基于V-Net模型的肺结节分割研究
2022-11-19梁富娥张伟吕珊珊顾旋刘东华
梁富娥,张伟,吕珊珊,顾旋,刘东华
(甘肃中医药大学 信息工程学院,甘肃 兰州 730000)
0 引 言
肺癌作为当今社会死亡率较高的癌症之一,已经影响到人类社会的正常生活,所以如何在早期发现并及时的进行诊断治疗是防止死亡率增加的有效措施。肺癌在人体内早期的表现形式为结节,表现形式并不显著,由于结节在人体的位置不同且种类多样等原因,个体出现的病理反应也不同,这一系列原因均导致了许多患者一经诊断就是晚期,这极大的增加了治疗的难度。有研究报告显示,肺癌早期患者如果能及时发现,并进行规范治疗,术后5年生存率可达到60%~90%,若在发病初期进行行之有效的治疗,其5年生存率可提升至90%以上,但若临床诊断为晚期,即使经过治疗,其术后5年生存率也远低于5%[1]。目前,深度学习在人工智能领域引起了巨大的反响,在各个领域被广泛应用。在医学领域中,利用深度学习方法辅助医生诊断治疗已取得有效成果,肺结节分割作为当前深度学习研究热点之一,其主要功能是利用深度神经网络实现图像分割,现有肺结节分割方法主要是将肺结节特征与机器学习算法结合[2]。Ronneberger 等[3]人提出了U-Net 网络模型,该模型使用较少的数据集进行端到端的训练方式,结果表明该模型对肺结节的分割具有良好的效果;张佳[4]基于短跳跃连接方式提出了一种改进的SCV-Net 模型,该模型可以更加充分的利用特征图信息,使得肺结节的漏检情况得到了有效的解决,明显提高肺部结节的分割精度;苗语等人[5]针对肺部CT 图像特征信息复杂程度较高及经典U 型卷积网络分割准确率较低的问题提出一种改进的网络,通过将U-Net 和DenseNet网络融合的方法对模型的分割性能进行提高,采用LUNA16数据集验证这一模型的有效性;钟思华等人[6]提出一种改进的V-Net 网络模型方法,即基于MSVNet 网络的肺结节分割模型,在继承原始V-Net 方法的基础上采用了多尺度结构和深监督策略来提取肺结节图像详细特征,有效提高了肺结节分割性能和分割鲁棒性。目前已有很多深度学习的网络结构被广泛用于医学图像的处理中。本文利用V-Net 分割模型对肺结节数据集LUNA16 进行实验,对LUNA16 数据集进行预处理后用V-Net 模型训练后评估预测,从而实现肺结节的自动分割,这一方法相对于人工特征提取分割的方法更加准确和快速,对肺癌患者的早发现和早诊断治疗有一定的参考价值。肺结节分割的基本过程如图1 所示。

图1 肺结节分割流程
1 数据与方法
1.1 数据集
本文采用的是LUNA16(Lung nodule analysis 2016)比赛提供的数据集。LUNA16 是由更大的肺数据集LIDC-IDRI进行选取后产生的一部分数据集,LIDC-IDRI 数据集共有1 018 个病例,每个病例对应的CT 图像都对应有xml 格式的标签文件。该数据集主要删除了切片厚度大于3 mm 和肺结节小于3 mm 的CT 影像,最后只剩下888 例患者低剂量肺部CT 图像构成了LUNA16 数据集[7]。LUNA16 数据集中的结节至少由四名专业影像医生进行标记后产生,其中每个CT 影像包含一系列胸腔的多个轴向切片,其中切片的数量受扫描机器、患者不同以及扫描层厚等不同的影响。需要说明的是每个CT 图中可能不是只有一个结节,也并不是每个CT 图中都有一个或多个结节。原始的肺部CT 图像都是三维图像,每个图像是由胸腔的多个二维轴向切片组合而成,切片大小是512 像素×512 像素。LUNA16 数据集中的888个CT 图像被均匀的划分成10 个子集,分别存放在subset0到subset9 这10 个子文件夹中,该数据集的图像存储方式为MetaImage(mhd/raw)的格式,每个mhd 文件都存储有一个单独的对应的raw 二进制文件,mhd 文件存放信息,raw文件用于存放像素数据,这两部分是同时存在的。
LUNA16 数据集作为目前肺结节检测大赛的公开数据集,其图像质量具有较高的可靠性,此外许多相关专家对肺结节的位置进行了标注,许多肺结节方面的研究均基于该数据集展开[8]。因此利用该数据集作为模型的训练数据和测试数据具有较高的可靠性以及良好的模型性能对比性。
1.2 数据预处理
为了使得肺结节分割不受其他组织的影响,结节分割的更加准确,我们需要对得到的肺部CT 图像进行一些数据预处理操作。基本的处理流程如图2 所示。

