DPENet:轻量化文档姿态估计网络
2022-11-20吕学强张祥祥
韩 晶,吕学强,张祥祥,郝 伟,张 凯
1.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101
2.首都师范大学 中国语言智能研究中心,北京 100048
纸质文档承载着大量有用的信息,这些信息在人们的日常工作与生活中起着至关重要的作用。随着移动智能手机、便携相机等设备的日益普及,用户可以通过拍照实现纸质文档的数字化[1]。然而,由于相机的姿态、文档放置状态等不确定因素,移动设备采集文档会出现透视倾斜变形,往往导致文档信息无法被准确提取,故需要进行图像矫正处理。对这类变形普遍采用“四点法”进行矫正,即通过变形文档上的四个点与矫正后一一对应的四个点求单应矩阵进而实现矫正,不同的方法区别在于如何寻找对应的四组点[2]。
2017年,Abbas等人[3]提出一种基于深度卷积神经网络的文档角点定位网络,该网络末端使用单层全连接实现文档角点坐标的回归,具有端到端可微的特性,但回归方法对卷积层输出的特征图进行了拉伸操作,丢失了特征图的空间特性,导致泛化性较差。同时由于该模型体量大,模型的参数量大,故推理速度较慢。
同年,Javed等人[4]提出一种先检测再递归调用的方法实现文档角点的定位。该方法设计了两个有先后调用顺序的深度卷积神经网络,第一个网络使用目标检测方法检测文档的角点,第二个网络被递归调用,以回归角点坐标。该方法非端到端可微,且后一步的角点坐标回归依赖于前者的文档角点检测,当前者未能检测出文档角点区域,后者角点坐标回归必然失效。同时,后一步的全连接回归坐标方式同样存在坐标泛化性差的问题。另外,计算过程中第二个模型需要被多次调用,算法推理速度较慢。
2019年,Korber[5]基于Abbas等人[3]的工作提出一种由Xception网络[6]改进的角点定位网络。该网络采用深度可分离卷积实现一定程度的轻量化,但该模型在实现轻量化特性的同时损失了一定的精度。另外,由于该模型也采用全连接方式进行坐标的预测,故模型的泛化性也较差。
随着深度学习与姿态估计技术的发展,基于深度学习的姿态估计技术被广泛地应用在人体姿态估计[7]、人脸姿态估计与人脸对齐[8]、手指姿态估计[9]、动物体态估计[10]等领域。这些领域的研究证明了姿态估计定位的高精度性与技术成熟性,而文档的角点可以看作文档图像中“文档个体”的四个姿态点,即可通过姿态估计技术实现文档角点的定位。
本文从姿态估计的角度寻求解决文档角点定位的更佳的解决方案,主要贡献有:(1)提出一种轻量化的、端到端的、高精度的文档姿态估计网络DPENet(lightweight document pose estimation network),相比于之前的基于深度学习的角点定位模型,具有角点定位精度高、角点坐标定位泛化性好、抗干扰性强、模型体量小、计算量小、推理速度快等优点;(2)针对回归方法角点定位精度低的问题,通过引入DSNT(differentiable spatial to numerical transform)结构[11]实现Heatmap方法[12]与坐标回归方法[13]的融合,既获得了回归模型端到端可微的特性,又得到了Heatmap方法良好的坐标泛化性,实现了优于回归方法与Heatmap方法的角点高精度的定位与端到端的文档姿态估计和矫正处理。
