基于PCA和决策树模型的异常电费数据检测和识别研究
2022-11-21向黎藜肖私宇钟爱郭娇段凯张人杰
向黎藜,肖私宇 ,钟爱 ,郭娇 ,段凯,张人杰
(国网重庆市电力公司营销服务中心,重庆 400000)
随着我国人口的不断增加和用电量的持续攀升,电费核算异常或差错是不可避免的。如电费计量系统出现故障、用户私自改装电表等,这可能给供电企业和用户带来一定的经济财产损失[1]。作为电力营销流程中重要的一环,准确的电费核算可以促进供电企业的稳定运行和持续发展,从而为企业制定合理的电力营销策略[2]。
长期以来,电费核算分析方法大多是通过人工经验总结的核算规则对异常电费数据进行筛查,这无法覆盖所有的异常情况,缺少有效的数据支撑[3],并且存在诸多不足。一是通过核算规则判断异常电费,均需要进行人工复核,人力投入成本较大,效率低下。二是电费核算规则异常甄别精准度不足,经过人工复核,存在异常或差错的电费数据比例并不高;另外通过规则判断无异常而实际发生电费差错的情况亦时有发生,给供电企业精准制定电力资源分配方案造成了一定的困难。三是基于多数规则仍依赖人工经验进行固化,存在阈值刚性不合理、一刀切或规则不完善等问题,无法最大程度发挥电费核算规则对电费差错的风险防控作用[4]。
在大数据技术高速发展的背景下,合理利用当前的技术手段挖掘电费大数据隐藏的价值和关联,从多种因素和多个维度去分析和识别异常电费数据成为各国学者研究的热点和重点[5]。决策树[6]、随机森林[7]、神经网络[8]等机器学习算法模型已被应用于异常电费检测和识别中。文献[9]提出了一种K-means聚类方法,用来对异常点进行检测。文献[10-11]利用K-means算法对不同用户进行区分,但这种方法检测结果不够精确,无法准确定位,且在大数据量下需要提高运行效率。文献[12]基于粒子群优化的k均值算法对电力数据进行聚类分析,相对于传统的人工核查方法,能够更快速高效筛选出异常用电的客户。文献[13]基于密度的聚类方法,对异常用电用户进行有效检测并识别窃电行为,同时,对比了K-means聚类、高斯混合模型(GMM)聚类和基于密度的噪声应用空间聚类(DBSCAN)的检测精度,结果表明作者提出的算法具有最好的性能表现。文献[14]结合mean-shift算法和决策树模型,对疑似异常用电的用户进行二次筛选,充分利用了电网的数据资源,提高了电量异常核查效率,实现了对用户用电行为的自动学习和异常检测。文献[15]利用电力数据并结合外部天气数据,使用机器学习的技术对电量电费异常用户进行识别,达到电费智能核算优化的目标。文献[16]利用特征工程、主成分分析法、网格处理以及局部异常点等方法,实现了利用少量的异常数据检测大量的其他异常数据,显著提高了用电异常检测和识别的效率。
本文分析了不同算法在检测异常电量方面的优缺点,并利用重庆公司的海量电量数据并结合外部天气数据进行相关分析。在以往,重庆公司通过人工积累的经验规则去检测和识别异常的电费数据,主要将居民用电量突增、突减、总表电量与各子表电量之和不符等因素作为参考依据,其具体的量化指标也是通过主观经验给出的,导致了检测的大量的异常数据在人工复核后被判断为正常数据,造成了人力、物力以及财力的大量浪费。实现自动、智能的异常用电数据检测并提高电费核算数据识别的准确率具有极其重要的理论和应用价值。本文利用机器学习算法和海量的电力数据,将异常电费核算的检测和识别可以看作一个二分类的问题,利用以往人工核查的异常电费数据作为训练集,并利用主成分分析法对降低数据的复杂度,最后通过决策树模型对大量的数据进行分类识别,检测异常电费核算数据,从而达到电费智能核算优化的目标。
1 数据预处理
1.1 数据准备
