基于主成分分析和梯度提升树的变电设备状态评价
2022-11-21马洪斌王文峰石峰杨飞郇帅
马洪斌,王文峰,石峰,杨飞,郇帅
(国网枣庄供电公司,山东 枣庄 277000)
电网的安全稳定运行是保障电力可靠供应的基础,作为电网组成部分的电力设备是否得到及时、准确的监测对于电网坚强运行至关重要。通过对设备进行有效的监测分析,了解设备的整体运行状况,可大大降低设备故障发生的概率,保障居民稳定用电和经济社会高效发展[1-3]。
随着大数据分析技术在电力领域的广泛应用,变电设备监测分析的方法也得到广泛的研究,文献[4]针对变电设备状态评价参数复杂多样且各参数之间存在不明确的关联关系,应用主成分分析构建参数体系。文献[5]针对输电线路的状态评价问题,提出了构建多棵决策树组合模型。文献[6]针对设备的类别及设备数据的结构,通过构建支持向量机分析模型进行状态评价。文献[7]通过对变压器运行过程中的监测数据及变压器的缺陷故障等数据进行处理,并提取其故障特征向量,进行数据建模和优化处理,实现对变压器故障识别的高准确性。
变电设备的状态评价影响因素众多,设备参数、运行工况、试验数据等信息均与设备的状态密切相关,随着大数据技术应用和数据中台建设,加快了电力数据分析和应用,中台的建设,逐步实现对设备信息、运行信息等大量数据的集成共享,逐渐形成了电力大数据体系,结合大数据分析技术对设备进行状态监测有了强力的支撑[8-10]。
本文第一部分首先提出了变电设备关键参数体系,第二部分介绍变电设备状态评价分析模型的搭建,第三部分展示变电设备状态评价结果。通过对建立设备的参数体系,提取设备的特征信息,采用梯度提升树算法搭建设备监测分析模型,实现对设备的精准、快速、可靠分析。
1 变电设备关键参数体系建立
1.1 变电设备参数选择
变电设备从出厂到现场运行到发生缺陷及故障直至报废过程中会产生大量的信息及数据,这些数据通常表征着设备的运行状态。通过对设备的运行数据进行统计分析,可以将设备数据分为静态参数、实时参数、准实时参数[11-13],将三类参数作为电力设备状态评价的因素对设备的运行状态进行识别。静态参数信息主要包括设备的技术参数、投运日期、地理位置、出厂实验参数等。实时参数信息主要是设备的在线监测信息及运行环境气象信息。准实时参数据信息主要是设备的带电检测数据、设备的故障、缺陷及检修等信息。通过对变电设备的静态参数、实时参数、准实时参数进行分析,满足设备状态评价的科学性和准确性。
