基于BERT-BiLSTM-CRF模型的中文实体识别研究
2022-11-23沈同平俞磊金力黄方亮许欢庆
沈同平,俞磊,金力,黄方亮,许欢庆
基于BERT-BiLSTM-CRF模型的中文实体识别研究
沈同平,俞磊,金力,黄方亮,许欢庆
(安徽中医药大学 医药信息工程学院,合肥 230012)
:中文文本实体识别,是自然语言处理的关键问题。传统的语言处理模型无法有效表示文本中的上下文语义信息,无法处理一词多义的不同语境,影响实体识别效果。提出了一种BERT-BiLSTM-CRF的实体识别模型,BERT预处理语言模型生成表征上下文语义信息的词向量,通过双向长短期记忆网络对生成的向量进行特征提取,自注意力机制能够有效获取文本语句中的长距离依赖,最后通过CRF进行解码生成实体标签序列。实验结果表明,该模型在微软亚洲研究院MSRA语料库和人民日报语料库上都取得了优异成绩,1分别达到96.12%和95.88%。
命名实体识别;深度学习;多头注意力;BERT
中文实体识别(Named Entity Recognition,NER)是自然语言处理(Natural Language Processing,NLP)研究的一个重要方向,主要对文本中的各类命名实体进行识别和提取,比如传统文本中的姓名、民族、学历、国籍、组织等,医学文本中的症状、疾病名称、检查手段和方式等。自1995年在第六届信息抽取会议上提出实体识别评测任务后,受到广泛关注。文本命名实体识别研究在国内外迅速发展,研究主要聚焦于在金融、新闻媒体、医学文本处理等方面。文本实体识别是信息提取、智能问答和知识图谱等研究的重要基础,NER提取效果的优劣直接影响后续自然处理质量和效率[1]。
针对命名实体提取的研究方法很多,主要有基于规则和词典的方法、机器学习方法、深度学习方法等。
基于词典和规则的方法,这类方法过多依赖于语言学家的制定的规则模板,程序繁琐,容易产生错误,移植性差。Humphreys等针对MUC-7任务开发了LaSIE-II系统[2]。Collins等提出未标记示例对于命名实体分类的影响,需要制定大量规则来提高实体识别效率[3]。随后传统的机器学习方法应用实体识别模型中,比如隐马尔可夫模型(HMM)、最大熵模型(MEM)、支持向量机模型(SVM)和条件随机场模型(CRF)等。Bikel等提出一种隐藏的马尔可夫模型,可以学习识别和分类名称、日期、时间和数字量[4]。乐娟等人采用HMM算法对京剧机构命名实体进行识别[5]。陆铭等提出一个简约语法规则和最大熵模型相结合的混合命名实体识别方法[6]。Bender等提出了一种使用最大熵算法提取自然语言输入的命名实体框架[7]。在传统的机器学习方法中,命名实体识别需要大规模的语料库来学习标注模型,在特征提取方面仍需要人工参与,同时语料库标注的质量严重影响实体识别效果。
