面向闪存的树型索引综述
2022-11-20武晓晓谢开斌高锦涛刘凇佐巫思敏
孙 鉴,武晓晓,谢开斌,高锦涛,刘凇佐,巫思敏
1.北方民族大学 计算机科学与工程学院,银川 750021
2.宁夏大学 信息工程学院,银川 750021
随着大数据时代的蓬勃发展,各行各业对数据存储提出了更高要求。传统的磁盘存储已无法满足大数据时代的存储需求,因此,经过不断的研究和创新,闪存诞生。闪存作为一种新型存储介质,由于其具有低功耗、高抗震性[1]等优点,很快被应用于固态硬盘(solid state drive,SSD)[2-3]。
固态硬盘,简称固态盘[4],主要是由NANDFLASH存储芯片阵列构成的电子设备,其内部包含控制单元、存储单元(FLASH芯片、DRAM芯片)以及缓存单元三个主要部件。与传统的由磁头、磁盘臂、盘片构成的机械硬盘磁盘不同,整个SSD的内部结构中没有机械部件,而是由电子芯片及电路板组成,图1为SSD基本结构。
从图1中可以看到固态硬盘控制器、闪存阵列、寄存器三个主要部件的结构。
SSD控制器是重要组件之一,主要有两个作用:一是应用FTL(flash translation layer)算法控制I/O请求,将数据分发至NANDFLASH芯片上进行操作,承担SSD中的逻辑地址与NANDFLASH芯片中物理页的地址映射。二是调配NANDFLASH芯片上的数据负荷,保证磨损均衡。不同厂家应用的SSD主控的功能差异较大,这使得SSD整体在读写操作的性能、整盘寿命、垃圾回收算法等各个方面产生很大的差距。
FLASH闪存阵列:NANDFLASH芯片是SSD固态硬盘中存储数据的主要介质,其数据的读写操作较传统磁盘有很大的不同。传统磁盘中,数据存储在磁性盘片上,以扇区为单位按照扇区、磁道、柱面、盘片的层次依次组织数据的存放方式,并以机械方式来读写数据。但是在SSD固态硬盘中,数据是存放在NANDFLASH芯片上,以物理页为基本的存储单位,按照物理页、物理块、分组、晶片、芯片的层次结构依次存放,以信号线和数据线的方式来读写数据。在SSD固态盘中,闪存芯片通过通道(channel)各自独立地连接至控制器中,以这种并行的方式组成NANDFLASH芯片阵列。因为SSD控制器中的每个通道可以独立工作,所以SSD可以充分发挥NANDFLASH芯片阵列的并行性,从而获取非常优异的读写性能。
闪存具有以下几个显著特点:
(1)读写速度不对称:闪存写操作的总体访问延迟比读操作的总体访问延迟要高很多。一般来说,闪存写延迟比读延迟高一个数量级[5]。
(2)擦除操作粒度与读写操作粒度不同,读写操作的最小单位是页[6],擦除操作的最小单位是块[7]。
(3)写前擦除[8]:闪存在写页面前需要先对这个页面所在的块执行擦除操作,即闪存不支持原地修改数据[9]。为了确保块内原先存储的数据不丢失,必须在执行擦除操作之前将该块的有效页面读取出来,待擦除操作完成后与需要写入的数据一同写回。这一过程带来的实际写操作数量远比本来需要写入的数量多,造成了“写放大”问题,同时带来了较大的延迟。为了减少每次更新操作的时间开销,闪存通常采用异地更新[10]策略,即先把更新数据存储到其他空闲页中,将原来旧数据所在的页标记为无效页[11],等到垃圾回收[12]时统一执行擦除操作,将原来旧数据所在的页变为空闲页。此外,垃圾回收会定期回收无效页。
(4)使用寿命有限:频繁的写操作会带来大量的擦除操作,而闪存芯片的擦除次数有限,使得闪存芯片在达到有限擦除次数后寿命耗尽,造成严重的数据丢失。通常,固态盘中设计闪存转换层来实现磨损均衡,从而延长闪存的使用寿命。