本文分析的变电设备主要是110kV及220kV变电站内的设备,包括油浸式变压器、互感器、开关等。结合设备的实际运行分析和设备状态评价研究,对变电设备的运行参数进行选择。针对电压互感器、电流互感器、断路器和隔离开关的特征主要包括基本参数、缺陷数据和试验数据。由于目前变电站内的高压变压器设备主要是以绝缘油作为介质,在实际的运行过程中,随着负荷的增加,油温的变化,油中会产生大量的气体,通过对油中气体进行监测分析和试验研判,实现变压器的运行的有效监测,因此对变压器设备的特征选取主要包括基本参数、油中气体、缺陷数据和试验数据。
根据特征提取获得的基本参数信息、油中气体数据信息、缺陷数据信息和试验数据信息,通过关键字段关联生成样本数据宽表,在对样本数据的标签定义上,通过结合实际的工作对每条样本数据集的故障类型进行标签化,包括正常、注意、异常等三种状态类型。将得到的变电设备状态评价特征信息和所对应的故障类型信息作为新的数据集,对数据集进行数据预处理操作,确保数据的完整性和可靠性。针对数据集数据存在缺失的情况,采用前一项或后一项数据进行填充,对缺失值进行补全。针对数据集中数据由于采集装置异常等原因造成的数据异常问题,对异常数据进行删除操作,得到干净的数据。由于机器学习只能识别数值,无法对状态的文字进行判断,因此将电力设备的状态信息进行数值化处理,对设备状态评价结果正常、注意、异常三种状态分别采用0、1、2表示,得到完整的电力设备样本数据集[14-15]。数据集包括每条样本设备数据的参数及数据对应的设备运行状态。

图1 设备参数Fig.1 Parameters of equipment
结合设备的静态参数、实时参数、准实时参数,对设备参数进行选取,所用的参数如下:运行天数、运行月数,运行年数,设备类型,设备厂家,电压等级,气体数据、缺陷总次数,危急缺陷次数,严重缺陷次数,一般缺陷次数,已消缺缺陷数,未消缺缺陷数,设备试验数据,设备名称编号等15项参数数据。
1.2 提取主成分
主成分分析是一种将多变量进行组合,从而得到较少变量的一种降维方法。原始的变量之间存在关联关系,通过线性组合的方式生成互不相关的综合指标,即主成分。通过主成分分析可以大大减少变量的个数,降低数据之间存在的关联关系导致的信息冗余等问题[16-17]。
基本原理是假设有p个综合评价的原始指标x1,x2,…,xp,设定这些指标在m个单位之间进行比较,则共有mp个数据。主成分分析是把原始的指标进行组合形成新的互不关联的新的指标y1,y2,…,yp,新的指标为原始指标的线性组合函数:
(1)
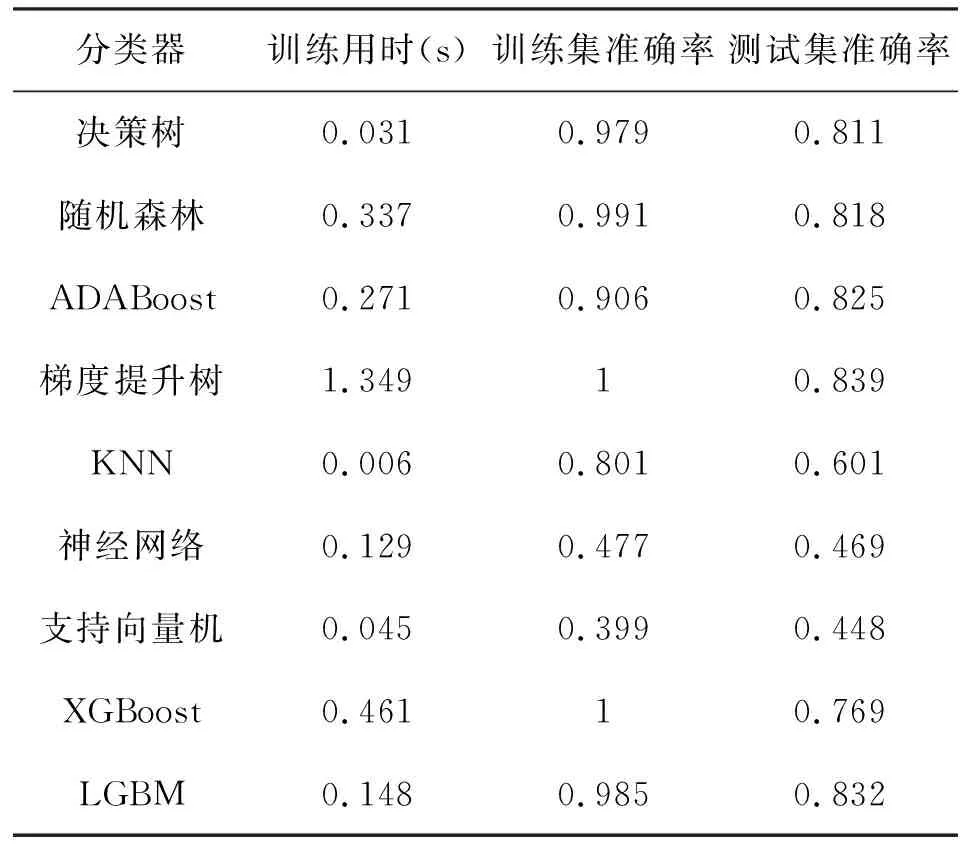
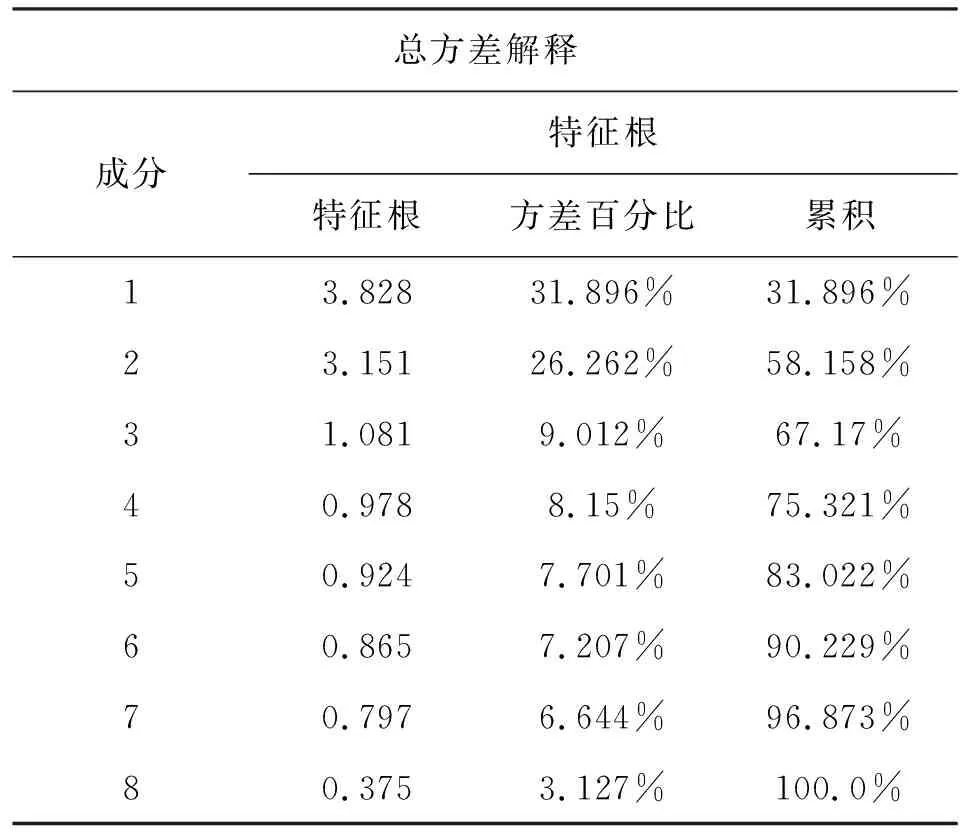
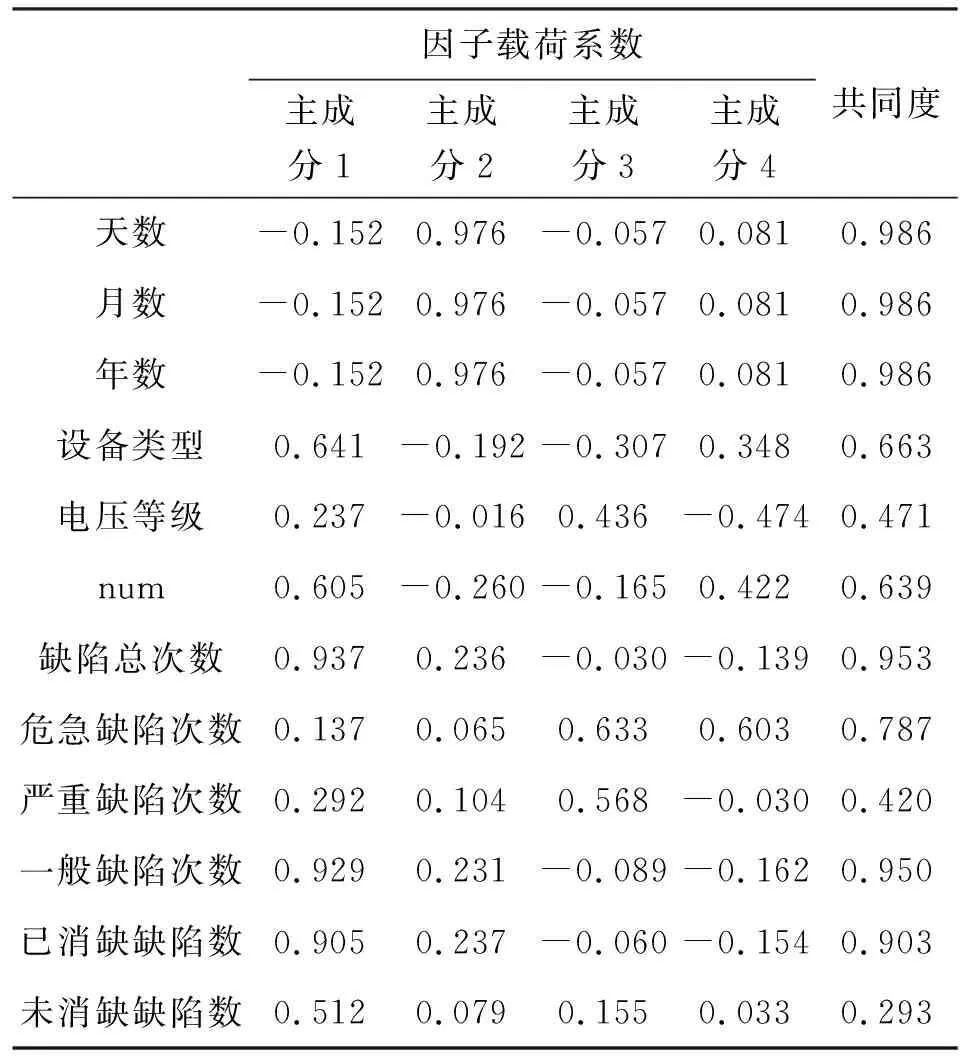
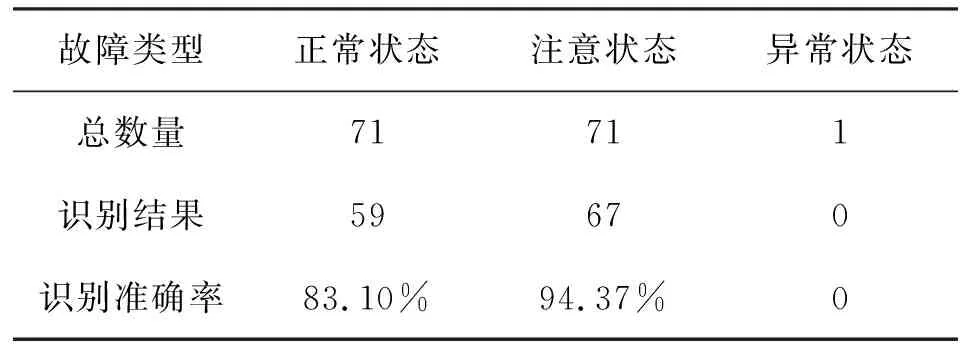