近年来,随着深度学习技术的不断发展,被广泛应用于自然语言处理领域,在实体识别任务中取得良好的效果。
Hammerton最早将长短期记忆网络(LSTM)应用到文本实体识别研究中,并取得良好的识别效果,LSTM-CRF结构成为实体识别的基础结构[8]。高翔等提出使用条件随机场(CRF)与长短时记忆神经网络(LSTM)相结合的LSTM-CRF模型, 通过加入预先训练的字嵌入向量及不同词位标注集,对军事动向文本进行实体识别[9]。
后来,Lample等在LSTM-CRF的基础上,提出双向长短期记忆网络(Bi-LSTM)和条件随机场(CRF)结合的模型,这种结构能够获取文本双向语义信息,在文本命名实体中任务中表现优异,在CoNLL-2003数据集中的1值达到90.94%[10]。
杨晓辉等提出一种基于分词任务和命名实体识别任务相结合的多任务双向长短期记忆网络模型,通过加入共享LSTM捕获分词任务中的词边界信息,丰富了命名实体识别任务的特征集,进而达到提高命名实体的效果[11]。陈美杉等提出一种结合实例迁移和模型迁移的KNN-BERT-BiLSTM-CRF框架,对仅有少量标注的肝癌患者提问文本进行跨领域命名实体识别[12]。朱顺乐针对维吾尔语命名实体识别中存在的语义信息欠缺及其数据稀疏等问题,提出一种基于深度神经网络的维吾尔语命名实体识别方法[13]。徐啸等提出一种基于自注意力的双向长短期记忆条件随机场(SelfAtt-BiLSTM-CRF)方法来识别微博中的实体,利用自注意力机制,获取词与词之间的依赖关系,进一步提高模型的识别能力[14]。崔丹丹等提出了基于LatticeLSTM模型的古汉语命名实体识别算法,该方法将字符序列信息和词序列信息共同作为模型的输入,提升了古汉语命名实体识别的效果[15]。
上述方法在自然语言处理领域取得一定的成效,实体识别效率得到进一步提升。但以上方法都存在一个问题,就是无法处理一词多义的问题,只能处理独立的字符、词语的特征向量,忽略字符的上下文语义信息,导致存在实体识别准确率不高的问题。2018年Goolge团队结合不同语言模型的优点,提出BERT模型[16]。BERT模型采用双向Transformer神经网络作为编码器,增强预训练词向量模型的泛化能力,充分描述字符、词语和语句之间的关系特征。对下个字的预测可以参考前后双向的输入信息,表征不同语境中的相同词的语义,有效解决一词多义的问题。