图2 预处理
对原始CT 图像进行直方图均衡化使得肺实质部分颜色加深更加突出;随后进行二值化处理是由于肺实质部分的灰度值和周围组织差距较大,对图像进行二值化可以初步分割出肺实质部分;接着对初步分割出的肺实质进行数学形态学处理,主要通过膨胀和腐蚀这两种方法来消除肺实质内部噪声和平滑边缘部分;最后将得到的肺实质掩膜进行感兴趣区域(ROI)的提取。经过上述处理流程产生的肺实质分割图像如图3 所示。
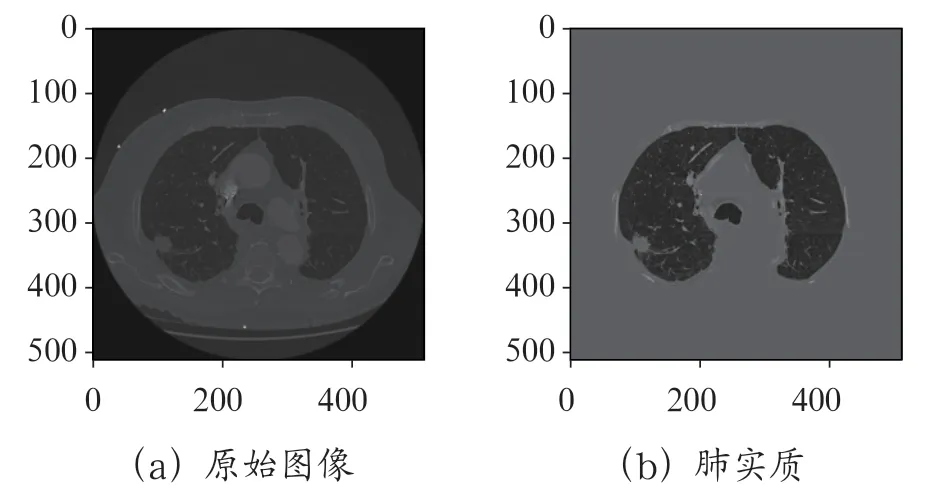
图3 原始图像与对应的肺实质
肺实质图像的获得对结节掩膜的提取更加方便,由于LUNA16 提供的标注数据,可以生成对应肺部CT 切片图像的结节掩膜图像,其中结节掩膜为一张仅含有1 和0 两个像素的图像,其中1 代表肺结节所在像素[2]。图4(右)中白色区域为根据结节的标记位置和结节直径生成的圆形。

图4 肺实质与对应的结节掩膜
在LUNA16 数据集中提供了annotations.csv 文件,该文件中存放的是某一结节CT 图像的病例编号、结节在世界坐标系下的(x,y,z)以及结节的直径大小。不同结节直径产生的像素图像也有很大差别,图5 可以通过肉眼直观的看到不同结节掩膜的大小,此外结节掩码的大小也可判定结节的良恶性,对肺结节的良恶性分类提供了良好的依据。