1 相关工作
1.1 MobileNet V2
目前的文档图像矫正应用一般部署在移动手机端或嵌入式边缘计算设备之上,而移动手机与嵌入式设备一般计算性能有限,则体积比较庞大、占用内存多、推理速度慢的模型一般不能适用,训练的模型即使精度很高也不具有良好的实用性。MobileNet V2[14]为针对移动端设备而精心设计的深度卷积神经网络,广泛应用在面向嵌入式边缘计算的设备中[15-16],可在保持精度的情况下大量降低模型参数、模型计算量以及模型大小,并且可以兼顾速度与精度。故本文选择MobileNet V2作为DPENet的主干网络。
1.2 DSNT
在现有的基于深度学习的坐标回归任务中,一般采用全连接层直接进行回归并输出关键点的坐标,或者使用高斯热图回归再通过求取热图中最值的位置来获取关键点的坐标。这两种方法均不够理想,前者是端到端可微的,可以直接输出关键点的坐标值,且速度较快,但全连接破坏了特征图的空间特征,故该方法空间泛化性不足,得到的坐标精度一般较低,且模型一般比较依赖训练数据的场景分布,对新数据的适应性差,容易过拟合。后者输出的是关键点的高斯热图,由于没有破坏特征图的空间特征,故该方法的空间泛化性较好,输出的坐标精度较高,但坐标精度与输出的高斯热图尺度大小有关,且存在上限,一般需要进行高斯热图多级监督,当坐标回归的精度要求较高时,就必须保证足够的上采样层与足够大的网络输出尺度与多级监督,会造成模型体积大、模型结构复杂、参数量多、训练速度慢、推理速度慢、内存消耗大等问题。另外高斯热图回归不是端到端的模型,坐标值的输出需要在输出的高斯热图之上进行进一步处理。
DSNT是针对以上两者的优缺点而提出的一种全新的通用型解决方案,不仅具有前者端到端、推理速度快的特点,还具有后者良好的空间泛化能力,且在使用上简单便捷,即插即用。DSNT核心思想是将关键点的坐标值的求解转化为坐标期望值的优化问题,将高斯热图各个像素位置的值进行归一化,作为对应坐标位置的值的权重使用,再构建两个与高斯热图大小相同的常量坐标矩阵,矩阵的每个元素值对应为该元素的轴向坐标值。然后将两个常量矩阵与归一化后的高斯热图按像素位相乘并求和,输出关键点的坐标x与y,即用数学期望的方法求解关键点的坐标。这样得到的最终坐标值与高斯热图的最值位置相互对应,在深度学习框架中形成了端到端可微的坐标期望优化问题。因为高斯热图的值的浮点性,即坐标值权重的浮点性,所以DSNT在小尺度的高斯热图上可以回归出高精度的浮点坐标值。因此,DSNT可以保持端到端可微的情况下兼顾精度与模型大小,这是单一的全连接坐标回归与单一的高斯热图回归所不能具备的。本文引入DSNT算法来预测文档角点的坐标,实现文档角点的高精度定位。
2 DPENet模型设计
本文从姿态估计的角度,将文档图像中的单一文档视为一个姿态估计对象,将文档的四个角点视为姿态估计点,采用轻量化设计的MobileNet V2作为主干网络提取角点特征,再经上采样得到分别对应四个角点的高斯热图,利用DSNT结构对高斯热图进行处理,输出角点的高精度相对坐标,最后使用“四点法”实现透视变形文档图像的矫正处理。本文所提出的DPENet模型结构如图1所示,主要从模型结构、损失函数两方面进行详细介绍。
