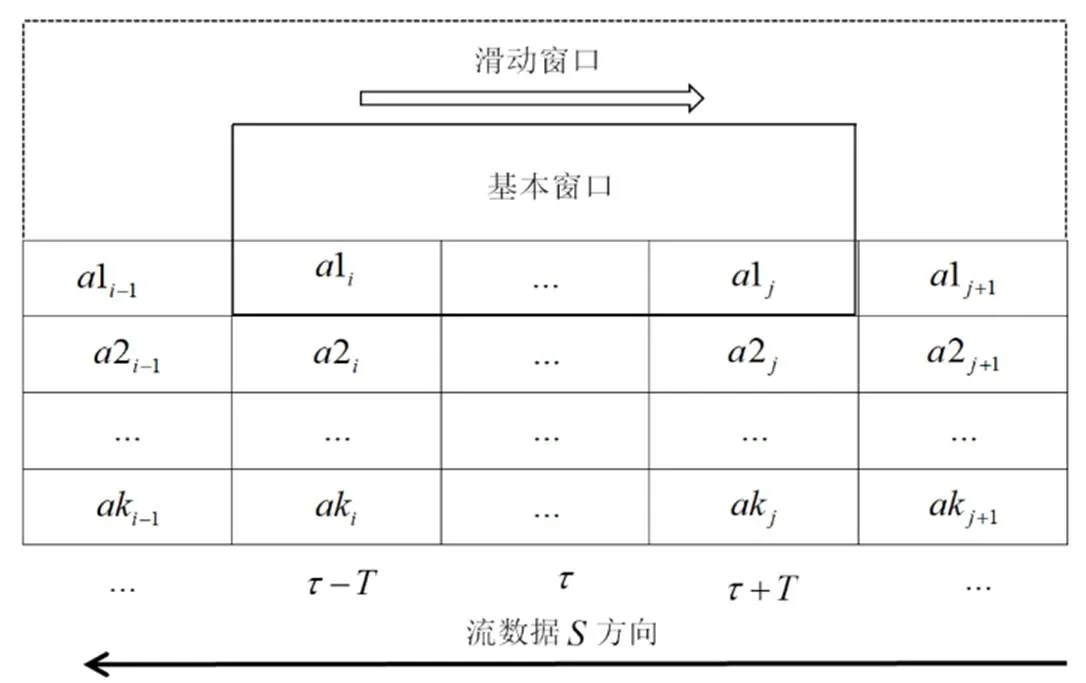
图3 滑动窗口处理模型
1.3 影响因素分析
PM2.5的浓度不仅受大气污染物浓度的影响,还与气象因子之间有着强大的关联。本文收集到的气象数据包含露点、温度、气压、组合风向、累计风速、累计降雪时间、累计降雨时间。图4展示了各气象因子以及空气质量数据之间的两两相似度,相似度由皮尔逊相关系数度量。可以看出PM2.5浓度与露点DEWP是成正相关,与累计风速Iws成负相关。
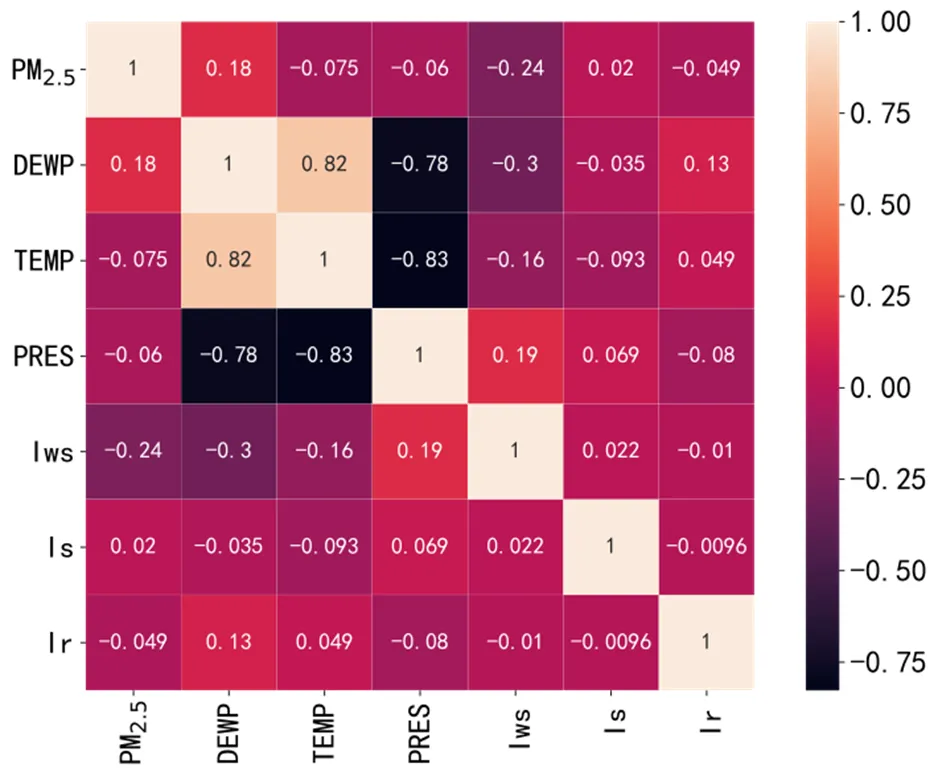
图4 PM2.5与各气象因子的热力图
2 PM2.5短期预测模型设计
2.1 PM2.5浓度预测的整体框架
本文设计的PM2.5小时浓度预测的总体框架如图5所示,首先是对包含气象数据及对应的空气质量数据的数据集进行预处理,具体操作如下:异常值的剔除、缺失值的填充、归一化处理以及去除季节性和趋势。然后考虑到PM2.5小时浓度数据具有很强的时序性,于是对其进行窗口化处理,之后将数据集划分成训练集和测试集,分别代入Lasso, SVR, XGBoost, LSTM四个模型进行训练,最后对预测结果进行分析。
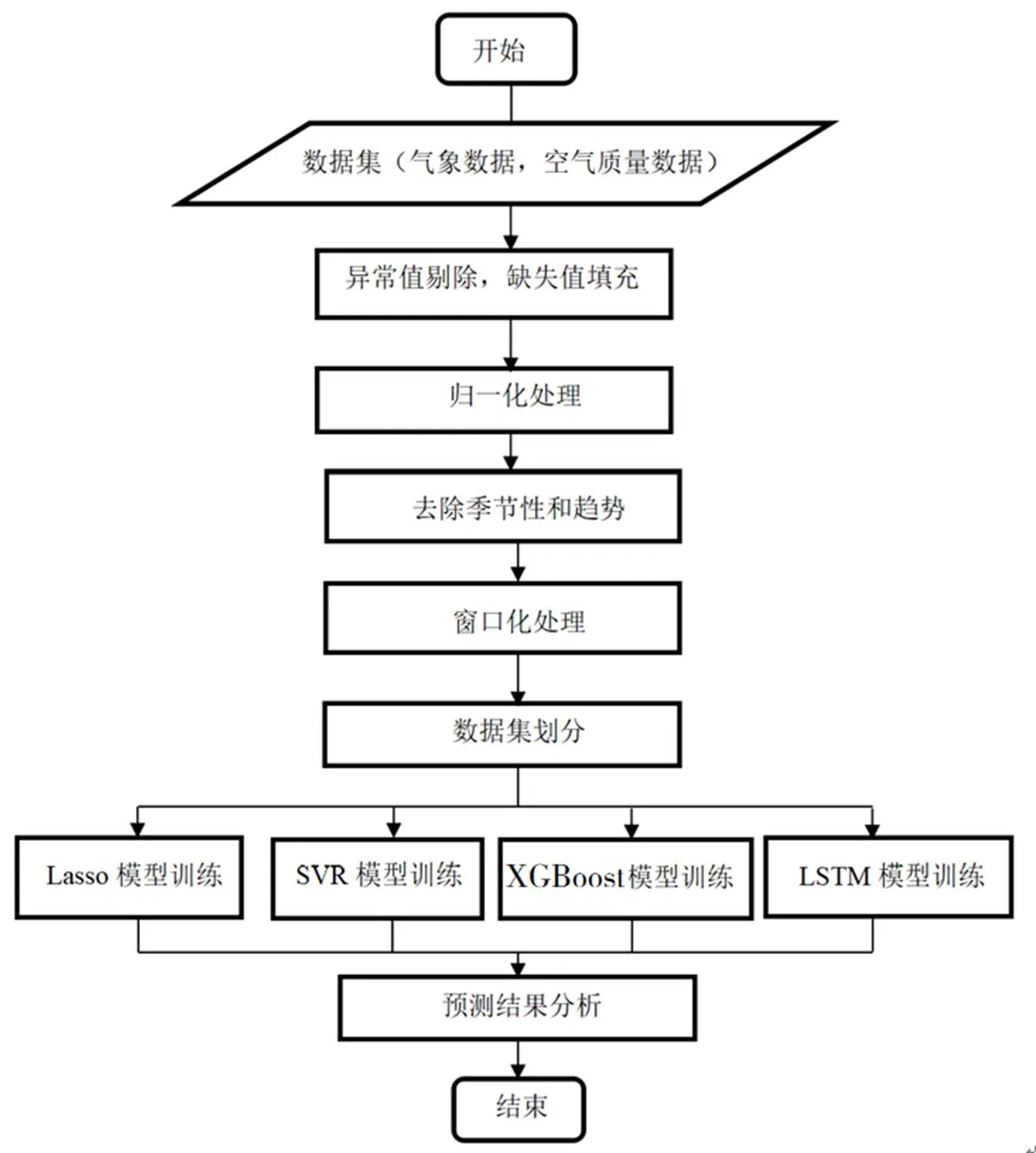
图5 PM2.5预测框架图
2.2 Lasso回归模型
Lasso是通过降维来进行预测的一种方法。首先构造一个惩罚函数,然后对于需要惩罚的变量,将其系数进行压缩,甚至设置为0,以此来达到变量选择的目的[6]。
对于一个待优化目标函数:
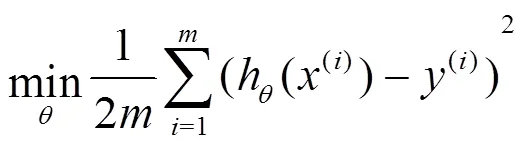
其中,为样本个数。
添加惩罚项后即得Lasso模型:
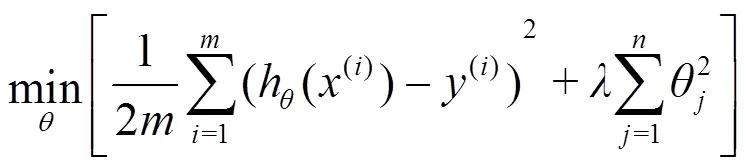
2.3 支持向量回归模型
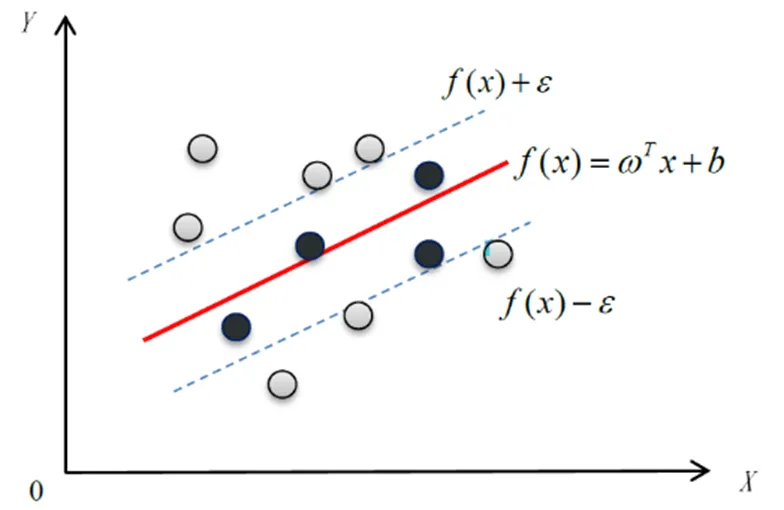
