融入语义信息的VSLAM研究综述
2022-11-18张荣芬袁文昊李景玉刘宇红
张荣芬,袁文昊,李景玉,刘宇红
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
同步定位与地图构建(simultaneous localization and mapping, SLAM)是一种用于在陌生环境中确定自身位姿和构建环境一致性地图的方法。近些年,SLAM一直是一个研究热点,被广泛应用于自动驾驶,AR,机器人等诸多领域。视觉同步定位与地图构建(visual simultaneous localization and mapping, VSLAM)系统因其基于视觉传感器可以直接获取场景内容,成本较低,深受研究人员喜爱。
传统VSLAM系统通过位姿估计,回环检测,非线性优化和建图解决在未知环境确定自身位姿和对环境的感知问题。目前,VSLAM的相关方案已经十分完善,如LSD-SLAM[1],RGBD-SLAMV2[2],ORB-SLAM[3-5]系列等。
VSLAM作为一种具有很强应用背景的算法技术,在实际应用中往往有着更高层次的需求。但传统的VSLAM仍存有一些不足之处,例如:视觉里程计中数据关联,基于特征点的方法中出现特征难以提取,中长期位姿估计的漂移和空间上物体尺度的变化,以及视点变化带来的回环检测位置识别,如何构建具有丰富感知信息的地图等问题仍然阻碍着VSLAM的实际应用趋势。随着深度学习的不断发展和深入,一些经典的神经网络例如SSD[6]、YOLOv3[7]、SegNet[8]、MaskRCNN[9]等的出现,给传统VSLAM带来了另一种不同的思路和启发,在借助语义信息改善传统VSLAM中存在的问题的同时,也拓展了VSLAM的研究领域,为VSLAM打开了语义的大门。
本文从传统的VSLAM框架出发,以视觉里程计、回环检测、建图3个部分分别对目前结合语义信息的VSLAM算法的研究现状进行分析和阐述,为语义VSLAM算法的研究提供参考。
1 语义与视觉里程计
传统的VSLAM系统主要由视觉传感器、前端(视觉里程计)、后端(非线性优化)、回环检测、地图构建5个部分组成,整体系统框架如图1所示。
视觉里程计作为重要的系统组成部分之一,从传感器获取数据进行处理,用于估计位姿和短期的局部地图构建,而位姿估计的准确性很大程度上取决于帧间有效的数据关联和帧中关键点的提取。在一些弱纹理、光照强烈变化的环境中,往往不能提取足够有效的关键点用于位姿估计;同时,环境中出现的动态物体也会造成错误的数据关联,给位姿估计带来较大误差。
为此,人们将语义引入视觉里程计进行优化,主要方式分为两种:一是将采用直接法(光流法)
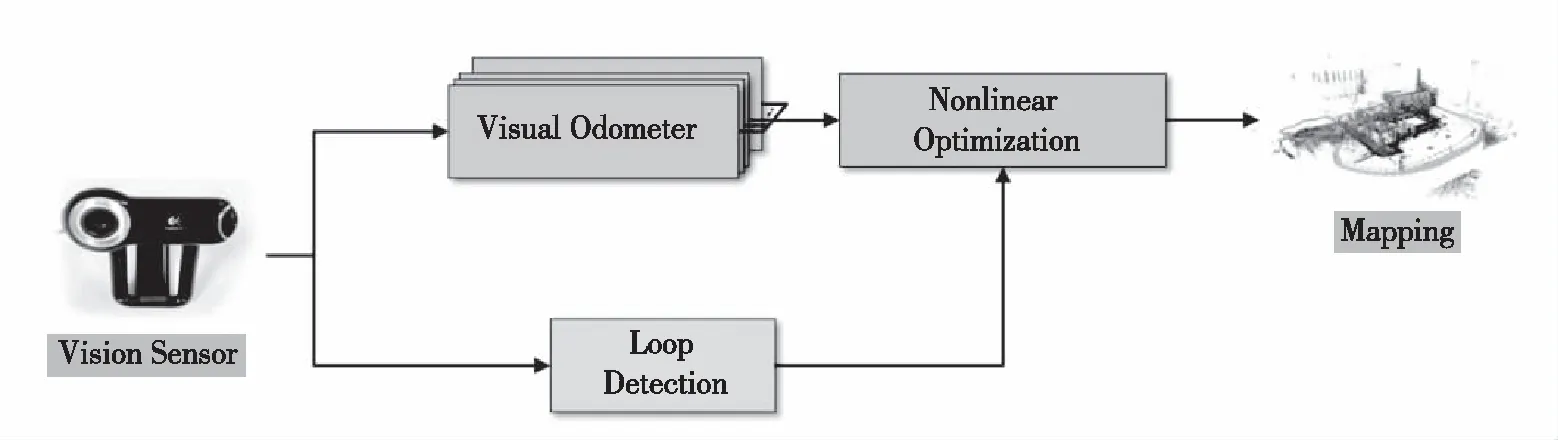
图1 基础系统框架Fig.1 The basic system structure