索引是存储系统的存储引擎,是整个存储系统的核心,直接决定了存储系统能够提供的性能和功能。同时,索引也是数据库管理员(database administrator,DBA)用来分析工作负载性能最重要的工具之一,因此对索引技术的研究尤为重要[13]。由于闪存的物理特性,基于传统存储系统的索引结构不能直接应用于固态盘上,因此,研究适用于固态盘的索引结构迫在眉睫。
传统磁盘索引结构,如B-tree[14-16](源码:https://github.com/tidwall/btree)通过减少磁盘访问次数来提高数据库性能,但是B-tree及其变体[17-18]在执行更新操作时会产生级联更新[19]现象。级联更新是指当叶节点需要更新时,由于闪存写前擦除和异地更新的特点,需要先将叶节点所在的页块全部写入内存中,再将更新数据和节点数据合并后一起写入新的空闲块中。同时,叶节点对应的父节点以及更高层的父节点的指针也要发生变化,意味着也需将这些父节点的节点数据写入到新的闪存页面中,这样便会产生大量的、代价高昂的闪存写操作。显然,传统的B-tree索引在闪存上将出现严重的性能退化现象[20],特别是在更新操作密集的工作负载中。因此,不经过任何转换优化,直接将B-tree应用到闪存上是不可行的,需要对基于磁盘设计的B-tree进行一定程度的修改,使其能够适配闪存的物理特性,尽量减少针对闪存的写操作,才能充分发挥闪存的存储优势。
目前基于闪存的索引机制研究按照索引结构进行分类,可分为:(1)基于闪存的哈希索引[21]机制研究,主要聚焦于线性哈希和可扩展哈希;(2)基于闪存的树型索引机制研究,主要聚焦于B-tree与R-tree[22-23];(3)基于闪存的位图索引机制研究,主要聚焦于布隆过滤器[24-25]。
通过阅读大量文献,本文对面向闪存的树型索引机制的研究进行归类和总结,从索引更新策略的角度切入,将当前关于树型索引的研究分为三类:(1)延迟更新类索引;(2)追加写更新类索引;(3)自适应动态更新类索引。本文详细描述了三大类别索引结构的核心思想及其具体实现。希望通过这样的总结归类方法,能够让研究者们有所收获。三类所包含的索引结构如表1所示。

表1 索引分类Table 1 Index classification
延迟更新方法首先将数据更新引发的索引变化缓存在内存中,当缓存的数据满足设定条件时再执行批量更新操作。该方法通过消除冗余操作和批量提交的方式降低了写操作代价。
追加写更新的思想如同日志文件系统,直接将更新内容追加写到末尾。当上一层索引的容量达到阈值后,执行归并操作,合并至下一层,依次类推,直至当前索引层不再发生溢出。在合并的过程中,一般只产生连续写操作。
自适应动态更新的思想是根据索引节点的读写负载情况实时调整索引结构。若工作负载是读密集型的,则将索引结构自动调整到适合读密集访问模式的结构,提高读操作效率[49-50]。
本文的主要贡献:(1)概述了闪存和树型闪存索引的研究现状以及目前研究所面临的挑战;(2)通过分类的方式总结这些树型索引结构采用的主要技术,并描述了各个主要技术的核心思想;(3)讨论目前闪存索引研究存在的问题,提出未来的研究方向和趋势。
1 延迟更新类索引
1.1 BFTL
BFTL(B-tree layer on flash memory)由缓冲区和节点转换表组成,当针对B-tree的某个节点执行插入、删除或更改操作时,更新信息将首先被缓存在缓冲区中;缓冲区满后,信息将被更新到闪存中,同时,BFTL将为这些信息建立对应的索引单元,并将其写入闪存物理页中。索引单元和节点的相对应关系通过节点转换表来获得。但BFTL存在以下缺点:(1)由于B-tree的节点信息分散在不同的物理页,访问一个节点往往引起多次的读操作;(2)节点转换表必须存储在内存中并不断增长,这会消耗大量的内存空间;(3)由于BFTL缓冲区只是按序记录更新信息,当节点执行分裂或其他操作时容易造成过多的冗余信息,使得缓冲区利用率较低。