图6 SVR示意图
间隔带距离计算公式为
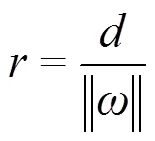
于是SVR问题可形式化为
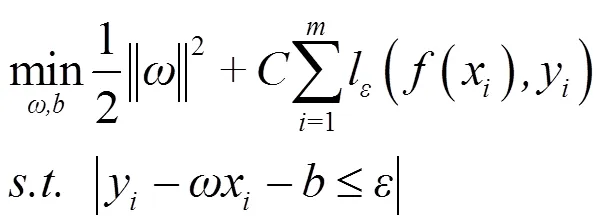
引入松弛变量后,上述问题可化为
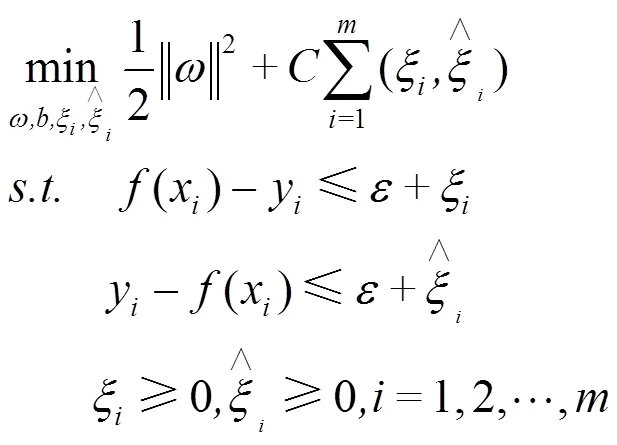
对约束条件使用拉格朗日乘子法,得最终SVR模型
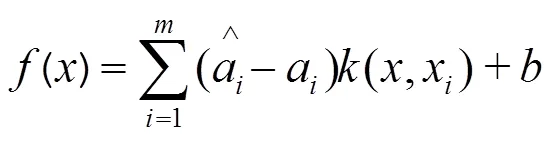
2.4 XGBoost模型
XGBoost是由陈天奇等提出的一种支持并行计算的梯度提升树模型,近些年该模型凭借突出的效率和较高的预测精度被广泛应用于Kaggle机器学习竞赛中[7]。XGBoost是基于GBDT(Gradient Boosting Decision Tree)改进的一种算法,二者本质上都是由许多决策树构成。相较于GBDT,XGBoost做了以下改进:(1)XGBoost在损失函数中加入了正则化项,以此来控制模型的复杂度,这样可以有效抑制模型的过拟合;(2)XGBoost将损失函数使用二阶泰勒展开,而GBDT使用的是一阶泰勒展开损失函数,二阶泰勒能够更好地近似化损失函数。
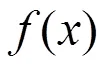
目标函数
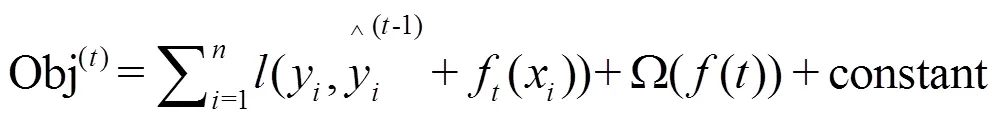
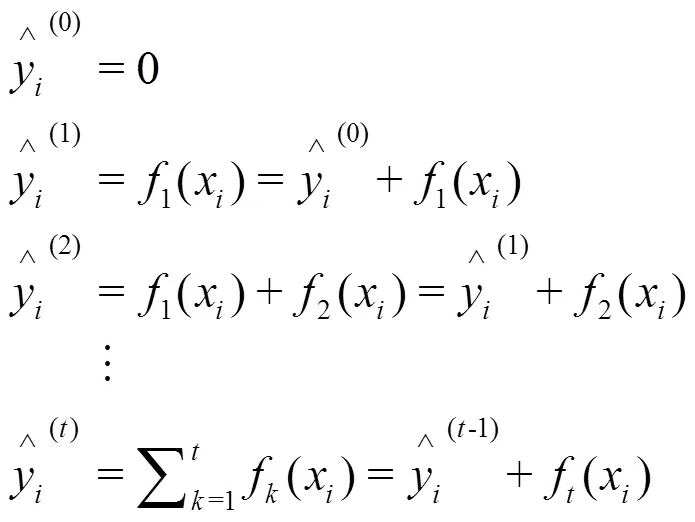
用二阶泰勒公式来近似展开目标函数:
令
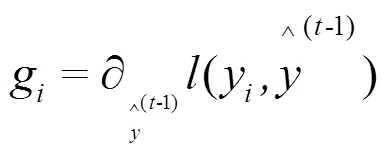
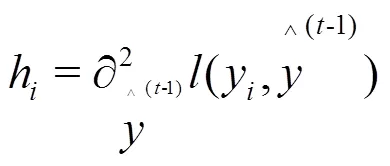
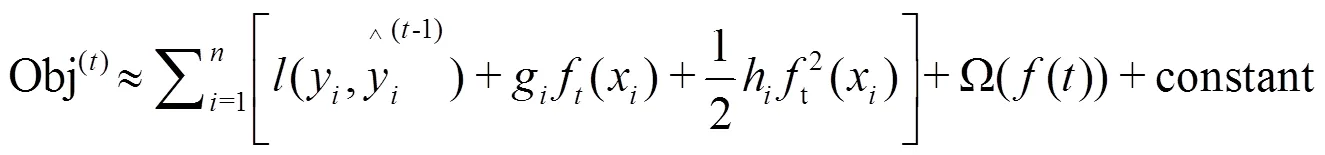