图5 肺实质(左)与对应的结节掩膜(右)
1.3 V-Net 分割模型
在医学图像分割领域中,U-Net 网络模型是最为经典的生物医学图像分割模型,该模型借鉴了全卷积神经网络的思想,最大的特点是采用了编码-解码的网络结构以及跳跃连接机制[3]。V-Net 模型作为U-Net 网络模型的一个变体,采用的也是编码-解码的结构,并且编码部分和解码部分的层数都是四层,两者有着很多的共同之处,但作为U-Net 的变体,V-Net 模型的独特之处在于V-Net 网络结构的每一层都融入了残差学习机制,加入该机制的主要作用是用来减缓模型训练过程的梯度消失,此外该模型用卷积层来代替池化层从而实现下采样,同时V-Net 是一种基于3D 卷积的三维分割方法,而临床使用的大多数医疗数据都是3D 的,它采用端到端的训练方式[9],这对于LUNA16 三维图像有很大的优势,更利于对肺结节的分割。V-Net 的模型结构如图6 所示。
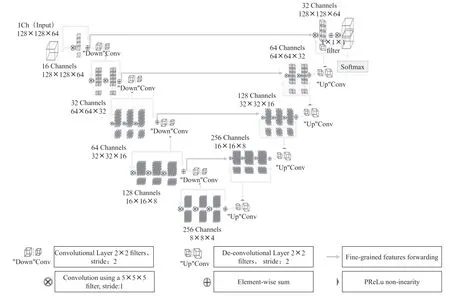
图6 V-Net 网络模型
其中V-Net 模型的左侧部分为压缩路径,也就是所谓的编码。编码部分被分成多层,每一层对应每某一个图像尺度的分辨率,每层使用5×5×5 的卷积核,进行了21 次卷积操作,所以感受野较大,但随着数据不断向下传送到不同的层,其对应的分辨率也会呈倍数缩小。该模型的每一层引入了残差学习结构,使用原理是本层最后一层卷积后得到的输出特征图同上一层下采样后的特征图进行了相加,V-Net 模型在每一层的最后均会进行下采样操作来获得更大的局部感受野,下采样操作之后,输出的特征图的分辨率会减半,但数量会成倍增加[10]。在图像的分割任务中,通过下采样操作会使得特征图的分辨率减小从而保留图像的细节特征。V-Net 模型的右侧部分为扩张路径,也就是所谓的解码,同编码部分一样的是解码部分的每一层也对应某一尺度的分辨率,随着数据向扩张路径的移动,对应的分辨率成倍增加[11]。在解码阶段,每一层使用了反卷积操作来实现数据特征图的上采样,进行上采样后会使得特征图的尺寸翻倍,通道数减半,该模型和U-Net 模型都采用了跳跃链接,即将编码部分每一层产生的输出和同一层对应的解码部分的输入连接起来,从而使得特征图的通道数不断变大,很好的融合了在编码过程中所丢失的一些重要细节特征。采用这一方式对图像的最终分割精度也会有较大的提高,这也是U-Net 和V-Net 网络模型被广泛用于医学分割任务的重要原因之一。
2 实验结果
本文通过对数据进行数据重采样、数据归一化、图像切割和标签生成等操作,可得到若干个尺寸为(96,96,16)的肺结节图像和掩码,其中至少包含1 个结节的肺部CT数据块和对应的肺结节标签。实验采用Python 3.8 环境及Tensforf low 深度学习框架。
对于已经训练好的V-Net 网络模型,我们对测试集部分进行相同的数据预处理后输入到训练好的模型进行预测。图7(a)为原始图像,图7(b)为LUNA16 提供的结节标记数据,即金标准图,图7(c)为模型预测生成的结果。取其中某三个测试集进行可视化展示,我们通过肉眼就可以直观的看到该模型对结节的分割性能。整体来说,模型预测的结果均达到了90%以上的良好分割精度。

图7 肺结节分割结果
3 结 论
本文的研究是基于V-Net 深度学习网络模型进行的肺结节分割实验,采用目前公开且应用广泛的肺结节数据集LUNA16 作为训练数据和测试数据,经过一系列预处理后,将数据通过模型训练和预测实验进行肺结节的分割。目前采用的深度学习方法能够实现自动分割任务,不需要人工提取肺结节特征,为医学图像处理带来了巨大便利。实验结果使用肉眼直观的展示了该模型的分割性能,但分割结果较为粗糙,在医学图像领域,只能辅助医生进行简单的位置诊断和结节大小判断。在接下来的学习研究中,采用某医院的实验数据进行验证是很有必要的,此外对分割结果进行更加详细的可视化任务和模型对比分析也是进一步要研究的重点内容。