1.2 IBSF
IBSF(index buffer management scheme)是对BFTL的优化,在闪存上的性能表现更好。作为一种典型的采用延迟更新策略的B-tree索引结构,IBSF取消了节点转换表,并对缓冲区中的信息进行了处理,这在一定程度上减少了冗余信息。IBSF的核心思想是:(1)与BFTL不同,当缓冲区中的更新信息数量达到一定的阈值时,IBSF将关于同一个节点的信息写入同一个闪存物理页中,因此不再需要节点转换表;(2)IBSF删除缓冲区中的冗余节点信息从而推迟写闪存的时间。因此,IBSF能显著减少对闪存的写操作次数。但IBSF也存在不足:(1)缓冲区每个更新单元除记录更新信息外,还需记录所属节点的信息,造成了信息冗余;(2)更新信息在缓冲区中是按序存储的,导致在执行增删改查等操作时需遍历整个缓冲区;(3)执行缓冲区替换操作时,IBSF忽略了更新信息访问频度不均衡的问题,导致更新次数频繁的节点被刷新至闪存,带来更多的写操作次数。上述缺陷的存在,使得IBSF在许多实际应用中不能取得很好的效果。
1.3 HNLBI
HNLBI(head node list B-tree indexing)索引是对IBSF的改进,该索引基于最长节点链表替换算法,将缓冲区内的索引单元重新组合,采用延迟更新的索引优化策略。HNLBI索引的主要思想是:(1)若关于某个节点的更新信息首次插入时,则首先在缓冲区中为该节点创建一个头节点,并将该头节点加入到头节点链表中;若待执行的是删除操作,则在头节点中创建一个用于更新节点删除信息的位图;若待执行的是插入操作,则在头节点后添加一个存储节点,用于存储待插入的键值信息。(2)若缓冲区中已存在某节点,且有关于该节点的更新信息出现时,HNLBI将会遍历头节点链表,找到该节点,随后根据更新操作的类型做出相应的操作。若为插入操作,则在该节点所属的存储插入操作信息的链表尾部创建新的存储节点,记录插入信息;若为删除操作,则遍历该节点所属的存储插入操作信息的链表,若发现已存在键值相同的冗余存储节点,则删除该冗余节点,并更新头节点中的位图来记录删除操作信息,若没有发现冗余存储节点,则直接更新头节点中的位图即可。(3)HNLBI索引的头节点链表与每个节点所属的存储插入信息的链表,两者组合形成一个头节点链表。当缓冲区溢出时,在执行替换操作前先遍历头节点链表,而后根据头节点信息找出链表长度最大的链表进行替换。这样的替换策略可以为缓冲区提供更多的空余空间,并有效减少了替换操作的执行次数,从而在较大程度上减少了闪存写操作次数。
1.4 CF-HNLBI
CF-HNLBI(code-first head node list B-tree indexing)是针对HNLBI缓冲区替换策略的改进。HNLBI缓冲区替换策略只是简单选择最大长度的链表进行替换,并未考虑到节点的更新频度。因此,CF-HNLBI设计了基于冷热分区的替换算法,加入了冷热分区的概念,热区中存放更新频繁的节点数据,冷区中存放更新不频繁的节点数据。当发生缓冲区替换时,CF-HNLBI只选择冷区中的节点进行替换。CF-HNLBI为头节点设置冷标志位来反映该头节点所对应的B-tree节点的更新频度。当冷标志位为1时,说明该头节点为冷节点,其对应的B-tree节点更新不频繁;相反,当冷标志位为0时,说明该头节点为热节点,其对应的B-tree节点更新频繁。另外,当位于缓冲区中的冷节点被再次访问时,则需将此冷节点标记为热节点,即将冷标识位设置为0。