由以上的分析可以得到综合指标yi之间是线性不相关的。主成分分析得到的新的指标y1,y2,…,yp,对于新指标的方差按照从大到小的顺序进行排序,p个综合指标的方差之和等于原始指标的总方差。若p个综合指标的前r个即可以有效地表征原始指标的信息,那么我们就将r值作为我们得到的主成分个数。通过主成分分析,我们将指标的个数由p个降为r个(r 主成分分析的步骤主要包括以下。 (1)对原始数据进行标准化处理。得到的数据往往由于量纲或者数量的大小存在差异,影响分析结果,因此在进行主成分分析之前,对数据进行标准化。 (2)查看指标之间的关联关系,通过计算指标之间的协方差,得到协方差矩阵。 (3)计算协方差矩阵的特征值和特征向量,识别主成分。主成分是原始指标线性组合得到的,之间相关独立互不关联,第一个主成分中包含了最多的信息,第二个主成分第二多,以此类推。得到p个主成分,其相加信息等于原始指标。 (4)通过特征值的顺序对特征向量进行排序,从最高到最低,即得到按重要性排序的主成分,根据实际需求选择合适的主成分进行评价分析。 决策树是一种采用树状结构对数据进行分类的分析模型。通常应用于预测分析,通过决策树对大量的数据进行分类分析,找到数据内部潜在的价值信息。决策树分类树结构简单易懂,描述简单,分类速度较快,便于人们理解,同时决策树的树状分析结构决定了在构建决策树模型时不需要大量的额外训练数据进行学习[19-20]。 通常采用信息熵对决策树进行属性选择,信息熵是描述消息中,不确定性的值,也叫不确定程度。熵越低,不确定性越低,就更容易得到确定的信息;熵越高,不确定性就越高,就难以得到确定的信息。在决策树种由于存在各个分支,各个分支中的样本数量又是不同的,若某一个分支中含有的样本数越大,则它的影响就越大,考虑到该问题采用权重方式进行处理。因此我们采用信息增益的方式对分支进行选择若计算得到信息增益值较大,则表明使用该属性进行分支划分时信息的纯度越高,效果越好。 决策树的生成步骤如下所示: (1)首先是所有的特征均为符号值,即离散值。如果某个特征的值为连续值,那么需要先将其离散化。 (2)决策树中包含有根节点、叶节点以及中间的路径,一个节点代表一个对象,在节点之间的分叉路径处代表属性值,从根节点到叶节点中间的路径代表对象值。某一个节点数据若都属于同一类型的话,那么该节点就是叶节点。若样本数据不是同一类型的话,我们就利用信息熵、信息增益来对样本数据进行划分,选择信息增益大的特征作为根节点。 (3)依次递归,直至特征划分时信息增益很小或者为特征可以划分,我们就得到了决策树模型。递归操作的停止条件为:一个节点中所有样本数据均为一类;没有特征可以用来对该节点样本进行划分;没有样本能够满足其他特征的取值。 