岳琪等将深度学习与知识图谱相结合,提出一种基于改进BERT和双向RNN的模型用于林业实体识别和实体关系抽取[17]。姜同强等通过BERT层进行字向量预训练,根据上下文语义生成字向量,字向量序列输入BiLSTM层和Attention层提取语义特征,再通过CRF层预测并输出字的最优标签序列,最终得到食品案件纠纷裁判文书中的实体[18]。杜琳等提出一种基于BERT+BiLSTM+Attention融合的病历短文本分类模型[19]。陈剑等使用基于双向训练Transformer的编码器表征预训练模型。在手工标注的语料库中微调模型参数,再由长短时记忆网络与条件随机场对前一层输出的语义编码进行解码,完成实体抽取[20]。赵平等为解决旅游文本在特征表示时的一词多义问题,针对旅游游记文本景点实体识别中景点别名的问题,研究了一种融合语言模型的中文景点实体识别模型[21]。
1 BERT-BiLSTM-CRF模型
1.1 模型概述
本文提出的BERT-BiLSTM-CRF模型结构如图1所示,模型总共由4个模块组成。BERT层将输入的文本经过预训练生成动态词向量,将得到的词向量信息作为BiLSTM层的输入进行双向训练,进一步提取文本特征。注意力机制主要对BiLSTM层输出的结果中提取对实体识别起关键作用的特征信息,对上层输出的特征向量进行权重分配,突出对实体识别起关键作用的特征,忽略无关特征。通过权重检查,直接评估哪些嵌入是特定下游任务的首选嵌入。最后通过CRF层可以有效地约束预测标签之间的依赖关系,对标签序列进行建模,从而获取全局最优序列。
算法描述如下:
输入:中文语句文本
输出:中文文本预测标签
算法步骤:
(1)将输入的文本分解成对应的字序列;
(2)将字序列输入到BERT模型中,经过双向Transformer结构,得到字符特征向量;
(3)BiLSTM层通过双向LSTM计算输入隐藏信息;
(4)Attention层对BiLSTM层输出的特征向量进行权重分配;
(5)利用CRF层,使用Viterbi算法对BiLSTM层输出进行解码,求解最优路径,获取文本标签。
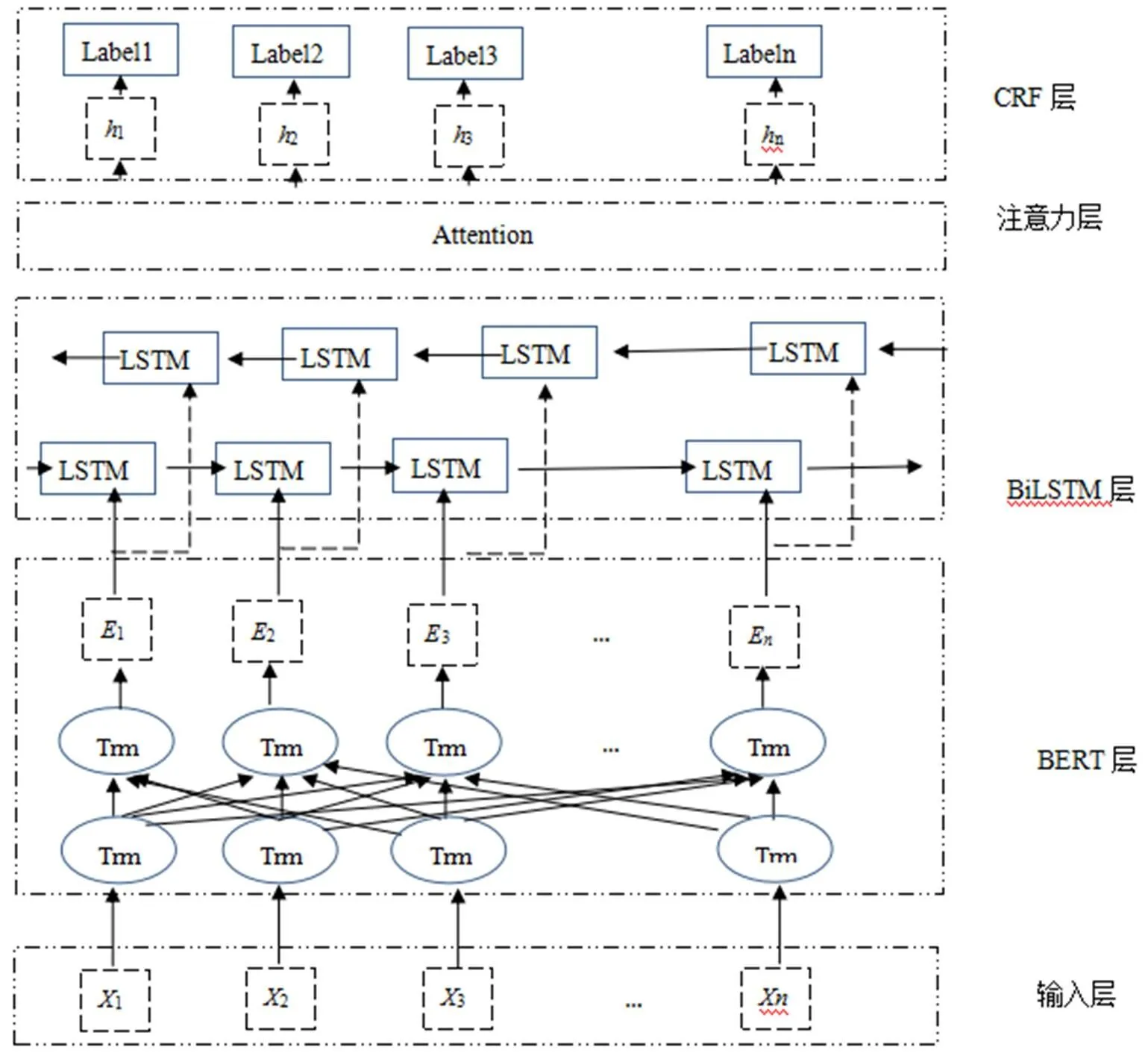
图1 BERT-BiLSTM-MHA-CRF模型框架
1.2 BERT模型
自然处理处理中,将文本信息转化为相应的词向量嵌入到模型中,是自然语言处理中的一个重要任务。比较常用的语言模型,如one-hot、Glove、Word2Vec和GPT等模型,这些模型训练出来的词向量属于静态向量,无法解决一词多义的问题,如“快快长大”和“马路长3米”这两句话中,“长”字表达的含义完全不同,但在传统的词向量语言模型中,2个“长”字向量值完全相同。GPT语言模型属于单向模型,能够表示一词多义,但是无法获取词的前后文信息。
