基于LSTM神经网络的馆际互借量预测研究
2022-11-21汪晴
汪 晴
(南京航空航天大学 图书馆,江苏 南京 211106)
0 引言
一校多址给高校图书馆的典藏管理带来巨大挑战。随着多校区图书馆分馆的产生,图书买几本,放哪里,怎么分配成了典藏的重要问题。本文以南航图书馆委托数据(即各分馆互借数据)为基础,对比采用神经网络算法建模,研究分馆典藏的智能预测和动态调整。
1 研究现状
馆际互借不仅仅是一校之内的研究课题。CCD(协同馆藏开发)活动为国外高校图书馆整体带来了巨大的经济效益,但服务质量和成本待进一步提升。
在跨馆典藏研究方面,杨静[1]提出校区互借服务应从以图书馆为导向朝以读者为导向转变。Walters[2]调研曼哈顿学院师生对图书的选择,指出学生群体的选择不可预测,与其个人特征相关性更为隐蔽。因此,人工方式预测有局限性,无法挖掘深层需求和感知需求变化,必须建立与时序相关的可靠模型来预测委托量趋势变化。田梅[3]采用支持向量机作为建模工具,但没有考虑除时间之外的因素对借阅的影响;尹志强[4]基于数据挖掘预测模型,引入混沌理论提升性能;王红等[5]采用聚类等技术探索读者与流通之间隐含规律;陈添源[6]基于学科细分读者群体和图书分类两个方面,通过APRIORI关联算法分析建模;张囡等[7]采用灰色神经网络算法,但对较长时间借阅量季节性变化预测的缺陷很明显。因此,本文从长时间、高精度预测要求出发,考虑委托书名、时间等有效信息对预测合理性和准确度的影响,选择LSTM神经网络算法来建模分析。
2 LSTM神经网络建模
2.1 LSTM神经网络
长短期记忆网络(Long Short Term Memory,LSTM)是一种时间递归神经网络,在学科主题热度预测[8]和中文专利关键词抽取[9]等图情领域应用,取得了很好的预测效果和准确率。通过在单元结构中引入门函数,LSTM可以很好地处理长期依赖性问题。
输入门it:计算当前计算的新状态已多大的程度更新到记忆单元,结果是向量,取值0~1,控制各维度流过阀门的信息量:
it=σ(Wixt+Uiht-1+bi)
(1)
遗忘门ft:控制前一步记忆单元的信息有多大程度被遗忘:
ft=σ(Wfxt+Ufht-1+bf)
(2)
输出门ot:控制当前的输出有多大程度取决于当前的记忆单元:
ot=σ(Woxt+Uoht-1+bo)
(3)
一个内部记忆单元ct:
(4)
(5)
最终,输出ht的计算公式是:
ht=ot⊙tanh(ct)
(6)
以遗忘门为例,根据上一轮的输入热度hi-1和本轮的输入xt,来计算当前的单元状态,Wf为遗忘门权重矩阵,bf为遗忘门偏差向量。输入门、输出门和遗忘门的计算方式类似。通过这3个门,LSTM不仅体现了单元之间外部循环的关系,而且体现了单元内部的自循环过程,所以更容易学习到图书、图书分类、图书委托量在时间序列上的变化关系。
2.2 预测模型构建
根据南航图书馆委托大数据的分析,设计模型如下。
输入数据:图书索书号、图书名称分词、图书分类、来源馆藏、目标馆藏、时间(学年或学期);