梯度提升树是一种组合的算法,通过对多个决策树的结果进行求和得到梯度提升树的识别结果。每棵决策树针对其中的部分数据做出预测,所有树的结果加起来即可以很好地分析最终结果,通过增加树的数量,可以不断迭代提升识别性能,是一种泛化能力较强的算法,占用内存较少,且预测速度较快[21-22]。 X为属性向量,假设梯度提升树模型生成了n个弱回归树,每一个弱回归树得到一个预测结果fi(X),i=1,2,…,n,f0为模型的初始值,则梯度提升树的预测结果为n个弱回归树的预测结果之和, F(X)=f0+f1(X)+…+fn(X) (2) 梯度提升树的步骤如下。 对于给定的训练集数据,表达式如下: T={(X1,y1),(X2,y2),…,(XN,yN)}, Xi∈γ∈Rn,yi∈γ∈R (3) N为训练样本数据的个数,对于每个样本数据Xi都含有z个变量(x1i,x2i,…,xzi),损失函数为L(y,f(x)),假设进行了M次的迭代过程,则梯度提升树的实现步骤如下所示。 (1)对模型进行初始化。首先我们要找到一个常数值c,确保常数值使得损失函数L最小, (4) 对于这里的回归树模型,我们采用平方误差损失函数: (5) 式中:y为真实值;g(x)为预测值。 (2)迭代过程。迭代的总次数为M。 1)对于i=1,2,…,N,通过计算得到损失函数的负梯度: (6) 对于平方误差损失函数,其梯度为: (7) 将梯度函数负梯度表达式进行简化得到: rmi=yi-fm-1(Xi) (8) 当我们利用平方误差函数进行求解时,上式得到的误差称为拟合残差。 2)我们将得到的(Xi,rmi),i=1,2,…,N从新作为训练数据,继续使用回归树模型进行学习,这样就得到了若干个叶节点区域,Rmj,j=1,2,…,J,其中J为第m颗弱回归树的叶节点数。 3)针对叶节点区域Rmj,j=1,2,…,J,我们利用线性搜索的方法求解使损失函数最小时所对应的常数c的值, (9) 4)更新强回归模型为: (10) 式中:I()是指示函数,当Xi落入Rmj中,该值为1,否则该值为0。 (3)通过迭代,并结合式(1)我们得到了最终的预测模型: F(X)=fM(X) (11) 影响变电设备状态评价的特征信息较多,考虑到大量信息作为特征输入会降低模型学习的时间和效率。对选取的运行天数、运行月数,运行年数,设备类型,设备厂家,电压等级,气体数据、缺陷总次数,危急缺陷次数,严重缺陷次数,一般缺陷次数,已消缺缺陷数,未消缺缺陷数,设备试验数据,设备名称编号等15项参数作进一步的筛选,选择差异性明显的指标变量作为建模变量。通过对15项参数进行均值和标准差计算,并用非参数检验方法对各参数进行校验,发现设备厂家、气体数据和试验数据的P值均大于0.05,指标差异性不显著剔除,保留12项特征参数信息。