一种基于视角选择经验增强算法的机器人抓取策略
2022-11-20王高陈晓鸿柳宁李德平
王高 陈晓鸿 柳宁 李德平†
(1.暨南大学信息科学技术学院,广东广州 510632;2.暨南大学机器人智能技术研究院,广东广州 510632;3.暨南大学智能科学与工程学院,广东珠海 519070)
抓取能力是机器人智能化的关键处理能力。面向散乱堆叠物品的机械化分拣,成为机器人与人类动作能力对比验证的皇冠问题。近年来,随着计算机视觉和深度学习的发展,机器人抓取技术取得长足进展,即基于视觉感知技术,选择合适的抓取姿态用以操纵末端执行器实现抓取。但是,由于物体间形状大小不同、复杂的背景、物体间相互遮挡等情况,如何在混杂物体散乱堆叠场景下,实现快速准确的抓取仍是极具挑战性的课题[1]。
针对散乱堆叠环境的机器人抓取问题,国内外学者开展了大量相关研究,包括但不仅限于采用单目相机结合结构光、多目相机、彩色深度(RGB-D)相机等方案。影响机器人抓取能力的因素有多方面,本文主要关注视觉方面的因素,包括物体识别定位、抓取姿态生成等。
早期的机器人抓取研究侧重于匹配物体三维模型或进行三维解析推理获取抓取区域,通常的流程为提取待抓物体对象特征,然后在点云或RGB-D图像中进行特征匹配,获取局部点云,之后进行位姿估计。在传统方法中,使用人工设计的特征进行特 征匹配,主要的人工特征有SIFT[2]、PPF[3]、Linemod[4]等,但这些方法需要预先获得物体的三维模型进行特征提取。当存在多个物体,需要为每一个物体创建模板,因此,出现了基于深度学习的无物体三维模型位姿估计研究。例如,Xiang 等[5]提出PoseCNN(位姿卷积神经网络),通过多层卷积神经网络提取特征后,使用两个全卷积网络分别进行语义分割和物体平移估计,采用全连接网络回归物体姿态的四元数,最后组合这3个网络结果获得物体的位姿信息。Wang 等[6]在其提出的DenseFu⁃sion(密集融合网络)中通过一种异构网络分别处理彩色和深度数据以充分利用这两种数据的互补信息进行位姿估计,在许多场景下的表现优于基于特征工程的传统方法,但它依赖于前置语义分割网络获取局部点云,从而导致位姿估计精度会受到语义分割精度的影响。基于深度学习的位姿估计方法大多需要大规模运算资源,对机器人抓取效率有较大影响。
随着深度学习的发展,众多学者开始对直接生成抓取姿态进行研究,即从可能抓取姿态的无穷空间中采样,并对采用得到的抓取候选姿态集根据一些质量指标进行排序。Lenz等[7]使用卷积网络预测图像块是否包含潜在抓取,将图像分解为若干个图像框迭代预测,准确率达到75%,但每幅图像的处理时间高达13.5 s。Park 等[8]提出一种基于分类的多级空间变换网络,该方法允许观察部分中间结果,如抓取候选姿态的抓取位置和方向。Morrison等[9]提出抓取生成卷积神经网络(GGCNN),以端到端的方式,直接从深度图生成像素语义上的抓取位姿和抓取权重,通过抓取权重选择最佳抓取效果,此方法在任意孤立物体抓取中可获得88%以上成功率。
上述工作主要在物体位姿估计、抓取姿态生成方面提升机器人抓取能力,一些学者则从主动视觉方面进行研究。Gualtieri 等[10]对合适的视角是否能影响抓取检测准确度进行研究,提出“Smart”视角选择算法,在已知物体粗略抓取位姿的情况下,计算最优视角以提高抓取位姿的准确度,其实验证明了合适的视角能够极大地提高抓取检测中获得的抓取候选点数量。Ten 等[11]在机器人运动轨迹中选择若干个点采集点云数据,将多个视角的点云数据合成为一种称为视点云(View Point Cloud)的结构,以视点云作为输入进行抓取检测。Morrison 提出Multi-View-Picking[12]方法,使用抓取检测输出的抓取质量为输入,面向最大熵减的目标进行下一次最佳视角预测,在抓取执行过程中多次进行最佳视角预测,该方法在杂乱堆叠场景中相对于固定视角提高了12%的抓取成功率。然而,此算法需要进行多次视角选择迭代且需要依赖于特定抓取检测算法。
另一方面,深度强化学习在不同领域取得突破性成果吸引了大量学者的注意,在机器人操作中,深度强化学习提供了一种框架,能够令机器人自主地通过视觉信息学习各类操作技能。例如,Zeng等[13]提出VPG(Visual Pushing &Grasping,视觉推动与抓取网络),通过深度Q 网络(DQN)令机器人学习推和抓两种动作的协同;Deng 等[14]设计了一种结合吸嘴和夹爪的组合夹爪,通过DQN 框架引导机器人主动探索环境,获取更优的抓取置信图。谷歌大脑团队[15]提出基于Q学习连续动作泛化的离线策略训练方法,将大规模分布式优化和DQN 结合,令机器人能够学习动态闭环控制策略而进行物体抓取。
由此,相机视角的选择对于机器人抓取的效果起着重要的作用。针对相机随末端运动的机器人杂乱堆叠环境抓取问题,本文的主要研究内容如下:
(1)提出一种基于深度强化学习的眼-手随动相机视角选择策略,通过深度网络拟合视角价值函数,在DQN框架下学习视角选择策略。
(2)提出一种视角选择经验增强算法,解决训练过程中出现的稀疏奖励问题,提高网络收敛速度。
(3)分别在V-REP®(Virtual Robot Experimenta⁃tion Platform)仿真环境和实体机器人上进行实验,实验中网络训练可以在2 h 左右达到收敛,在实体机器人混杂场景中抓取成功率达到82.7%,每小时平均抓取个数达到294个。
1 视角选择策略学习框架
1.1 任务描述
在机器人抓取应用场景中,采用相机随机器人末端移动(眼在手上)的方式实现混杂物品散乱堆叠的抓取。相对于固定环境相机,眼在手上相机的抓取具有更高的灵活性,机器人能够根据运动可达空间选择合适的拍摄位姿。由于相机安装在机器人末端,则机器人视角V可以由相机在机器人坐标系下的6维位姿定义:

式中:x、y、z为机器人末端在基坐标系的位置,rx、ry、rz分别是绕x、y、z轴的旋转角度。
机器人主动视角选择抓取任务的工作流程如图1所示。首先机器人移动至预先设定好的全局拍照点进行拍照以获取整个工作空间的图像,获取深度图像后进行最佳视角预测,得到最佳视角的像素坐标VI,再经由相机模型和坐标变换得到最佳视角的机器人坐标VR,机器人移动到VR获取局部图像进行抓取检测,然后执行相应抓取动作,最后判断是否达到结束任务条件,否则重复以上步骤。

图1 机器人主动视角选择抓取任务示意图Fig.1 Illustration of robot active viewpoint selection grasping task
1.2 任务建模
将强化学习应用到机器人主动视角选择的关键问题是视角选择过程的马尔可夫决策过程(MDP)建模。基于智能体和环境进行构建的MDP 是一种基于序列决策的数学模型,视角选择过程的MDP 模型如图2所示。
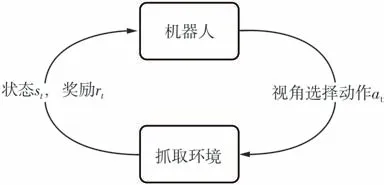
图2 机器人抓取任务马尔可夫决策过程Fig.2 Markov decision process in robot grasping task
机器人通过相机感知系统当前的状态,并根据视角选择策略获取最佳视角,移动至最佳视角并执行抓取流程(即再次获取深度图执行抓取检测并根据抓取检测的结果决定是否执行抓取),最后检测夹爪状态并获取奖励。因此,需要在视角选择过程MDP模型中对状态空间、动作空间、奖励和策略进行定义。
1.2.1 状态空间
抓取环境的状态st定义为在t时刻待抓取物体之间的位置关系,本文使用在全局拍照位置获得的深度图作为st,即在每次抓取前,机器人移动至预先设定的能够观察到整个工作空间的视角,以此视角获取的深度图表达当前环境的状态。
1.2.2 动作空间
视角选择动作a定义为机器人移动到视角选择策略预测的下一个最佳视角,并执行抓取流程。由于相机安装于机器人末端,视角选择可以包含6个自由度,但是六维的连续动作空间将导致样本复杂度为O(n6)。高维模型在训练时候耗费大量计算资源,并且需要海量训练数据才能使网络收敛。为了增强学习训练结果部署在实体机器人上的可行性,本文将无穷多的视角选择集简化为3个自由度的有限视角集合,即根据表示环境状态的深度图,产生与其深度图像素点一一对应的视角点,即:

式中:r、c分别表示像素点的行坐标和列坐标,zr,c表示深度图在像素点(r,c)位置上的深度值,ar,c表示深度图在像素点(r,c)位置上对应的动作。
因此,动作空间的维度为二维空间。通过相机针孔模型P和手眼标定获得的刚性变换矩阵,可将动作ar,c转换为以机器人坐标系表示的动作:
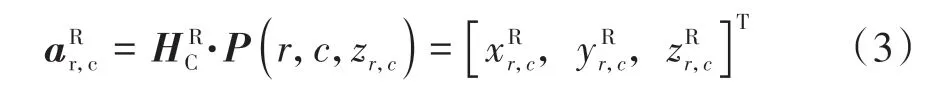
式中:P(r,c,zr,c)表示动作ar,c通过相机针孔模型P转换得到的ar,c在相机坐标系的位置
1.2.3 奖励设计
奖励rt表示在t时刻的状态st下,执行视角选择动作at后得到的收益。它是关于st、at以及下一时刻的状态st+1的函数,即:

在机器人抓取任务中,其最终目的是提高抓取成功率。因此,奖励设计为二维空间圆形区域奖励:若抓取成功,奖励的值由从圆心到边缘从1下降至0.5的二维高斯函数计算;若抓取失败,圆形区域的值为0。即:

式中,x0、y0为奖励区域的圆心,r为奖励区域的半径,σ为奖励从圆心到边缘下降的速度。在圆形区域外的奖励为未定义,不支持参数更新。
1.2.4 视角状态价值函数与最优策略
基于奖励定义可将机器人最终目标转换为最大化回报,回报是指从开始抓取到物体清空结束,这一有限长状态动作序列τ中的奖励累计值。为了控制机器人倾向于尽可能快地完成抓取任务,本文中使用带折扣因子的回报函数,即:

式中:γ为未来奖励折扣因子,表示智能体对未来奖励的权重,权重越大越重视长期回报,反之则更重视短期回报。
式(7)所示视角状态价值函数Qπ(s,a)表示机器人基于视角选择策略π在状态s下执行视角动作a后的期望回报:
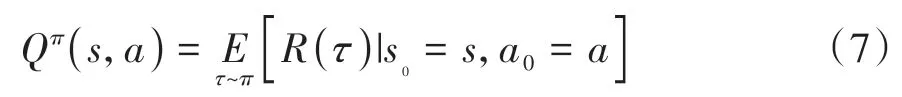
式中,s为当前状态,a为执行的动作。
通过视角状态价值函数Qπ(s,a)可以评估当前状态s下的机器人执行动作a在未来可以获得的期望奖励,Q值越大,说明采取该动作能够在未来获得更大的回报,即价值越大。在Qπ(s,a)已知条件下,可以通过选择令Q函数取最大值的动作为最优动作,导出贪婪最优策略π*,即:

通过上述MDP 建模过程分析,可将求解机器人最佳视角选择问题转换为对视角Q函数的求解,输出当前状态下每个视角的价值,取Q值最大的视角作为当前状态的下一个最佳视角。最终的求解目标即可转换为对视角价值函数的拟合,即分析从系统状态表达到视角价值的过程,设计合适的深度神经网络拟合视角价值函数。
2 视角价值函数学习
2.1 视角价值函数拟合
视角价值函数Q(st,a)的输入为机器人抓取环境当前状态,在机器人主动视角选择任务中使用在全局拍照位置获取的深度图表达。若深度图的分辨率为sx×sy,则状态空间中状态数量为216×sx×sy,接近无穷计数,因此无法使用传统Q-Learning 强化学习中的查表法求解。而深度卷积神经网络擅长从图像这类高维数据中学习特征,因此选择深度卷积网络拟合视角价值函数,并且基于深度Q网络[16]设计强化学习训练的框架。
从场景状态图像内容估计视角价值的过程等同于面向图像中每个像素从不同的感受野提取信息,并依据此信息预测提取获得的各维度特征与像素点对应的视角价值,这类似于语义分割的过程。深度反卷积编码-解码器结构网络[17]克服了原始全卷积网络中存在的尺度缩放问题,并且具备识别具有更多细节的结构和处理多尺度对象的能力。基于此,本文中提出使用编码-解码器卷积神经网络拟合视角动作价值函数,网络结构如图3所示。网络输入定义为t时刻机器人在全局拍照点采集的深度图,经过三层卷积编码后,再由三层反卷积解码,最终可输出与输入的深度图尺寸一致的视角价值图。视角价值图中的像素值代表了选择该像素点所对应的视角后可以获得的未来期望回报。
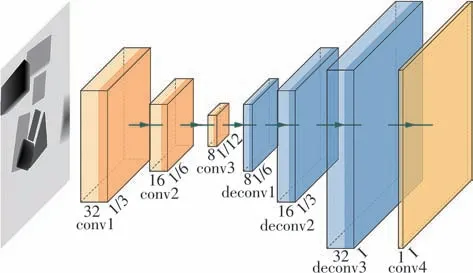
图3 视角动作价值函数近似网络结构Fig.3 Viewpoint action value function approximation network structure
在DQN 强化学习训练中,为了解决强化学习的样本关联性,采用经验回放机制[18],基于机器人视角选择任务特征,在训练流程中加入结束条件判定、经验增强。基于ε-greedy 策略对机器人抓取场景设计可选择的下一个最佳视角a*,即:

式中:W、H为视角价值图的分辨率,ε为探索概率,U(0,1)表示在[0,1]区间的均匀分布。若g≥ε,则通过视角价值函数Q(st,a)产生视角动作,否则通过2 个相互独立的均匀分布产生视角动作。为了减少探索的概率,使机器人逐渐倾向于根据训练的策略选择动作,同时保留探索到更优动作的可能性;ε伴随训练的递进渐次从初始值ε0下降至0.1,即:

式中,gε为递减系数,k为训练的轮次。
移动至预测的最佳视角后,机器人执行抓取流程,根据抓取结果生成经验数据E={st,at,rt+1,st+1,d}(d表示机器人抓取任务是否完成),对所得经验数据进行增强,然后存入经验池。若经验池中的经验数大于预先设定的批尺寸N,从经验池中随机抽取N个经验数据后进行训练。视角价值动作函数训练算法流程图如图4所示。
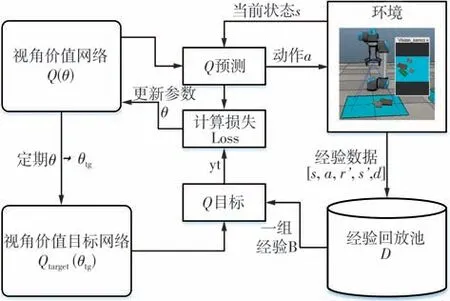
图4 视角动作价值函数训练算法流程图Fig.4 Flow chart of viewpoint action value function training algorithm
在图4中通过与环境交互获得的经验数据中包含一个变量d用于判断机器人抓取任务是否完成,即机器人是否将视野中的物体全部抓取并转移到目标位置。因此,需要根据执行动作后的状态判断场景是否清空,当场景清空时可判断本轮抓取任务已完成。
完成上述算法,要先通过相机内参数K将深度图转换为点云。相机内参数对相机成像针孔模型进行描述,可表达为:

式中:ax为水平方向像元尺寸;ay为竖直方向像元尺寸;u为水平方向的投影中心偏移;v为竖直方向的投影中心偏移,需通过相机标定获得。
深度图的像素值表示每个像素的成像点在相机坐标系的z坐标,在已知成像点z坐标和像素坐标的条件下,即可通过相机内参计算成像点在相机坐标系下的坐标。设第i个成像点的像素坐标为ri,ci,其相机坐标系坐标为:

式中,Idepth(ri,ci)为深度图在(ri,ci)位置的深度值。
将深度图中所有像素点变换为成像点坐标,因此所有点可表示为三维列向量,经组合获得点云矩阵DC。根据手眼关系将相机坐标系表示的点云变换为机器人基坐标系中的点云D:

不失一般性,本文令抓取工作空间与机器人基坐标系xy平面平行,因此只需统计点云PB中z坐标大于固定阈值zmin的点个数即可判断场景是否清空,如下式:

式中:S(Pb>zmin)表示点云PB中z坐标值大于zmin的点个数;Th为判断场景情况的点数阈值。
2.2 视角选择经验增强算法
参阅深度强化学习时的稀疏奖励问题[19],可以理解在智能体与环境进行交互的过程中,由于奖励获取的抽象和复杂性,智能体在初始条件的策略实施下难以获得奖励,出现正样本与负样本的比例失衡和样本效率低,从而导致强化学习算法迭代时间长,甚至无法收敛。因此,为了提高视角选择网络的收敛速度,本文对视角选择过程建模,提出一种新的经验增强算法,以提高样本利用效率,从而提升视角价值函数的学习速度。
机器人最佳抓取视角选择标准是目标物体能够出现在视野正中央。基于对最佳视角的假设判断,本文所提方法对抓取成功的视角经验进行增强,扩展奖励区域从单一视角点增强到一个视角选择区域。对于抓取成功的情况,如图5所示,以抓取点作为圆心,视角点与抓取点间距离作为半径,在该圆形区域给予奖励;另外,为了让机器人更倾向于选择令目标物体处于中央的视角,在圆形区域中,从圆心到边缘以高斯函数的方式将奖励从1衰减到0.5。如图6 所示,对于抓取失败,通过圆周四向探索的方式增强经验。图6 以失败的视角点为起点,设定固定的搜索半径步长s,令搜索半径r每次增加s。获取所有圆边缘的计算探索位置,并对所有探索位置进行抓取检测。若本轮所有探索位置均抓取检测失败,则增加半径一个步长,重复同类探索;否则,以当前半径作为增强奖励区域的半径参数结束探索。
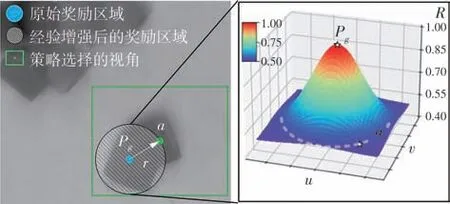
图5 抓取成功条件下抓取经验增强过程Fig.5 Process of grasping experience enhancement under grasp⁃ing success

图6 抓取失败条件下抓取经验探索过程Fig.6 Process of grasping experience exploration under grasp⁃ing failure
具体算法如下:

3 实验结果及分析
3.1 实验环境配置
为证明基于深度强化学习的视角选择经验增强算法可行性,本文在V-REP仿真环境中实施强化学习训练并进行抓取对比实验,同时在安川机器人上进行抓取实验,对比验证几种视角选择算法对提升抓取性能的效果。实验使用的计算机系统配置如表1所示。