2018年Goolge团队结合不同语言模型的优点,提出BERT模型。BERT模型一方面采用双向Transformer神经网络作为编码器,对下个字的预测可以参考前后双向的输入信息。另一方面,采用“MASK语言模型”来进行模型预训练,将句子中的15%的词语掩盖,通过上下文的内容来预测被掩盖的词。因此,BERT模型具有很强的语义获取能力和实体关系识别能力,同时能够有效解决一词多义的问题,迅速取得研究人员的关注。经过BERT模型训练输出的词向量由三部分组成,字向量、句向量和位置向量,如图2所示。

图2 BERT词向量
通过查找字向量表,将输入的字符转换为字向量形式。句向量表示句子中的语义信息,区分不同语句。位置向量可以区分不同语句中不同位置的字的语义信息,通过BERT预训练模型,可以获取含有丰富语义特征的文本序列向量。其中,[CLS]特殊标记表示为文本序列的开始,[SEP]特殊标记表示为句子间的间隔或文本序列的结束。
1.3 BILSTM模块
LSTM(Long-Short Term Memory)长短期记忆网络,是一种特殊的循环神经网络(RNN)。RNN网络主要包括输入层、隐藏层和输出层三部分组成,隐藏层连接前后两层,这种特殊的结构,能让RNN网络具有一定的“记忆”能力,能够有效处理命名实体识别任务。但随着处理文本序列长度增加,RNN网络可能存在梯度爆炸现象,影响模型运行效果。
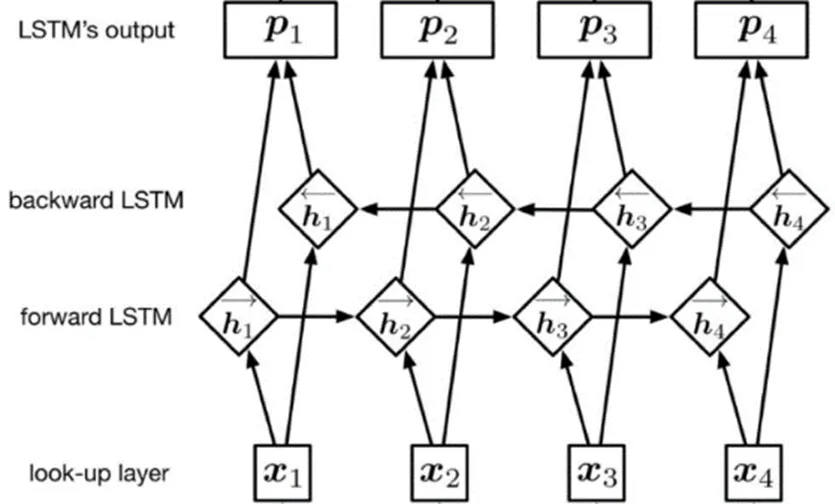
图3 BiLSTM结构图
单向LSTM只能考虑文本序列中的前向信息,无法处理后向信息。在自然语言处理中,将文本信息切分为单个词,每个词与前后词之间都存在一定的关联性,因此对实体的识别必须考虑上下文的关系。为了提高模型适应性,文章采用BiLSTM模型,模型结构如图3所示。
1.4 注意力机制
注意力机制类似于人类视觉机制,观察物体时,一般关注物体的重要部分,而忽略不相关的细节信息。本文中,注意力机制主要对BiLSTM层输出的结果中提取对实体识别起关键作用的特征信息,对上层输出的特征向量进行权重分配,突出对实体识别起关键作用的特征,忽略无关特征。注意力机制模型的运用,可以通过权重检查,直接评估哪些嵌入是特定下游任务的首选嵌入,从而提高模型整体效果。对于时刻模型经过注意力机制加权后的输出,如式(1)所示。
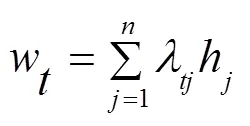
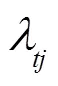