2.1 DPENet模型结构
DPENet网络结构可分为五部分,依次为:(1)输入部分(Input);(2)主干网络部分(MobileNet V2 backbone);(3)上采样部分(Upsample);(4)DSNT部分;(5)输出部分。输入部分采用文献[3]中的输入尺寸设计,具体尺寸为384×256×3(H×W×C);输出部分采用归一化坐标预测,输出四个姿态估计点的浮点型相对坐标,可有效避免整形坐标带来的误差,保证了DPENet的高精度。主干网络部分、上采样部分、DSNT部分具体细节如下。
2.1.1 主干网络部分
如图1中的标识为“MobileNet V2 backbone”的部分所示,MobileNet V2结构中,由浅层到深层,通道数逐渐增加,特征图尺度逐渐减小,与后面的上采样结构构成编/解码器结构,因此主干网部分可称为DPENet的编码器模块。MobileNet V2的默认输入尺度为224×224×4,此处根据DPENet的输入部分的尺度设计修改为384×256×3,经过1个卷积层,17个瓶颈残差块,再接1个卷积层,最后的输出尺度为12×8×1 280,即DPENet主干网络的输出尺寸。详细结构参数如表1所示。其中,瓶颈残差块(Bottleneck)设计为线性瓶颈和倒置残差的结构,如图2所示。
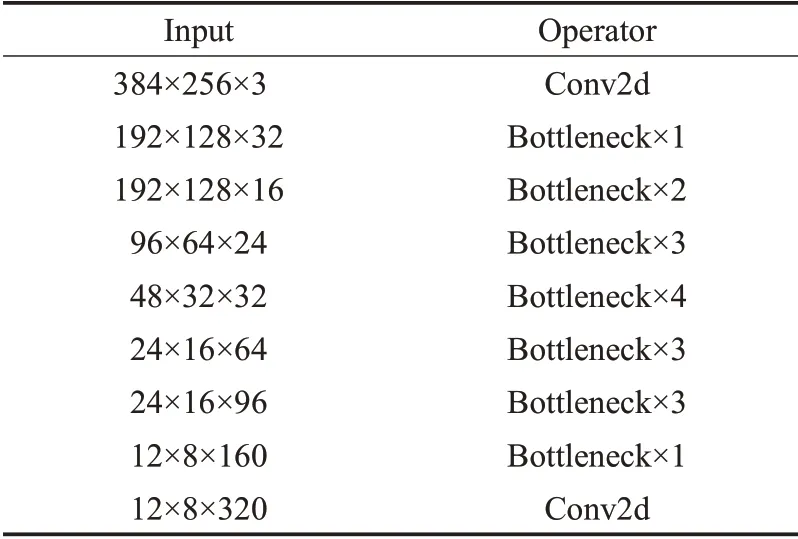
表1 特征模块结构细节Table 1 Details of features module structure
线性瓶颈结构使用1×1的卷积替代ReLU对3×3卷积和ReLU6后的特征图进行“激活”操作,可以在一定程度上减少ReLU6非线性变换带来的信息损失。
倒置残差结构在残差连接上与标准残差结构[17]一致,但在通道数设计上,先用1×1卷积核进行通道升维操作,再用3×3的卷积核进行通道数固定的卷积操作,最后用1×1的卷积进行通道降维操作,使前后层级的通道数比中间的通道数少。其中,中间层采用深度可分离卷积实现,大大降低了参数量,这是MobileNet V2轻量化的主要原因。在COCO数据上与SSD模型进行的性能比较实验[14]中,MobileNet V2+SSDLite的结构仅以4.3×106的参数量实现了22.1%的mAP,较SSD300仅低1.1%,而SSD300的参数量高达3.61×107,充分说明以MobileNet V2为主干网络,可以在付出极小的精度损失代价下大幅减少模型参数量。另外,倒置残差结构中采用的激活函数为ReLU6,它与ReLU的区别在于其输出包含上限,上限值为6,使得MobileNet V2具有更强的鲁棒性。
2.1.2 上采样部分
经过DPENet的主干网络,图像的特征信息被“编码”,特征图尺度变小,通道数变多,要想得到更高精度的姿态点位估计,还需进行“解码”操作,则上采样部分可称为DPENet的解码器模块。
