非结构化数据处理系统的设计与实现研究
2022-11-22吴文蔚
吴文蔚
(山西职业技术学院 山西 太原 030006)
0 引言
随着大数据时代的来临,海量数据存储成了信息化技术发展所重点关注的问题,其中非结构化数据占到了总数据量的一半以上。非结构化数据指的是无法用二维关系直接表示的数据信息[1],与结构化数据相比,具有数据容量大、数据来源更加丰富、数据产生速度快等特点[2],这使得非结构化数据的增量要远远高于结构化数据,因此非结构化数据成了数据处理中的主要组成部分。
非结构化数据的处理存在的关键性问题主要包括两个方面,一是数据类型不一致,使其很难用统一的数据格式标准进行描述与操作;二是传统的关系型数据库无法满足非结构化数据的存储需求。针对上述问题,本研究提出了MapReduce与Hadoop数据库(Hadoop Database,HBase)技术相结合的非结构化数据处理解决方案,采用MapReduce分布式数据分析框架实现海量数据的并行处理,以提高系统的数据处理性能;采用HBase技术实现异构数据的存储,并在此基础上通过Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)构建统一的数据处理模型和通用交互接口[3],以解决异构数据的规范化表示和操作问题。
1 非结构化数据处理的关键性技术
1.1 MapReduce
MapReduce是运行于分布式系统上的并行计算框架,Map(映射)与Reduce(归约)是它的两个核心要素[4]。其中Map函数用于实现原始数据的关系映射,先对大量类型不一的数据进行格式解析和特征分析,然后在此基础上将具有关联关系的数据以{key:value1,value2,……,valueN}的格式建立对应关系,并保存在新的数据列表当中,这个过程称为数据清洗;Reduce函数用于实现经过Map映射所生成的列表中元素的化简,也称为化简函数,即按照一定特征规则进行适当的元素合并,通过多次的递归迭代,最终将一个数据集列表中的若干数据元素化简为一个最终结果。
MapReduce可以将任务按照节点进行划分,将任务分解为若干数据块(Task)后,分布在多个节点上实现并行运算,这些节点既包括Map节点,又包括Reduce节点[5],并通过主控制节点(JobTracker)实现对Map节点和Reduce节点的分配调度和状态监控。MapReduce的任务执行流程如图1所示:

图1 MapReduce的任务执行流程
1.2 HDFS
HDFS是MapReduce框架的典型应用,用于实现通用硬件上的分布式文件管理。HDFS系统的架构部署同样采用主从节点模式[6],主节点(NameNode)包括一个文件命名管理空间和调度服务器,用于实现文件目录的管理和从节点的调度;从节点(DataNode)对应的是具体的存储设备,并在其上以数据块(DataBlock)为单位实现数据的存储。HDFS系统结构如图2所示:
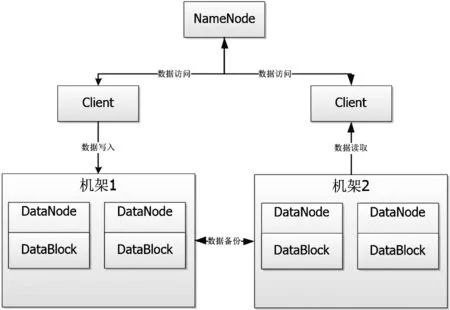
图2 HDFS系统结构
数据访问请求首先通过通用接口Client与NameNode进行交互,NameNode再在各个DataNode之间进行调度,这些DataNode的物理位置映射可以是属于同一空间的设备集群,也可以是不同物理空间的设备集群[7]。为了保证系统存储的数据可靠性和安全性,各个DataNode之间还可以实现异地的数据备份。
采用HDFS系统实现数据的分布式存储,一方面HDFS具有很好的系统容错性,能够有效地屏蔽硬件的性能差异,大大降低了分布式硬件环境的部署成本;另一方面HDFS是以流的形式实现数据的批处理操作,而非交互式的数据操作,所以具有极高的系统吞吐量,适合超大数据集的并行处理。
1.3 HBase