输出数据:委托量。
该模型训练完成后即可用于对下个周期(学年或学期等)的图书资源进行预测,用于指导全局馆藏调度的执行方案。首先对历史委托数据进行预处理,然后使用Tensorflow/Keras框架建立LSTM神经网络。下面简单示意构建LSTM神经网络的代码:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 64, input_length = maxword),
tf.keras.layers.LSTM(128, return_sequences=True),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.LSTM(32),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
tf.keras.utils.plot_model(model, to_file='lstm_model.png', show_dtype=True, show_shapes=True)
2.3 委托量数据预处理
基于以上模型,首先对历史数据进行预处理,从数据库中获取的原始数据示例如表1所示。
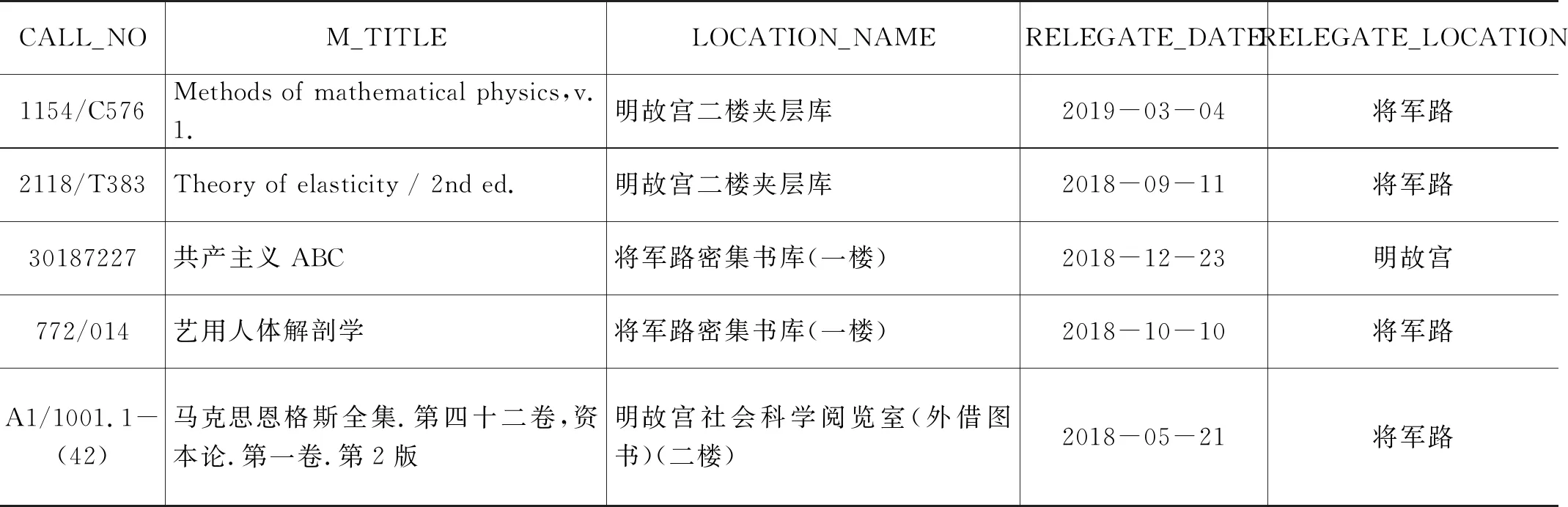
表1 委托借阅原始数据示例
2.3.1 书名分词
书名往往包含所属领域等特征,可能会体现出这些书籍和委托量、委托周期的关系,例如每年下半学期在将军路校区开马克思主义哲学选修课,就会产生一定的委托量。因此,本文对书名进行分词,如《时代精神的精华:马克思主义哲学原著导读》分词为[马克思主义,哲学…],转化为特征向量,和委托量、委托周期相关联,进行训练。采用结巴分词的代码示例如下:
import jieba
title = "时代精神的精华:马克思主义哲学原著导读"
seg = jieba.cut(title)
print(",".join(seg))
# 时代精神,的,精华,:,马克思主义,哲学,原著,导读
2.3.2 编码
上述数据中有些字段例如委托地、被委托地等,并非连续值,而是分类值,因此需要用数字来表示这些非连续的分类信息。本文采用ONE-HOT编码,即:使用1位有效编码来表达特征中的一个维度。ONE-HOT编码示例:
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
# 馆藏委托地特征,第一项是委托地,第二项是被委托地
feature = [['明故宫二楼夹层库', '将军路'], ['将军路密集书库(一楼)', '明故宫社会科学阅览室(外借图书)'], ['将军路密集书库(一楼)', '明故宫二楼夹层库']]
enc.fit(feature)
transform = enc.transform([['将军路密集书库(一楼)', '将军路']]).toarray()
print(transform) # [[1. 0. 1. 0. 0.]]
