TensorFlow下基于CNN卷积神经网络的手写数字识别研究
2022-11-22陈群贤
陈群贤
(上海电机学院 上海 200240)
0 引言
手写数字识别在现实生活中应用范围非常广泛,如邮政快递的普通信息单、金融财务领域的数据统计、智能手机的手写输入法等[1],使得手写数字识别研究成了深度学习的研究热点之一。过去人们也提出了基于反向传播神经网络的数字识别方法、类中心欧式距离、贝叶斯分类算法等来进行手写数字识别,但效果不尽人意[2]。本文利用卷积神经网络来处理手写数字识别问题,卷积神经网络可以自己训练,自我修正模型参数,来达到良好的识别效果。
1 MNIST手写数字集
MNIST数据集是一个著名的手写体数据集,用于识别手写数字字符图像算法的性能评估。MNIST数据集由样本数为60 000的训练集和样本数为10 000的测试集组成,训练集包含训练字符图像文件和训练类别标签文件,测试集包含测试字符图像文件和测试类别标签文件。每个字符图像尺寸为28像素×28像素,每像素用1字节表示,标签为数字0~9[3]。
2 手写数字识别的卷积神经网络
2.1 卷积神经网络简介
卷积神经网络(convolutional neural networks,CNN)是人工神经网络(ANN)的一种特殊类型[4],主要用于计算机视觉和自然语言处理等领域。CNN由输入层、卷积层、池化层、全连接层和输出层组成。CNN主要有两个处理阶段:特征学习阶段和分类阶段,特征学习阶段通过卷积层和池化层结合来实现,这个阶段是从训练示例中提取最重要的特征,然后把这些提取的特征传送到全连接层,深度神经网络的最后一层往往是全连接层+Softmax分类网络,生成一个等于项目中所需要类的数量的分类器。
卷积神经网络中有多个卷积层,功能是对输入数据进行特征提取。卷积层由多个卷积核组成,其优点是先局部感知,然后在高层综合局部信息从而得到全局信息;卷积参数共享极大地减少了运算量;多个卷积核从多个视角提取图像信息[1]。卷积层后紧接池化层,池化层用于对输入的特征图进行压缩,使特征图变小,简化网络计算复杂度或进行特征压缩,提取主要特征。
2.2 手写字体识别的卷积神经网络结构
手写字体识别的卷积神经网络由输入层(inputs)、卷积层-1(conv-1)、池化层-1(pooling-1)、卷积层-2(conv-2)、池化层-2(pooling-2)、全连接层-1(fullc_1)、全连接层-2(fullc_2)、全连接层-3(fullc_3)和输出层(outputs)组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
2.2.1 输入层
输入层是CNN架构中的第一层,实现神经网络的输入。TensorFlow下基于卷积神经网络的手写数字识别要用CNN对28×28像素的黑白图像组成的MNIST数据集做数字分类,用 train_images=train_images.reshape(-1,28,28,1)重塑操作,输入层的形状变为[batch_size,28,28,1],其中batch_size是从原始训练集中选取的样本数量。
为了供卷积神经网络训练使用,输入层采用归一化方式对原始数据进行预处理。MNIST训练数据集共有60 000张图像数据,数据集图像维度为60000×28×28,标签维度为60 000×1,单张训练图像数据是28×28的二维数据,图像矩阵原始数据为0~255之间。输入层采用归一化的预处理方式将原始图像矩阵的数据都变为0~1的数据。单张图像标签数据表示图像数字如5。MNIST测试数据集共有10 000张图像数据,数据集图像维度为10 000×28×28,标签维度为10 000×1,单张测试图像数据是28×28的二维数据,图像矩阵数据为0~255。
2.2.2 卷积层