或间接法(特征点法)提取点特征的方式替换成直接从图像帧中提取语义特征,用于估计位姿。例如,文献[10-13]利用场景语义信息完成对特征的学习和提取,将对特征的提取转变成语义方式。文献[14]提出了一种区别于传统特征点描述符的方法,通过提取场景上下文语义形成紧密描述符,进一步学习语义描述符正确匹配的上下文信息,仅匹配语义接近的一组关键点,提高匹配精度。二是将语义信息作为约束条件,协助提高位姿估计精度。这种方式往往更倾向于多种约束共同作用,以此解决数据关联中的误关联问题。文献[15-19]利用光流信息,场景流信息,多视角几何与语义信息结合形成对动态物体的紧密约束,通过对获取的语义掩膜结合其他动点检测方法,剔除动态物体对数据关联的影响。图2是文献[15]中SOF-SLAM的动态物体剔除算法流程。
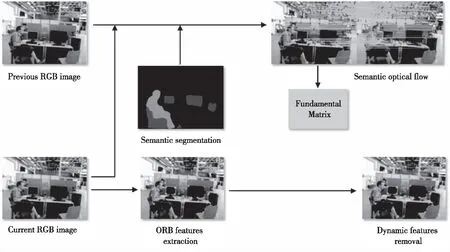
图2 SOF-SLAM的动态物体剔除算法流程Fig.2 Flowchart of dynamic object removal algorithm in SOF-SLAM
随着实例分割网络的出现,对于物体的分割达到了不同的精度。文献[20-21] 结合实例分割和多视图几何、ORB(oriented FAST and rotated BRIEF)特征点方法,显著提高了SLAM系统在高动态环境下的鲁棒性和准确性。Co-Fusion将场景中的对象进行分割划分,使用多模型拟合方法,有效跟踪对象形状并随着时间推移进行融合,实时重建3D形状,完成对多目标物体的追踪[22]。和这些方法不同的是,在语义信息的利用上,文献[23-27]在获取物体语义信息的同时,针对物体的2D检测框也做了相应的处理。从2D目标检测边界框推断3D物体姿态,使用语义标签区分不同类别的物体,通过匹配相同语义标签消除相似特征的数据关联,或者直接在语义获取的确定对象区域中进行特征信息提取,这些方法在一定程度上可以降低数据间的误关联,提高视觉里程计的鲁棒性。
2 语义与回环
在中长期的位姿估计中会产生误差累积,物体的尺寸在空间上变化以及视点的变化都会影响构建全局一致性地图,而对同一位置难以进行有效识别,最终影响位姿轨迹的有效闭环,这是VSLAM中需要关心的一个重要问题。为了构建准确的全局一致性地图,矫正位姿估计,VSLAM系统引入了回环检测。传统的回环检测方法主要是词袋模型和相似性度量。词袋模型一般需要事先载入训练好的词典树。为了达到有效区分,词典树往往较为庞大,在一些移动应用上受到限制;而基于相似性度量的方法,在计算图像特征相似度时则需要大量的计算。这两种方法虽然被广泛应用,但仍有一些不足。
在回环检测中使用语义信息的主要方式有两种:一种是协助传统方法提高相似特征搜索速度和精度;另一种是仅使用卷积神经网络(convolutional neural network, CNN)去提取语义特征,使用特征点进行相似性度量,判断回环。OLAODE等[28]将语义信息融入到词袋模型的构建中,降低了冗余、批量矢量化的图像特征,使词袋模型与图像内容多样性相关,并具有语义信息。文献[29-31]将语义信息与词袋模型相结合,在搜索相似特征匹配时,利用语义信息的一致性缩小相似度量的范围、增强特征点的相似性,达到提高搜索速度和闭环精度的目的。文献[32-33]利用语义地标信息,协助判断特征的相似性,丢弃不相关的特征,使用CNN的方法将语义信息替换词袋和图像特征相似性度量,使用语义特征进行回环检测。