表1 计算机系统配置Table 1 Computer system configuration
采用Pytorch 编写视角选择经验增强算法框架,机器人执行任务过程与环境交互的轨迹长度Lτ跟场景中物体个数相关,因此邻接控制周期所获取奖励权重渐次增强。
不失一般性,设置折扣因子γ=0.5,学习率α=0.001,经验池容量R=4 000,目标Q网络参数同步步数M=20。为了增强对噪声抑制的鲁棒性,损失函数使用Huber Loss,损失函数Li为
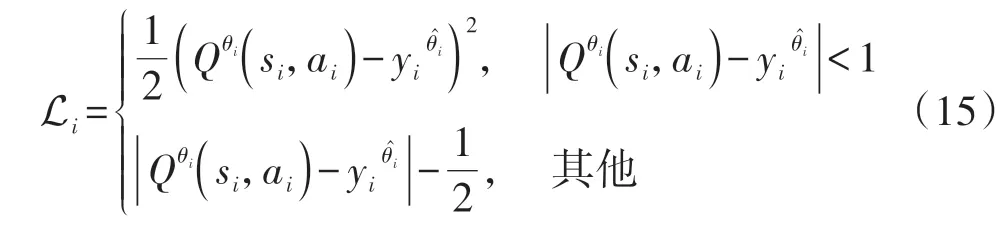
式中:θi为在第i次迭代中的主网络的参数,为目标网络的参数,si、ai、yi分别代表第i次迭代的状态、动作和目标价值。每次更新只传递获得奖励元素的梯度参数,其他位置对应元素的损失强制置为零。优化策略采用随机梯度下降算法,探索策略则使用ε-greedy 策略,设置探索概率ε的初始值为0.5,gε=0.99。
3.2 对比实验设计
采用6DOF机器人重复执行50次抓取任务,每次在机器人工作空间中随机放置N个物体,执行抓取流程,最终将抓取对象放置到料箱。连续抓取直至工作空间所有物体被放入料箱(即场景清空)视为成功;连续抓取不到视为失败。具体到抓取任务失败的条件可设置为连续抓取失败超过指定次数,例如5 次,目的是防止机器人因当前场景过于复杂,不能有效抓取而引起的重复动作。
3.2.1 对比方法
采用以下3种典型视角选择生成策略与本文提出的视角选择经验增强算法进行对比实验,具体方案如下。
(1)固定单视角 使用安装在工作空间上方固定位置的单个相机获取场景图像,任务执行过程中的相机位置保持不变。获取固定位置图像后进行抓取检测并执行抓取。
(2)固定多视角 同时使用多个相机或单个末端相机多次采集来获取待抓取目标图像,并根据所采集多视角间的位置关联关系实现信息融合。本文选择专利[20]中的方法作为目标对比方法。使用眼在手上工作模式并根据机器人预设路径采集多视角深度图,然后进行点云融合,使用融合点云进行抓取检测。
(3)基于熵的主动多视角 使用Multi-View Picking[12]方法,从固定位置开始,根据当前场景图像的熵计算下一个最佳视角,再移动机器人到目标视角,回环往复多次迭代执行视角预测。每次视角预测均通过深度图像输出相关计算熵,并根据熵结果变化趋势而选择视角。
机器人进行视角选择后,判断抓取检测并获取稳定抓取点,执行抓取操作。与前述对比文献方法保持一致,本文中采用综合时间和准确率最佳的端到端抓取检测方法——抓取生成卷积神经网络[9],作为本实验方案中使用的抓取检测算法。
3.2.2 评价指标
本文中使用表2所示指标来评估算法在抓取任务中的性能。

表2 抓取性能评价指标Table 2 Evaluation metrics of grasping performance
3.3 仿真实验
使用V-REP仿真平台搭建机器人抓取环境,如图7所示。仿真机器人采用Universal Robot:UR5,末端安装Onrobot RG2 夹爪和彩色深度相机,设置机器人工作空间为350 mm×350 mm 的方形区域,调用V-REP仿真平台的远程控制接口,获取训练过程中机器人运动状态及获取彩色深度图像。

图7 机器人抓取仿真环境Fig.7 Robot grasping simulation environment
仿真实验中,设定训练、对比的抓取对象为8 种不同形状的3D积木块,如图8所示。随机选择不同形状和颜色的积木块作为待抓取对象。

图8 仿真环境中的抓取对象Fig.8 Grasping objects in simulation environment
3.3.1 训练过程
通过机器人与环境的交互学习获得视角选择策略。基于这一原则,将训练步骤安排为:在机器人工作空间随机放入n个物体,机器人连续执行抓取任务,并在执行任务过程中不断收集经验数据存入经验池,直到清空工作空间物体,再重新放置m个物体。为提高训练收敛速度,采用从易到难的方式放置待抓物体,即训练开始时只往工作空间中放置一个物体,随着训练次数增加而改变放入物体个数。
本文中提出的一种视角选择经验增强算法,在训练过程中的抓取成功率变化如图9 所示。在500轮抓取任务训练中,经过100轮(约2 h)训练后网络已达到良好收敛效果。

图9 训练过程中抓取成功率变化Fig.9 Variation of grasping performance during training
3.3.2 对比实验的结果分析
仿真环境中的对比实验总共设计8 组,分别放置1 到8 个物体,每组分别进行50 轮抓取任务。图10 为各方法抓取成功率和清空率随物体个数增加的变化曲线。