自注意力机制在文本系列中完成注意力的计算,寻找文本序列中的内部联系。将文本中的每个词同时作为query, key, value,将每个词和句子中的所有词进行对比。计算两两词之间的关系,从而归一化得到权重,最后再用整个句子的所有单词的词向量的加权平均作为这个词的新的词向量,遍历一次从而完成句子中词向量的更新,自注意力机制模型仅仅与词向量本身有关,与词间距离无关,一定程度上克服BiLSTM层的距离依赖问题(图4)。
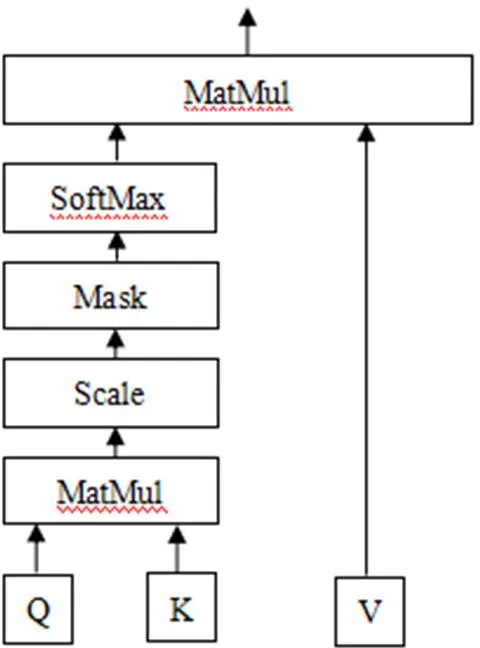
图4 自注意力机制结构图
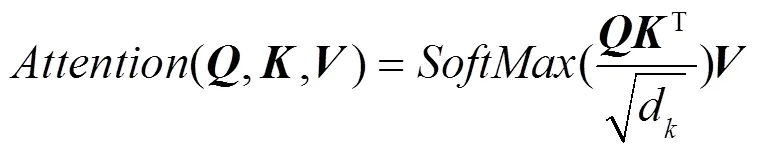
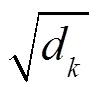
1.5 CRF层
CRF模型是一种经典的判别式概率无向图模型,该模型主要应用于自然语言处理的序列标注任务中,在序列标注任务中,相邻的字或词的标要遵循一定的规则,比如I标签前面是B标签,不能是O标签,I-LOC不会跟在B-PER后面等等。CRF层可以有效地约束预测标签之间的依赖关系,对标签序列进行建模,从而获取全局最优序列。
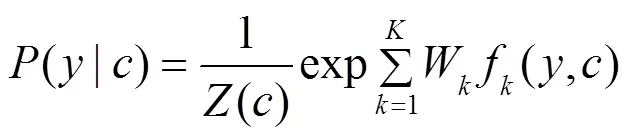
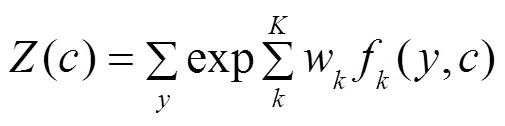
BiLSTM模型可以有效处理长距离的文本信息,对输入序列中的上下文的信息进行建模学习,计算每个标签的具体分值,选取最大得分值作为输出标签。但是BiLSTM模型无法处理相邻标签的依赖关系,导致输出的标签无法组成完整的实体,不能作为模型的预测结果。
在中文文本实体识别过程中,多头注意力机制没法考虑标签之间的依赖关系,比如“I-ORG”标签不能紧接在“B-PER”标签后面。CRF层可以有效地约束预测标签之间的依赖关系,对标签序列进行建模,从而获取全局最优序列。
使用最大化对数似然函数对CRF模型进行训练,通过式(5)和(6)计算在给定句子的情况下标签序列的条件概率,其中,y为给定的句子全部可能的标签序列,为定义的损失函数。
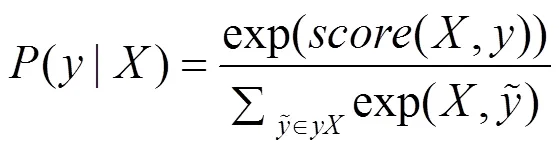
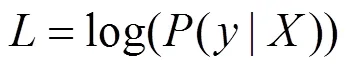
在CRF模型预测过程中,采用Viterbi算法来求解全局最优序列,如式(7)所示,其中为集合中使得分函数取得最大值的序列。
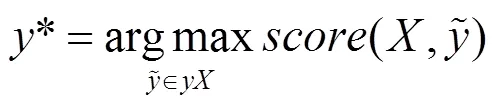
2 实验结果分析
2.1 实验数据集
本文实验采用的数据集是国内公开评测的中文数据集,分别是微软亚洲研究院的MSRA语料库和人民日报语料库。两个数据集中包括了3种实体,分别是人名(PER)、地名(LOC)和组织机构(ORG)。
