基于二叉树结构采样预估的召回模型框架
2022-11-22靳甲广
靳甲广?

摘要:在广告或者推荐系统的召回阶段,通常会包含百万到亿级别的候选集,采样和预估就成为很重要的问题;传统的召回模型会做随机负采样,这种方法采样的数据分布和整体样本分布可能存在不一致,影响模型训练效果,在预估服务时线上infer性能也是严峻的考验;针对这两个问题,我们提出了基于树结构的采样预估服务,把全量候选集通过层次聚类构建到一颗二叉树中,所有物料挂在的树的叶子结点,通过二叉树采样可能无偏的来到所有物料,并且线上infer时间复杂度从O(n)降低到O(log(n)),整体提升了模型训练效果和预估时间开销。
关键词:召回模型,广告系统,推荐系统,二叉树
一、背景介绍
在多阶段广告系统中,召回技术的任务是从百万-亿量级的全库候选广告集合中挑选千级别的优质广告,供给粗排和精排进行更高精度的广告候选集挑选。
当前人们普遍认同召回技术已经发展了两代,并正向第三代新技术的发展进程中:
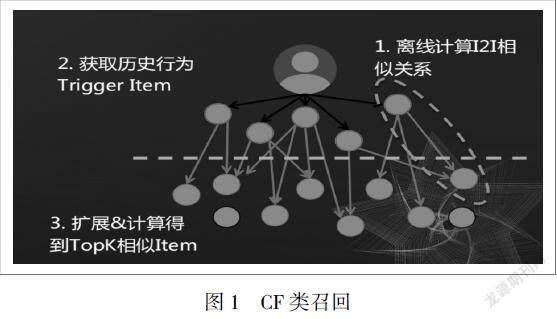
第一代:启发式规则召回技术,例如基于ItemCF的U2I2I召回,召回用户访问过的广告的相类似广告。
优点是实现简单,推断高效。实现为两阶段:
1.用户的历史行为(点击、购买等)获得触发广告(Trigger Item)。
2.在候选广告集中检索与触发广告最相似的广告。相似度可以离线预先计算好。
缺点是:
1.不是全库,而是针对历史行为相关的相似广告集合被召回,新颖性不够,对冷启动不友好。
2.模型过于简单,精度有限,泛化能力不够。
3. 两阶段实现,无法实现联合优化,影响效果。
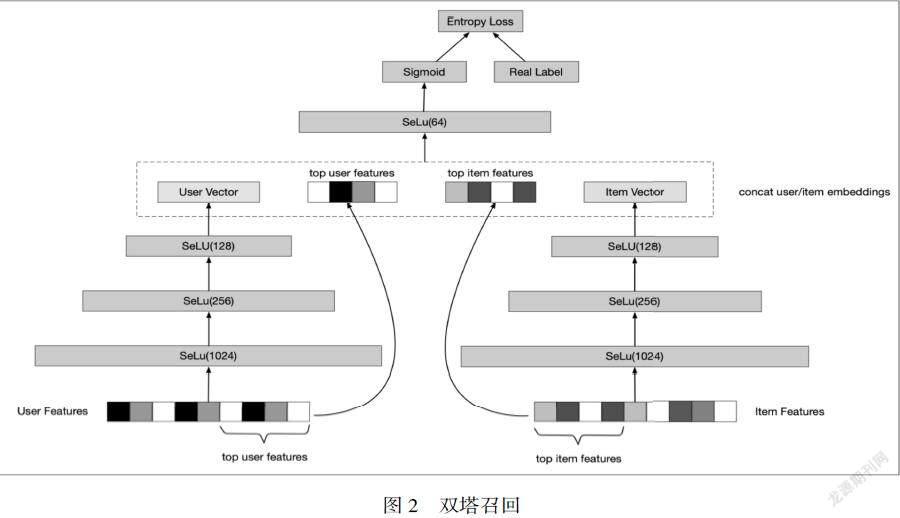
第二代:基于Embedding的向量内积召回模型。广告的检索变成了用户embedding向量和广告embedding向量的内置。它的优点是实现为双塔结构,借助ANN可以实现全库近似计算,或者使用GPU实现全库暴力算。
1.一阶段端到端模型训练,把用户和item的各种辅助学习表示成统一空间的向量表示,精度提高,泛化性更好。
2.用户和item的向量可以准实时计算和更新,实时性更好
虽然以全量暴力算为代表的双塔模型在广告业务中取得了很多收益,但是它的缺点也是很明显:双塔建模中用户和item特征没有价差,向量内置的计算score的方式导致模型表达能力有限。虽然使用MLP能获取的进一步收益,但它比更多的attention或者复杂模型表达能力要差不少。
未来的先进模型召回技术必须满足以下核心诉求:
1.检索效率高:在线推断能够针对全库召回:能对候选广告集合进行全量检索,提高召回技术的效果天花板。
2.模型表达能力强:能够克服双塔模型结构的缺陷,提高召回的泛化性。
3.一致性:選出的广告能被后端的粗排和精排也认为优质。
在现有算力约束下,模型表达能力可能制约和限制召回模型的检索效率。如果模型复杂度增加,表达能力变强了,可能使得能够检索的物料范围受到限制。因此,只有改进检索效率,才能有提高模型表达能力的先决条件。
二、召回树模型框架
(一)什么是召回树模型
顾名思义,召回树模型是采用树作为提高检索效率的索引结构,同时使用一般深度学习模型取代常用的双塔模型结构提高模型的表达能力。
树模型把全库的广告候选集自底向上构建一颗二叉树,叶子节点代表全库的广告候选集,中间节点是虚拟节点,代表了满足一定特性的广告子集的聚类。
使用二叉树后,数模型的检索效率由O(N)提高到O(logN)。检索包含1亿个候选广告的集合只需要27步计算。
(二)类最大堆树 Max-heap like tree
类最大堆树是召回数模型的一个发明,它保证了树的检索是可以通过采样beam search的方法获得top-k的最优候选广告集。
类最大堆树脂的是一棵树,它的第j层的中间节点 nj 被给定用户 u 感兴趣概率 P(nj |u )由它的子节点(即第 j+1层的节点)的最大值确定。
检索时,只需要从根节点开始,找出p(n|u)的所有子节点进行概率计算,排序后选取top-k个节点继续检索,直到找到top-k个叶子节点,作为最后的召回结果。
有了类最大堆的性质,可以保证这种检索方法得到的top-k结果必定是全局最优的top-k结果,即使用更少的检索代价达到了全库检索的效果。
(三)召回树模型的初始化和模型训练