1.5 LU B+tree
LU(lazy update)B+tree将缓冲区划分为页面缓存区和延迟更新区,页面缓存区用来缓存B+tree的节点,延迟更新区用来缓存节点的更新请求。当有新的更新请求时,它不是立即提交到B+tree,而是先暂时存储在延迟更新池中。当有新的更新请求但延迟更新池已满时,采用提交策略选择一组更新请求进行提交,从而为新的更新请求留出存储空间。因此,选择哪个组作为提交的组是一个关键问题。
CF-HNLBI设计了两种解决方案:一是最大规模策略。若新的更新请求在池中有要加入的现有组,就会发生命中。由于池的容量是有限的,为了提高命中率,应该在池中最大限度地保留更多的小群组,因此该策略选择容量最大的请求组作为受害者组。这里,组的大小定义为存储在组中的更新请求的数量。二是基于成本的策略。与最大规模策略类似,该策略的目标是使选择受害者组的代价最小化。仿真结果表明,LU B+tree在保持查询效率的同时,显著提高了传统B+tree的更新性能。
1.6 MB-tree
MB-tree(modified B-tree)由批处理缓冲区(batch process buffer,BPB)、根节点、内部节点、叶节点和叶节点头(leaf node header,LNH)组成。BPB存储在主存中,其他部分存储在闪存中。MB-tree的结构如图2所示。
MB-tree设置批处理缓冲区(BPB)的目的是减少总的页写次数,以延迟更新。当执行插入操作时,若批处理缓冲区(BPB)未满,则直接插入条目,直至完全填满批处理缓冲区(BPB);若批处理缓冲区(BPB)被填满,BPB将会根据每个条目所属的叶节点对插入的条目进行分类。接下来,BPB选择拥有最多条目的叶节点,将新条目插入所选的叶节点。最后,将这个拥有最多条目的叶节点写入闪存中。通过这种方式,MB-tree在处理一组插入操作时只需执行一次写操作。
实验结果表明,与传统B-tree和其他B-tree变体相比,MB-tree显著减少了页写次数,在闪存上的性能表现更好,搜索速度比其他B-tree变体更快。
1.7 HF-tree
HF-tree类似于B+tree的结构,其引入了日志结构,以增加一定的读消耗为代价来换取低的索引维护代价。HF-tree通过组提交、更新合并以及多级延迟的方式来提高更新性能。
HF-tree由BF-tree和Tri-Hash两部分组成。它的优点在于:(1)高速的更新性能,Tri-Hash通过块提交和写延迟的方式有效提高索引整体的更新速度;(2)高效的查询性能,HF-tree通过Tri-Hash来查询最新数据,通过BF-tree来查询未修改数据,有效提高了索引整体的查询性能;(3)低垃圾回收成本,HF-tree将更新后的数据打包成块写入闪存中,并且在数据移动时也以块为单位,有效避免了写操作,减少了垃圾数据的产生。
其中,BF-tree采取块存储模型,根节点、索引节点、叶子节点分别对应存储在根块、索引块、叶子块中。需要注意的是,叶子块的前48页存储叶子节点,后16页则用来存储叶子节点的更新。但若一有叶子节点的更新发生,就立即写入叶子块中,会导致叶子节点迅速消耗光,因此HF-tree设计Tri-Hash来实现延迟更新。Tri-Hash结构如图3所示。