2.2 数据集标注及评价指标
中文实体命名标注体系常用的有BMES、BIO和BIOES,本文选用的是BIO标注体系。B-Entity代表实体的首字符,I-Entity代表实体的中间部分,O-Entity代表非识别实体。具体标注示例见表1。本文选择精确率(Precision)、召回率(Recall)和1值对模型评价,3种评价指标越高,代表模型性能越好。

表1 标注示例
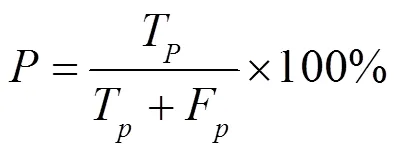
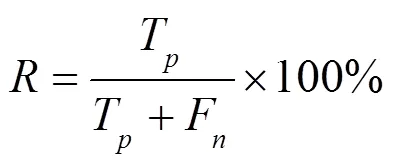
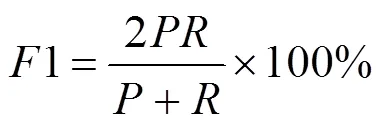
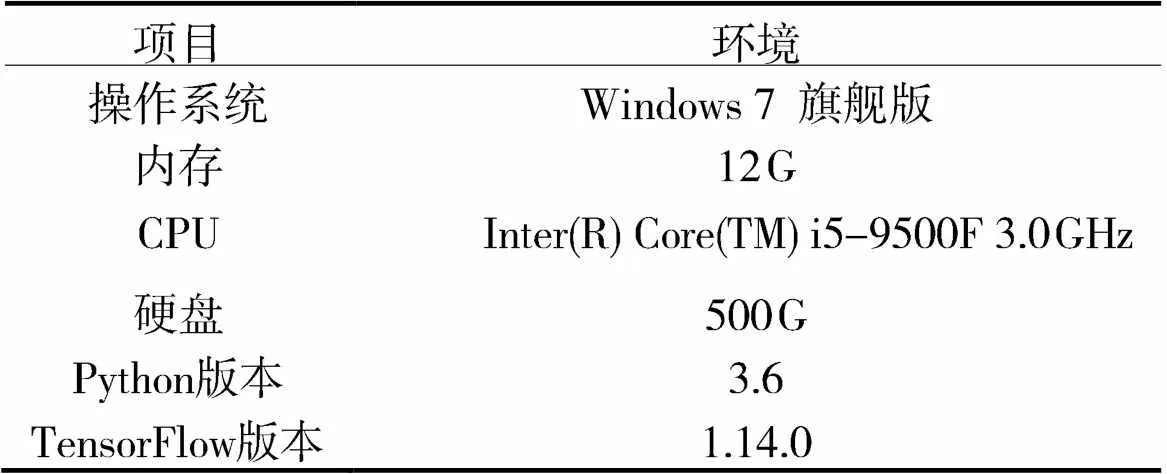
表2 训练环境设置
2.3 实验环境和参数
实体识别模型实验基于TensorFlow框架,具体实验环境设置如表2所示。
通过表3和表4,可以发现BiLSTM-CRF模型在人民日报语料库和MSRA语料库的1值分别比LSTM-CRF模型高出2.66%和1.14%,表明BiLSTM模型获取前向和后向文本信息,文本实体识别效果优于LSTM模型。BiLSTM-CRF模型在人民日报语料库和MSRA语料库的1值分别比BiLSTM模型高出2.01%和1.89%,表明CRF模块能够有效提高模型识别效果。因为CRF层可以有效地约束预测标签之间的依赖关系,对标签序列进行建模,从而获取全局最优序列。
IDCNN-CRF和BiLSTM-CRF模型在人民日报语料库的1值分别为86.48%和86.98%;在MSRA语料库上的1值分别为86.48%和88.40%,说明这两种模型的识别效果比较接近。IDCNN-CRF模型并行处理能力要优于BiLSTM-CRF模型。
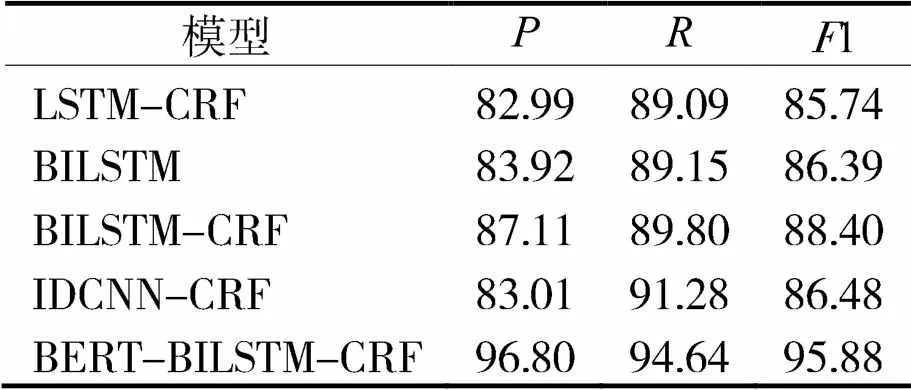
表3 人民日报语料测试结果 %
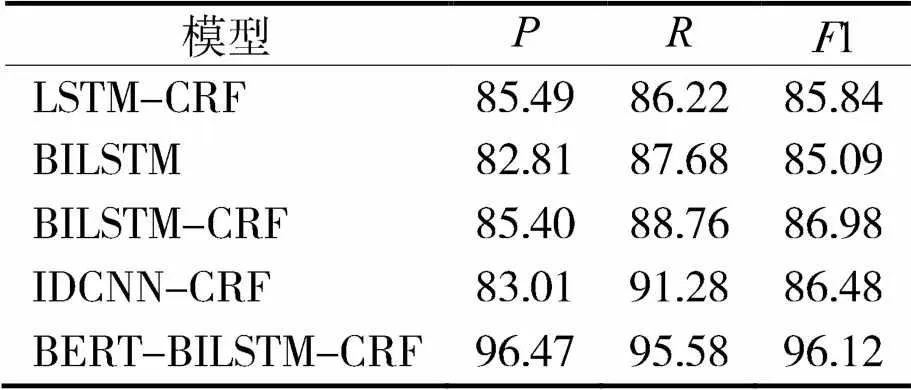
表4 MSRA语料测试结果 %
为了获取更强的语义信息,采用Google的BERT预训练模型,将经过BERT预处理的词向量作为BiLSTM模型的输入信息,实验结果有了很高的提升。在人民日报语料库和MSRA语料库的1值分别达到95.88%和96.12%。和BiLSTM-CRF模型相比,分别提升7.48%和9.14%。因为Bert模型具有很强的语义获取能力,能够充分表征字符级、词级、句子级和语句之间关系的信息,经过BERT模型预处理后,训练出来的词向量能够处理不同语境中的语法和词语信息,增强模型泛化能力,进而提高实体和实体关系识别和提取的能力。