如图1与表2所示,上采样部分共分为五层,第一层为普通的1×1卷积层,对上一部分输出的特征图进行通道维度上的低维度投影,特征图尺度保持不变,通道数降为256,为上一部分与本部分的衔接层;第二、三、四层为三个连续的反卷积层,每经过一层,特征图尺度扩大一倍,通道数减半;第五层为上采样部分与下一层的衔接层,输入输出特征图尺寸不变,即96×64,输出通道数为4,分别对应文档图像的四个角点的高斯热图,即高斯热图的分辨率为输入图像尺寸(384×256)的两倍下采样尺度,为主干网络编码结果(12×8)的三倍上采样尺度,处于一个适中的尺度,这保证了算法在精度与参数量之间的权衡。如图3所示伪彩色高斯热图,颜色由蓝色到红色,像素颜色越靠近红色,表示该点是文档图像角点的概率越高。明显可以看出,高斯热图中热点的相对位置与原图中角点的相对位置高度吻合。
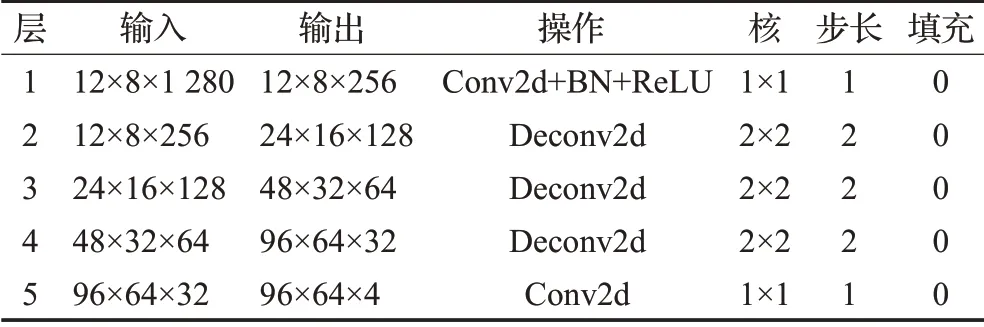
表2 上采样结构细节Table 2 Details of upsample structure
第一层除了基本卷积外,模型中还加入了批归一化操作与特征图激活操作,使用的激活函数为ReLU函数[18]。
2.1.3 DSNT部分
如图4所示,DSNT部分为高斯热图向姿态坐标点的转换模块,分两步实现。
第一步,对上一部分输出的四张高斯热图进行激活操作,将高斯热图中的数值归一化至0~1内,此时整张高斯热图中所有元素值的和为1,即每个元素的值转化为该元素所在位置的概率值。此处使用Softmax2d进行激活操作,如式(1)所示,其中w=64,h=96。
第二步,构建两个归一化的常量坐标矩阵,分别记为X与Y,一个代表x坐标,一个代表y坐标,两个常量矩阵的尺度与高斯热图的尺度一致且在位置上一一对应,各元素值可由式(2)计算得到,然后按式(3)进行Hadamard乘积再求和,得预测坐标(xp,yp),其中Hi,j、Hm,n表示高斯热图H在对应二维索引位置的元素值。
2.2 损失函数
如图1所示,DPENet模型的总损失函数L由Euclidean损失Leuc和高斯热图规范化损失Lreg组成,Lreg由超参数λ因子进行带权约束,总的损失反映DPENet模型的整体性能。
Leuc为真实文档图像姿态坐标点与模型预测坐标点之间的损失,衔接在DPENet网络结构的尾端,直接反映模型姿态估计的精度;Lreg采用JS散度构造,用于度量两个概率分布的相似度,此处Lreg度量预测的二维高斯热图与真实的二维高斯热图在分布上的相似度,可对高斯热图的分布起约束作用。Lreg直接反映模型预测的高斯热图的准确性,同时间接对DSNT与坐标预测起优化所用。
Leuc、Lreg、总损失函数L依次由式(4)、式(5)和式(7)表示。
其中,Cp、Cgt分别表示预测的坐标与真实的坐标标签。
其中,Hp、Hgt分别表示预测的高斯热图与真实的高斯热图标签。DJS(·||·)、DKL(·||·)分别为JS散度与KL散度的公式表示。JS散度为KL散度的变体,此处JS散度由KL散度表示,KL散度如式(6)所示。综上所述,本文以透视倾斜变形文档图像为研究对象,以本领域普遍使用的“四点法”为矫正手段,提出轻量型文档姿态估计网络DPENet,来解决文档四个角点的坐标的准确性问题。由于DPENet采用轻量化的主干网络MobileNet V2,整个模型的参数量大大降低的同时保留较高的精度,实现了DPENet的轻量化;引入DSNT模块对文档角点进行姿态估计,将文档四个角点的坐标值的求解转化为坐标期望值的优化问题,从而得到文档四个角点精确的相对坐标,且这种方法得到的坐标为浮点型坐标,相对于直接以高斯热图极值点回归坐标的方法得到的坐标更加精确,这也是DPENet拥有高精度和高准确性的根本。