WANG等[34]使用语义与几何信息构建语义子图,利用3D空间中物体之间的形状相似度和欧几里得距离,通过图匹配衡量图像的相似度进行回环检测。YUAN等[35]将视觉特征与语义标签连接起来建立了语义词袋模型,编码设计了语义地标向量模型与语义图的几何关系,最后融合语义、视觉和几何信息用于回环检测。文献[36-37]利用CNN提取深层特征识别匹配图像之间的地标,或结合滤波方式提高位置识别的精度,达到检测回环的目的。VYSOTSKA等[38]在CNN特征提取的基础上,利用哈希算法改善了高维CNN特征的检索速度。SARLIN等[39]提出一种基于整体CNN的分层定位方法,同时预测局部特征与全局描述符,以全局检索假设位置,再匹配候选位置的局部特征识别位置。LI等[40]提取图像的卷积特征作为描述符,然后对提取的特征进行处理,计算出图像的相似度得分,进而判断回环。CHANCN等[41]从单目图像序列中学习图像内容和位置的标志,获取基于序列位置识别的双峰描述符,提高识别精度。WANG等[42]引入语义拓扑图对地标的空间关系进行编码,并采用随机描述符表征用于图匹配的拓扑图,选择有特色的地标进行回环检测。MERRILL等[43]从原始图像提取鲁棒性特征,利用自动编码网络,结合定向梯度直方图,构建描述符,进行回环检测。
3 语义与建图
传统的VSLAM能够构建出度量地图和拓扑地图,但是对于更高层次的人机交互应用来说,缺少环境内容信息的地图很难被应用。机器人虽然可以感知环境中的空间占据信息,却无法深入理解物体的具体信息。这对一些需要机器人与环境交互的应用来说,例如寻物导航与目标抓取,是亟需改善的。而场景的语义信息中包含丰富的环境内容感知,将语义信息融入地图或者构建具有语义信息的地图正是解决这一问题的关键。
地图有机融入语义信息主要有三种方式:第一种是将2D语义信息与VSLAM构建出来的地图按照一定的方式进行融合,使地图具有语义信息。CNN-SLAM利用CNN获取深度图,结合单目SLAM获取的深度图,融合单帧语义与稠密点云,得到语义连贯的地图[44]。文献[44]中CNN-SLAM的语义地图如图3所示。文献[45-46]通过语义分割网络获取语义信息,根据3D点云的深度、语义标签等信息更新点云状态。ZHENG等[47]利用目标检测获取场景中对象的信息,数据关联时将其与已经存在的所有对象进行比较,若找到对应则点云配准、合并点云,并结合关键点和类别置信度构建对象点云,否则创建新的对象实例,输出包含对象信息组成的地图。文献[48-49]利用CNN模型提取场景中的语义信息,采用三维体素状态表示空间占用率的方式,将语义信息与3D地图实现紧耦合,完成完整的3D场景地图的表达。

图3 CNN-SLAM的语义地图Fig.3 Semantic map of the CNN-SLAM
