融合时间信息的音乐推荐算法研究
2022-11-22李宏滨
周 欢,李宏滨
(太原师范学院 山西 晋中 030619)
0 引言
随着科技的发展和时代的进步,互联网信息和电子音乐网站井喷式增长,音乐资源变得越来越丰富,但是各种音乐没有被有效整合,导致人们信息过载,不能够第一时间找到自己喜欢的音乐。这时候音乐推荐算法的出现对于音乐网站来说就显得至关重要,它整合了原本丰富但混乱的音乐资源,使用户能够更快地找到自己喜欢的歌曲,同时也让音乐网站获得了远超以往的收益和流量。一般来说,音乐具有以下特征:音乐时间长短,使用者可以反复聆听相同的歌曲,并且流行的歌曲也会很快更新,音乐的这个特征使得它非常适合使用推荐系统来进行推荐。推荐系统能够从海量的数据资源中快速找到用户的喜好,然后根据用户的喜好推荐符合用户喜好的各种资源[1]。音乐推荐系统能够根据使用者的在线行为特征,对用户的潜在目标进行挖掘,这是一种被动的、无须使用者主动参与的方式,这种方式会给用户带来更好的体验[2]。当前主流的推荐方法大多是基于用户的历史听歌记录进行推荐,但是这种推荐方法通常不够精确,并且存在一定的延迟。所以能够更加精确地推测用户的意向和兴趣,并及时将其推荐给目标用户,是目前音乐推荐系统的发展方向[3]。本文以音乐平台的用户为研究对象,将用户的音乐偏好动态变化与时间信息相结合,由此提出一种融合时间信息的音乐推荐算法,并最终得到一个更加准确的符合用户音乐偏好的推荐列表。
1 问题建模
音乐推荐需要充分考虑到用户的听歌偏好,而用户的音乐偏好又会随着时间而变化[4],针对此问题,本文选取用户最近的音乐播放记录来反映用户在这个时间段的音乐偏好,并通过时间效应函数来模拟用户音乐偏好的不断变化。不仅如此,在不同的季节,人们会喜欢不同种类的歌曲,所以音乐也具有一定的季节周期性,本文由此构建了音乐季节敏感函数,然后将两个与时间信息相关的函数融合加权,得到一个新的加权模型。将得到的加权模型赋予用户-歌曲评分,获得新用户-歌曲评分,在这个基础上进行用户相似度的改进并预测评分,最终得到融合时间信息的音乐推荐列表。融合时间信息的音乐推荐模型如图1所示。
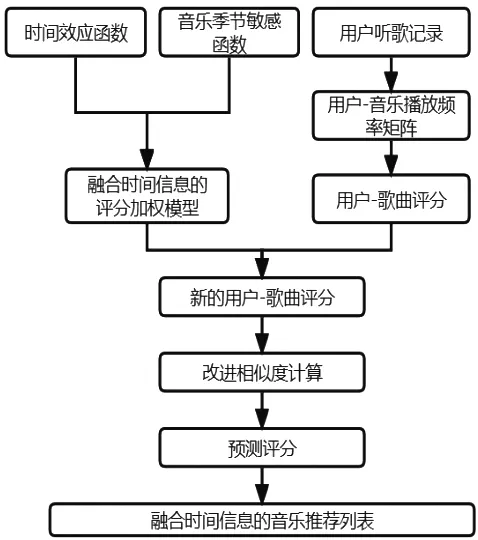
图1 融合时间信息的音乐推荐模型
2 融合时间信息的协同过滤算法
个性化推荐系统的关键在于基于用户过去的互动来建模用户对物品的偏好,这被称为协同过滤。协同过滤推荐算法主要包括基于用户和基于项目两种协同过滤算法,基于用户的协同过滤算法主要包括三个阶段。首先要进行相似度计算,其次是用户最近邻搜寻,最后预测评分并生成top-N推荐[5]。
2.1 用户-音乐评分
由于用户不会特意去对自己喜欢的歌曲进行评分,而是通过不断的循环播放同一首歌曲来表达自己对此歌曲的喜爱,由此推断,如果一首歌曲有很高的播放次数,就表明这首歌曲是用户喜欢的,可给予较高的评分。本文通过对用户播放歌曲的频率进行统计,用户每播放一次歌曲就对这首歌的偏好值加一,按照这样逐个累加,可以得到一个表示用户-音乐播放频率的矩阵。但是直接用一首歌曲的播放频率来反映用户对这首歌的评分并不合适。如果一个用户对某首歌播放的次数过多,就会造成歌曲评分过高,相反则评分过低。所以,为了使用户对歌曲的评分更加准确,本文将非线性关系导入,用来描述用户对一首歌曲的偏好和这首歌曲的播放频率,并使用式(1)将用户-音乐播放频率转换成用户-音乐评分:

其中:e为用户-音乐的偏好评分,c为用户x对歌曲i的播放频率,a、b为公式中的调节系数,取值范围为0~5。
2.2 融合时间信息的评分权重模型
用户对音乐的偏好会随着时间而改变,而最近一段时间内的听歌记录能更好地体现用户近期的音乐偏好。在上下文信息中,最重要的就是时间信息,它对用户的兴趣有很大的影响,对于一个系统的推荐准确度也相当重要。由于用户自身原因,随着时间的变化,其偏好、兴趣也发生了改变。这个改变对于一个推荐系统在推荐的准确度上有着极大地影响,而传统的模型并没有很好地运用这条信息,对这个问题并没有深入的研究。本文用指数函数拟合艾宾浩斯遗忘曲线作为时间效应函数[6],用来表示用户对音乐的偏好随时间的变化而变化,拟合后的公式如下:

其中ti表示用户当前时间听歌与其最后听歌i的时间差,单位是天。
音乐还存在特殊的季节周期性[7],在不同的季节人们的确是会喜欢不同的音乐。从Google Trends和百度指数两个搜索引擎从2006年到2011年的月度数据中,可以非常明显地发现对于电子乐、流行乐、摇滚乐、古典乐,最受欢迎的季节是不一样的[8]。听音乐,也与当时的环境有关,同样的音乐在不同的环境下会有完全不同的感受。在某些日子里,天气的变化会把我们从一种音乐的气氛带到另一种环境。据此本文构建了音乐季节敏感函数如下:

其中,kis表示音乐i对季节s是否敏感,若敏感,则Kis为1,不敏感,则为0。S的取值范围为1~4,以此来表示一年四季,本文通过加权的方式后将得到的两个与时间信息相关的函数相结合,结合后的模型公式如下:

其中,Wi为融合时间信息的用户-音乐评分权重,a为权重因子。
2.3 改进用户相似度计算
在推荐系统中,一般思路是先进行合理的数据处理,再计算相似度,从而得出结果。首先需要获取用户或物品的数据,并同构合理的表示函数来构造用户或物品的Embedding,之后计算用户之间的相似度。余弦计算法没有考虑到不同应用对象的评价尺度不同,造成推荐的结果不够精确。所以本文选用皮尔逊相关系数进行相似度改进,皮尔逊相关系数只通过共同评分项目进行用户相似度计算,并加入了用户平均分对各独立评分进行调整,降低了用户评分偏置的影响[9]。首先将融合时间信息的评分权重Wi赋予用户-音乐评分x,i得到新的用户-音乐评分:

得到新的相似度计算公式如下:
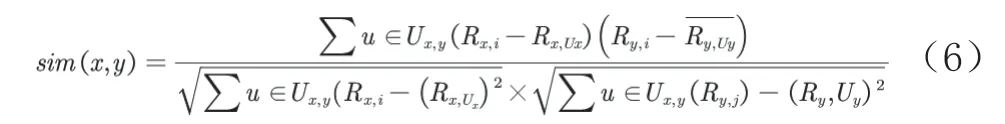
其中,Ux,y表示Ux和Uy评分过的合集,Rx,i和Ry,i分别表示用户x和用户y对项目i的评分,Rx,Ux表示用户x对所有物品的平均评分,同理Ry,Uy表示用户y对所有物品的平均评分。
2.4 预测评分
本文由得到的式(6)对用户相似度进行计算,并通过式(7),预测目标用户x对音乐i的评分:

其中,K表示式(6)中计算出来的目标用户x的近邻合集,Ry,i表示近邻用户y对音乐i的评分,sim(x,y)表示的是用户x和近邻用户y的相似度。最后,通过对得到预测评分进行排序就可以得到融合时间信息的音乐推荐列表。
3 实验
3.1 数据集
本文的数据集主要来自网易云音乐平台,通过对30个用户在最近这段时间内听的50首歌曲的采集,再利用平台自带的音乐播放频率统计功能,记录所采集的目标用户在30天中播放每首歌的频率和歌曲的具体信息,最终形成了包含用户-歌曲播放频率-时间的数据,之后进行数据预处理,对每个用户的歌曲播放频率处理后作为用户对音乐的评分,构建一个能够有效反应用户与音乐之间关系的矩阵,即用户评分矩阵。为了得到符合本文实验所需的数据集,本文将数据集记录的时间戳排序后按照4∶1的比例划分为训练集和测试集。
3.2 评价指标
本文选取精确率precision作为实验的评价指标[10],精确率越高,就表明改进后的推荐算法预测的音乐推荐列表可以更符合目标用户的需求。
precision计算公式如下:

其中Au表示用户u在测试集上偏好的音乐合集,Ru是推荐算法推荐给用户u的音乐列表。
3.3 实验结果及分析
利用改进后的协同过滤算法,本文得到一个目标用户的融合时间信息的音乐推荐列表,为了使实验结果更加有说服力,本文使用对比验证,将改进的推荐算法与传统的两种协同过滤算法UCF和ICF的推荐结果进行对比。本实验在训练本文改进的UCFT+模型时,设置了6个不同的目标用户的近邻个数取值{10,15,20,25,30,35}。观察当取不同值时模型的变化,寻找合适时能达到最高的准确率,计算后得到的precision值如图2所示。
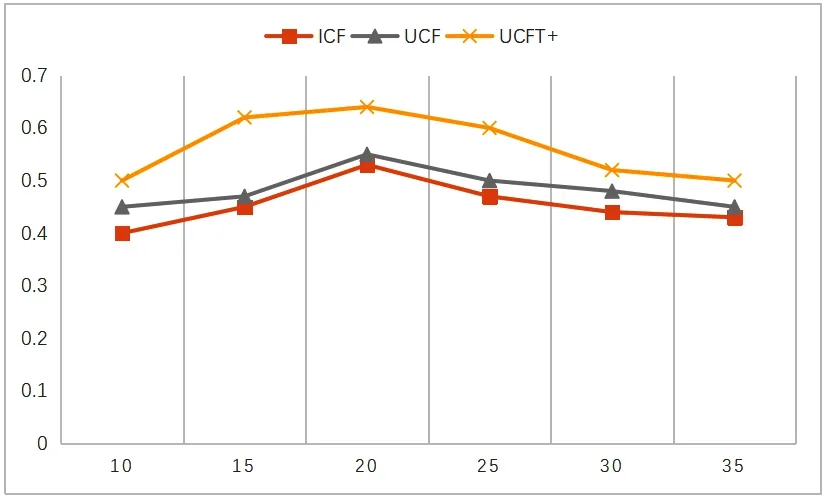
图2 三种算法的precision值比较
图2中横轴表示的是目标用户的近邻个数取值,纵轴表示的是推荐算法推荐的精确率,本文分别使用三种算法对推荐的精确率进行计算,如图中的计算结果显示,改进后的推荐算法精确率相比于其他两种确实有一定的提升,并且当近邻个数取值为20时,推荐算法的精确率precision达到最高值。所以,适当在推荐算法中考虑时间信息可以在一定程度上提高算法的精确率。
4 结语
随着音乐业务的快速发展,音乐种类正在变得越来越丰富,用户对音乐偏好的差异化也越来越大。在本文中提出了融合时间信息的音乐推荐算法,并通过实验数据表明,UCFT+可以一定程度上提高推荐算法的推荐准确性,它可以帮助用户更快、更准确地找到自己喜欢的音乐。对于未来的工作,本文希望能做到融合更多、更复杂的时间信息,以充分研究用户浏览音乐网站时,时间信息对推荐歌曲的影响。