召回树的初始化过程是使用类目信息完成的:时候选集的物料的类目排序,相同的类目放在同一桶里随机排序,然后把这些分桶的物料进行二分。此过程循环,直到每个二分里只剩下一个物料。最终结果是一颗自顶向下构建的近似或完全的二叉树。
召回树模型的训练是一个类似EM的算法:
1.构建一个初始二叉树,在树上训练模型直到收敛。
2.通过叶子节点的embedding重新构建一颗新树。
3.使用新构建的树训练收敛的模型。
重复2、3步骤,不断dump出模型放到线上推断,具体算法入Algorithm 1。
三、How:实现与实践
(一) 系统结构
主要部分:
1. Embedding Producer (Photo Emb Server):产生Photo Embedding。
2.Tree Calc Server: 根据Embedding Producer构建全量和增量的召回树。
3.Offline Tree Server:服务模型训练负采样的Tree Server。
4. Online Tree server/Predict Server:用于召回服务的在线推断。
5. Embedding Server:存储User/Item的Embedding。
6.离线模型训练/Dragon负采样。
(二) 召回树的构建
在实践过程中,召回树的构建与论文实现不同,而是结合快手主站、特别是商业化的业务特点进行改造。
1.建树过程
在召回树的构建上,建树的过程如下:
(1)Embedding Producer使用已有的线上双塔模型,加载DSP的物料库,每个一定周期(例如15分钟)产生全库物料的Embedding,并聚合层photo粒度。
(2)Calc Tree server通过BTQ监听Embedding Producer产生的Embedding变化,并通过gRPC向Item Service获取creative_id对应的Photo Service。
(3) Calc Tree Server 每天构建一个全量的召回树,并在一定周期(1小时或者15分钟)内增量更新树。
(4)通过BTQ,Offline Tree Server和Online Tree Server获得最新的召回树,并分别进行离线和在线的模型训练与推断。
2. K-means建树
在构建树的过程中,使用K-means算法对Embedding进行完全二叉树的构建。大致流程如下:
(1)使用K-means算法对所有的Embedding进行聚类,得到两个类,分别对应left tree和right tree。
(2)使用平衡算法,使得左右两棵树的物料一样多。
(3)分别对left tree和right tree进一步进行聚类并执行平衡算法,每棵树得到left子树和right子树。
(4)重复步骤(3),直到每棵子树只包含一个或两个节点停止。
k-means建树之后,还需要进行两步处理:
(1)把物料对应的都节点都下发到叶子节点;
(2)根据叶子节点更新中间节点的信息,例如生成中间节点的虚拟ID特征,虚拟统计信息(例如子节点的click数的平均值作为中间节点的click树)。
对于增量建树,广告动态插入到树中,并从根节点开始依次寻找最相似的中间节点插入,直到倒数第一层,作为叶子节点插入到召回树中
3. 树的采样
在离线的模型训练中,召回树模型与一般模型训练的差别在于树的采样:从在线数据流中读取到训练样本依次经过以下过程:
(1)从样本得到样本的label。当前采用多标签Label,例如 未下发、下发未曝光、下发并曝光、曝光并点击的样本的label
(2)使用负采样Processor把样本通过gRPC服务调用offline Tree Server接口对样本进行采样。
(3)使用特征抽取的Processor对负采样processor返回的数据进行特征抽取。
(4)抽取后的特征发送给训练平台进行在线模型训练。
四、结束语
综上,召回树模型可以有效的提升训练采样样本和真实分布一致性,引入更多的真实和虚拟节点样本训练模型,使得模型学习更充分无偏,并在在线预估时提升整体性能。
作者单位:靳甲广 北京快手科技有限公司
參 考 文 献
[1] Jui-Ting Huang. Embedding-based Retrieval in Facebook Search, KDD 2020,Facebook
[2] Han Zhu. Learning Tree-based Deep Model for Recommender Systems,Alibaba