2.5 LSTM神经网络模型
LSTM神经网络模型是基于普通的循环神经网络(Recurrent Neural Network,RNN)改进的一种新型循环神经网络算法。
尽管RNN模型很善于处理非线性时间序列数据,但仍然存在以下2个问题:(1)随着训练所用到的时间步的推移,由于梯度消失和梯度爆炸问题,RNN不能用于处理较长的时间序列数据;(2)RNN模型的训练需要预先确定延迟窗口长度,然而实际操作中很难找到该参数的最优值[8]。
于是,LSTM模型应运而生。LSTM模型将隐藏层的RNN细胞替换为LSTM细胞,能有效克服梯度在反向传播的过程中可能会快速消失这一问题,使其具有长期记忆能力,能够处理长时间序列数据。
如图7[8]所示,RNN在细胞单元内部建立的递归计算;相对于RNN,LSTM单元的内部设置了3个门控开关,如图8[8]所示,其中,为输入门;为遗忘门;为细胞状态;为输出门;和tanh分别为Sigmoid和双曲正切激活函数。
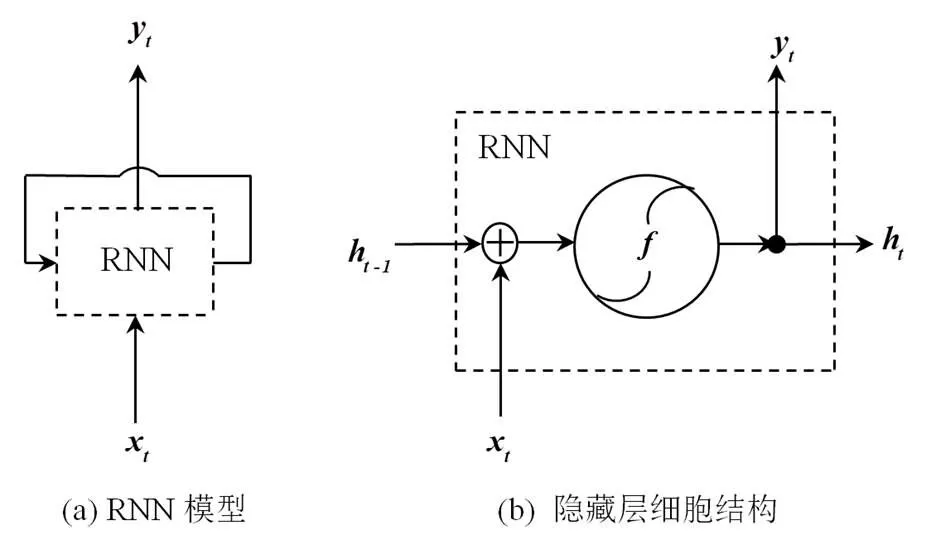
图7 RNN模型及隐藏层细胞结构
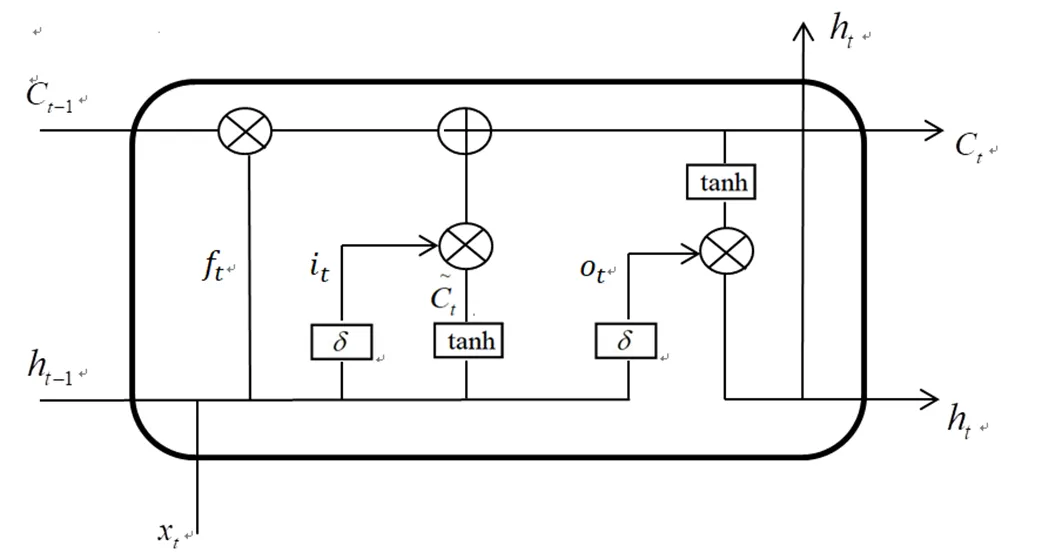
图8 LSTM隐藏层细胞结构
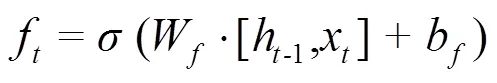
输入门用来更新单元状态。先将先前隐藏状态的信息和当前输入的信息输入到Sigmoid函数,在0和1之间调整输出值来决定更新哪些信息,0表示不重要,1表示重要。同时将隐藏状态和当前输入传输给tanh函数,并在-1和1之间压缩数值以调节网络,然后把tanh输出和Sigmoid输出相乘,Sigmoid输出将决定在tanh输出中哪些信息是重要的且需要进行保留。
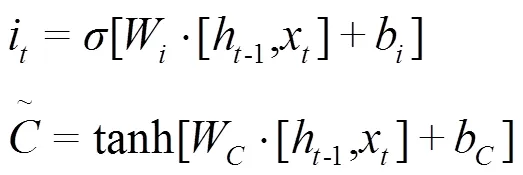