HBase是基于HDFS文件系统的异构数据库管理工具,HBase仍以二维表格(Table)的形式存储数据,但采用的是基于列的模式。HBase表格包括三个主要属性,分别为行键(RowKey)、时间戳(Timestamp)、列簇(ColumnFamily)。其中行键提供了待存储数据的所有属性项,是Table的主键;时间戳用于记录Table中每个单元格内具体数值的更新时间,用于标识数值的更新版本;列簇指的是当前Table内指定列下所有数值的集合,列簇对数值的类型、数量均没有限制,统一以二进制形式进行数据存储,是一个可以动态扩展的数据集合。HDFS文件系统会以列簇为单位构建数据文件,不同的列簇对应不同HDFS文件。
当Table中的列记录不断扩充,直到Table中存储的数据量超过预设的阈值之后,HBase还可以对Table进行切片操作,将其按行进行分割,分割后的行数据合集称为region,并通过内置表格.META记录若干region的所属Table、包含行号、时间版本等信息,另外一个内置表格-ROOT-则用于记录若干.META与region的映射关系。当数据交互时,客户端(Client)需要先与HBase的Zookeeper接口进行连通,然后通过-ROOT-查询到.META位置,在通过.META查询到region的所在Table,最终获取到所需数据。
2 非结构化数据处理系统的总体设计
非结构化数据处理系统的设计目的是要解决海量非结构化数据的可靠存储、统一交互,以及高效的并行处理等问题。其中数据的存储采用了HBase数据库技术,以实现基于分布式文件系统的异构数据存储管理;数据的统一交互和调度采用HDFS分布式文件管理系统,实现了以文件为单位的数据访问和存储设备的调度管理;数据的并行处理采用MapReduce软件框架,实现了原始数据的高效并行处理。其总体框架设计如图3所示。
非结构化数据处理系统主要用于处理三类数据任务:数据读取、数据写入和数据批处理任务。
任务首先由前端客户端发起,提交至MapReduce计算集群对原始数据进行初步处理,由分布式调度节点JobTracker进行任务节点的调度与分配,并调用Map函数与Reduce函数对原始数据进行特征分析、重组和归约,经过初步处理的数据,多个关联特征化简为一个最终结果,以排除冗余数据和解析错误的数据。
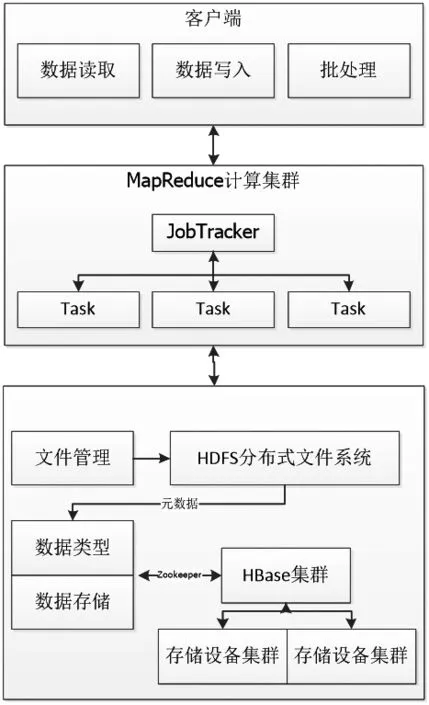
图3 非结构化数据处理系统框架设计
经过初步处理的数据集合会以文件形式提交至HDFS分布式文件系统,HDFS将文件按照预设的阈值进行数据块的分割,并以数据块为单位进行分布式存储。关于若干数据块与一个文件的映射关系、存储位置、以及数据块的属性描述等信息的集合则称为元数据,多个元数据的集合则以文件的形式保存在 NameNode节点的文件命名空间当中。NameNode作为HDFS的主服务器,负责HDFS系统内所有文件和目录的操作,例如打开、关闭、删除、重命名等,同时还负责标记数据块与DataNode节点的映射关系。DataNode节点用于响应文件中具体数据的读写操作请求,并以数据块的形式对其进行管理,例如数据块的创建、删除、复制、迁移等。
依据元数据提供数据属性描述,主要属性有数据类型、数据存储大小、位置等,采用HBase实现底层设备数据存储的逻辑结构构建。HBase数据库统一采用二进制格式进行数据存储,不同的数据类型在HBase中都会被屏蔽,因此HBase非常适合异构数据库的搭建和应用。HBase以region为单位进行数据的分布式存储,region是由二维表格切片构成的行维度上的数据集合,HBase设有一个主服务器HMaster和若干Region服务器,Region服务器用于维护其所对应的region集合,已解决单一服务器负载整个数据表格维护的效率低下、运行不稳定等问题;HMaster用于管理和调度Region节点,以确保Region节点之间的负载均衡。为了确保HMaster和Region节点信息的同步更新,HBase还部署有分布式协调器Zookeeper用于集中记录HMaster和Region服务器的状态,包括Region目录、当前的HMaster状态等。