卷积层旨在学习输入数据的特征信息。卷积层由多张特征图(feature maps)组成,每张特征图的每个神经元与它前一层的局部感受野相连。为计算一个新的特征图,输入特征图首先与一个学习好的卷积核做卷积运算,然后将结果传递给一个非线性激活函数,通过应用不同的卷积核得到新的特征图,有更多的卷积核,意味着可以从图像中挖掘更多的特征。
卷积运算的主要目的是从图像中提取信息或特征,任何图像都可以看作一个数值矩阵,而矩阵中一组特定的数值可以构成一个特征。卷积运算的目的是扫描并尝试为图像挖掘相关的或可解释特征。如输入图像大小为n×n,过滤器大小为f×f,填充padding为p,步长为s,卷积运算后输出矩阵为:
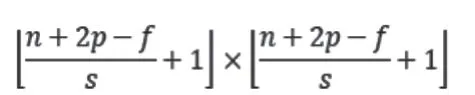
2.2.3 池化层
池化层旨在减少卷积步骤输出(特征映射)的维数,既缩减模型的规模,同时在新缩减的模型里保留重要的信息。池化层通常位于两个卷积层之间,每个池化层的特征图和其相应的前一卷积层的特征图相连,因此它们的特征图数量相同。池化运算是最大池化和平均池化,最大池化运算用得较多。
假设池化层的输入为nH×nW×nC,过滤器大小为f×f,填充padding为p,池化层很少用padding,因此一般设置p=0,步长为s,则池化运算后输出矩阵为:
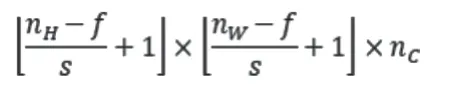
由于需要对每个通道都做池化,因此输入通道与输出通道的数量相同。
手写字体识别的卷积神经网络输入图像大小为28×28,conv_1为第一个卷积层,过滤器的形状为3×3,步长s=1,填充p=1,输出矩阵的形状为28×28。
pooling_1为第一个池化层,pooling_1层对conv_1层32个通道的28×28输出矩阵进行池化操作,池化核的形状为2×2(即f=2),步长s=2,则得到32个14×14的输出。
conv_2为第二个卷积层,有32个输入通道和64个输出通道,过滤器的形状为3×3,步长s=1,填充p=1,输出矩阵的形状为14×14。
pooling_2为第二个池化层,pooling_2层对conv_2层64个通道的14×14输出矩阵进行池化操作,池化核的形状为2×2(即f=2),步长s=2,则得到64个7×7的输出。
2.2.4 全连接层
全连接层将图像数据高度抽象为一维数组,经过两轮卷积层和池化层的处理之后,在卷积神经网络的最后,由3个全连接层来给出最后的分类结果。
从卷积层或者池化层到全连接层的过渡需要对输入“压平”的Flatten层,即把多维的输入一维化。fullc-1为第一个全连接层,该层输入为pooling-2池化层的输出,即7×7×64的节点矩阵,将该矩阵拉成一个向量,经过Flatten后的神经元个数为7×7×64=3 136。
Dense层的目的,是将前面提取的特征,在Dense经过非线性变化,提取这些特征之间的关联,最后映射到输出空间上。加更多的Dense,能更快地收敛。在手写字体识别的卷积神经网络中采用两层Dense层。fullc-2为第二个全连接层,是Dense层,该层输入为3 136个节点,输出为512个节点。fullc-3为第三个全连接层,也是Dense层,该层输入为512个节点,输出为10个节点,分别代表0~9这10个数字,每个神经元的激活值表示对应字符的响应强度,最大值则为对应的识别结果[5]。
3 Keras搭建手写数字识别的卷积神经网络
卷积神经网络理论框架搭建完成后,可以使用TensorFlow 2.0的高层封装接口Keras搭建具有预测功能的卷积网络。Keras可以搭建完整周期的模型,即新建神经网络、配置损失函数与优化器、训练神经网络、保存网络参数及日志文件、载入神经网络参数、神经网络预测。
3.1 搭建手写数字识别的卷积神经网络
手写数字识别的卷积神经网络使用Sequential外置序列化搭建网络结构 。使用keras新建神经网络,返回神经网络model实例的伪代码如下所示:

#通过add方法依次添加卷积层-1、最大池化层-1、卷积层-2、最大池化层-2、
全连接层-1、全连接层-2、全连接层-3
#配置损失计算及优化器
#展示网络结构,输出模型各层的参数状况
return model
通过add方法依次添加卷积层-1、最大池化层-1、卷积层-2、最大池化层-2、全连接层-1、全连接层-2、全连接层-3,通过summary方法获取了卷积神经网络的结构和参数。
采用compile方法配置训练神经网络的优化器、损失函数和衡量指标。损失函数用于计算神经网络输出值与标签值的差值,并作为神经网络优化的目标函数。神经网络参数配置代码如下所示:

optimizer:损失函数优化器,选择Adam优化器;loss:计算神经网络输出值和标签值的损失,选择交叉熵函数;metrics:训练和测试过程中评估的指标列表,通常使用accuracy,accuracy(准确率)是机器学习中最简单的一种评价模型好坏的指标。
3.2 训练手写数字识别的卷积神经网络
手写数字识别的卷积神经网络搭建好后,训练神经网络得先载入数据,通过TensorFlow提供的读取工具,获取MNIST手写字体数据集的训练图像和训练标签。
训练数据准备好之后开始训练。训练神经网络包括模型训练和模型保存两个过程。卷积神经网络训练过程的代码如下:

其中,model:神经网络实例;inputs:输入数据;outputs:输出数据;model_path:模型文件路径;log_path:日志文件路径;epochs:模型训练次数;callbacks:回调函数,用于训练过程中执行保存模型、保存TensorBoard文件;verbose:训练模型的输出日志格式,0只显示保存模型,不显示训练过程。
3.3 卷积神经网络训练结果分析
卷积神经网络的手写数字识别采用MNIST数据集中60 000个样本作为训练集,训练结果的损失函数和预测精度值在TensorBoard中以标量结果展示,如图1所示。从损失函数的标量数据图可知,曲线拟合预测值与实际值的偏差随训练的进行逐渐减小,并最终稳在一定误差范围内,说明损失函数逐渐收敛,模型预测准确度逐渐提高:而预测精度曲线则表示模型的预测精度逐步提高,并最终稳定在95%~100%之间。

图1 损失函数和预测精度标量图
为了找到合适的训练参数,实验中通过不同的训练次数获取对应的损失值和预测精度值如表1所示,从表中可见训练次数选择30次比较理想。

表1 不同训练次数下损失值和预测精度值
3.4 手写字体识别神经网络
神经网络训练结束并保存训练模型后,使用训练模型预测结果。预测过程分为载入训练模型和预测结果两部分,首先卷积神经网络载入最新版本模型的参数,然后将图像数据输入到神经网络中完成预测。
手写字体识别神经网络训练完成后,使用训练完成的模型预测测试图像数据,通过预测结果与原始手写字体数据集标注的标签对比,评估模型预测质量。本次测试使用MNIST手写字体数据测试集的10 000张图片,将这10 000张图片图像数据输入到神经网络中,predict对输入的数据进行预测,获取神经网络预测矩阵如下所示。

对所获取神经网络的预测矩阵进行argmax运算后得到预测值:[7 2 ......],在测试集中图像代表的数字分别为:7、2、......。
使用混淆矩阵方式来展示预测结果,列表示标签值,行表示预测值,标签值和预测值组成预测数据统计量的坐标,坐标的数据为标签值和预测值一致的个数。在混淆矩阵中,所有数据之和为10 000,即混淆矩阵的数据之和为预测数据个数,对角线的数据表示标签值与预测值相同,结果分析使用对角线数据。手写字体预测混淆矩阵如表2所示,正确率为 98.8 %。

表2 手写字体预测混淆矩阵
预测结果表明,卷积神经网络用于识别手写数字准确率最高可达98.8%,进一步证明了该方法用于识别手写数字的可行性,具有鲁棒性强的优点,解决了人工处理大量数字的问题,具有很好的研究价值。
4 结语
本文研究了卷积神经网络算法,并将此算法应用于识别手写数字中。首先设计了手写字体识别的卷积神经网络理论框架,然后使用TensorFlow 2.0的高层封装接口Keras搭建了具有预测功能的卷积网络,最后对MNIST测试集中的手写数字进行了预测。预测的结果显示卷积神经网络方法在准确方面优于传统方法,在运行效率和鲁棒性方面也优于传统方法。