输出门控制着下个隐藏状态的值。当然,隐藏状态也可用于预测。首先把先前的隐藏状态和当前输入传递给Sigmoid函数;同时把新得到的单元状态传递给tanh函数;然后把tanh输出和Sigmoid输出相乘,得出隐藏状态新的信息,作为当前单元的输出值输出;最后将新的单元状态和隐藏状态同步至下个时间步。
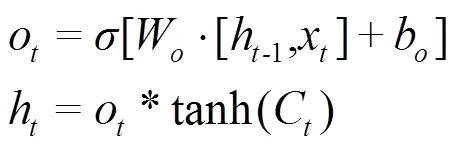
LSTM模型训练过程采用的是与经典的反向传播(Back Propagation,BP)算法原理类似的BPTT(Back Propagation Through Time,BPTT)算法,大致可以分为4个步骤:(1)按照前向计算方法(式(12)~(14))计算LSTM细胞的输出值;W和b分别为对应的权重系数矩阵和偏置项;(2)反向计算每个LSTM细胞的误差项,包括按时间和网络层级2个反向传播方向;(3)根据相应的误差项,计算每个权重的梯度;(4)应用基于梯度的优化算法更新权重[8]。
3 实验与分析
3.1 与其他模型进行比较
本文构建了Lasso回归模型、SVR模型、XGBoost模型和LSTM网络模型来分别预测PM2.5浓度。首先将预处理之后的数据进行5期窗口化处理,即把第-5天、第-4天、第-3天、第-2天、第-1天的共5天的PM2.5浓度的小时数据和对应的气象数据以及第天的气象数据当作自变量,把第天24:00的PM2.5浓度的小时数据当作因变量,代入各模型进行训练。
对于Lasso模型、SVR模型、XGBoost模型的超参数,均使用网格搜索算法进行确定。对于LSTM神经网络模型,根据经验法则,不断调试,最终构建了32-64-32-64-1的5层神经网络模型,并对第2, 3层神经元进行随机失活,同时加入L2正则化参数。学习率引入了指数衰减法,优化方法采用Adam。
3.2 评价方法
本文采用均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、决定系数(2)来评价模型的预测效果。具体计算方法如表1所示。