2.3.3 归一化
编码对于分类有限的字段,例如委托地,能够使用数字表达;但是对于书名分词,特征维度较多,数据量较大,因此采用如下特征归一化的方法进行处理:
x′=-1+(x-MIN)×2/(MAX-MIN)
(7)
即把[MIN, MAX]区间的数据线性映射到[-1, 1]。
综上所述,对原始数据需要进行如下预处理:图书ID、(来源馆藏、目标馆藏):采用OneHot编码并归一化;图书名称、图书分类:先使用jieba分词,然后采用LabelEncoder编码并归一化;委托时间:采用增量值表达,例如如果按学期划分,2017年上半学年为0,2017年下半学年为1,2018年上半学年为2,以此类推。
2.4 馆藏自动调整服务
有了算法模型后,就需构建一个自动化训练系统,降低人工干预,提升自动化率。如图1所示,本文通过crontab定时任务设定馆藏优化的分析周期,定期触发分析任务,采集上个周期的委托数据并预处理,然后和历史数据一起组成训练数据集;分析任务触发模型训练任务,输出新的算法模型,并给出测试集上预测数据,输出给人工审核,对模型参数进行调整。

图1 馆藏自动调整服务流程
2.5 实验验证
2.5.1 评价指标
综合应用场景和评价指标的含义,本文使用RMSE的方式来评价预测的好坏。RMSE就是MSE的平方根,作用是统一数量级单位。RMSE均方根误差(Root Mean Square Error):
(8)
范围[0,+∞),值越大表示误差越大。等于0表示预测值与真实值完全吻合,即完美模型。
2.5.2 实验结果
本文选取2017—2020年的图书馆委托记录数据进行实验,共计95 024条,每周作为一个时间段,根据75%,25%的比例随机分配训练集和测试集,使用TensorFlow框架构建LSTM模型,通过预训练效果设定如下参数:
epochs = 100
batch_size = 300
loss = tf.keras.metrics.mean_squared_error
metrics = [tf.keras.metrics.RootMeanSquaredError(name='rmse')]
optimizer = 'rmsprop'
选取线性支持向量机(Linear-SVN)、K近邻算法(KNN)对比,各模型预测效果如图2所示。
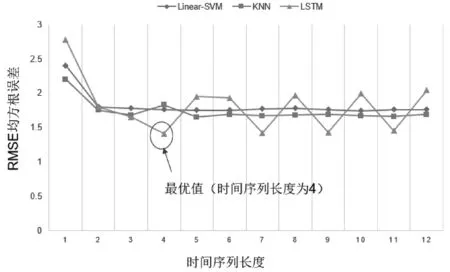
图2 各预测模型的根均方误差
从RMSE误差来看,Linear-SVM,KNN和LSTM都具有较好的准确度,但是随着时间序列的变化,LSTM的误差出现上下波动,甚至增加。由此可见,相对于其他模型无序拟合每一个变量达到最优,LSTM对时间序列更加敏感。因为时间序列的长度不同,所以准确度会发生变化。当时间序列长度为4时,RMSE达到最小值,LSTM模型效果最好。综上可见,基于LSTM的图书馆委托量预测模型,误差最小,预测效果最佳。
3 结语
本文通过对比使用LSTM神经网络算法,在原有委托量大数据的基础上,自动学习分析委托量需要调整的地方,并提示动态调整需求。实施效果显示大大减少了委托量,减少了馆员的工作量,提升了读者满意度。本研究可以进一步对模型进行优化,提升预测准确度,扩大到借阅量预测,对新书典藏分布提供有效建议。