3 实验与分析
3.1 实验准备
3.1.1 实验环境
本文的实验环境主要分为两种,模型的训练与测试在含有GPU的服务器环境下进行,而文档图像的矫正测试在个人笔记本电脑上进行,环境细节见表3。
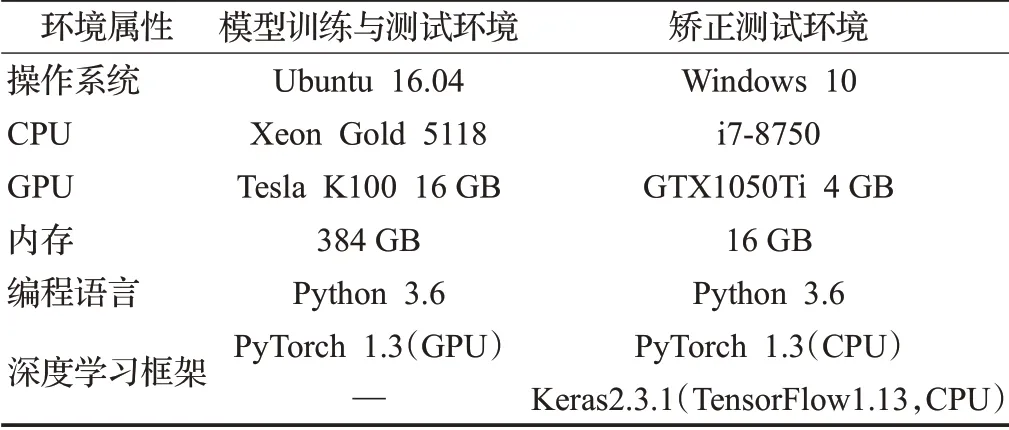
表3 实验环境Table 3 Experiment environment
3.1.2 模型训练配置
DPENet模型及相关的对比模型均在单GPU环境下训练,batch size统一设为128;均采用Adam[19](β1=0.9,β2=0.999,ϵ=10-8)优化器进行网络优化;均采用
ReduceLROnPlateau(mode=“min”,factor=0.5,patience=20)算法进行学习率的动态调节;初始学习率根据具体的模型情况进行探索性设定,保证该模型在具体的环境下可训练出更好的结果。
3.1.3 算法评估标准
本文主要从文档图像的姿态估计精度、矫正效果、姿态估计速度与矫正速度四方面对本文所提算法进行评估。
对于文档姿态估计的精度,本文使用文档四个角点的姿态估计坐标与真实坐标之间的平均位移误差(mean displacement error,MDE)进行评估,单位为像素(pixel),MDE越小表示姿态估计精度越高。记N为姿态估计点的数量,本文中N=4,则MDE可由式(8)表示,其中(xGiT,yiGT)与(xPi,yiP)分别表示真实的坐标标签与姿态估计坐标。
矫正效果主要用矫正成功的数量与矫正成功率评估,矫正成功的数量越多,矫正成功率越大,模型的矫正效果越好。记P、NR、NA分别为矫正成功率、矫正成功的数量、测试集数据总量,则算法的矫正成功率可由式(9)表示。
姿态估计的速度与矫正的速度均以单张文档图像的平均处理时间进行评估,平均处理时间越短,速度越快。
3.2 消融实验
3.2.1 模型结构可行性实验
为了获得最佳的模型结构,本文在设计模型时,对多种模型结构进行了对比分析,如表4所示。本文共分析了六种模型结构,这六种模型的主干网络均采用MobileNet V2;上采样部分,模型(1)~(3)使用DUC结构[20],模型(4)~(6)使用反卷积结构;坐标回归部分,模型(1)(4)、(2)(5)、(3)(6)分别使用全连接回归结构、高斯热图回归结构、DSNT结构,其中高斯热图回归结构使用的是最简单的单级监督模式,即仅对模型的尾部输出的特征图求损失。
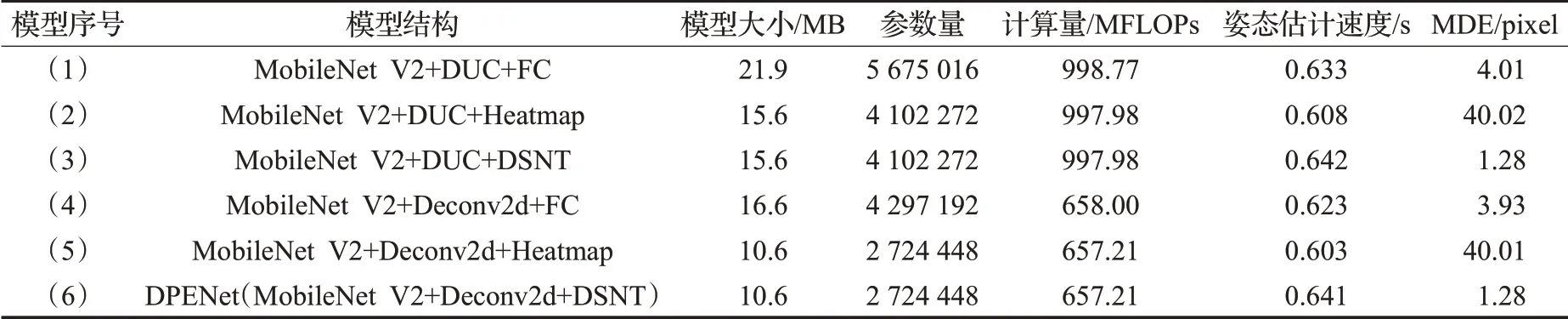
表4 六种模型对比Table 4 Comparison of six models