当一个索引项更新时,会经历从RAM Hash到Leaf Hash的级联缓冲过程,最后当Leaf Hash满时,启动合并操作将Leaf Hash中的更新写入到BF-tree中。这样,更新被有效地延迟与合并,从而减少额外的写次数。此外,数据的移动始终以块为单位,因此在数据移动的过程中,Tri-Hash能够有效减少垃圾数据的产生。
通过大量和BFTL及IPL的对比实验充分说明了HF-tree在更新上的卓越性能,同时在对等查询和范围查询上也表现出优越的性能。
延迟更新类索引的主要思想是将更新信息首先保存在缓冲区内,达到某些条件后再更新到闪存中,以减少闪存的读写操作。从索引结构上可以分为B-tree及B+tree两类:在以B-tree作为索引结构的优化算法中,BFTL在延迟更新的思想上设计了节点转换表来建立索引单元和节点的应对关系。IBSF则以追踪索引节点在物理页面的写入模式来替代BFTL的节点转换表,弥补了BFTL中“内存占用量大”及“写入次数多”的问题。HNLBI在处理节点映射方面引入了“最长节点链表替换算法”,减少了缓冲区的空间代价。而CF-NHLBI在考虑节点更新的冷热频度的基础上使用“冷热分区替换算法”代替HNLBI中的最长节点链表算法,降低了Btree中节点的更新频度。MB-tree使用批处理思想来处理缓冲区内的条目,保证一组插入操作仅仅在闪存中执行一次写操作,从而显著降低闪存中的写操作。在以B+tree作为索引结构的优化算法中,LUB+tree将缓冲区划分为页面缓存区和延迟更新区,并设计了两种提交策略保证查询效率及更新性能。HF-tree引用了日志结构来降低索引维护代价,这种方式带来了优秀的更新性能和较快的查询性能。综上,延迟更新类索引方法除了考虑索引查询、闪存读写之类的常规性能指标外,还额外考虑了缓冲区利用率、冷热均衡等因素,而这类因素也是延迟更新类索引优化的切入点。
2 追加写更新类索引
2.1 LSM-tree
LSM-tree又称日志结构合并树(log-structured merge-tree),被用于SSD的日志结构文件系统[51](源码:https://github.com/intfrr/lsmtree)。
LSM-tree的核心思想是利用顺序写来提高写性能,如图4所示,它的顶层树位于内存中,其他层的树位于闪存,当上层树的容量达到阈值时,就会启动归并算法,上一层向下一层归并,依次类推,直至当前层不再溢出。虽然LSM-tree这样的设计会稍微降低读性能,但通过牺牲小部分读性能换取高性能写,使得LSM-tree成为非常流行的存储结构。
2.2 FD-tree
FD-tree由香港科技大学研究团队提出,是一种使用对数方法和分级级联技术[52]设计的树索引(源码:https://github.com/Kukos/FDTree---cost-model)。FD-tree由两部分组成,最顶层是存储在内存中的一个小的B+tree,叫作Head tree。另一部分是存储在闪存中的顺序排列的多层连续页面,每层能够容纳的数据量按对数方法组织。FD-tree在相邻页面间插入栅栏,使得查询时允许在下一层继续搜索,而无需每次从头开始进行扫描或二进制搜索。图5说明了FD-tree的结构。
FD-tree的随机写操作仅限于小区域的Head tree中,将大量的随机写累积转化成顺序写,当上层容量满后,向下一层归并[53]。FD-tree的归并操作首先顺序读取相邻两层的所有页面,然后进行归并,并将归并后的数据写入下一层的页面。这样做不但可以避免大量随机写,还能有效减少闪存的擦除次数,从而提高闪存的寿命。
2.3 CLR-tree