通过对含有12项特征信息的数据集分为训练集和测试集数据,以训练集数据进行识别分类器模型构建,并通过测试集数据验证模型的准确性。选择准确率较高的分类器作为我们的故障识别模型。进一步对12项特征参数信息进行主成分分析,选择合适的主成分因子个数,分析因子贡献率,得到降维的表征设备状态的主成分。将新的特征信息作为样本数据集,划为训练集和测试集,以训练集数据进行训练学习得到设备的状态识别模型,利用测试集数据对模型的识别结果进行验证分析。模型采用梯度提升树作为状态识别模型,为验证模型的准确性,同时采用决策树、随机森林等多种模型进行分析,并结合交叉验证进行验证[23]。 将含有12项特征参数的数据集分为训练数据和测试数据进行数据建模和模型验证,并通过与决策树、随机森林、AdaBoost、KNN、神经网络、支持向量机、XGBoost、LGBM等分类器进行比较分析[24-29]。数据集数据为474条,训练集数据为332条,测试集数据为142条。各分类器的分类识别结果如表1 所示。 表1 不同分类器识别结果Tab.1 Identify results of different classifier 从表中的分析结果可以看出在9个分类器中,KNN的训练用时最小,仅为0.006s,但是其训练集和测试集的准确率过低,分别为0.801、0.601。梯度提升树的训练用时较长为1.349s,但是训练集和测试集的准确率较高,分别为1、0.839。在实际工作中,检修运维人员对于设备的状态评价考虑更多的是识别结果的准确率,因此我们舍弃训练时间因素,考虑高识别率,最终选择梯度提升树作为我们的变电设备状态识别模型。 进一步对梯度提升树分类模型的识别结果进行分析,细化每类设备状态的识别结果,得到如下表2的结果。 表2 变电设备不同状态识别结果Tab.2 Identify results of different status of substation equipment 由以上的分析结果可以看到,模型对于正常状态、注意状态的识别准确率较高,分别为85.91%、83.10%,由于异常状态的数据样本数较少,导致识别效果较差。 为进一步优化状态评价模型的特征参数,通过主成分分析对特征参数进行方差解释,获得主成分分析的个数及每一个成分的贡献率和主成分的累计贡献率,得到结果如下表3所示。 表3 主成分分析结果Tab.3 Analyze results of principal component 基于以上的分析结果可以看出在主成分4时,总方差解释的特征根低于1,变量解释的贡献率达到75.321%,可以有效地表征设备的特征,因此我们选择四个主成分进行分析。 