3 结束语
中文文本实体识别,是自然语言处理的关键问题。传统的语言处理模型无法有效表示文本中的上下文语义信息,无法处理一词多义的不同语境,影响实体识别效果。本文提出一种BERT-BiLSTM-CRF的实体识别模型,BERT层作为模型嵌入层,将输入文本生成生成表征上下文语义信息的词向量,解决语义消岐问题,通过BiLSTM网络对生成的向量进行特征提取,自注意力机制捕获文本序列中单词间关系及距离依赖,选择性的关注重要部位权重信息,最后通过CRF进行解码生成实体标签序列。实验结果表明,该模型在微软亚洲研究院MSRA语料库和人民日报语料库上都取得了优异成绩,1分别达到96.12%和95.88%。对比实验结果表明,本文提出的模型在所有的对比模型中各方面的性能为最优。下一步的工作,一方面是简化模型结构,提升模型训练速度,另一方面是将模型应用到其他领域,完成相应的自然语言处理任务,提高模型的适应性。
[1] 张栋,陈文亮. 基于上下文相关字向量的中文命名实体识别[J]. 计算机科学,2021, 48(3): 233-238.
[2] HUMPHREYS K, GAIZAUSKAS R, AZZAM S, et al. University of Sheffield: Description of the LaSIE-II system as used for MUC-7[C]//Seventh Message Understanding Conference (MUC-7): Proceedings of a Conference Held in Fairfax, Virginia, 1998: 1-20.
[3] COLLINS M, SINGER Y. Unsupervised models for named entity classification[C]//1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. 1999.
[4] BIKEL D M, SCHWARTZ R, WEISCHEDEL R M. An algorithm that learns what's in a name[J]. Machine learning, 1999, 34(1): 211-231.
[5] 乐娟,赵玺. 基于HMM的京剧机构命名实体识别算法[J]. 计算机工程,2013, 39(06): 266-271, 286.
[6] 陆铭,康雨洁,俞能海. 简约语法规则和最大熵模型相结合的混合实体识别[J]. 小型微型计算机系统,2012,33(03): 537-541.