CLR-tree(compact log R-tree)是基于R-tree提出的一种新型索引结构。CLR-tree的设计并没有改变R-tree的内部结构,只是在R-tree的基础上增加了一个日志区域,并针对加入日志会导致读取操作增多的缺陷,设计了日志压缩。所谓日志压缩就是通过将属于某个节点的更新操作合并在一起,并将对于某个节点的更新尽量写到一个页中,以减少写次数。这样的设计使得随机写转为顺序写,较大程度地提高了索引的整体性能,并且日志压缩大大节约了日志查找时间。实验表明CLRtree的性能优于现有的方法。
追加写更新类索引的主要思想是通过将大量随机写转换为顺序写来提升性能。LSM-tree设计了层次化的数据组织结构,并通过层次间的归并存放节点数据。FD-tree除了在闪存内保存了LSM-tree的层级结构,还额外设计了内存中常住的Head tree保存少量随机写来提升性能,并在闪存的层级结构中设计“栅栏”来提升查询效率。CLR-tree结构设计基于R-tree,并应用了日志压缩技术来提升索引性能。综上,追加写更新类索引方法额外考虑了索引结构、查询效率等因素,而这类因素也是追加写更新类索引的优化方向。
3 自适应动态更新类索引
3.1 LM-B+tree
LM-B+tree索引结构根据闪存页读写负载情况,将索引的缓冲操作逻辑映射于B+tree特定节点,同时在系统运行过程中,LM-B+tree根据索引影响因子的状况,动态调整预存页大小及合并时机。
LM-B+tree由一棵B+tree和若干个预存页组成。索引节点的更新首先根据页面负载代价,判定是否更新在预存页中,若要更新在预存页中,检查预存页是否已满,如果未满,就直接写入,如果预存页已满,迭代更新至下一级预存页中,直至更新到叶子节点的父节点;若更新至缓存页将产生较大代价,则合并更新至B+tree。查询时,LM-B+tree首先根据关键字查找相应的预存页。
预存页与日志页的不同在于:
(1)数量上:LM-B+tree根据B+tree的各个层节点读写的负载情况,动态划分预存页对应的节点数。
(2)存储内容上:日志页仅缓冲了对索引更新操作的日志记录,预存页考虑到闪存读写粒度特性,使用经典的最近最少使用(least recently used,LRU)算法,在存储了更新记录的同时存放了经常使用的索引记录,更新记录具有更高的存储级别。
(3)写缓存页时:插入和删除直接写入预存页,更新若出现范围跨度时则需先删除后写入更新对应的预存页内容。
实验结果表明,相对于BFTL等,LM-B+tree的性能更稳定。
3.2 FlashDB
FlashDB是一种新型的自适应索引技术,它设计了一种代价估算算法,根据索引节点的读写比例选择相应的更新方式,将工作负载分为写密集型和读密集型,写密集型负载采取日志存储模式,读密集型负载采取磁盘存储模式。
FlashDB的日志存储模式是指,当有更新数据到达时,先将更新数据按顺序存储为日志。这样的设计提高了更新速度,但若要读取一条数据记录时,必须读取原始数据信息和存储在日志中的更新数据这两部分内容。因此,日志存储模式不适合读密集型的工作负载。
FlashDB的磁盘存储模式是指直接将索引当成数据存盘。因为闪存的读写速度不均衡,随机访问性能很好,访问索引时基本不会有延迟,但若更新操作繁多,闪存写的速度就会很慢,所以磁盘存储模式很适合读密集型负载。
3.3 LA-tree
LA(lazy adaptive)-tree是一种新型索引结构,采用以下两种技术:(1)级联缓冲,LA-tree将多个层的节点存入缓冲区中,缓冲区中保存了对这层节点及其孩子节点的更新操作。(2)一种在线自适应算法,LA-tree索引使用最优在线算法动态适应任意工作负载[54-55],从而为更新和查找提供有效支持。基于上述设计,使LA-tree索引在查询密集和更新密集的访问模式下都有较高效率。