本文所使用的数据集是由重庆公司提供的大量电力相关数据,主要包括电力营销、电力生产以及外部数据。自开展营销信息化建设以来,重庆公司积累了丰富的电力营销数据,包括营销业务数据(如电费信息、客户缴费信息等)、用户采集数据、客户服务数据(如95598电话、支付宝等移动电子渠道信息)等。电力生产数据主要包括电能的输送、分配等相关数据。在外部数据方面,主要通过网络爬虫等技术,获取了重庆各个区域内的历史天气数据以及相关政策等数据。这些数据以逐行格式存储,用户每天记录一行,为电费异常的识别和检测提供了强有力的数据支撑。
1.2 数据清洗
在对数据进行处理和分析之前,对数据的清洗是必不可少的[17]。在这一章节中,我们对得到的数据进行重新审查和校验,去除数据集中重复的数据,并将剩余数据转换成标准的可接受格式。在这个过程中,主要针对空缺数据、错误数据和不一致数据。其中,空缺数据需根据实际情况通过手工填入,使数据完整真实;错误数据主要是指系统无法识别的数据,例如数据中混入异常字符、数字“0”写成字母“O”、日期格式错误等,需纠正后方可对数据进行处理分析;不一致数据主要是指一些相互矛盾的数据,如同一用户同一时间记录了两条不一致的电表用电量数据,需进一步纠正和处理。
在原始数据行的基础上,对错误数据、空缺数据和不一致数据进行一系列的清洗和处理,得到303518个可用于数据分析的有效数据行。
1.3 数据集成
在本文所使用的数据集中,包含了大量的字段,仅从直观上很难判断出哪个因素的影响是巨大的,哪个因素的影响是微弱的。通过详细的特征工程,包括数据归一化处理、统计特征、相关系数分析、重要特征选择等,实现了对现有的特征的选择和扩展组合特征[18],例如供电单位、线下营业厅分布情况对居民的缴费情况有着更加重要的影响、居民的当月用电量与年平均用电量的比值更能反映用电的异常情况等。
由于电力数据中的指标是根据实际业务确定的,虽然通过特征工程提取了相对重要的特征,但仍然面临着影响因素过多的情况,这将导致问题变得更加复杂困难,极大地增加了计算量。同时,各个特征之间也存在着一定的相关性,这将造成信息的重复,可能会使异常电费数据检测结果和实际情况相悖。因此,数据集成、变量简化就成为一项不可或缺的数据预处理过程[19]。
数据集成、变量简化指的是剔除各个变量之间的冗余成分,即各个变量之间的重叠信息部分,并保持原有数据的信息量和决策能力。将多个相关的影响因素简化为尽可能少的不相关的综合特征,既减少了数据分析的计算量,也使异常电费数据的检测和识别结果更加科学合理[20]。
思蓉和思远走后,楚墨重新扎进厨房。这次他要为念蓉榨一杯西瓜汁,他说天太热,喝杯西瓜汁去暑。念蓉不理他,去浴室洗好澡,出来,楚墨已经将两杯西瓜汁榨好。
1.4 PCA降维
常用的变量简化、模型降阶方法主要有主观赋权法和客观赋权法[21]。前者会受到主观经验的影响,往往会夸大或减弱某一因素的影响,从而导致不能准确的检测和识别异常用电数据。后者主要包括因子分析法、主成分分析法(PCA)[22]等。本文利用PCA法对可能影响电费数据异常的因素赋予不同的权重,客观地反映数据间的真实关系。
PCA法是一种常用数据分析方法,常用于高维数据的降维, 被用于提取数据的主要特征[23]。该方法在降低维度、减少变量的同时,尽量减少原始信息的损失,并得到了很多研究者证实和广泛应用[24]。利用PCA方法大大简化了人脸识别问题中的特征[25],在保证精度的同时极大地提高了检测效率。瞿等人[26]利用PCA法对异常电力数据进行检测,其结果的准确率、误报率和漏报率均优于K-means、支持向量机等算法。本文将PCA算法应用到电力大数据模型的简化和降维过程中,通过特征工程和以往的经验,将数据本身的特征组合扩展得到新的一系列特征。显然,这些特征之间具有一定的重叠和相关性。通过PCA算法将这些相关的一系列特征重新组合计算,得到一组相互无关的综合性特征,同时降低了数据集中特征的阶数,达到了简化、降维的目的。PCA算法可归纳如下:
假设原始数据中X=(x1,x2,…,xp)T的n个样本Xi=(xi1,xi2,…,xip)T,(i=1,2,…,n;n>p),则样本矩阵X为:

(1)
对X进行标准化变换,

(2)
对标准化矩阵Z求相关系数矩阵:
(3)
再解相关系数矩阵R的p个特征值:
|R-λIp|=0
(4)

(5)

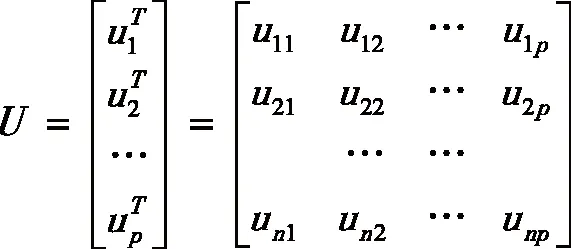
(6)

根据经过清洗和处理之后的有效数据,首先利用主成分分析法(PCA)进行变量简化。
2 数据模型
2.1 模型介绍
对异常电费数据的检测和识别可以看作为一个二分类问题。作为一种被广泛应用的分类算法——决策树算法,具有条理清晰,定量、定性分析相结合,易于掌握,适用范围广等优点。决策树模型中通常包含一个根结点,若干内部节点和若干叶结点,其中叶结点对应决策分类结果。目前已有很多学者进行了大量的基于决策树模型的研究工作,同时开发了很多基于决策树模型的分类系统,包括ID3、C4.5、CART、QUEST、C5等。Tso等人对比了决策树算法和神经网络模型在电力数据识别和预测方面的性能表现,结果表明二者具有一定程度上的可替代性。Tehrani等人基于决策树模型对电力数据中可能存在的窃电行为进行检测和识别,并取得了较好的结果。因此,本文同样采用决策树算法对PCA降维处理后的数据进行分析和检测。
决策树是一种十分常用的分类方法,其本质是由多个判断节点组成的树。树的每个节点对应着一个特征,在每个节点处对数据进行分析,进而在树的最末枝对电力数据是否异常给出最佳判断。在某种意义上,该算法与传统的人工算法类似,在数据集中的每一个特征上寻找一个阈值,根据这些阈值对数据进行分类,实现对异常数据的检测和识别,不同的是利用机器学习算法自动地创建分类规则摆脱了主观经验的影响,检测结果更加客观、准确。因此,决策树很容易转化形成更加精准的分类规则,常常被应用于专家系统。在本文中,应用决策树算法可以更直观地理解和复核异常电费数据。
2.2 模型训练
本文采用的CART决策树算法,其类似于自顶向下的穷举算法。该算法基于基尼指数最小化准则构建二叉树。每个节点根据选择的结果将该节点分裂为两个或多个子节点,重复这一过程,直至达到对训练集准确地分类或所有的特征已被选择过。该算法具体操作步骤如下。
(1)令训练数据集为S,计算PCA处理后的所有特征对S的基尼指数,此时对于每一个特征K,其可能取得的值为λ,根据此值将训练集数据划分为两个部分W1和W2,然后令K=λ,可得基尼指数的表达式为:

(7)
(2)接着,在所有可能的特征以及可能取得的值中,选择令基尼指数最小的特征和切分点将数据集划分为两个部分,即该节点分裂为两个节点。
(3)在得到了两个节点中,重复上述操作,节点不断分裂,直到可以准确地对训练集数据进行划分或对所有特征均完成选取和训练。
(4)完成决策树的生成,对测试集数据进行分类,从而对异常的电费数据进行检测和识别。
2.3 结果应用
从提高核算准确度、提升核算效率、转变班组职能三个方面,利用信息化技术和手段,统筹各部门间的协调和合作,有效提升了电费核算工作,降低核算风险,推进电费结算的智能核算工作。
(1)提高核算准确度
通过核算集约化管理,借助信息系统的能力提升,电费核算部门集中管理,提高电费核算的准确度。一次性算费准确率提高到99.96%。
(2)提升核算效率
将原有的主要人工审核电费的工作方式,改变为信息系统根据审核规则智能筛选异常、精准定位问题,人工解决问题的模式。根据2021年10月以后的数据情况来看,拦截次数减少了84398次,电费笔数减少了51677笔,拦截有效率提升了9.82%。
(3)转移核算重心
以信息系统自动推进替代原有的人工推进量费核算环节,减少人工工作任务,核算重心转移到量价费的全面监控。
3 结语
本文针对传统的基于主观经验的检测方法难以及时高效地检测和识别用电异常数据问题,结合了电力营销数据和外部数据的特征分析和数据挖掘,对各影响因素的内在联系做了一系列的研究,得到了影响或判断异常用电的关键特征,并针对不同的类别的用户对相关指标进行分别量化,例如低压居民的用电量突增为近12个月均电量的2倍以上时,才被判断为可能的异常用电,而同样的指标,对于低压非居民的用电量突增3倍以上时,其被判断为用电异常的概率会提升。
基于PCA算法和决策树模型,利用电力数据并结合外部天气数据对电费智能核算进行建模,有效地提升了异常用户识别的准确率,在降低了拦截用户的总量的同时,显著提升了有效的拦截率,错拦和漏拦的异常用电数据大幅减少。依靠主观经验和判断审核电费的工作方式,改变为利用机器学习系统进行自动的、智能的筛选异常、精准定位问题,有效提升了电费核算工作的效率,推进了电费结算的智能核算工作,有效降低供电企业的经济损失,不断提高企业的服务水平。
在未来的工作中,将不断地收集更多可能影响异常用电的因素和提高算法的性能,进一步提高异常用电检测和识别的精确性,同时实现对用户异常用电的预测工作。