[7] BENDER O, OCH F J, NEY H. Maximum entropy models for named entity recognition[C]//Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003. 2003: 148-151.
[8] HAMMERTON J. Named entity recognition with long short-term memory[C]//Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003, 2003: 172-175.
[9] 高翔,张金登,许潇,等. 基于LSTM-CRF的军事动向文本实体识别方法[J]. 指挥信息系统与技术,2020, 11(06): 91-95.
[10] LAMPLE G, BALLESTEROS M, Subramanian S , et al. Neural Architectures for Named Entity Recognition[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016.
[11] 杨晓辉,毕雪华,张琳琳,等. 基于多任务的中文电子病历中命名实体识别研究[J]. 东北师大学报(自然科学版),2020, 52(01): 81-87.
[12] 陈美杉,夏晨曦. 肝癌患者在线提问的命名实体识别研究:一种基于迁移学习的方法[J]. 数据分析与知识发现, 2019, 3(12): 61-69.
[13] 朱顺乐. 基于深度学习的维吾尔语命名实体识别模型[J]. 计算机工程与设计,2019, 40(10): 2874-2878, 2890.
[14] 徐啸,朱艳辉,冀相冰. 基于自注意力深度学习的微博实体识别研究[J]. 湖南工业大学学报,2019, 33(02): 48-52.
[15] 崔丹丹,刘秀磊,陈若愚,等. 基于Lattice LSTM的古汉语命名实体识别[J]. 计算机科学,2020, 47(S2): 18-22.
[16] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[17] 岳琪,李想. 基于BERT和双向RNN的中文林业知识图谱构建研究[J]. 内蒙古大学学报(自然科学版),2021, 52(02): 176-184.
[18] 姜同强,王岚熙.基于双向编码器表示模型和注意力机制的食品安全命名实体识别[J]. 科学技术与工程,2021, 21(03): 1103-1108.
[19] 杜琳,曹东,林树元,等. 基于BERT与Bi-LSTM融合注意力机制的中医病历文本的提取与自动分类[J]. 计算机科学,2020, 47(S2): 416-420.
[20] 陈剑,何涛,闻英友,等. 基于BERT模型的司法文书实体识别方法[J]. 东北大学学报(自然科学版),2020, 41(10): 1382-1387.
[21] 赵平,孙连英,万莹,等. 基于BERT+BiLSTM+CRF的中文景点命名实体识别[J]. 计算机系统应用,2020, 29(06): 169-174.
Chinese entity recognition based on BERT-BiLSTM-CRF model
SHEN Tong-ping,YU Lei,JIN Li,HUANG Fang-liang,XU Huan-qing
(School of Medicine and Information Engineering, Anhui University of Chinese Medicine, Hefei 230012, China)
Chinese text entity recognition is a key problem in natural language processing. Traditional language processing models cannot effectively represent the contextual semantic information in text and cannot handle different contexts with multiple meanings of a word, which affects the effect of entity recognition. In this paper, we propose a BERT-BiLSTM-CRF entity recognition model , in which the BERT pre-processing language model generates word vectors that represent contextual semantic information, and through bidirectional long short term memory. The generated vectors are extracted by a bidirectional long short term memory network, and the Self-Attention mechanism can effectively capture the long-range dependencies in the text utterances, and finally the entity label sequences are decoded by CRF. The experimental results show that the model achieves excellent results on both the Microsoft Asia Research Institute MSRA corpus and the People's Daily corpus, with F1 reaching 96.14% and 96.88% respectively.
named entity recognition;deep learning;multi-head attention;BERT
2021-07-21
国家自然科学基金项目(61701005);2019年高校优秀青年骨干人才国外访学研究项目(gxgwfx2019026);安徽省质量工程项目(2017mooc223,2020jyxm1029);安徽高校自然科学研究重点项目(KJ2020A0443);安徽中医药大学教研项目(2017xjjy_yb010);安徽中医药大学质量工程项目(2021zlgc046);安徽中医药大学自然重点项目(2020zrzd18,2019zrzd11,2018zryb06)
沈同平(1986-),男,安徽无为人,副教授,硕士,主要从事中医药信息化研究,shentp1986@126.com。
TP391
A
1007-984X(2022)01-0026-07