3.4 DB-tree
DB-tree索引将更新操作以“伪B+tree”的结构形式存储,从而避免检索时扫描整个更新日志区;以分支合并的方式使更新操作有针对性地聚集于闪存页;引入更新缓冲区大小及合并频率的自适应机制使闪存数据库适用于不同的读写负载。
DB-tree由OB-tree和NB-tree两部分组成,其中OBtree是一棵传统的B+tree,NB-tree为一棵“伪B+tree”。DB-tree纯闪存,无日志,能够根据闪存负载情况,自适应调整缓冲区大小及合并操作。“伪B+tree”的设计使得DB-tree在执行检索操作时无需扫描整个缓冲区。因此,DB-tree减少了重新调整索引的次数以及合并操作的代价,加快了更新检索速度,提高了索引的整体性能。
自适应动态更新类索引的主要思想是根据不同的读写特征采取相应的索引策略来提升索引性能。LMB+tree提出了预存页的设计,用来保存索引更新的操作日志,并根据负载情况动态划分节点对应的预存页。DB-tree在缓冲区内针对大小及合并频率引入动态更新机制,使其闪存数据库可以适应多种类型负载。FLSHDB中索引节点的更新方式取决于负载的读写比例,其中日志更新模式可以有效提升更新速度,而磁盘更新模式适合读密集型负载。LA-tree借鉴了最佳写更新类索引的多层级模式,并应用了最优在线算法来动态适应工作负载。综上,自适应动态更新类索引的优化更关注索引结构及自适应的索引策略设计。
4 讨论
本章主要讨论各种索引算法本身的优缺点和横向之间的对比结果。表2为对比表格中符号的具体解释,表3和表4对论文中罗列的索引进行了比较,其中“—”表示在论文中没有明确说明。以上索引仅在某几个方面优化了索引性能,并未全面考虑到其他影响因素。可以看出:

表2 符号含义Table 2 Symbol meaning
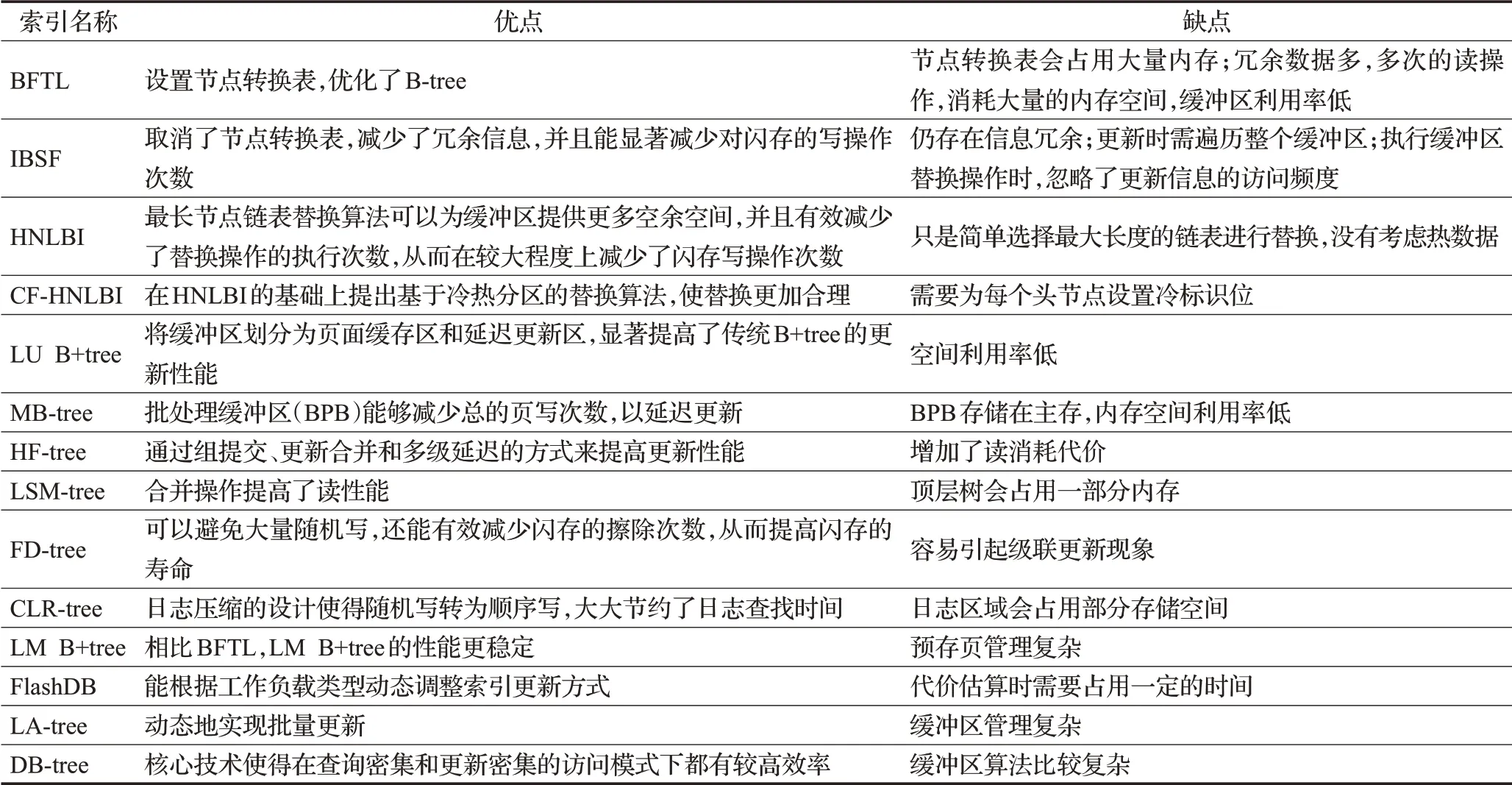
表3 索引优缺点总结Table 3 Summary on advantages and disadvantages of index
(1)每种索引各有优缺点,因此,如何针对各个索引做到扬长避短,最大限度地规避劣势,利用优势,是接下来研究的可行方向。
(2)表4中,IBSF相较于BFTL,更新性能、查询性能以及空间复杂度都有较大提升。BFTL通过将节点分散到多个页面来交换读和写,并且由于维护的辅助信息,它还会增加主内存和辅助内存开销,BFTL慢慢已不再适用于当代SSD。IBSF试图通过节点转换表来延迟缓冲区溢出,然而它的性能仍然严重依赖于主存。
(3)表4中,IBSF和CF-HNLBI执行一次插入的读代价相同,这是因为两者在每一层都需读取一个闪存页来获得该层某个B-tree节点的信息。另外,CF-HNLBI索引的闪存读代价与IBSF索引相同,均优于BFTL。
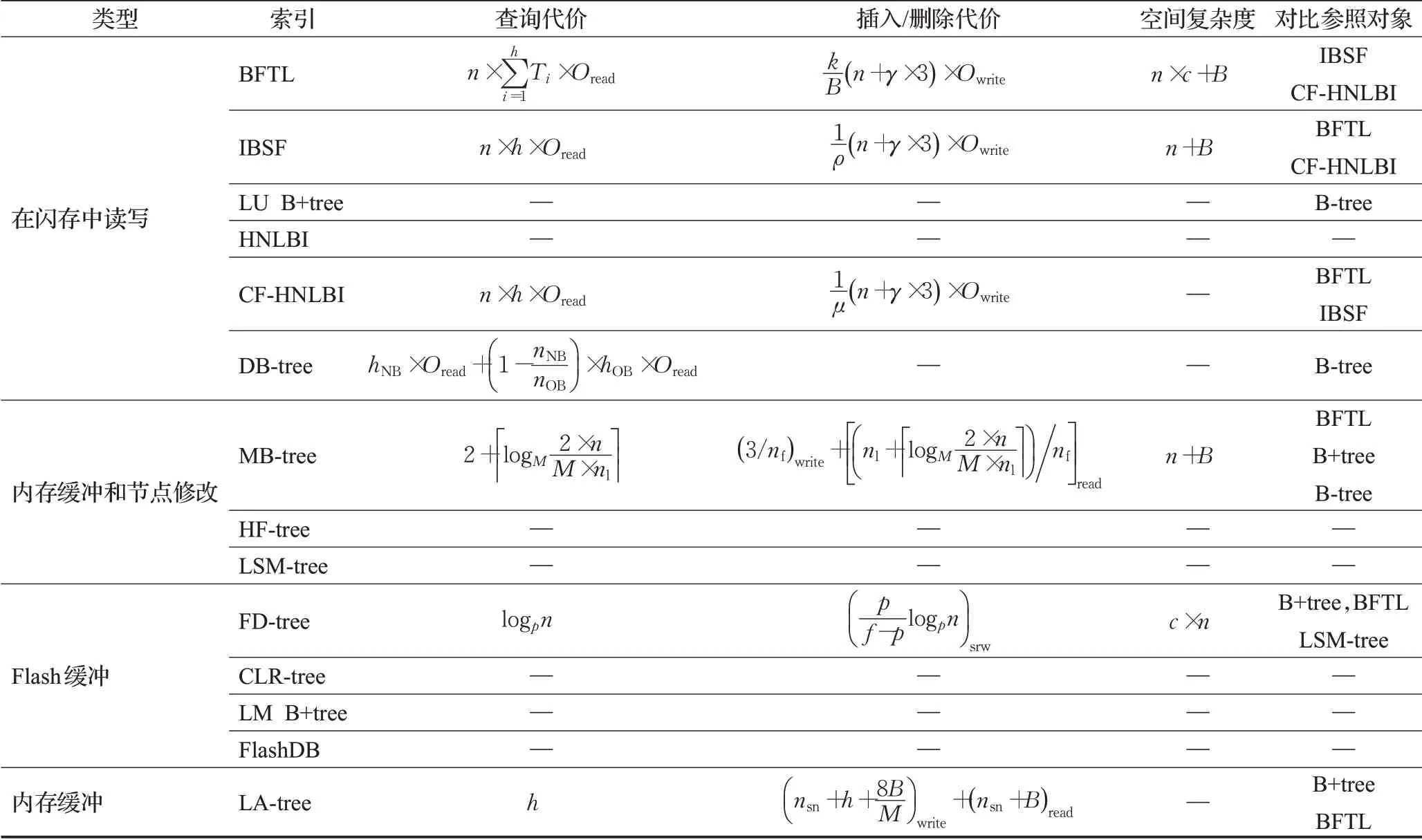
表4 索引性能对比Table 4 Index performance comparison
(4)LU B+tree的核心思想是通过将缓存区分区与组提交方式来控制写和读,然而这可能导致CPU和I/O代价较高。MB-tree设置批处理缓冲区以延迟树的更新重建,但需额外的辅助叶节点,因此需要额外的CPU和I/O操作来进行搜索和维护。
(5)FD-tree由于高度的增加,它的搜索时间可能比B-tree的搜索时间要差。此外,过多的写操作会损害SSD的寿命。