图10 仿真环境下抓取成功率与场景清空率对比Fig.10 Comparison of grasping success rate and clear rate in simulation environment
与使用固定单视角的情况对比,本文方法在复杂场景下的抓取成功率和场景清空率两方面均获得较大提升。其中,场景物体个数为8个时,抓取成功率提升了14%(从62.3%提升到76.2%),而场景清空率提升了46%(从44%提升到90%)。本文所提视角选择策略可以通过选择合适视角来降低视野中场景的复杂度,克服固定单视角模式下机器人出现连续抓取失败的问题,从而提升场景清空率。实验对比结果证明,本文方法可以有效提高机器人在复杂场景中的抓取能力。
与固定多视角和主动视角选择这2 种方法对比,本文所提算法在抓取成功率和场景清空率方面相差不大,但两种对比方法都需要机器人移动多个视角导致抓取效率降低。而本文的视角选择策略在达到相似抓取率的同时只需进行一次视角选择,进一步提升了机器人的抓取效率。
3.4 实体机器人实验
为验证仿真环境中训练的视角选择策略,本文同时进行了实体机器人抓取实验。本文算法由图像预测的视角需通过手眼关系转换为机器人视角,精度与手眼标定算法有关,而在实体机器人实验中手眼标定精度可控制在3 mm 以内,对本文算法影响可以忽略,因此采用首钢莫托曼Yaskawa MOTOMAN-GP8 工业机器人,集成远程控制MOTOCOM32 API 完成机器人控制。抓取夹具使用舵机驱动的机械夹爪,控制器通过串口控制夹爪开闭并读取夹取状态。末端集成Intel Realsense D435 深度相机,实体机器人抓取实验平台如图11所示。

图11 实体机器人抓取实验平台Fig.11 Real-world robot grasping experimental platform
抓取对象选择常见工业零件:三通管、四通管、90 度弯头管等,如图12 所示,随机选择添加至机器人抓取工作空间。

图12 工业零件抓取对象Fig.12 Industrial parts grasping objects
实体机器人执行与仿真完全一致的10 组零件抓取实验,分别放置1到10个相异物体,每组分别执行50 轮抓取任务,记录每组实验抓取成功率、清空率、执行时间。
如图13 所示,实验结果表明本文提出的视角选择经验增强算法对训练中未出现过的物体抓取成功率仍能够达到与仿真实验相近的水平。在混杂物体散乱堆叠场景(10 个物体)下的成功率达到了82.7%,相对于一般单视角方法提升了22.8%,相对于主动多视角和固定多视角提升了约2%。在场景清空率方面,本文算法在混杂场景能够达到90% 的清空率,优于前两种对比方法。

图13 真实场景下抓取成功率与场景清空率对比Fig.13 Comparison of grasping success rate and clear rate in real-world scenes
实体机器人抓取实验结果如图14 所示,文中提出的视角选择经验增强算法具备实际应用特征,能够选择合适的视角提升抓取成功率,在一定程度上解决了机器人处理复杂场景中抓取的问题。

图14 实际视角选择抓取过程Fig.14 Process of real-world viewpoint selection grasping
如表3 所示,设待抓取物体个数为10,本文的方法对比固定单视角、固定多视角、主动多视角的抓取成功率、平均抓取时间的结果显示:平均抓取时间以固定单视角最小,但由于其较低的抓取成功率在实效性方面不如本文算法;另外两种多视角方法虽与本文算法保持接近的成功率,但本文算法可直接预测下一个最佳视角,只需选择移动一次相机视角,而多视角方法则需要移动多次,因此本文方法可以保证更短视角选择时间,在抓取效率方面优于另外两种算法。实验结果证实了本文提出的视角选择经验增强算法在实体机器人场景下能以小幅增加单次抓取耗时的代价,获得更高的抓取成功率,从而达到更优的抓取效率。

表3 对比实验结果(物体个数为10)Table 3 Experiment result of comparison(number of objects is 10)
4 结论
针对机器人在固定单一视角下难以解决物体散乱堆叠场景下的抓取问题,本文提出一种基于深度强化学习的视角经验增强算法,将视角选择问题转化为马尔科夫决策过程建模,使用编码-解码器网络拟合视角价值函数。针对训练过程中稀疏奖励的问题,提出一种视角选择经验增强算法。实际训练结果表明,扩展视角选择奖励区间可有效解决当前场景中的稀疏奖励问题,加快强化学习收敛速度。仿真与实体机器人抓取实验结果表明,本文算法可通过强化学习的方法得到有效的视角选择策略,且具备了较好的抓取目标泛化能力,在抓取成功率、场景清空率和抓取效率方面与其他方法相比获得不同程度的提升,证明了合适的视角选择策略在提高机器人抓取性能方面的较强适应力。为今后机器人控制体系采用强化学习框架学习视角选择和抓取选择提供了实验数据支撑。未来,高自由度视角的选择研究将逐步场景化,融合策略搜索算法、注意力机制框架等方法将提高系统鲁棒性和适应性。