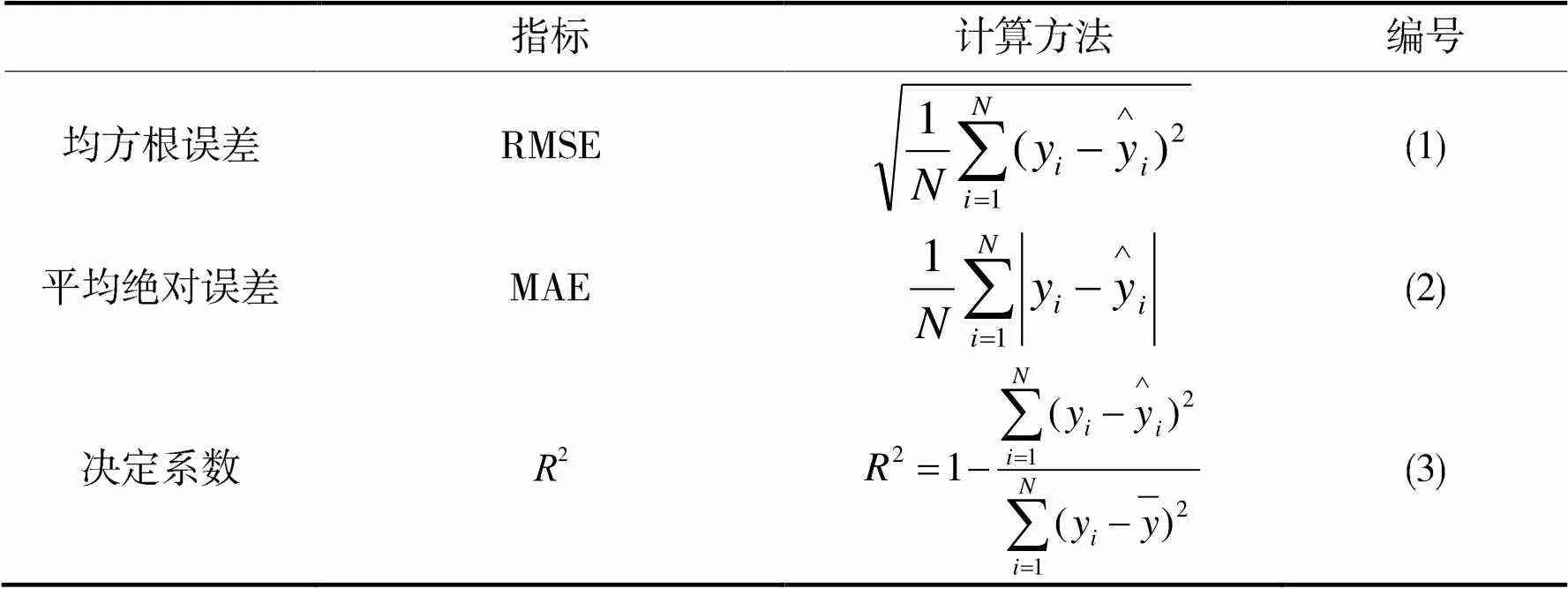
表1 评价指标及计算公式
3.3 不同模型的预测性能
图9展示了4个模型预测值与真实值的散点图。图中红线为1∶1标准线,蓝线为真实值与预测值之间的关系式,左上角给出了具体表达式。蓝线越靠近红线,说明预测值与真实值越接近,预测效果越好。可以看出4个模型的蓝线都很靠近红线,都能对PM2.5浓度做出预测。可以看出LSTM的预测最为准确。
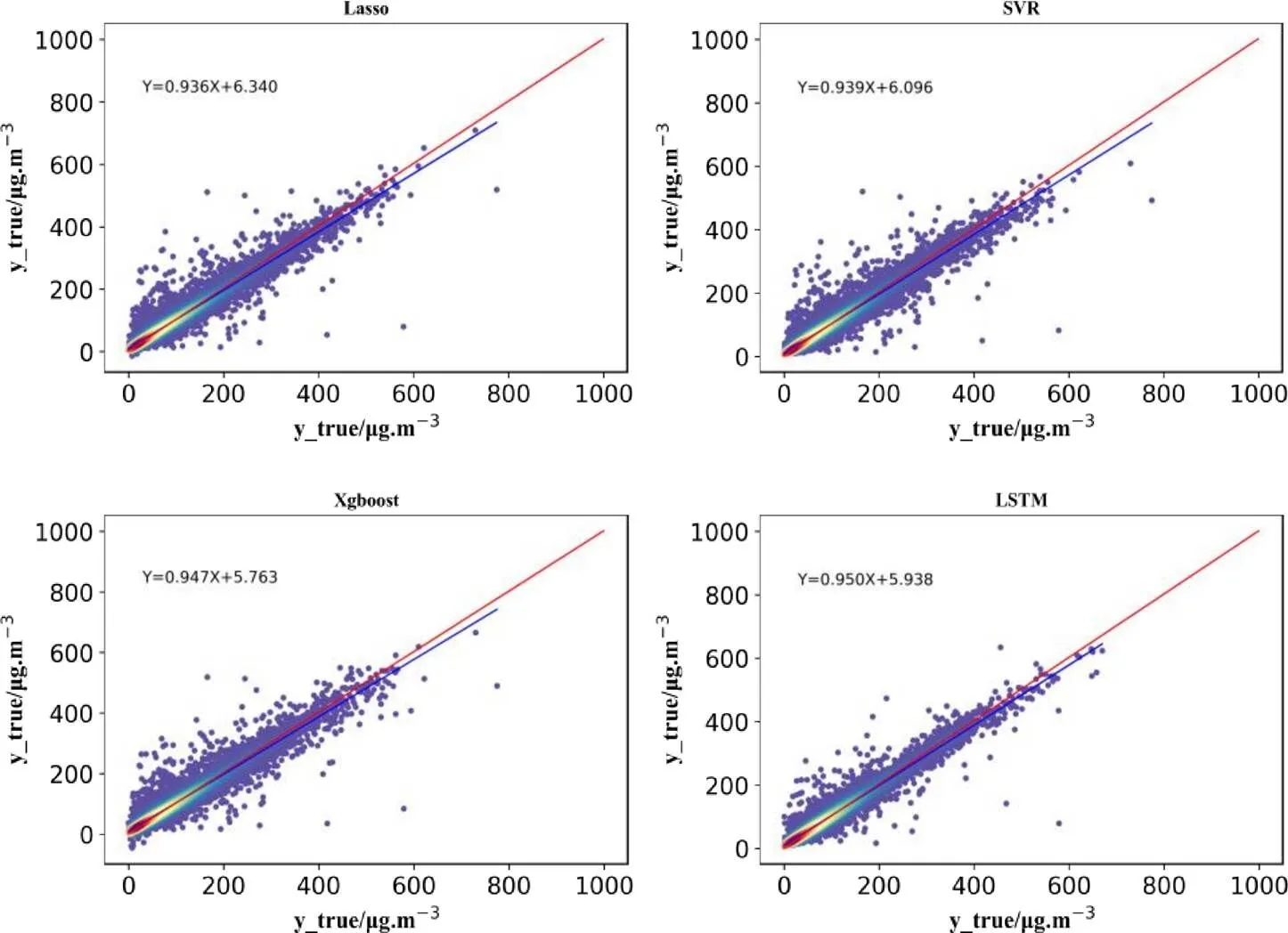
图9 测试集上各模型预测效果散点图
根据表2和表3可知,Lasso模型在训练集和测试集上的RMSE最大,MAE最大,2最小,其次是SVR模型,再是XGBoost模型,LSTM模型在训练集和测试集上的RMSE最小、MAE最小,2最大。说明LSTM模型对数据的处理能力最强,拟合效果最好,预测精度最高。
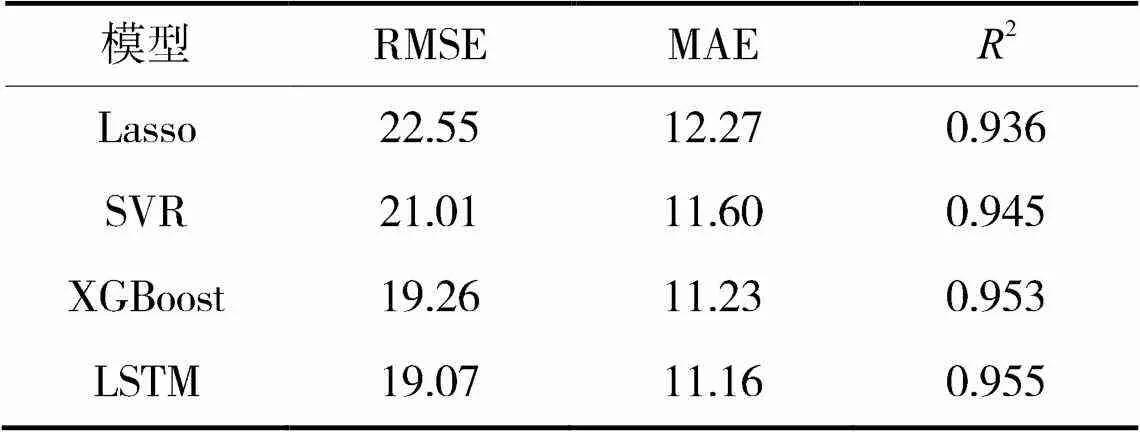
表2 训练集上不同模型的预测性能
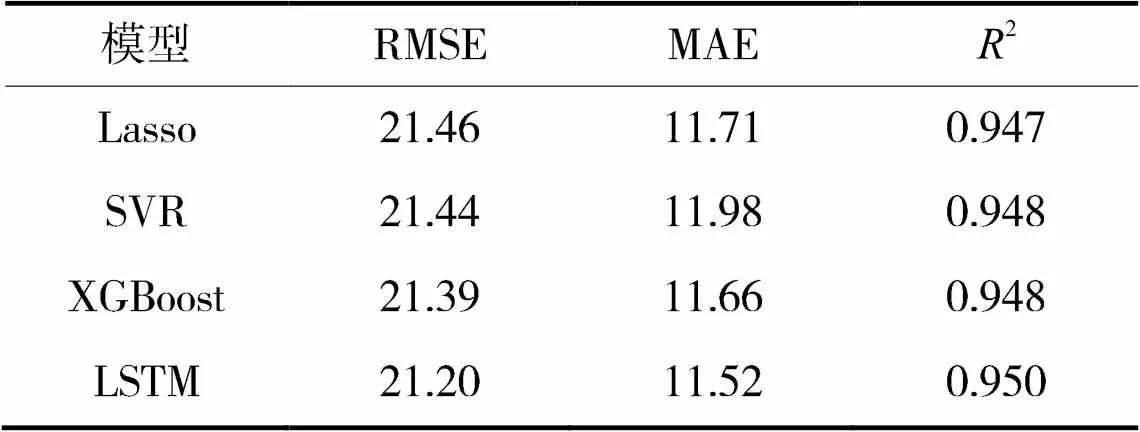
表3 测试集上不同模型的预测性能
4 结论
本文通过构建基于滑动窗口的LSTM网络模型,对北京市的空气质量进行预测分析,并将结果与Lasso模型、SVR模型、XGBoost模型进行对比,得出以下结论:
(1)影响因子相关分析表明露点、温度、气压、组合风向、累计风速、累计降雪时间、累计降雨时间均与PM2.5浓度有不同程度的关联,其中露点、累计风速与PM2.5浓度的关联性最强;
(2)对数据进行滑动窗口处理可以有效利用空气质量和气象数据的前后关联性;
(3)LSTM模型比Lasso模型、SVR模型、XGBoost模型的预测误差更小,展现了LSTM模型处理时序性数据的能力。