(6)LA-tree由于插入/删除操作都是通过重复的缓冲区清空和写入来实现的,写放大和读增加是不可避免的,对应操作的时间自然也较长。
5 研究展望
闪存由于卓越的I/O性能[56],以及低功耗、高抗振等特点,在存储领域发展飞速,被广泛认为是能够代替磁盘的新一代存储介质之一[57]。但传统磁盘索引无法适应闪存的特性。因此,基于传统磁盘索引的改进和优化,设计适配闪存的索引技术是关键,对不同类型闪存索引的研究至关重要。本文从索引更新策略角度出发,分别介绍了各类闪存索引,分析对比了各自的优劣势,发现现有闪存索引研究的一些技术瓶颈问题仍需深入研究,这些研究可以从以下几个方面展开:
(1)基于深度强化学习的索引优化
目前多数研究已经基本解决了索引在本地事务处理过程中效率方面的问题,但在云环境中,传统的索引方法很难应付数以百万计的数据库实例。传统的机器学习模型只能描述一个层次的学习过程,过于简单,难以求解海量数据索引的复杂问题。深度强化学习(deep reinforcement learning,DRL)将深度学习与强化学习结合,并利用其搜索强大解空间的能力来解决NP难问题,深度强化学习虽然对样本量需求减少,但训练时间较长,难以适应高强度的在线数据处理需求。随着大规模数据管理系统的应用,如何高效充分地利用深度强化学习方法来优化索引的更新,提升索引的性能将成为未来的研究趋势。
(2)面向海量流数据的分布式索引
随着Storm[58]、Flink[59]等高吞吐的分布式流计算平台大量涌现,海量流数据的处理与分析越来越受到人们的关注,但目前数据流的处理仍然依赖实时存储,流数据处理框架在存储层面只保存查询和计算结果,不存储完整数据流。海量流数据实时存储的一个关键挑战是在不影响读写性能的前提下高效实时地构建索引,以实现快速查询。现有的分布式索引可以分为主从式结构[60-61]和对等结构[62-63],在数据实时性、索引平衡性及系统性能方面存在一定缺陷。大数据流场景下,索引的更新频率高,存储开销大,如何在保证大规模存储系统性能的前提下,设计体量大、维度多、吞吐量高的流数据索引方法将成为未来的研究热点之一。
(3)面向新型非易失存储器的索引优化
伴随着新型存储介质的商用及存储架构的发展,当前索引技术将部署和应用到以非易失性存储器(nonvolatile memory,NVM)[64]为代表的、具有非易失、低延迟、高随机读写能力的新型混合硬件平台上,如何在此类环境下构建高效索引系统也将成为研究趋势。近两年的研究工作大多基于英特尔傲腾持久内存[65-66],并且针对过去基于DRAM模拟研究工作的问题,对傲腾持久内存的一些硬件特性进行了适配。但英特尔尚未公布傲腾持久内存的内部原理和架构,给相关的存储优化工作带来阻碍。
综上所述,在飞速发展的大数据时代,对闪存索引技术的研究仍任重而道远。思考如何在基于深度强化学习的索引优化、面向海量流数据的分布式索引优化以及面向新型非易失存储器的索引优化等方面取得突破性进展,将是未来的主要工作之一。
6 结束语
本文对面向闪存的树型索引研究现状进行了综述。首先对背景知识和研究问题进行了介绍,给出了树型索引更新策略面临的挑战,然后对现有的索引方法进行分类介绍,从索引的更新方式出发,根据类别分析总结了目前部分树型闪存索引的优势和缺陷,并提出未来闪存索引研究的一些方向和思考。
传统磁盘索引无法适应闪存的特性,因此,基于传统磁盘索引的改进和优化,使得索引能够适用于闪存设备,极大提高了存储速度,为大数据存储领域带来新突破。随着各类大数据存储技术研究的不断深入,闪存索引技术必须不断创新,适应直至融合于新的大数据发展潮流。