对比模型(1)(4)、(2)(5)、(3)(6)可知,在相同层数与通道数的情况,DUC结构与Deconv2d结构在精度上基本相近,但DUC结构的模型在模型大小、模型参数量、计算量以及姿态估计速度上均高于Deconv2d的模型,说明Deconv2d结构可以在保证同等精度的情况下保持更好的模型轻量化特性。
通过模型(1)、(2)、(3)与模型(4)、(5)、(6)之间的对比可知,全连接结构的模型体量最大,高斯热图回归结构与DSNT结构体量相等;姿态估计速度上三者的推理速度比较相近,DSNT结构低于高斯热图结构;在精度方面DSNT结构精度最高,全连接次之,高斯热图回归模型精度最低且远远低于前两者的精度。
DSNT结构模型与高斯热图回归结构模型相比仅增加一个DSNT结构块,但不增加模型参数,因此两者体量相当;但DSNT结构模型多一步坐标期望计算,因此推理速度略慢;全连接结构打破了特征图的空间信息,因而精度低;高斯热图得出的坐标为热图对应的坐标位置,在上采样还原至原始图像尺度时存在理论误差上限,因此高斯热图回归结构精度较低。
DSNT结构为全连接结构与高斯热图结构的综合,既保证了特征图的空间信息不被打破,又可像全连接结构一样直接输出文档角点的坐标值,同时坐标值为浮点坐标,不存在上限,故其精度最高。
本文在合成数据集[3]和SmartDoc-QA数据集[21]上对DPENet进行测试,并对姿态估计结果进行高斯热图可视化展示,如图5所示,第1行为合成数据集上的结果,第2~4行为SmartDoc-QA上的结果,依次为大、中、小三种尺度。左侧第1列为样本原图,第2~5列分别为DPENet输出的文档左上、右上、左下、右下角点的高斯热图,第6列图片为高斯热图渲染结果。DPENet输出的高斯热图与原始文档图像的文档角点具有精准的位置对应关系,其不仅在训练的验证集上表现良好,在新数据上依然有良好的姿态估计结果,这说明DPENet对新数据具有良好的适应性。且新数据具有大、中、小三种不同的尺度,故DPENet对姿态点的预测具有良好的空间泛化能力。
综上所述,由MobileNet V2、Deconv2d与DSNT构成的DPENet模型为实验中的最优模型,具有模型小、参数量小、计算量大、推理速度快、精度高、数据适应性强、空间泛化能力强等优点。
3.2.2 超参数消融实验
由式(7)可知,权重λ会影响模型的训练结果。为了设置合适的λ值,本文对8组λ值(1、5、8、9、10、11、12、15)进行实验分析。
如图6所示,λ=5时总的损失值最小,但Leuc与Lreg并未达到最小;λ=11时Leuc与Lreg均达到最小值,但总的损失未达到最小值。由式(7)的形式可知,当λ值较大时,即使Leuc与Lreg均较小,总的损失值亦可能较大,而在DPENet中Leuc直接反映模型的姿态估计的精度,因此,本文以Leuc为主要参考对λ值进行最终的选定,此处λ值最终设定为11。
如图7所示,对λ=11的模型共训练了24轮,最终在验证集上测得Leuc=0.016 7,此时得到本实验中最好的模型训练结果。
3.3 对比实验
本文将DPENet与当前面向文档图像矫正处理的模型(文献[3]、文献[4]、文献[5])在SmartDoc-QA数据集[21]上进行了对比,结果如表5所示。