表4 主成分分析因子载荷系数Tab.4 Load coefficient of analyze fctor of principal component 上表为因子载荷系数表,可以分析到每个主成分中隐变量的重要性。在主成分1中缺陷总次数、一般缺陷次数、已消缺缺陷数的权重较大,主要体现为缺陷数据对特征的影响;在主成分2中天数、月数和年数的权重较大,主要体现为设备的运行时间对特征的影响;在主成分3中,危急缺陷次数、严重缺陷次数的权重较大,主要体现在缺陷的程度对特征的影响;在主成分4中,主要是设备的运行时间对特征的影响,在共同度分析中,可以得到电压等级、严重缺陷次数和未消缺缺陷数的权重较小,因此排除掉电压等级、严重缺陷次数和未消缺次数,保留其他参数作为主成分。 将含有天数、月数、年数、设备类型、num、缺陷总次数、危急缺陷次数、一般缺陷次数、已消缺缺陷数等9项特征参数的数据集分为训练数据和测试数据进行数据建模和模型验证,选择状态识别模型为梯度提升树,对训练集数据进行验证分析,数据集数据为474条,训练集数据为332条,测试集数据为142条。梯度提升树的分类识别结果如下表5所示。 表5 主成分分析分类识别结果Tab.5 Results of calssifying identify of principal component 由上表的识别结果可以看出,基于主成分分析获得新的特征数据集,通过梯度提升树分类器模型进行建模分析,训练集、交叉验证集和测试集的准确率分别为1、0.758和0.881,相比于未进行主成分分析的故障识别结果0.839,准确率上升了0.042。 对每类设备状态的识别结果进行分析,得到如下表6结果 。 表6 变电设备不同状态识别结果Tab.6 Identify results of different status of substation equipment 由以上的分析结果可以看出正常状态、注意状态的识别准确率分别为83.10%、94.37%,相对于主成分分析之前的结果得到了大大的提升,同时我们得到注意状态的识别准确率达到94.37%,相比于未进行主成分分析之前的识别率83.10%,提高了11.27%,注意状态的识别效果更好,对于我们在日常的变电设备监测中具有较好的指导意义。 本文通过梳理变电设备的参数体系,选择特征信息,采用主成分分析获得新的特征参数集,搭建梯度提升树分类模型,并与其他类型的分类器识别结果进行比较分析,验证梯度提升树的准确性,对于设备的监测分析具有重要的意义。在特征的选择上结合数据分析技术进行优化,将会进一步提升状态评价结果的准确性和可靠性。2 变电设备状态评价分析模型
2.1 梯度提升树模型
2.2 变电设备状态评价流程
3 变电设备状态评价结果


4 结语