未来可以考虑对数据的预处理LSTM模型的结构做进一步改进,以进一步提高精度。
[1]CHELANI A B. Prediction of daily maximum ground ozone concentration using support vector machine[J]. Environmental Monitoring and Assessment, 2010, 162(1-4): 169-176.
[2] ORTIZ-GARCIA E G, SALCEDO-SANZ S, PEREZ-BELLIDO A M, et al. Prediction of hourly O3concentrations using support vector regression algorithms[J]. Atmospheric Environment, 2010, 44(35): 4481-4488.
[3] 白盛楠,申晓留. 基于LSTM循环神经网络的PM2.5预测[J]. 计算机应用与软件,2019, 36(01): 67-70, 104.
[4] PAN B Y. Application of XGBoost algorithm in hourly PM2.5concentration prediction[J]. IOP Conference Series: Earth and Environmental Science, 2018, 113(1): 012127.
[5] 徐江,张鸿宇,李军怀,等. 基于滑动窗口的流数据并行处理方法[J]. 重型机械,2021(01): 29-36.
[6] 张兴祥,钟威,洪永淼. 国民幸福感的指标体系构建与影响因素分析:基于LASSO的筛选方法[J]. 统计研究,2018, 35(11): 3-13.
[7] 陈延展,胡浩,任紫畅,等. 基于XGBoost和改进灰狼优化算法的催化裂化汽油精制装置的辛烷值损失模型分析[J/OL].石油学报(石油加工): 1-15[2021-06-17].http://kns.cnki.net/kcms/detail/11.2129.TE.202106-02.1425.002.html.
[8] 王鑫,吴际,刘超,等. 基于LSTM循环神经网络的故障时间序列预测[J]. 北京航空航天大学学报,2018, 44(04): 772-784.
PM2.5concentration prediction model based on sliding window and LSTM
LIU Jun-yang1,ZAHNG Zhong-rong1,QI Yan-jie2
(1.School of Mathmatics and Physics, Lanzhou Jiaotong University, Lanzhou 730070, China; 2.Gansu rongzeyuan Data Technology Co., Ltd., Lanzhou 730070, China)
With the increasing importance of ambient air quality, the concentration of PM2.5has been paid more and more attention. In this paper, the hourly data of PM2.5concentration from January 1, 2010 to December 31, 2014 in an air quality monitoring station in Beijing and the corresponding meteorological data were taken as samples for experiments. Firstly, the data are preprocessed, considering the strong correlation between PM2.5and PM2.5, the data are processed by sliding window based on time to take advantage of the time series, and then Pearson correlation analysis is carried out on each meteorological factor, and a five-layer LSTM network model is constructed. The learning rate exponential decay method is introduced to predict the concentration of PM2.5after one hour, which is compared with Lasso regression, SVR model and XGBoost. It is found that the constructed LSTM model has the best prediction effect.
air quality;PM2.5;sliding window processing;LSTM;exponential decay method
2021-07-27
国家自然科学基金重点项目(41930101);甘肃省科技计划资助(20YF3GA013);甘肃省科技型中小企业技术创新基金项目资助(20CX9JA128)
刘俊扬(1996-),男,湖北随州人,硕士,主要从事数据科学与时空预测预警研究,523555778@qq.com。
X513
A
1007-984X(2022)01-0087-08