表5 不同模型性能指标对比Tabel 5 Comparison of performance indexes of different models
在模型大小、参数量、计算量方面,文献[4]模型处于最优状态,这是因为其采用的主干网络为早期在计算资源受限时使用的小型模型AlexNet[22],DPENet虽比文献[4]模型的体量大,但与文献[3]模型和文献[5]模型相比,DPENet的体量远远低于两者。
在精度方面,文献[3]模型为个人复现,MDE=2.74,原文献中MDE=2.45,存在细微的差别;文献[4]模型与文献[5]模型为开源实现。DPENet的精度最高,MDE仅为1.28,性能较文献[3]模型提升53.3%。
在矫正速度上,文献[4]模型处于最优状态,文献[5]模型次之,DPENet第三。文献[4]模型虽速度较快,但由于其由两个模型组成,且第二模型一般需要多次且不定次数的调用,一般数据难度低时速度快、难度高时速度慢,此处可参考文献[23]中医疗文档图像数据的矫正速度(1.21 s>0.37 s),其矫正时间随数据的变化而变化,不具有稳定性。文献[5]模型矫正速度快是因为其使用了速度更快的深度学习框架Keras。而DPENet的矫正速度不因数据的变化而变化,既具有稳定性又能保持较快的矫正速度。
对于矫正成功数量、矫正成功率,DPENet模型均处于最优状态,远远优于其他三种模型,较文献[4]模型提升44.4%,体现了DPENet优越的准确性。
图8为不同模型的图像矫正效果对比,其中第1列为SmartDoc-QA数据集中的样例原图,分别为大、中、小三种尺度,第2~5列分别为文献[3]模型、文献[4]模型、文献[5]模型、DPENet的矫正结果。从空间泛化性看,四种模型对大尺度的样本均有较好的矫正效果,其中在DPENet的矫正结果中文档背景残留最小;在对中、小尺度样本进行矫正时,在文献[5]模型的矫正结果中出现大面积的背景残留,而文献[3]模型的矫正结果中不仅有背景残留,还出现内容残缺的现象,文献[4]模型的矫正结果中也存在一定的背景残留,而DPENet的矫正结果中无内容残缺,且背景残留也最小,这说明DPENet具有更好的矫正效果和更好的空间泛化性。
综上所述,DPENet可以在平衡速度和体量的条件下实现最优的矫正准确性和精度,并具有更好的矫正效果和空间泛化性,这得益于DPENet对文档角点的良好的估计效果。
4 结束语
本文针对当前基于深度学习的文档图像角点定位与矫正算法的不足,结合当前的姿态估计技术,引入姿态估计算法来对文档图像进行角点的定位与矫正处理,提出一种文档姿态估计网络DPENet,并在开源数据集上进行测试,与当前主流的深度学习方法进行对比分析。实验结果表明,DPENet在保持轻量化的条件下拥有最高的精度,不仅具有全连接坐标回归的端到端的特性,还具有高斯热图回归方法的良好的空间泛化性、高精度等特性,可以高精度且实时地实现透视变形文档图像的姿态估计与矫正处理。但DPENet也有不足之处,DPENet中的DSNT模块的第一步操作为Softmax2d,则姿态估计坐标被限定在特征图所对应的输入文档图像的坐标范围之内,故DPENet不能处理缺角的文档图像。如何对缺角文档图像进行姿态估计与矫正处理将是下一步的研究内容。