3 非结构化数据处理系统的性能优化
3.1 小文件存储的性能优化
由于MapReduce、HDFS框架都是基于批处理的分布式数据处理系统,主要适用于大批量、大体积的文件处理,小文件处理一直是其技术短板,关键问题主要涉及两个方面:一是小文件存储所导致的存储空间浪费,当小文件的存储容量小于大文件的单个数据块容量时,分配给单个数据块的存储空间就会存在一部分的浪费,小文件越多,存储空间的资源浪费就越严重;二是对小文件的频繁读写会严重影响系统的执行效率。为了解决上述问题,本系统提出了合并小文件的性能优化方案。
首先是存储空间的优化,依据HDFS划分的数据块存储空间大小、小文件的属性特征等信息对若干小文件进行筛选,并将特征相近或属性相关的、适当数量的小文件合并为大文件,同时将文件的合并信息标记在小文件的元数据当中,其中包括两个关键参数:小文件存储容量的累加值参数(简称smailSpace)、单一数据块存储总量减去小文件存储容量累加值参数(简称smailFree)。每合并一个小文件,都要对这两个参数进行更新,当smailSpace大于smailFree,或smailFree小于预设阈值,将中断当前文件的合并操作,并按照HDFS的处理流程完成合并文件的存储处理。
其次是存储效率的优化,小文件合并需要建立相应的索引文件以标识小文件与合并后大文件的映射关系,因此对小文件的读写操作需要分步骤实现:第一步先读取索引文件,查询其所在大文件的存储位置;第二步从小文件元数据中获取小文件的具体存储信息,包括文件大小、文件位置、文件类型、在大文件中的排列标识等;第三步获取最终的文件数据。本系统基于以上三个步骤增加了分级预处理机制,以实现索引文件的预处理和小文件数据的预处理,针对近期数据请求行为的特征分析,对文件操作的范围进行预判,并在此基础上锁定对应索引文件、关联数据信息,进行预读取、预缓存、预调度操作,以有效提高数据的读写效率。
3.2 HBase数据表的读写优化
HBase数据表的读写优化旨在提高数据读写的批量处理效率。由于HBase数据表中的数据存储是按行关键字进行排列存储,因此行关键字的组合检索有利于提高批量数据的读写吞吐量,甚至一次有效的关键字组合检索,能够批量获取到上万条用户数据。为了提高关键字组合检索的有效性,本系统增设了手动的Major_Compact参数配置策略,Major_Compact是一种基于HBase的文件合并策略,默认为关闭状态。通过手动配置该策略参数,可以实现有选择的文件合并、清除和过滤冗余数据、提高数据读写效率等功能。依据行关键字的属性关联规律,利用Major_Compact进行关联行数据的合并,并存储为新的Htable文件,一方面可以实现多个Htable文件的并行读写,另一方面可以提高组合关键字的检索效率。
4 结论
随着网络当中非结构化数据的体量日益庞大,传统的结构化数据处理技术已经很难满足海量数据的处理需求,在此背景下,本研究对异构数据处理的关键技术展开了深入研究,并在此基础上设计与实现了一个非结构化数据处理系统。该系统通过MapReduce框架实现了原始数据的标准化批量处理,HDFS系统完成了数据文件的分布式管理,HBase数据库解决了异构数据的分布式存储,并提供了统一的数据交互接口。除此之外还提出了小文件的存储性能优化和HBase数据表的读写优化解决方案,大大改善了非结构化数据处理系统的运行效率。