第二种是基于对象模型的方法。首先,分割场景中的语义对象;其次,由不同的对象模型构成环境地图。MCCORMAC等[50]使用语义分割获取每个对象及其掩码,结合对象检测结果,对每个物体进行三维重建,建立物体级的语义地图。SALAS-MORENO等[51]利用由许多重复的、特定的对象和结构组成的场景中的先验知识,为实时3D物体识别和跟踪提供了六自由度的相机-对象模型约束。约束信息实时输入到对象图中并不断搜索新对象,最后以增量的方式构建地图。GRINVALD等[52]提出将几何方法与实例语义预测相结合,以检测已识别的场景元素以及以前看不见的对象;通过数据关联步骤跟踪不同帧的预测实例,将对象的3D 形状、位置和语义类的信息融合到全局地图中。RUNZ等[53]提出一种通过识别、分割为场景中的不同对象分配语义标签,同时跟踪和重建,即使它们独立于相机移动,其中基于图像的实例级语义分割会创建语义对象掩码,从而实现实时识别并为世界地图创建对象级表示。图4展示了文献[53]中MaskFusion的物体重塑化效果。ROSINOL等[54]提出了一个实时语义度量的视觉惯导SLAM开源库,可以稳健地快速进行网格重建并构建稠密语义3D地图。

图4 MaskFusion算法的物体重塑化效果Fig.4 Effect of object reconstruction in MaskFusion
第三种是采用多视角的方式。其将不同视角的语义信息相结合,构建信息更加丰富的环境地图。普通的单视角的方式通常不能看到充足的环境信息,而多视角可以得到环境的全面信息,结合语义可以构建较为全面的环境感知地图。MCCORMAC等[55]将CNN与Elastic Fusion相结合,在循环扫描轨迹期间提供视频帧之间的长期密集对应关系,概率性地融合来自多个视点的语义预测到地图中,产生3D语义地图。CHANG等[56]使用多机器人协作的模式,利用机器人间的闭环进行轨迹的估计,从不同的空间角度,结合语义信息构建3D语义度量地图。QIN等[57]将来自不同个体的海量数据合并到云端服务器,及时更新语义地图;再将语义地图压缩并分发到每一个个体,实现在不同空间和时间上的语义地图。
4 总结和应用展望
目前,语义信息已经被广泛应用到VSLAM的各个模块中,对于前端视觉里程计来说,主流选择还是与其他动点检测方法形成约束解决数据关联问题。对于使用语义分割网络代替视觉里程计的研究还不足,在回环检测中也出现相同的趋势,但是对于构建语义地图,语义信息却得到了充分利用和拓展。从当前的研究趋势我们不难看出,结合语义不仅能够提高VSLAM系统的鲁棒性和精准性,而且还能为高层应用提供更加丰富的环境感知信息,进一步实现人机交互的智能化。
在未来,一方面,语义信息的利用呈现一种多约束条件共同作用的趋势,例如语义信息与视觉惯导的融合,不同传感器语义信息的相互约束,多SLAM系统相互约束等;另一方面,VSLAM语义信息地图也将更加深入应用到VSLAM各行各业的方方面面。例如课题组正在研究的面向3D场景理解与交互的盲人出行导航与避障、居家寻物取物、商场购物选物等智能任务,其中,针对稀疏语义地图的增强和面向交互的局部稠密化技术可以为AR空间打造、服务机器人、无人机低空自主飞行等特殊空间类似场景的理解应用提供借鉴与支持;此外,面向边缘计算的语义VSLAM实现架构与算法部署是上述应用得以实时实施的关键,或将语义VSLAM推向一个新的应用研究热潮。
